









卷积神经网络中卷积层的参数设置与卷积核的大小还有数目有关。具体数目为:卷积核size×卷积核size×均积核的channel数目×卷积核的数目×bias(卷积核数目);
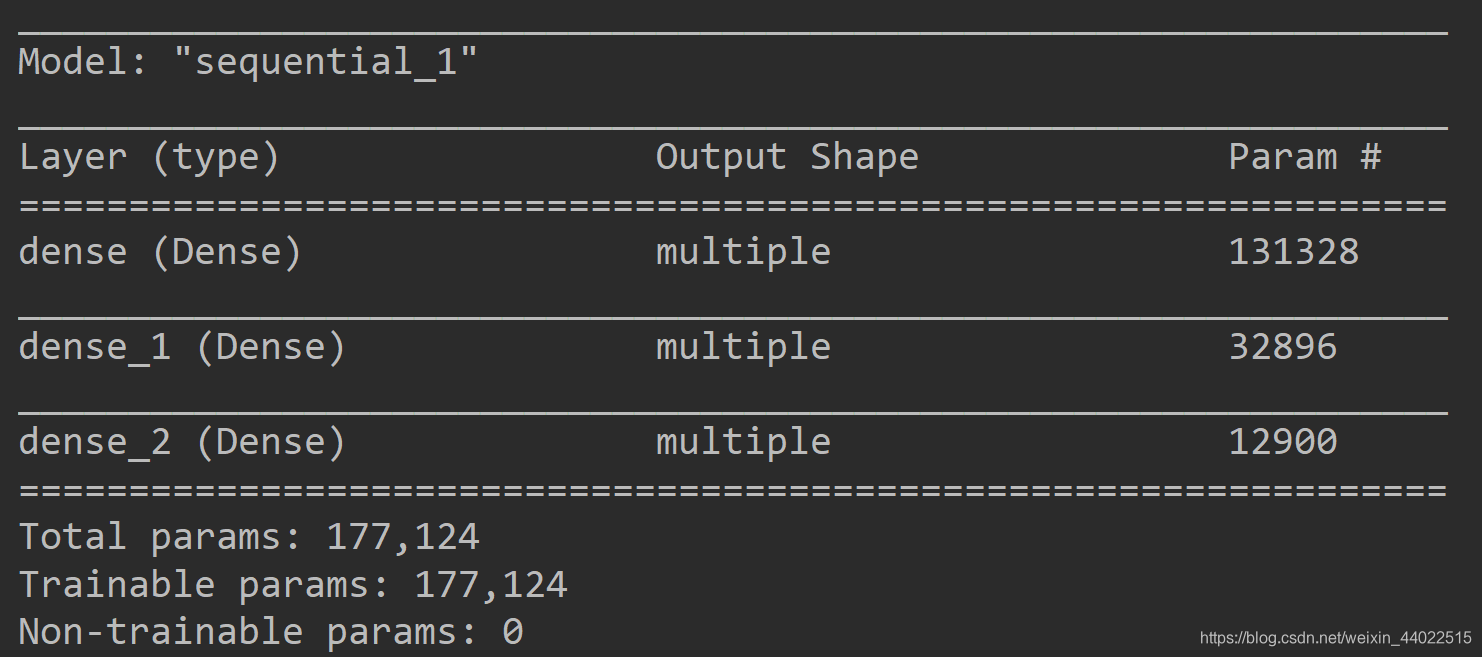
全连接层的参数数目为:imput的matrix特征数目*全连接层Dense数值
import tensorflow as tf
from tensorflow.keras import layers, optimizers, datasets, Sequential
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
tf.random.set_seed(2345)
conv_layers = [
layers.Conv2D(64, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
# 本层参数:卷积核size×卷积核size×均积核的channel数目×卷积核的数目×bias(卷积核数目)对应 3*3*3*64+64=1792
layers.Conv2D(64, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
#本层参数数目:3*3*64*64+64=36928,chanel数目为上一个卷积层的输出结果,为64
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
# 同理,本层参数为3*3*64*128+128=73856,64为上一个卷积层的输出为64
layers.Conv2D(128, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(256, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
]
def preprocss(x, y):
x = tf.cast(x, dtype=tf.float32)/255.
y = tf.cast(y, dtype=tf.int32)
return x, y
(x, y), (x_test, y_test) = datasets.cifar100.load_data()
y = tf.squeeze(y, axis=1)
y_test = tf.squeeze(y_test, axis=1)
print(x.shape, y.shape, x_test.shape, y_test.shape)
train_db = tf.data.Dataset.from_tensor_slices((x, y))
train_db = train_db.shuffle(1000).map(preprocss).batch(64)
train_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
train_test = train_test.map(preprocss).batch(64)
sample = next(iter(train_db))
print('sample: ', sample[0].shape, sample[1].shape,
tf.reduce_min(sample[0]), tf.reduce_max(sample[0]))
def main():
conv_net = Sequential(conv_layers)
# x = tf.random.normal([4, 32, 32, 3])
# out = conv_net(x)
# print(out.shape)
fc_net = Sequential([
layers.Dense(256, activation=tf.nn.relu),#参数数目:imput dim(512)*256+256=131328
layers.Dense(128, activation=tf.nn.relu),
layers.Dense(100)
])
conv_net.build(input_shape=[None, 32, 32, 3])
fc_net.build(input_shape=[None, 512])
conv_net.summary()
fc_net.summary()
if __name__ == '__main__':
main()
结果:
卷积层参数数目:
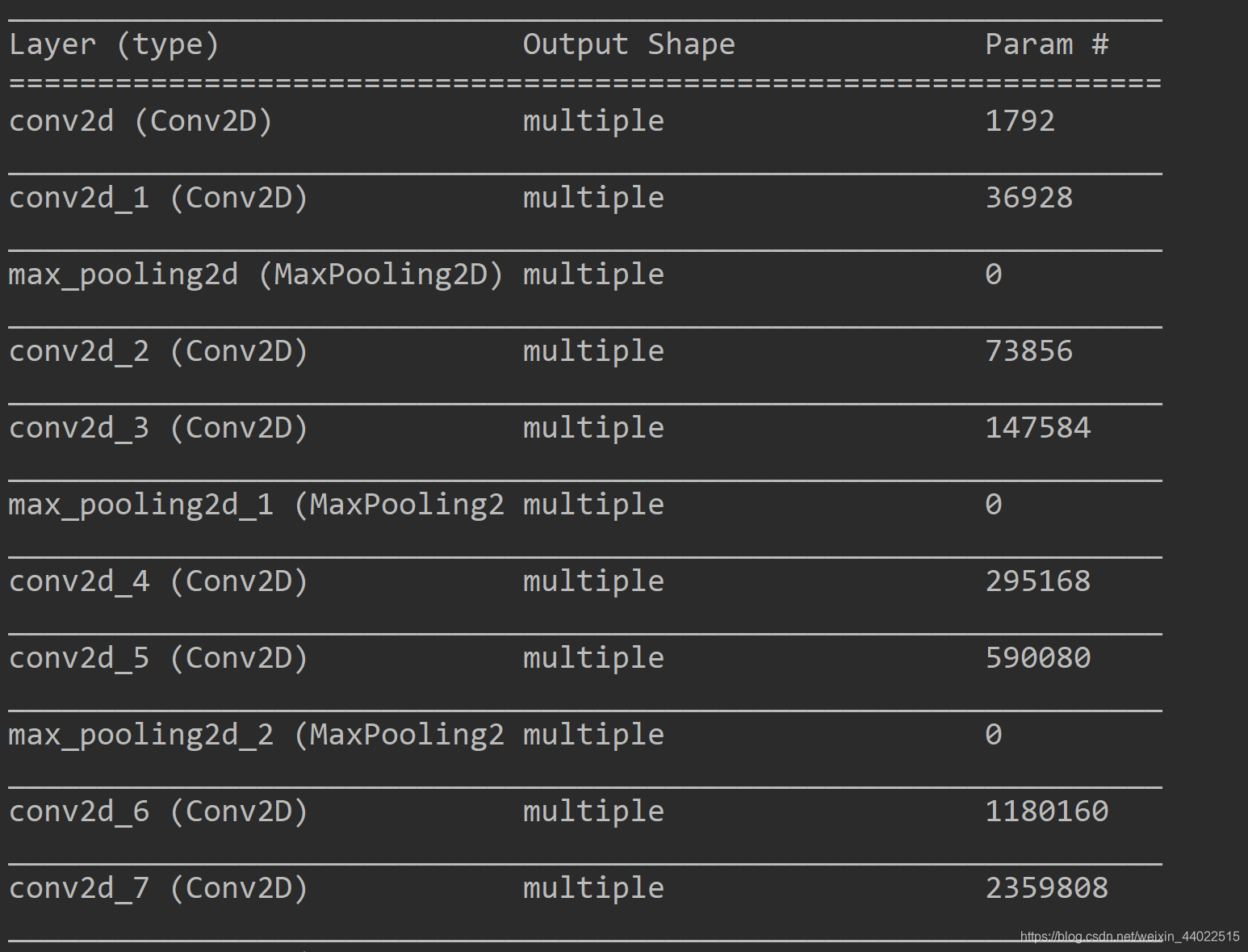
全连接层参数:














 624
624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









