







(回环检测)Scan Context Egocentric Spatial Descriptor for Place Recognition within 3D Point Cloud Map
摘要
与用于视觉场景的各种特征检测器和描述子相比,使用结构信息描述一个场景的文章相对较少。 同时定位和建图 (SLAM) 的最新进展提供了环境的稠密 3D 地图,并且定位是由不同的传感器提出的。 针对基于结构信息的全局定位,我们提出了 Scan Context,这是一种来自 3D 光探测和激光雷达扫描的基于非直方图的全局描述子。 与以前的方法不同,所提出的方法直接从传感器中记录空间的 3D 结构,而不依赖于直方图或先验的训练。 此外,该方法提出了使用相似度分数来计算两个 Scan Context 之间的距离,并且还提出了两阶段搜索算法来有效地检测闭环。Scan Context 及其搜索算法使闭环检测对LiDAR视角变化具有不变性,因此可以在重新访问同一个地点和拐角等地方检测到闭环。 Scan Context 性能已经通过 3D LiDAR 扫描的各种基准数据集进行了评估,并且所提出的方法显示出充分改进的性能。
引言
在许多机器人应用中,位置识别是重要的问题。 特别是对于 SLAM,这种识别为闭环提供了候选者,这对于纠正漂移误差和构建全局一致的地图至关重要 [1]。 虽然闭环对机器人导航至关重要,但错误的匹配可能是灾难性的,需要仔细匹配。 视觉识别随着相机传感器的广泛使用而流行,然而,由于光照变化和短期(例如,移动的物体)或长期(例如,季节)的变化,它本质上是困难的。 类似的环境可能出现在不同的位置,通常会导致感知混叠。 因此,最近的文献通过检查表示 [2] 和弹性后端 [3] 来关注稳健的位置识别。
与这些视觉传感器不同,LiDAR 最近因其对感知变化的强不变性而受到关注。 早期,传统的局部关键点描述子 [4, 5, 6, 7] 最初是为计算机视觉中的 3D 模型设计的,尽管它们容易受到噪声的影响,但已被用于位置识别。 基于激光雷达的位置识别方法已在机器人文献中广泛提出 [8, 9, 10]。 这些工作侧重于从结构信息(例如点云)中以局部 [8] 和全局方式 [10] 开发描述子。
现有的基于 LiDAR 的位置识别方法一直试图克服两个问题。 首先,无论视角如何变化,都需要描述子来实现旋转不变性。 其次,噪声处理是这些空间描述子的另一个主要问题,因为点云的分辨率随距离而变化,是有噪声的。 现有方法主要使用直方图[9,11,12]来解决上述两个问题。 然而,由于直方图方法只提供场景的随机索引,描述场景的详细结构并不直接。 这种限制使得描述子对于位置识别问题的可识别性降低,从而导致潜在的误匹配。
在本文中,我们提出了 Scan Context,这是一种具有匹配算法的新型空间描述子,专门针对使用单次 3D 扫描的户外位置识别。 我们的表示将 3D 扫描中的整个点云编码为矩阵(图 1)。
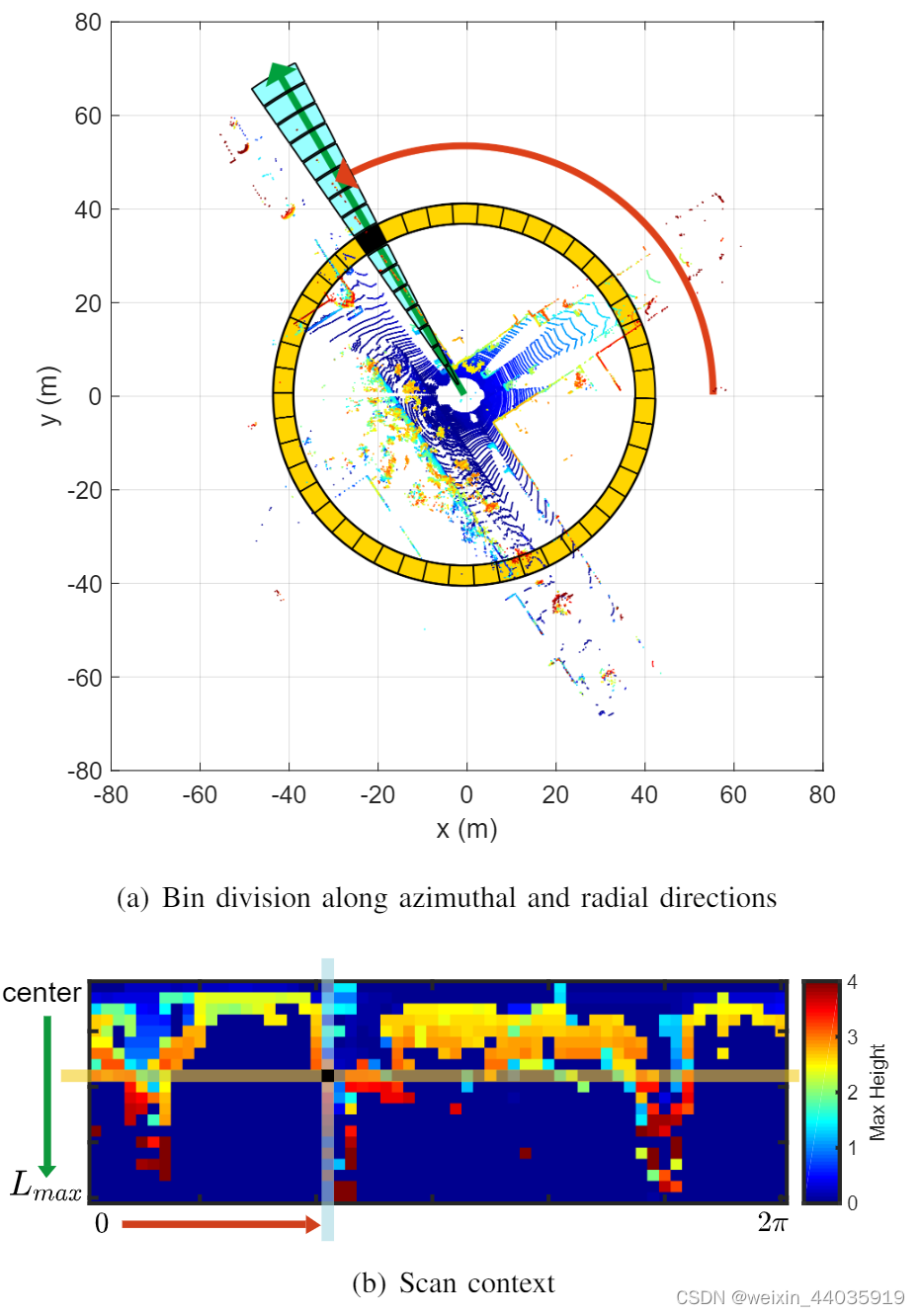
图1
两步Scan Context 创建。 使用来自 3D 扫描的点云的顶视图 (a),我们将地面区域划分为bin,根据方位角(在 LiDAR 框架内从 0 到 2π)和径向(从中心到最大感应范围)进行划分方向。 我们将黄色区域称为一个环,将青色区域称为一个扇区,将黑色填充区域称为一个 bin。Scan Context是(b)中的矩阵,它明确地保留了点云的绝对几何结构。 (a) 中描述的环和扇区在 (b) 中分别由相同颜色的列和行表示。 从位于每个 bin 中的点中提取的代表值用作 (b) 的对应像素值。 在本文中,我们使用 bin 中点的最大高度。
所提出的表示描述了以自我为中心的 2.5D 信息。 该方法的贡献点是:
-
高效的 bin 编码功能。 与现有的点云描述子 [7, 10] 不同,所提出的方法不需要计算 bin 中的点数,而是提出了一种更有效的用于位置识别的 bin 编码函数。 这种编码对点云的密度和法线具有不变性。
-
保留点云的内部结构。 如图 1 所示,矩阵的每个元素值仅由属于 bin 的点云确定。 因此,与将点的相对几何描述为直方图并丢失点的绝对位置信息的[9]不同,我们的方法通过有意避免使用直方图来保留点云的绝对内部结构。 这提高了判别能力,还可以在计算距离时将被查询扫描的视角对准候选扫描(在我们的实验中, 6 ° 6\degree 6°方位角分辨率)。 因此,也可以通过使用Scan Context来检测反向闭环。
-
有效的两相匹配算法。 为了获得可行的搜索时间,我们为第一个最近邻搜索提供了一个旋转不变的子描述子,并将其与成对相似度评分进行分层合并,从而避免搜索所有数据库进行闭环检测。
-
对照其他最先进的空间描述子进行全面对比验证。 与其他现有的全局点云描述子相比,例如 M2DP [8]、形状函数集合 (ESF) [11] 和 Z 投影 [12],所提出的方法具有实质性的改进。
相关工作
移动机器人的位置识别方法可以分为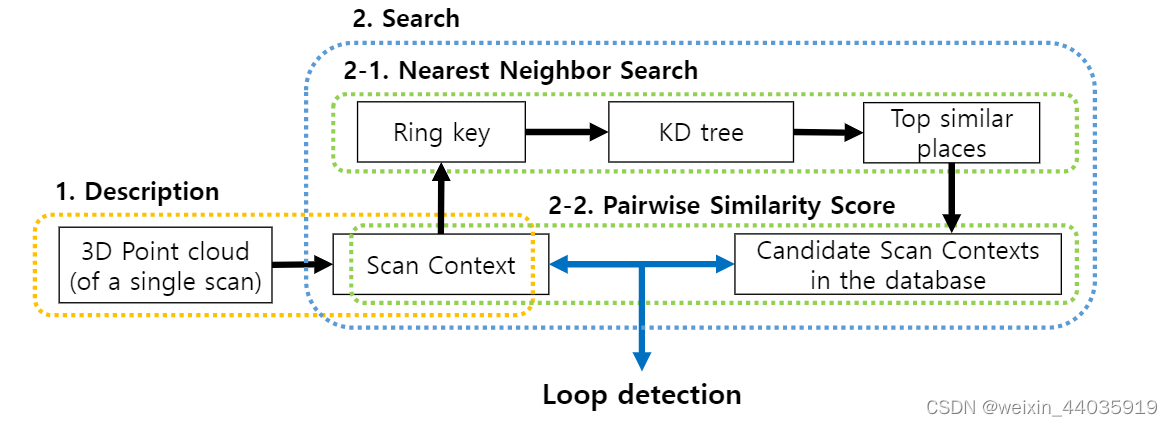
基于视觉和基于激光雷达的方法。 视觉方法已普遍用于 SLAM 文献中的位置识别 [13, 14, 15]。 FAB-MAP [13] 通过学习视觉词袋的生成模型,使用概率方法提高了鲁棒性。 然而,视觉表示具有局限性,例如易受光照条件变化的影响[16]。 已经提出了几种方法来克服这些问题。 SeqSLAM [17] 提出了基于道路的方法,并显示出比 FAB-MAP 有很大改进的性能。 SRAL [2] 融合了几种不同的表示,例如颜色、GIST [18] 和 HOG [19],用于长期视觉位置识别。
LiDAR 对上述这些感知变化具有很强的鲁棒性。 基于 LiDAR 的方法被进一步分类为局部和全局描述子。 局部描述子,例如 PFH [4]、SHOT [5]、shape contex [7] 或spin image [6],首先找到一个关键点,将附近的点分成 bin,并将周围 bin 的模式编码为直方图。Steder等人提出了使用点特征和格式塔描述子[20]以词袋方式进行位置识别的方法[8]。
然而,这些关键点描述子显示出局限性,因为它们最初是为 3D 模型部分匹配而不是为位置识别而设计的。 例如,与 3D 模型不同,3D 扫描(例如,来自 VLP-16)中的点云密度会随着与传感器的距离而变化。 此外,由于现实世界中的非结构化对象(例如树),点的法线比模型噪声更大。 因此,局部方法通常需要关键点的法线,因此不太适合户外的位置识别。
全局描述子不包括关键点检测阶段。 GLARE [9] 及其变体 [21, 22] 将点之间的几何关系编码为直方图,以代替搜索关键点和提取描述子。 ESF [11] 使用了由形状函数制成的直方图的串联。 Muhammad 和 Lacroix 提出了 Zprojection [12],它是法向量的直方图,以及具有两个距离函数的双阈值方案。 Heet等人提出了 M2DP [10],它将扫描的整个 3D 点云投影到多个 2D 平面并提取 192 维紧凑的全局表示。 M2DP 表现出比现有点云描述子更高的性能以及对噪声和分辨率变化的鲁棒性。 如本文所述,全局描述子通常使用直方图。 最近,SegMatch [23] 引入了一种基于分段的匹配算法。 这是一种高级感知,但需要一个训练步骤,并且需要在全局参考框架中表示点。
在本文中,我们提出了一种新的位置描述符,称为Scan Context,它将 3D 扫描的点云编码为矩阵。 Scan Context可以被认为是用于定位 3D LiDAR 扫描数据的位置识别的Shape Context [7] 的扩展。 具体来说,Scan Context包含三个组成部分:在每个 bin 中保留点云的绝对位置信息的表示、高效的 bin 编码函数和两步搜索算法。
用于位置识别的Scan Context
在本节中,我们描述了给定来自 3D 扫描的点云的Scan Context创建,并提出了一种计算两个Scan Context之间距离。 接下来,介绍两步搜索过程。 使用Scan Context进行位置识别的整体流程如图 2 所示。Scan Context的创建和验证也可以在 scancontext.mp4 中找到。

图2
算法概述。 首先,将单次 3D 扫描中的点云编码到Scan Context中。 然后,从Scan Context中对 Nr(环数)维向量进行编码,并用于检索最近的候选者以及 KD 树的构造。 最后,将检索到的候选与查询Scan Context进行比较。 满足接受阈值并最接近查询的候选被认为是闭环。
A.Scan Context
我们为户外位置识别定义了一个名为 Scan Context 的场景描述符子。 Scan Context的关键思想受到 Belongie 等人提出的 Shape Context [7] 的启发,它将局部关键点周围的点云的几何形状编码为图像。 虽然他们的方法只是简单地计算点的数量来总结点的分布,但我们的方法与他们的不同之处在于我们使用每个 bin 中点云的最大高度。 使用高度的原因是为了有效地总结周围结构的垂直形状,而不需要大量的计算来分析点云的特征。 此外,最大高度表示从传感器可以看到周围结构的哪一部分。 这种以自我为中心的可见性在城市设计文献中一直是一个众所周知的概念,用于分析一个地方的身份[24, 25]。
与Shape Context [7] 类似,我们首先将 3D 扫描划分为传感器坐标中的方位角和径向 bin,但采用等间距的方式,如图 1(a) 所示。 扫描的中心充当全局关键点,因此我们将Scan Context称为以自我为中心的位置描述子。 N s N_s Ns 和 N r N_r Nr 分别是扇区和环的数量。 也就是说,如果我们将 LiDAR 传感器的最大感应范围设置为 L m a x L_{max} Lmax,则环之间的径向间隙为 L m a x N r \frac{L_{max}}{N_r} NrLmax ,扇形的中心角等于 2 π N s \frac{2 \pi}{N_s} Ns2π。 在本文中,我们使用 N s = 60 N_s = 60 Ns=60 和 N r = 20 N_r = 20 Nr=20。
因此,生成Scan Context的第一个过程是将 3D 扫描的整个点划分为相互分离的点云,如图 1(a) 所示。
P
i
j
\mathcal{P}_{ij}
Pij是属于第
i
i
i 个环和第
j
j
j 个扇区重叠的 bin 的点集。 符号
[
N
s
]
[N_s]
[Ns] 等于
{
1
,
2
,
.
.
.
,
N
s
−
1
,
N
s
}
\{1,2,...,N_{s-1},N_s\}
{1,2,...,Ns−1,Ns}。 因此,分区在数学上是
P
=
⋃
i
∈
[
N
r
]
,
j
∈
[
N
s
]
P
i
j
(1)
\mathcal{P}=\bigcup_{i \in\left[N_{r}\right], j \in\left[N_{s}\right]} \mathcal{P}_{i j}\tag{1}
P=i∈[Nr],j∈[Ns]⋃Pij(1)
因为点云是按固定间隔划分的,所以远离传感器的 bin 的物理面积比近的 bin 更大。 但是,两者都被同等地编码到Scan Context的单个像素中。 因此,Scan Context补偿了由于远点稀疏导致的信息量不足,并将附近的动态物体视为稀疏噪声。
在点云分区之后,使用该 bin 中的点云为每个 bin 分配一个实数值:
ϕ
:
P
i
j
→
R
(2)
\phi: \mathcal{P}_{i j} \rightarrow \mathbb{R}\tag{2}
ϕ:Pij→R(2)
我们使用最大高度,其灵感来自城市能见度分析 [24, 25]。 因此,bin 编码函数为
ϕ
(
P
i
j
)
=
max
p
∈
P
i
j
z
(
p
)
(3)
\phi\left(\mathcal{P}_{i j}\right)=\max _{\mathbf{p} \in \mathcal{P}_{i j}} z(\mathbf{p})\tag{3}
ϕ(Pij)=p∈Pijmaxz(p)(3)
其中
z
(
⋅
)
z(\cdot)
z(⋅) 是返回点
p
\mathbf{p}
p 的
z
z
z 坐标值的函数。 我们为空bin分配零。 例如,如图 1(b) 所示,Scan Context中的蓝色像素意味着与其 bin 对应的空间是空闲的,或者由于遮挡而未观察到。
通过上述过程,最终将Scan Context 表示为
N
r
×
N
s
N_r \times N_s
Nr×Ns 矩阵
I
=
(
a
i
j
)
∈
R
N
r
×
N
s
,
a
i
j
=
ϕ
(
P
i
j
)
(4)
I=\left(a_{i j}\right) \in \mathbb{R}^{N_{r} \times N_{s}}, a_{i j}=\phi\left(\mathcal{P}_{i j}\right)\tag{4}
I=(aij)∈RNr×Ns,aij=ϕ(Pij)(4)
为了对平移进行稳健的识别,我们通过root shifting来增强Scan Context。 通过这样做,使得在轻微运动扰动下从原始扫描中获取各种Scan Context变得可行。 在重新访问到过的地方时,单个Scan Context可能对平移运动下扫描的中心位置敏感。 例如,当在不同的车道中重新访问相同的位置时,Scan Context的行顺序可能不会被保留。 为了克服这种情况,我们根据车道水平间隔将原始点云转换为
N
t
r
a
n
s
N_{trans}
Ntrans 个邻居(本文中使用
N
t
r
a
n
s
=
8
N_{trans}= 8
Ntrans=8),并将从这些root shifting的点云获得的Scan Context存储在一起。 我们假设即使在实际移动的位置也能获得类似的点云,这是有效的,除了少数情况下,例如突然出现新空间的交叉路口接入点。
B.Scan Context之间的相似度得分
给定一个Scan Context对,我们需要一个距离度量来衡量两个地方的相似性。
I
q
I^{q}
Iq 和
I
c
I^{c}
Ic 分别是从查询点云和候选点云获取的Scan Context。 它们以列方式进行比较。 也就是说,距离是同一索引处的各列之间的距离之和。 余弦距离用于计算相同索引处的两个列向量
c
j
q
c_j^q
cjq和
c
j
c
c_j^c
cjc之间的距离。 此外,我们将总和除以列数
N
s
N_s
Ns 以进行归一化。 因此,距离函数为
d
(
I
q
,
I
c
)
=
1
N
s
∑
j
=
1
N
s
(
1
−
c
j
q
⋅
c
j
c
∥
c
j
q
∥
∥
c
j
c
∥
)
(5)
d\left(I^{q}, I^{c}\right)=\frac{1}{N_{s}} \sum_{j=1}^{N_{s}}\left(1-\frac{c_{j}^{q} \cdot c_{j}^{c}}{\left\|c_{j}^{q}\right\|\left\|c_{j}^{c}\right\|}\right)\tag{5}
d(Iq,Ic)=Ns1j=1∑Ns(1−∥∥cjq∥∥∥∥cjc∥∥cjq⋅cjc)(5)
通过考虑整个扇区的一致性,逐列比较对于动态对象特别有效。 然而,即使在同一个地方,候选Scan Context的列也可能会移动,因为 LiDAR 的视角会随着不同的地方而变化(例如,在相反的方向或角落重新访问同一个地方)。 图 3 说明了这种情况。
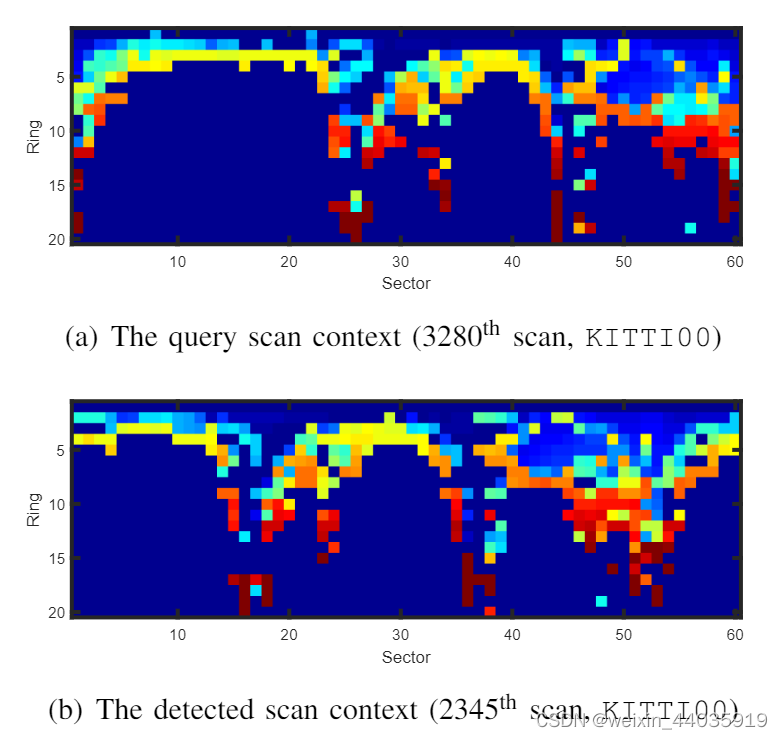
图3
一段时间间隔的同一地点Scan Context的示例。 重新访问时传感器视角的变化导致Scan Context的列移位,如 (a) 所示。 但是,这两个矩阵包含相似的形状并显示相同的行顺序。
由于Scan Context是依赖于传感器位置的表示,因此行顺序始终是一致的。 但是,如果 LiDAR 传感器相对于全局坐标的坐标发生变化,则列顺序可能会有所不同。
为了缓解这个问题,我们计算所有可能的列移位后的Scan Context的距离并找到最小距离。
I
n
c
I_{n}^{c}
Inc 是一个Scan Context,它的
n
n
n 列从原始列
I
c
I^{c}
Ic偏移过来。 这与以
2
π
N
s
\frac{2 \pi}{N_s}
Ns2π 分辨率粗略对齐两个点云以获取旋转分量中的偏航角的任务相同。 然后我们确定最佳对齐的列移位次数(7)和对应的距离(6):
D
(
I
q
,
I
c
)
=
min
n
∈
[
N
s
]
d
(
I
q
,
I
n
c
)
(6)
D\left(I^{q}, I^{c}\right)=\min _{n \in\left[N_{s}\right]} d\left(I^{q}, I_{n}^{c}\right)\tag{6}
D(Iq,Ic)=n∈[Ns]mind(Iq,Inc)(6)
n
∗
=
argmin
n
∈
[
N
s
]
d
(
I
q
,
I
n
c
)
.
(7)
n^{*}=\underset{n \in\left[N_{s}\right]}{\operatorname{argmin}} d\left(I^{q}, I_{n}^{c}\right) .\tag{7}
n∗=n∈[Ns]argmind(Iq,Inc).(7)
请注意,这个额外的移位信息可以作为进一步定位细化的良好初始值,例如迭代最近点 (ICP),如第 IV-C 节所示。
C.两阶段的搜索算法
在位置识别中搜索时,有三个主要的典型工作流:成对相似度评分、最近邻搜索和稀疏优化 [26]。 我们的搜索算法将成对评分和最近邻搜索分层融合,以获得可接受的搜索时间。
由于我们在 (6) 中的距离计算比其他全局描述子(如 [12, 10])更加耗时,因此我们通过引入ring key提供了一种两阶段分层搜索算法。 Ring key 是一个旋转不变的描述子,它是从Scan Context中提取的。 Scan Context的每一行
r
r
r 通过环编码函数
ψ
\psi
ψ 编码为一个实数值。 向量
k
\mathbf{k}
k 的第一个元素来自距离传感器最近的环,随后的元素按顺序来自下一个环,如图 4 所示。

图4
用于快速搜索的ring key生成。
因此,ring key成为一个
N
r
N_r
Nr维向量,如 (8):
k
=
(
ψ
(
r
1
)
,
…
,
ψ
(
r
N
r
)
)
,
where
ψ
:
r
i
→
R
(8)
\mathbf{k}=\left(\psi\left(r_{1}\right), \ldots, \psi\left(r_{N_{r}}\right)\right), \text { where } \psi: r_{i} \rightarrow \mathbb{R}\tag{8}
k=(ψ(r1),…,ψ(rNr)), where ψ:ri→R(8)
我们使用的环编码函数
ψ
\psi
ψ 是使用
L
0
L_0
L0 范数表示的环的占用率:
ψ
(
r
i
)
=
∥
r
i
∥
0
N
s
(9)
\psi\left(r_{i}\right)=\frac{\left\|r_{i}\right\|_{0}}{N_{s}}\tag{9}
ψ(ri)=Ns∥ri∥0(9)
由于占用率与视角无关,因此环键实现了旋转不变性。
虽然比Scan Context信息量少,但ring key可以快速搜索以找到可能的闭环候选者。 向量
k
\mathbf{k}
k 用作构建 KD 树的key。 同时,查询的ring key用于查找相似的key及其对应的扫描索引。 将被检索到的最相似key的数量由用户确定。 这些恒定数量的候选Scan Context通过使用距离 (6) 与查询Scan Context进行比较。 最接近的满足给定阈值的查询的候选者被视为重新访问同一个地点:
c
∗
=
argmin
c
k
∈
C
D
(
I
q
,
I
c
k
)
, s.t
D
<
τ
(10)
c^{*}=\underset{c_{k} \in \mathcal{C}}{\operatorname{argmin}} D\left(I^{q}, I^{c_{k}}\right) \text {, s.t } D<\tau\tag{10}
c∗=ck∈CargminD(Iq,Ick), s.t D<τ(10)
其中
C
\mathcal{C}
C 是从 KD 树中提取的一组候选索引,
τ
\tau
τ 是给定的阈值,
c
∗
c^{*}
c∗ 是被确定为闭环的位置的索引。
实验评估
在本节中,我们的算法在各种数据集和其他最先进的算法进行评估。 由于Scan Context 是全局描述子,因此我们将表示的性能与使用 3D 点云的其他三个全局表示进行比较:M2DP [10]、Z-projection [12] 和 ESF [11]。 我们在用 C++ 实现的点云库 (PCL) 中使用 ESF,以及作者 He 等人的 M2DP 的 Matlab 代码,并自己在 Matlab 上实现 Z-projection。 所有实验均在具有 3.40GHz 的 Intel i7-6700 CPU 和 16GB 内存的同一系统上进行。
A.数据集和实验设置
我们使用 KITTI 数据集 [27]、NCLT 数据集 [28] 和复杂城市激光雷达数据集 [29] 来验证我们的方法。 这三个数据集的选择考虑了多样性,例如 3D LiDAR 传感器的类型(例如,线数、传感器安装类型,例如环绕和倾斜)和闭环的类型(例如,发生在相同方向或相反方向 方向称为反向闭环)。 每个数据集的特征总结在表 I 中。术语节点表示单个采样位置。

表I
用于验证的选定数据集列表
-
KITTI数据集:
在具有位姿ground truth的11个序列中(从00到10),选择闭环出现次数最多的前四个序列:00、02、05和08。序列08只有反向闭环,其他序列有相同方向的闭环事件。 KITTI 数据集的扫描来自位于汽车中央的 64 射线激光雷达(Velodyne HDL-64E)。 由于 KITTI 数据集提供了带有索引的扫描,我们直接将每个 bin 文件用作一个节点。
-
NCLT数据集:
NCLT 数据集提供沿相似路线的不同日期的长期测量值。 NCLT 数据集的扫描来自移动平台的 32 线 LiDAR (Velodyne HDL-32E)。 考虑到闭环出现的次数和季节多样性,选择了四个序列。 在本实验中,扫描以等距 (2 m) 的间隔进行采样,为方便起见,仅将那些采样的扫描用作节点。
-
复杂城市激光雷达数据集:
复杂城市 LiDAR 数据集包括从住宅区到大都市区的各种复杂城市环境。 考虑到[29]提供的复杂性和广泛的道路速率,选择了四个序列。 本实验使用序列 04、04_0 和 04_1 的三个子路线。 为方便起见,扫描以 3 m 的间隔进行采样。 有趣的事实是,该数据集使用两个倾斜的 LiDAR (Velodyne VLP-16 PUCK) 进行城市建图。 因此,该数据集的单次扫描能够测量结构的较高部分,但没有 360° 环绕视图。 为了在各个方向上包含更多信息,我们合并了来自左右倾斜 LiDAR 的点云,并将它们用作单次扫描以创建Scan Context。
如果查询和被匹配节点之间的地面实况姿态距离小于 4 m,则认为检测为真阳性。 总共有 50 个先前相邻的节点被排除在搜索之外。 Scan Context的实验是使用 KD 树中的 10 个候选和 50 个候选进行的,因此每种方法分别称为Scan Context-10 和Scan Context-50。 与仅与从 KD 树中提取的恒定数量的候选对象进行比较的Scan Context不同,其他方法(M2DP、ESF 和 Z-projection)将查询描述与数据库中的所有内容进行比较。 在本文中,我们将Scan Context的参数设置为 N s = 60 、 N r = 20 N_s = 60、N_r = 20 Ns=60、Nr=20 和 L m a x = 80 m L_{max} = 80 m Lmax=80m。 也就是说,每个扇区的分辨率为 6 ° 6\degree 6°,每个环的间隙为 4 m 4 m 4m。 Z-projection 的 bin 数量设置为 100。我们使用 M2DP 和 ESF 可用代码的默认参数。 为了计算效率,我们使用 0.6 m 3 0.6m^{3} 0.6m3 网格对Scan Context和 M2DP 下采样点云,因为 He 等人。 [10] 报道 M2DP 对下采样具有鲁棒性,而 Z-projection和 ESF 使用原始点云而没有下采样,因为它们容易受到低密度的影响。 我们在实验中只改变了一个接受阈值。
B.准确率-召回率评估
使用图 5 中的准确率-召回率曲线分析Scan Contexts的性能。基于直方图的方法ESF 和 Z-projection在所有数据集上都报告了较差的性能。 这些方法依赖于直方图,只有当可见空间的结构有很大不同时才能区分位置。 与这些基于直方图的方法不同,我们的方法为整个数据序列提供了有意义的性能。 总体而言,Scan Context-50 总是显示出比 Scan Context-10 更好的性能。 Scan Context的性能取决于 KD 树中候选者的数量。 由于ring key比Scan Context信息量少,如果有许多相似的结构,检查少量(例如,超过 3000 个节点中的 10 个)候选者很容易失败。
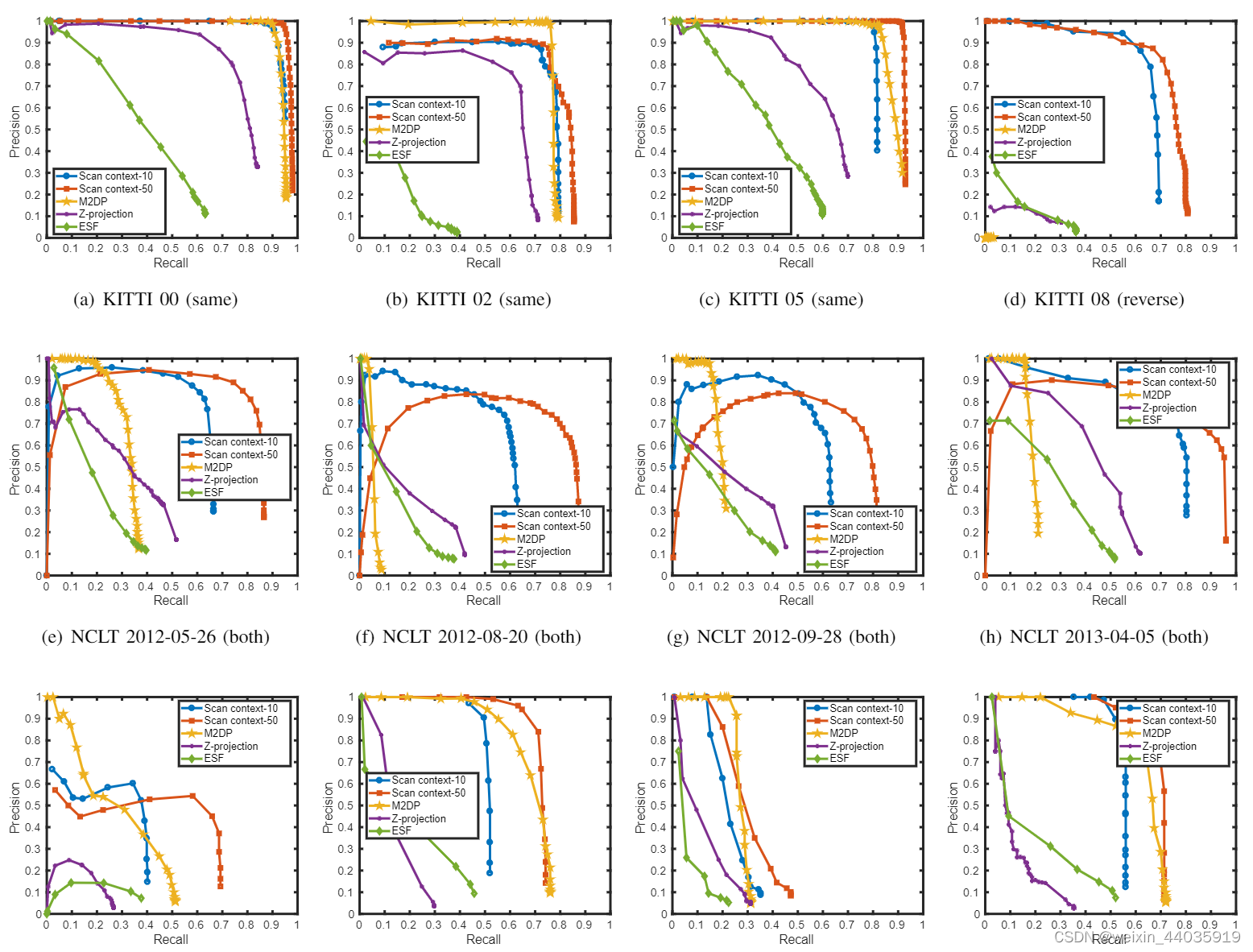
图5
评估数据集的准确率-召回率曲线。 重新访问同一地方期间的方向(same:同向,both:反向)显示在括号中。
当应用户外城市数据集时,所提出的方法优于其他方法。 这是因为使用垂直高度的动机来自城市分析。 然而,当应用于垂直高度变化不太显着的室内环境时,性能受到限制。 当应用于 NCLT 数据集时,Scan Context在准确率和召回率(每个图的左侧)方面表现出低性能,因为 NCLT 数据集的轨迹包含狭窄的室内环境,只有很小的区域可用。
使用 复杂城市激光雷达数据集数据集进行评估时,所有方法都显示出比KITTI数据集更差的性能。 特别是,Urban 02 为所有方法提供了最具挑战性的案例,因为与 KITTI数据集相比,该序列具有狭窄的道路和具有相似高度和矩形形状的重复结构。 图 6 给出了来自这个具有挑战性的 Urban 02 的Scan Context示例。
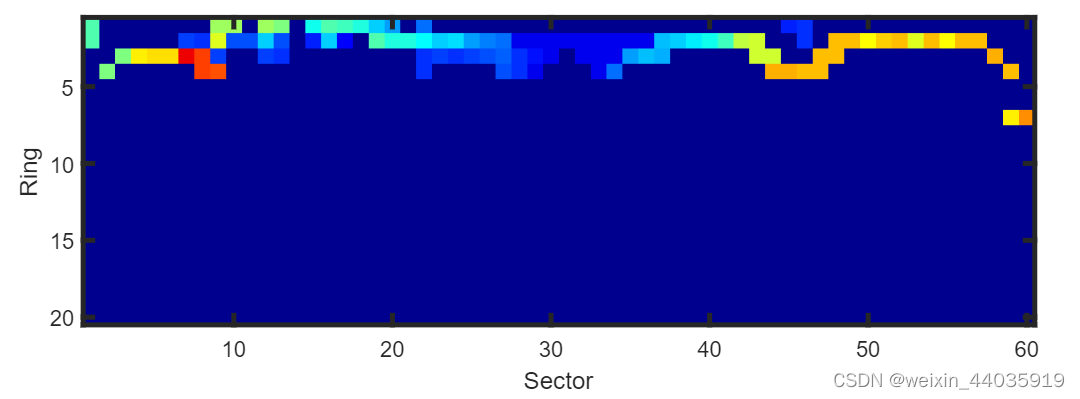
图6
从复杂城市 LiDAR 数据集序列 02 中捕获的一个具有挑战性的示例。道路在各个方向都非常狭窄,以至于可用信息量太少。
尽管在这个具有挑战性的数据集中报告了一定程度的性能下降,但所提出的方法仍然优于其他现有方法。
通过使用基于视图对齐的匹配,即使对于反向重访,所提出的描述子也呈现出很强的旋转不变性。 例如,M2DP 未能检测到反向闭环。 在这些数据集中,KITTI 08 只有反向闭环,并且所提出的方法大大优于其他方法。 在具有部分反向闭环的 NCLT 序列中也观察到这种现象。 因此,在 NCLT 序列中,M2DP 在非常低的召回率下表现出了高精度,因为正确检测到正向闭环。 然而,由于错过了反向闭环,曲线的斜率迅速减小。
C.定位精度
本文提出的方法也可用于为其他定位方法(如ICP)提供鲁棒的初始估计。 我们使用具有反向闭环的 KITTI 08 进行了实验。 ICP 是点对点执行的,无需下采样。 图 7 描述了初始化和未初始化的 ICP 结果示例。
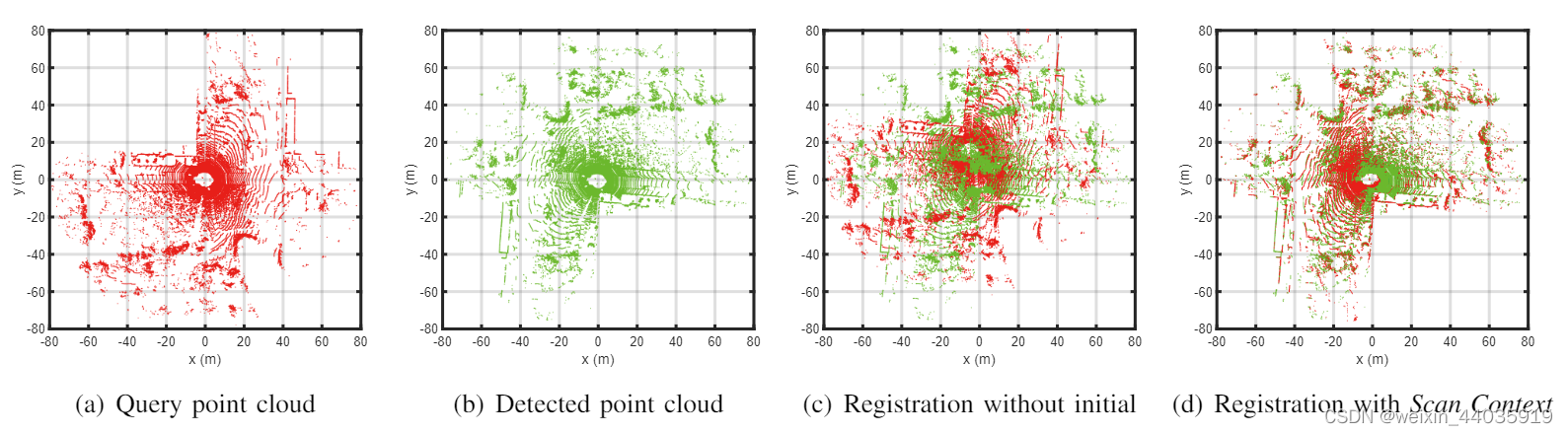
图7
来自 KITTI 08 的点对点 ICP 结果示例。查询和检测到的点云分别来自第 1785 次和第 109 次扫描。 LiDAR 传感器坐标系下表示点云的坐标。 对两个Scan Context之间的相似性进行评分提供了粗略的偏航旋转,它作为初始估计来指导更精细的定位(即 ICP)。 在这种反向闭环的情况下,如果没有这样的初始估计,匹配很容易失败。 相比之下,即使是这种非结构化环境也可以使用从Scan Context中获得的初始估计进行匹配。
对于这个序列,我们进一步验证了计算时间和均方根误差 (RMSE) 方面的改进。 图 8 显示了使用 (7) 进行初始偏航旋转估计的改进性能。
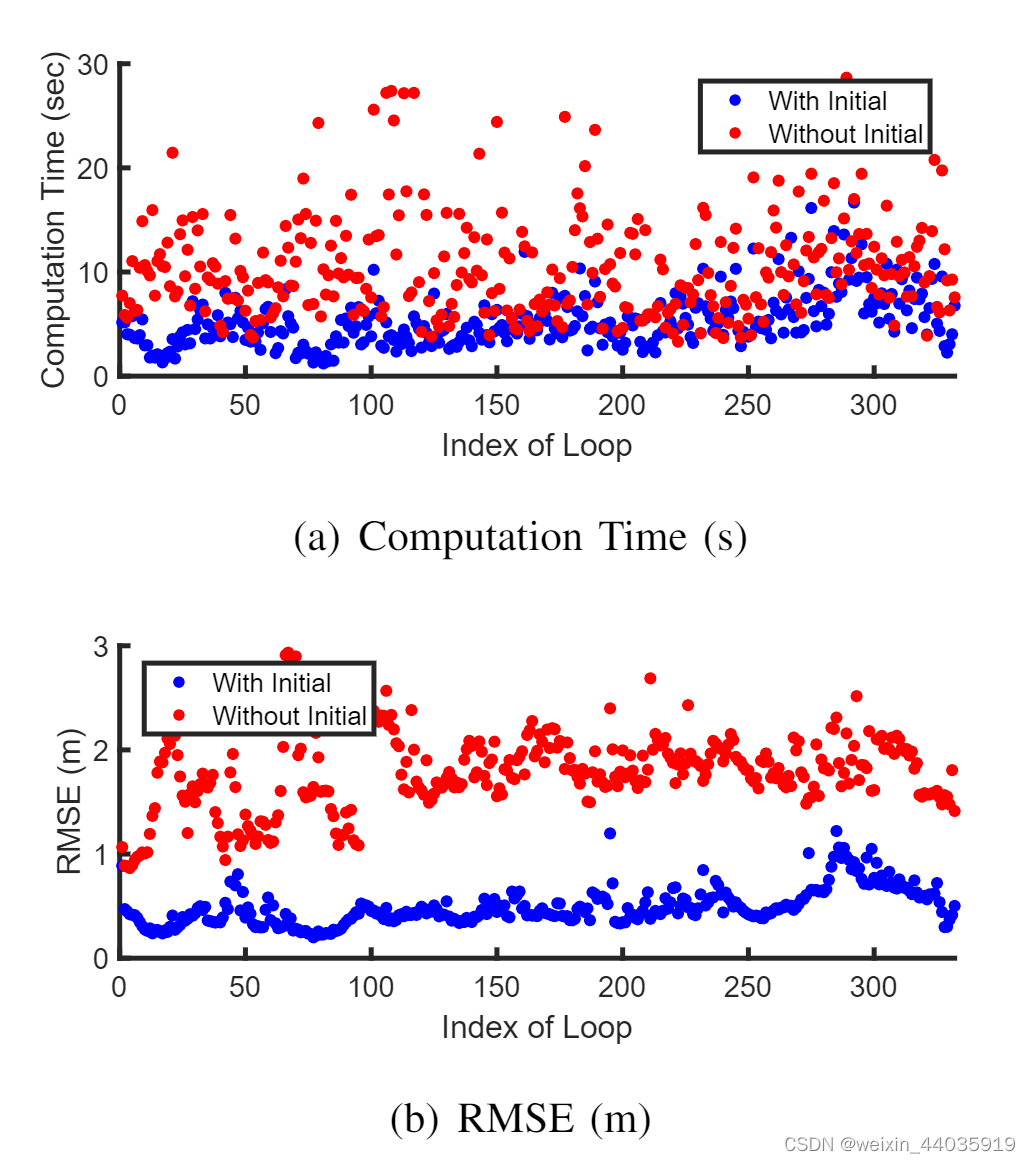
图8
计算有和没有初始值下的时间和 RMSE 。 x 轴代表 KITTI 08 的真实闭环事件的索引。蓝色和红色分别表示可用和不可用的初始猜测。
D.计算复杂度
在 KITTI 00 上评估的平均计算时间在表 II 中给出。 所有方法都使用
0.6
m
3
0.6m^3
0.6m3 网格的点云下采样。 在这些实验中,Scan Context创建需要更长的时间,因为我们采用了Scan Context增强,这是非强制性的。 因此,创建单个Scan Context所需的时间(0.0143 秒,Scan Context增强除外)比其他方法要短。 Scan Context的搜索时间包括KD树的创建和距离的计算。 Scan Context可能需要比其他全局描述子更长的搜索时间,但在合理的范围内(Matlab 上为 2-5 Hz)。
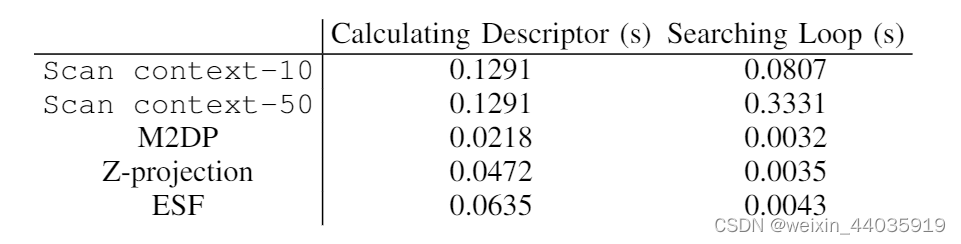
表II
KITTI00 的平均时间成本。
结论
在本文中,我们提出了一个空间描述子,Scan Context,将一个地方概括为一个矩阵,明确描述以自我为中心的环境的 2.5D 结构信息。 与使用点云的现有全局描述子相比,Scan Context在各种数据集上显示出更高的闭环检测性能。
在未来的工作中,我们计划通过引入额外的层来扩展Scan Context。 也就是说,其他 bin 编码函数(例如 bin 的语义信息)可用于提高性能,即使对于具有高度重复结构的数据集(如复杂城市 LiDAR 数据集)也是如此。

















 389
389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









