






基于fpga的实时视觉SLAM特征提取
本篇文章发表于2017年FPT
摘要
同步定位和映射(SLAM)是构建或更新未知环境地图的问题,同时跟踪代理在其中的位置。如何在移动甚至物联网级设备上健壮和持久地实现SLAM是当今行业面临的主要挑战。我们需要解决的主要问题是: 1.) 如何加速 SLAM 管道以满足实时性要求; 2.) 如何减少 SLAM 能耗以延长电池寿命。在深入研究问题后,我们发现特征提取确实是性能和能耗的瓶颈。因此,在本文中,我们设计并评估了硬件 ORB 特征提取器,并证明与 ARM Krait 和 Intel Core i5 相比,我们的设计在性能和能耗之间取得了很好的平衡。
索引术语-ORB,特征提取,SLAM,FPGA
介绍
同步定位和映射(SLAM)[7]-[8]是自动驾驶汽车、机器人、虚拟现实(VR)和增强现实(AR)等应用背后的核心使能技术。具体来说,SLAM 是构建或更新未知环境地图的问题,同时跟踪代理在其中的位置。图1显示了我们的生产级视觉惯性SLAM系统的简化版本,该系统利用了MSCKF[1]和ORB-SLAM[2]的设计概念。
我们在四核ARM v8移动SoC上实现了这种SLAM技术。基于我们的分析结果,特征提取阶段确实是 CPU 资源中最计算密集型、消耗 >50%。即使有如此繁重的计算资源消耗,从 VGA 分辨率 (640 × 480) 图像中提取特征仍然需要大约 50 毫秒,导致帧速率仅为大约 20 FPS。
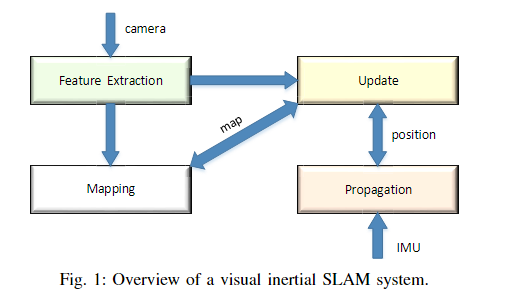

因此,在本文中,我们的目标是通过实现 ORB 特征提取器的硬件加速器来解决这些实际问题到硬件级别。ORB广泛应用于机器人技术中,它被证明为SIFT[3]提供了一种快速高效的替代方案。此外,我们检查了设计的性能、资源占用和能耗,以实现进一步的改进。
本文的其余部分安排如下。在第 II 节中,我们回顾了 ORB 算法的上下文信息。在第 III 节中,我们描述了所提出的硬件特征提取器的架构。在第四节中,我们分享了实验方法和结果。最后,我们在第 V 节总结了我们的结论。
2 用于视觉 SLAM的ORB特征提取算法

基于ORB的特征提取算法的概述如图2所示。它由基于oFAST(来自加速段测试的方向特征)[5]的特征两部分组成基于检测和简要(二进制鲁棒独立基本特征)的特征描述符计算
A 加速段测试(oFAST)定向特征
一般来说,给定图像,oFAST有助于找出特征点,然后计算特征点的方向,以确保旋转不变。oFAST的详细信息如图2所示。首先,使用双线性插值[4]调整原始图像的大小。其次,计算原始图像和调整大小图像的特征点。第三,确定特征点的方向。特征点的方向计算如下。
定义特征点的补丁为以特征点为中心的圆。patch mpq 的矩定义为,
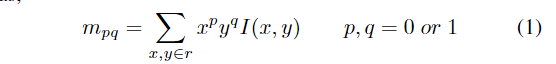
其中 I(x, y) 是补丁中点 (x, y) 的强度值,r 是圆的半径。特征点 θ 的方向由 θ = arctan( m01m10 ) 获得。sin θ 和cos θ 计算如下。
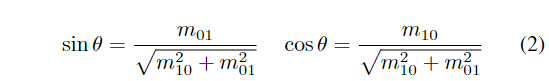
B 导向二元鲁棒独立基本特征(导向简要)
一般来说,特征点由一组描述符表示。在ORB算法中,采用导向BRIEF算法计算特征点的描述子。转向BRIEF算法的细节描述如下。
首先,考虑oFAST中定义的圆形补丁。根据高斯分布选择补丁中的点对。其次,为了保证旋转不变,将这些点对旋转由方程2确定的角度。因此,在旋转后,M对点可以标记为d1(IA1, IB1),D2(IA2, IB2),D3(IA3, IB3)。… DM (IAM , IBM ),其中 Ai 和 Bi 是一对的两个点,IAi 和 IBi 是点的强度值。第三,算子定义如下,
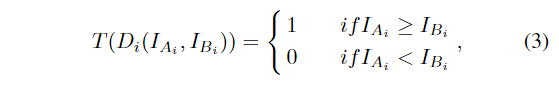
对于每对点,运算符 T 产生一点结果。使用 M 对点,算子 T 产生一个长度为 M 的位向量。例如,T 产生以下结果,T (D1(IA1, IB1)) = 1, T (D2(IA2, IB2)) = 1, T (D3(IA3, IB3)) = 0。… T (DM (IAM , IBM ))) = 1,则特征点 P 的描述符为 110…1.位向量是特征点的描述符。
三、硬件架构
A. 基于fpga的实时SLAM的总体架构
图3(右)说明了所提出的基于fpga的实时SLAM系统体系结构。ARM多核处理器用于在SLAM中执行控制逻辑和其他计算。AXI总线用于连接存储系统、ORB加速器和ARM处理器。
特征提取加速器由访问部分和内核部分的数据组成。内核部分由指令内存、控制单元和特征提取器组成。访问部分的数据由输入缓冲区、输出缓冲区和 DMA/Bus 接口组成。DMA/Bus接口通过AXI总线直接访问相机捕获的数据流,并将数据存储在特征提取器的输入缓冲区中。特征提取器的结果存储在输出缓冲区中,最后发送到 L2 缓存。ARM多核系统将使用这些特征进行进一步的处理。
B.ORB特征提取器的硬件架构
ORB特征提取器的硬件架构如图3(左)所示。该体系结构由图像大小调整模块、特征检测模块、方向计算模块和描述符计算模块组成。线缓冲区和寄存器用于存储中间结果。
调整大小模块实现双线性插值并构建 2 级图像金字塔。输入图像的大小为640 × 480,缩放图像的大小为533×400。RAM1存储每个级别的图像。
LB1(行缓冲区1)存储31行像素。RB1(寄存器库1)存储31 × 31像素的邻域,其中包含每个点的圆形补丁。特征检测模块检测特征点并计算patch的矩,即m10和m01。特征点的坐标(x, y)存储在RAM3中。
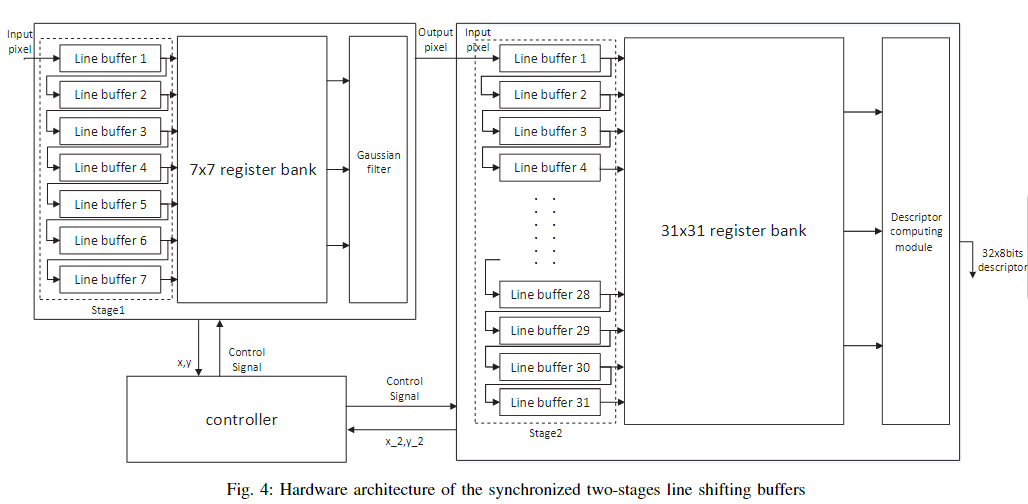
方向计算模块根据公式 2 计算 sin θ 和 cos θ。 sin θ 和 cos θ 存储在 RAM2 中。使用 7 × 7 硬件高斯滤波器平滑图像。LB2 和 RB2 分别缓冲 7 行像素和高斯滤波器的 7 × 7 像素补丁。LB3 和 RB3 用于存储高斯滤波器的结果。由于描述符计算模块以31 × 31像素为单位计算描述符,LB3存储31行像素,RB3缓冲区31 × 31字节。
描述符计算模块将图像中特征点的平滑图像、方向和坐标作为输入,并计算特征点的描述符。由于描述符计算模块依赖于高斯滤波器的结果,一个简单的实现是在开始计算描述符之前缓冲整个图像。然而,这种需要存储整个图像的简单设计需要大量的片上内存资源。此外,从在整个图像上高斯滤波后计算描述符将停止特征检测和方向计算的流处理,这将增加系统的延迟。
提出了同步的两阶段移动线缓冲区,如图4所示,以流方式计算高斯滤波和描述符。线缓冲区的第一阶段和第二阶段分别存储高斯滤波器和描述符计算模块的像素。每个阶段的线缓冲区被组织为移位器。控制单元同步行缓冲区中的数据移动。如果没有检测到特征点,两阶段线缓冲区会移动缓冲区中的数据。如果检测到特征点,控制单元停止移动两级线缓冲区,并开始计算特征点的描述符。通过利用所提出的同步两阶段线缓冲区,保存575K字节的片上存储器
四 评估结果与讨论
A.字长优化
根据方程2,特征点的方向由圆形面片的矩决定。在我们的设计中,补丁的半径是15。m10和m01的值范围从-624750到624750不等。需要21位来表示m10和m01。方向计算模块需要更多的比特来保持精度,这将消耗大量硬件资源。
字长优化用于减少硬件消耗。通过计算所有可能的圆形斑块的m10和m01,我们发现m10和m01中的许多重要位在大多数情况下为零。此外,计算中低位的影响非常小。因此,所提出的缩短字长的操作描述如下。
首先,从不考虑符号位的最高数据位开始,找到 m10 和 m01 的重叠 0s 然后删除它们。其次,在剩余的数据位中,取更高的 N 位。如果剩余部分小于 N 位,则用零填充它。最后,拼接符号位,得到N位。这样,字长将缩短到 N+1 位。
截断字长在计算旋转角度时引入了截断误差,并进一步影响旋转后点的坐标。对于一个特定的点(x, y),旋转后的坐标为(x ', y '),由:
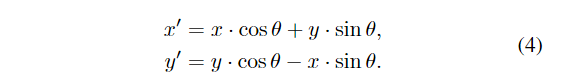
我们定义了以下度量来定量评估由字长截断引入的误差,
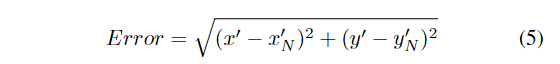
其中 (x′, y′) 是使用原始字长计算的坐标,而 (x′N , y′N ) 用 N 的字长计算。
补丁中的像素对字长截断有不同的敏感性。当以相同的角度旋转面片中的两个不同点时,离原点更远的点将进一步移动。因此,从原始点更远的点更有可能处于错误的位置。最大误差发生在点 (±15, ±15),这些点与补丁中原始点最远的点。
图 5 说明了字长和最大平均误差之间的关系。结果表明,随着字长的减小,最大误差呈指数增长。考虑到精度和硬件消耗,我们设计中方向计算单元的字长为8位。
表 I 将方向计算模块的硬件消耗与 21 位和 8 位字长进行了比较。结果表明,字长优化后,寄存器和LUT的数量显著减少65%和83%。

B.硬件评估
所提出的 ORB 特征提取器在 Altera Stratix V FPGA 上实现和评估。所提出的硬件消耗 25648 个 ALUT、21791 个寄存器、1.18M 个 BRAM 和 8 个 DSP 块。所提出的硬件的时钟频率为203MHz。处理图像的硬件延迟为14.8ms,硬件的吞吐量为每秒67帧。
我们将所提出的硬件与多核ARM处理器和Intel CPU进行了比较。表 II 显示了所提出的硬件和 ORB 实现在 ARM Krait 和 Intel Core i5 CPU 上的性能比较。比较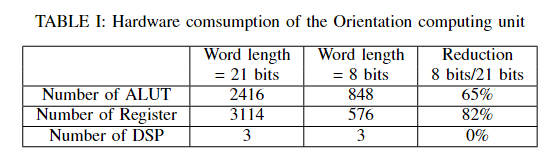
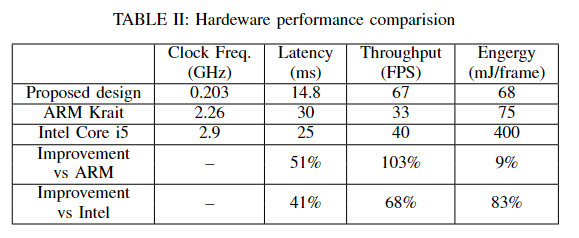
使用ARM Krait,延迟和能量消耗减少了51%和9%,吞吐量提高了103%。与 Intel i5 CPU 相比,延迟和能耗降低了 41% 和 83%,吞吐量提高了 68%。
5 结论
特征提取是视觉惯性SLAM系统中计算量最大的部分。在我们的生产级系统中,我们利用 ORB 作为我们的特征提取器,因为 ORB 广泛用于机器人技术,并且被证明可以为 SIFT 提供快速高效的替代方案。基于我们的分析结果,ORB 特征提取需要超过 50% 的 CPU 资源和能源预算。在本文中,我们旨在解决这个问题,我们设计并评估了硬件 ORB 特征提取器。我们的设计只在大约203 MHz下运行,以减少能源消耗。在计算延迟类别中,它比 ARM Krat 高出 51%,英特尔酷睿 i5 高出 41%;在计算吞吐量类别中,它比 ARM Krat 高出 103%,英特尔酷睿 i5 高出 68%;最重要的是,在能耗类别中,它比 ARM Krat 高出 10%,Intel Core i5 高出 83%。因此,这种设计被证明是性能和能源消耗之间的巨大平衡。
6 问题
这是一篇相对来说比较老的文章了,平平无奇,对于现在这个时间来说没有特别值得学习的地方。















 2191
2191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









