







Scan Context: Egocentric Spatial Descriptorfor Place Recognition within 3D Point Cloud Map
摘要
与用于视觉场景的各种特征检测器和描述器相比,使用结构信息描述一个场景的报道相对较少。同步定位和建图(SLAM)的最新进展提供了环境的稠密3D地图,并且定位是由不同的传感器提出的。对于基于结构信息的全局定位,我们提出了一种来自三维光探测和激光雷达扫描的基于非直方图的全局描述子——Scan Context。与以前报道的方法不同,提出的方法直接从传感器记录可视空间的三维结构,而不依赖于直方或先验的训练。此外,该方法提出使用相似性分数来计算两个Scan Context之间的距离,并且还提出了两阶段搜索算法来有效地检测闭环。Scan Context及其搜索算法使闭环检测对LiDAR视角变化具有不变性,从而可以在重新访问同一个地点和拐角等地方检测到闭环。Scan Context性能已经通过3D LiDAR扫描的各种基准数据集进行了评估,并且所提出的方法显示出足够改进的性能。
引言
在许多机器人应用中,位置识别是一个重要的问题。特别是对于SLAM,这种识别为闭环检测提供了候选项,这对于修正漂移误差和建立全局一致的地图是必不可少的[1]。虽然闭环对于机器人导航至关重要,但错误的配准可能是灾难性的,需要进行仔细的配准。视觉识别随着相机的广泛使用而流行,然而,由于光照变化和短期(例如,移动物体)或长期(例如,季节)变化,视觉识别有其固有的技术困难。相似的环境可能出现在不同的位置,这往往会造成感知混淆。因此,最近的文献集中在通过检查表示[2]和弹性后端[3]的鲁棒位置识别。
与这些视觉传感器不同,激光雷达由于对感知变化具有很强的不变性,最近引起了人们的注意。在早期,传统的局部关键点描述子[4,5,6,7]最初是为计算机视觉中的3D模型设计的,尽管它们容易受到噪声的影响,但已经被用于位置识别。基于激光雷达的位置识别方法已在机器人文献中广泛提出[8,9,10]。这些工作集中于从结构信息(例如点云)中以局部方式[8]和全局方式[10]开发描述子。
现有的基于激光雷达的位置识别方法一直在努力克服两个问题。首先,无论视角如何变化,描述子都需要实现旋转不变性。其次,噪声处理是这些空间描述子的另一个主要问题,因为点云的分辨率随距离变化,通常是有噪声的。现有的方法主要使用直方图[9,11,12]来解决上述两个问题。然而,由于直方图方法只提供场景的随机索引,描述场景的详细结构并不直接。这种限制使得描述子对于位置识别问题难以识别,从而导致潜在的误匹配。
在本文中,我们提出了一种新的空间描述子——Scan Context,它带有一种匹配算法,专门针对使用单次三维扫描的户外位置识别。我们的表示将三维扫描中的整个点云编码成矩阵(图1)。
所提出的表示描述了以自我为中心的2.5D信息。我们提出的方法的贡献点为:
- 高效的bin编码功能。与现有的点云描述子[7,10]不同,所提出的方法不需要计算bin中的点数,而是提出了一种更有效的bin编码函数用于位置识别。这种编码呈现出对点云的密度和法线的不变性。
- 保留了点云的内部结构。如上图所示,矩阵的每个元素值仅由属于该bin的点云确定。因此,与将点的相对几何形状描述为直方图并丢失点的绝对位置信息的[9]不同,我们的方法通过有意避免使用直方图来保留点云的绝对内部结构。这提高了辨别能力,并且还能够在计算距离时将被查询扫描的视角对准候选扫描(在我们的实验中, 6 ° 6^{\degree} 6°方位角分辨率)。因此,通过使用Scan Context来检测反向闭环也是可能的。
- 有效的两相匹配算法。为了获得一个可行的搜索时间,我们为第一次最近邻搜索提供了一个具有旋转不变性的子描述子,并将其与成对相似性评分进行分层合并,从而避免搜索所有数据库进行闭环检测。
- 对照其他最先进的描述子进行全面验证。与其他现有的全局点云描述子(如M2DP [8]、ESF) [11]和Z投影[12])相比,所提出的方法表现出了实质性的提升。
相关工作
移动机器人的位置识别方法可以分为基于视觉的方法和基于激光雷达的方法。在SLAM文献[13,14,15]中,视觉方法已经被普遍用于位置识别。FAB-MAP [13]通过学习视觉词袋的生成模型,增加了概率方法的鲁棒性。然而,视觉表示有一些局限性,例如易受光照条件变化的影响[16]。已经提出了几种方法来克服这些问题。 SeqSLAM [17] 提出了基于道路的方法,并且表现出比 FAB-MAP 大大提高的性能。 SRAL [2] 融合了几种不同的表示,例如颜色、GIST [18] 和 HOG [19],用于长期视觉位置识别。
激光雷达对上述感知变化具有很强的鲁棒性。基于激光雷达的方法被进一步分类为局部和全局描述符。局部描述子,如PFH [4]、SHOT [5]、shape context[7]或spin image [6],首先找到一个关键点,将附近的点分成多个bin,并将周围bin的模式编码为直方图。Steder等人提出了以词袋的方式利用点特征和完形描述子[20]的位置识别方法[8]。
然而,这些关键点描述子有着局限性,因为它们最初是为三维模型零件匹配而设计的,而不是为了位置识别。例如,与3D模型不同,3D扫描(例如,来自VLP-16)中点云的密度随着离传感器的距离而变化。此外,由于现实世界中的非结构化对象(例如树),点云的法线比三位模型的噪声更强。因此,局部方法通常需要关键点的法线,因此不太适合在室外进行位置识别。
全局描述子不包括关键点检测阶段。GLARE[9]及其变体[21,22]将点之间的几何关系编码到直方图中,而不是搜索关键点和提取描述子。ESF [11]使用了由形状函数构成的直方图串联。Muhammad和Lacroix提出了Z投影[12],这是一个法向量的直方图,以及一个具有两个距离函数的双阈值方案。Heet等人提出了M2DP [10],它将扫描的整个三维点云投影到多个2D平面,并提取192维的紧凑全局表示。M2DP显示了比现有点云描述子更高的性能,以及对噪声和分辨率变化的鲁棒性。正如本文所介绍的,全局描述子通常使用直方图。最近,SegMatch [23]引入了一种基于分段的匹配算法。这是一种高水平的感知,但需要一个训练步骤,并且需要在一个全局参考系中表示点。
在本文中,我们提出了一种新的称为Scan Context的位置描述子,它将三维扫描的点云编码成矩阵。Scan Context可以被认为是针对三维激光雷达扫描数据的位置识别的Shape Context[7]的扩展。具体来说,Scan Context有三个组成部分:在每个bin中保存点云绝对位置信息的表示、高效的bin编码函数和两步搜索算法。
用于位置识别的Scan Context
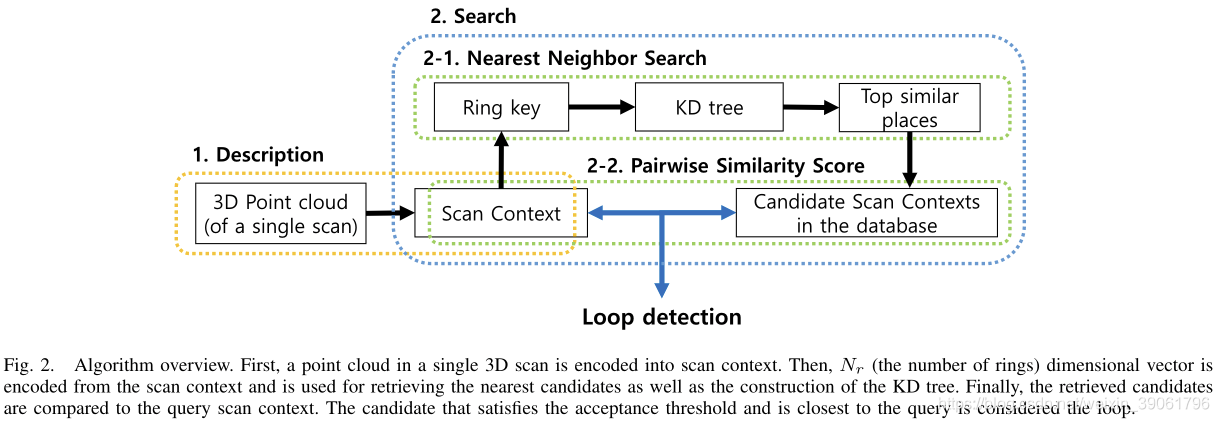
在本节中,我们描述了给定三维扫描点云的Scan Context创建,并提出了一种计算两个Scan Context之间距离的方法。接下来,介绍两步搜索过程。图2描述了使用Scan Context进行位置识别的pipline。Scan Context创造和验证也可以在scancontext.mp4中找到。
A.Scan Context
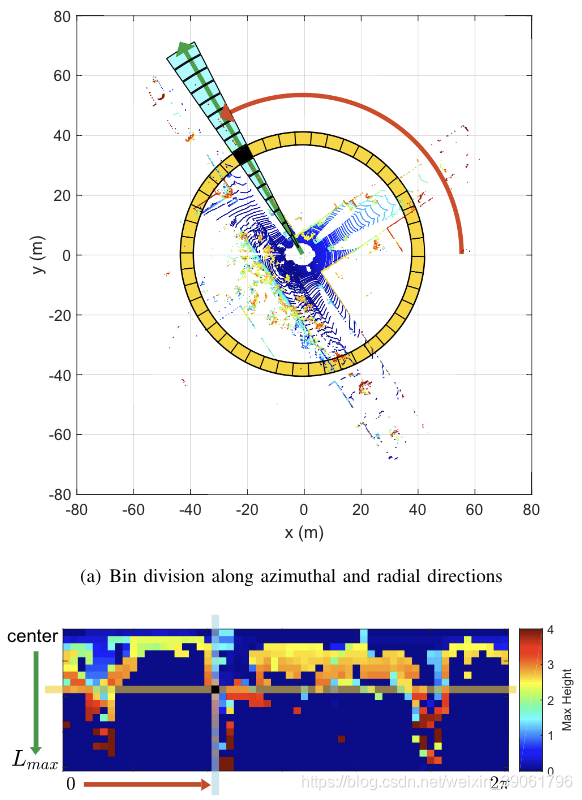
我们定义了一个叫做Scan Context的场景描述子用于户外位置识别,Scan Context的核心思想受Belongieet al .提出的Shape Context[7]的启发,它将局部关键点周围的点云的几何形状编码成图像。虽然他们的方法只是简单地计算点数来概括点云的分布,我们的方法与他们的不同之处在于,我们使用每个bin中点云的最大高度。使用高度的原因是为了有效地概括周围结构的垂直形状,而不需要大量的计算来分析点云的特征。此外,最大高度说明了从传感器可以看到周围结构的哪个部分。这种以自我为中心的可视性已经成为城市设计文献中一个众所周知的概念,用于分析一个地方的身份[24,25]。
类似于Shape Context[7],我们首先将3D扫描划分为传感器坐标中的方位角和径向bin,但是是以如下图所示的等间距方式。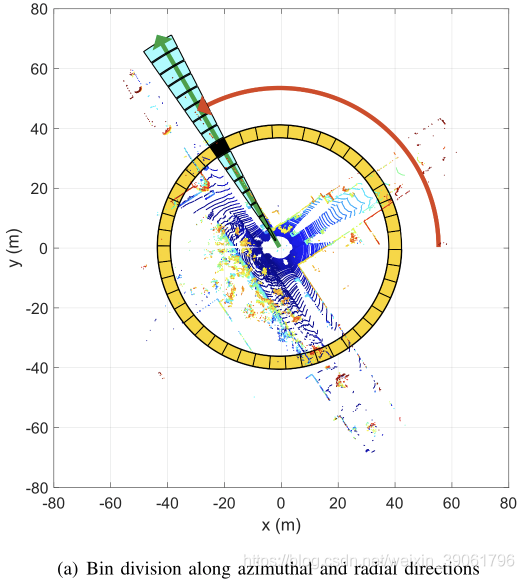
扫描的中心作为全局关键点,因此我们称Scan Context为以自我为中心的位置描述子。 N s N_s Ns和 N r N_r Nr分别是扇区和环的数量。也就是说,如果我们将激光雷达传感器的最大测量范围设为 L m a x L_{max} Lmax,环之间的径向间隙为 L m a x N r \frac{L_{max}}{N_r} NrLmax,扇形的中心角等于 2 π N s \frac{2 \pi}{N_s} Ns2π。本文中,我们使用了 N s = 60 N_s = 60 Ns=60和 N r = 20 N_r = 20 Nr=20。
因此,生成Scan Context的第一个过程是将3D扫描的所有点分割成相互分离的点云,如上图所示。 P i j \mathcal{P}_{ij} Pij是属于第 i i i个环和第 j j j个扇区重叠的bin中的一组点。符号 [ N s ] [Ns] [Ns]等于 { 1 , 2 , . . . , N s − 1 , N s } \{1,2,...,N_{s-1},N_s\} {
1,2,...,Ns−1,Ns}。因此,分区在数学上是
P = ⋃ i i n [ N r ] , j ∈ [ N s ] P i j (1) \mathcal{P} = \bigcup_{i \ in [N_r],j \in [N_s]}{\mathcal{P}_{ij}} \tag{1} P=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 390
390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









