






文章目录
引言
Facebook MetaAI 开源了自己的一个语言大模型——LLaMa,这个模型有56Billion(650亿),效果是非常不错的。他们的目的也是想让这个大模型更加的亲民,能够让更多人拿到这个模型的参数,有可能就能直接应用到他们的领域中去了,是一件非常好的事儿。他们分别开源了四个模型,从小到大有70亿、130亿、330亿和650亿参数量。
他们虽然管自己叫LLM,但事实上在这篇博文里,他们自己的LLAMA叫做smaller models,就是他认为自己是小模型。这个其实就看和谁比了,如果和 GPT-3(175billion) 比,或者和Google的 PaLM(540billion) 比,那这个 65billion 确实是小了一个数量级,但其实66billion已经比我们平时用的大多数模型都要大很多倍了,基本上很少有人能够去训练这些上10亿参数的模型,就更不用说产品部署了,这些大模型对于大部分研究者来说其实是可望而不可即的。
自然语言处理那边,大模型已经是主流,模型越堆越大了。那计算机视觉CV这边肯定也不甘落后,Google又推翻了自己之前最大的vision transformer,又推出了更大的ViT,有22billion的参数,现在视觉也算是有了自己的这个大模型了。那这个效果自然也是不用说,各种各样的视觉任务都能做,而且效果都很好。
眼看科研进步的速度越来越快,不仅每天可能都有立意比较新的论文出来,而且之前的模型也是越做越大,现在这些模型都成了系列,动不动就是V1、V2、V3,所以是一代比一代大,一代比一代强,**现在这个模型方向已经卷的都玩不动了,还有什么别的方向可以做呢?**还有同学可能说现在很多工作都是大力出奇迹,那如果我没有这个大力,我该怎么出奇迹?或者还有很多同学就问,实验室没有那么多计算资源,该怎么样选择一个合适的研究方向呢?
李沐读论文系列中,朱老师用自己参与过的一些不那么需要计算资源的项目来跟大家讨论一下,如何在有限的计算资源内做出一篇让自己比较满意的工作?
总述——四个方向
1. Efficient: PEFT(Parameter-Efficient Fine-Tuning)
因为你没有那么多的计算资源,所以你肯定是要往这个efficiency上去做的,所以这也是最直白的一个方式,就是哪里慢我就让它哪里快起来,哪里太heavy了,我就把它变得lightweight一些,总之就是让所有的这些方法变得更efficient一点。
这里举得一个例子就是,用比较火的PEFT,就是 Parameter-Efficient Fine-Tuning去如何做大模型的微调?
2. Existing Stuff (pretrained model) + New directions
能不做Pretraining就不做Pretraining,能借助已有的东西,那就尽量借助已有的东西.比如说别人已经预训练好的模型,那不用白不用,那CLIP出来之后就有那么多那么多几百、上千篇论文出来,直接就调用CLIP的模型去做各种非常有意思的应用,这些都很有impact。
同时可以选择那些比较新的研究方向,这样能避免有很多的竞争者,而且也不用天天想着如何去刷榜,能够全心全意投入到自己喜欢的科研工作之中。
3. Plug-and-play
尽量做一些通用的,能够Plug-and-play,就是即插即用的模块。这个模块其实不光是说模型上的模块,它有可能也是一个目标函数,一个新的loss,或者是一个data augmentation的方法,总之就是一个很简单的东西,但是能够应用到各种领域的。
那这个方法的好处就是说你只需要选很多很多的baseline,然后在一个你能承受的这个setting之下去做这个实验,因为它是公平对比,所以这就已经足可以说明你方法的有效性了,而不需要你真的在特别大的数据集上,用特别大的模型去证明你的有效性。
4. Dataset、evaluation and survey
最后一个方向就是比如说构建一个数据集,或者做一些以分析为主的文章,或者写一篇综述论文。这个方向是最不需要计算资源的,但同样非常有这个影响力,因为你给整个领域都提供了一些非常新颖的见解,同时也能让你自己对这个领域的理解加深一些。
思路一: 使用PEFT做大模型预训练
PEFT(parameter-efficient fine-tuning),顾名思义就是为了高效。高效的方法毫无疑问就是冻结大部分模型参数,只对部分模块做微调。
以作者团队发表的论文AIM: ADAPTING IMAGE MODELS FOR EFFICIENT VIDEO ACTION RECOGNITION (ICML 2023)为例,这是用来做视频动作识别,也就视频理解的一个工作。
先来看一下这篇文章的图一,其实就是回顾一下之前的那些视频理解的工作都是怎么做的。
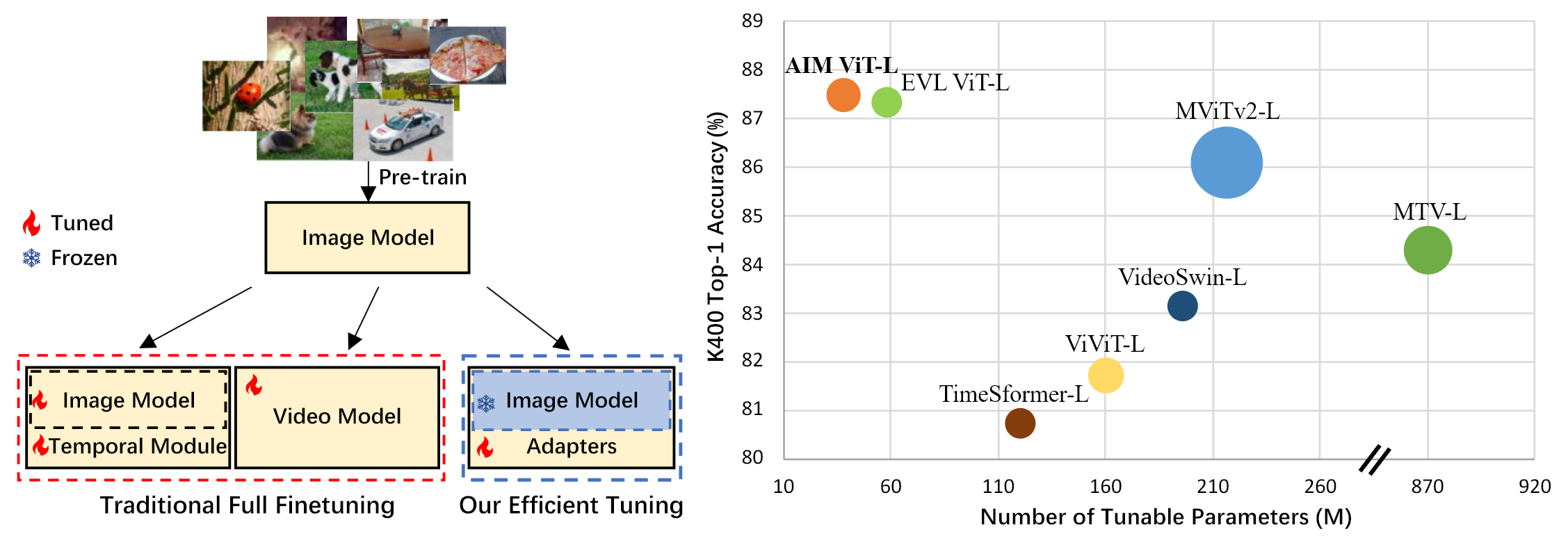
其实简单一点,粗略一点来分类的话。大部分之前的工作都可以被划分为两类:
- 1. 时间上和空间上的处理尽量分开来做
- 具体做法:往往是先有一个很大的图像数据集,先去做预训练,得到Image Model(例如在ImageNet上训练的ResNet50或ViT模型)。接下来,要么就是在这个已有的图像模型上单独的增加一些时序处理模块(例如Time Transformer,就是先做Time Attention,再做Spatial Attention,把Special、Temporal劈开来做)。大致上就可以总结为是在一个已有的图像模型之上,加上了一些时序处理的模块。
- 2. 时间空间上的处理一起做
- 这里面主要就是3D网络,比如Transformer时代的Video Swing,就把2D的Shifted Window变成了3D的Shifted Window。
之前的这些方法虽然说效果上都非常的好,但是他们都有一个小小的问题,就是计算代价实在是太大,因为他们的这些模型全都是需要Full Fine-Tune的,就是整个模型所有的参数都要进行训练。由于训练数据集本身就比较大,数据的io一般又有bottleneck,模型本身也比较大,导致训练的cost非常昂贵。
- 一般时空分开做的方法还好,如果你有一台八卡机,可能三四天、四五天能完成一个模型的训练,当然如果你的backbone比较大,可能也需要一周到十天的时间,总之稍微能轻量一点。
- 对于这种Joint Video Model来说,比如大分部3D网络,它们的训练时间就非常感人了。
- 以上模型还好,因为他们利用了预训练的图像模型,如果直接从头开始训练那就需要更长的时间了,比如VideoMAE这些自监督的视频学习方法,他们的训练代价都是以周为计算单位的,一般情况下想要复现他们的模型都很困难,更不要说是提出什么新模型比他的效果更好了。
已经训练好的Image Model需不需要微调?
第一个原因就是CLIP已经证明了,即使Zero-shot它的效果就很好(Zero-shot就是模型不变,直接在各个数据集上所推理) ,所以它已经部分验证了这个假设,就是如果一个已经训练得很好的图像模型,我们可以直接从它里面抽视觉的特征,应该是比较具有泛化性,而且随着时代的进步,随着大家都在讨论Foundation Model,以后的这个视觉模型,这个视觉的Foundation Model肯定是越来越好,越来越大的,那也就意味着它里面抽出来的特征肯定是越来越具有泛化性,而且越来越有效的。所以从有效性的这个方面来讲,当有了一个极其强大的已经预训练好的这个图像模型之后,我们可能就不需要Fine-Tuning这个部分。
另外一个原因也很好理解,就是为了防止灾难性遗忘。就是说如果你已经训练好了一个特别大的模型,它的参数量也非常多,那这个时候如果下游数据集没有很好的数据,或者说没有很多的数据,你硬要去Fine-Tune这个大模型的话,往往你是Fine-Tune不好的,要么就是直接overfit了,整个模型就不能用了,要么呢就是即使你能在你现在这个下游任务上表现得很好,但是它有了灾难性遗忘,就是它之前的很多大模型有的这种特性全都就丢失了,它的泛化性可能也丢失了,这也是得不偿失的一件事情。
所以说从这两个主要的方面去考虑,当拿来一个非常大、非常有效的这个image model之后,能不能直接就把它的模型参数锁住,然后在上面加一些时序处理的模块,或者加一些新的这个目标函数?总之就是通过修改周边的方式,让这个模型具备时序建模的能力,从而让一个图像模型直接做视频理解的任务,而不需要再从头训练一个视频模型,省时省力。
接下来就稍微过一下其中两个比较普遍的方法,Adapter和Prompt-Tuning。
1. Adapter
Adapter最早来自于2019年的论文 Parameter-Efficient Transfer Learning for NLP,最早的时候就是用来做NLP的。可以看到很多视觉或者多模态这边用的技术都是从NLP那边过来,原因就是因为大家都用transformer做backbone了。所以说之前在NLP那边work的一些方法,大概率在这边也是能work的,所以说就能很好的迁移过来。
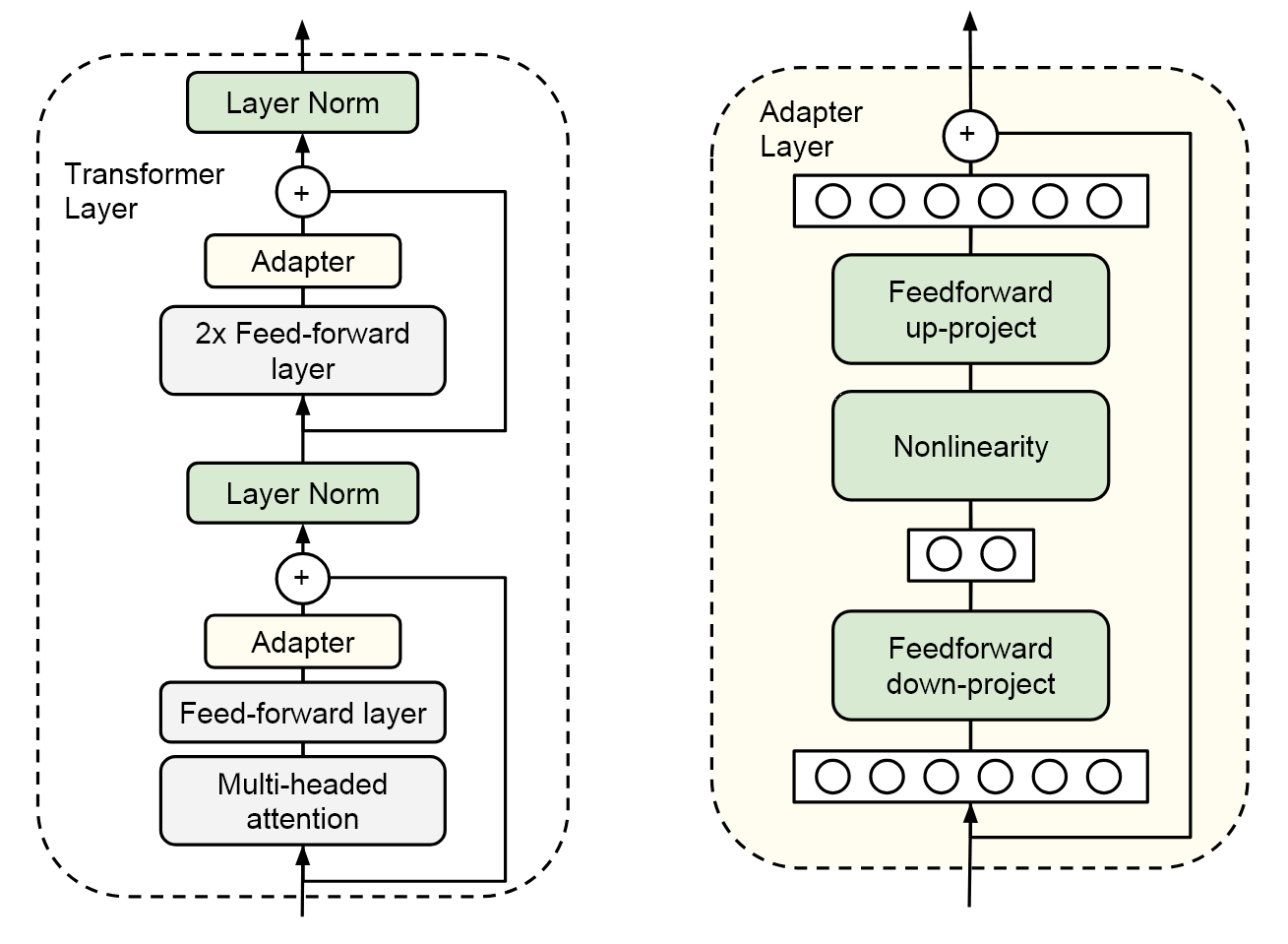
那Adapter是什么呢? 就是一个下采样的FC层 + 非线性激活层 + 上采样的FC层,最后还有一个残差连接。这个就是一个Adapter Layer,就像一个即插即用的模块一样,可以插到Transformer Layer里的任何一个地方。
加Adapter的作用是什么,为什么这称为Parameter-Efficient Fine-Tuning呢? 其实就是说,原来已经训练好的这个大模型Transformer是不动的,就是图中灰色的部分参数全部都是锁住的,在大模型微调的过程中完全是没有gradient update的,只有这些新添加的Adapter层在不停的学习。Adapter层它里面就是两层FC,而且也有下采样的过程,所以说它的参数量是非常之少的。尤其是跟那些动辄就几B、几十B或者几百B的这个language模型比,新添加的Adapter就这几Million的新参数量,其实就可以完全忽略不计了。
比如说在最新的一个PEFT的方法Lora在论文的摘要里,就写如果你在一个超大的模型里,比如说GPT-3 175B的模型里使用Lora,那其实最后需要训练的模型参数只是原来模型参数的1/10,000,所以说是可训练的模型参数量的节省是非常impressive的。
AIM工作采用方式——Adapter
Adapter它就是一个即插即用的模块,它到底应该插在哪儿?每一个transferblock里到底要插几个?那看看AIM是具体如何设计的。
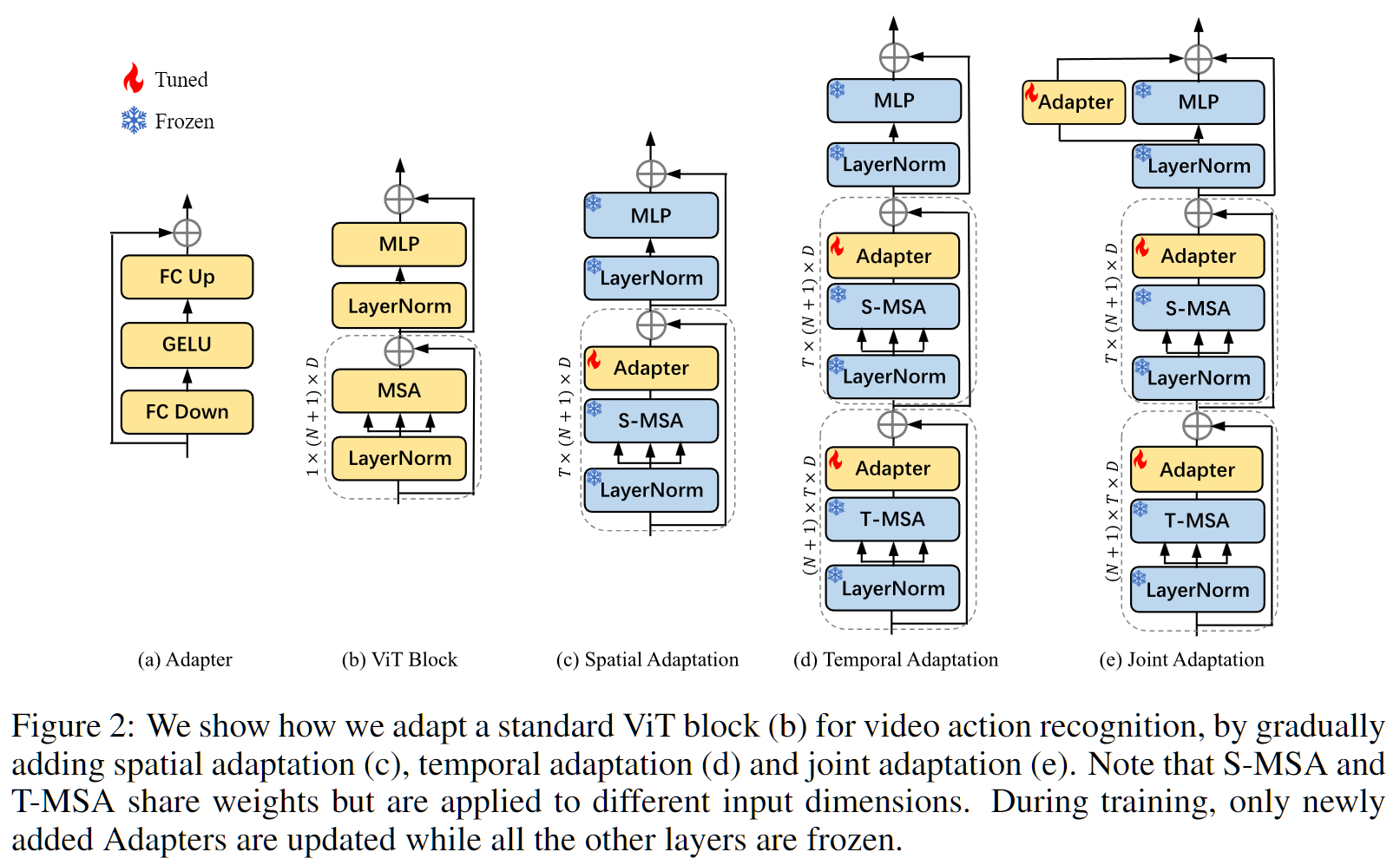
这里依次提出了三种方式:Spatial Adaptation、Temporal Adaptation和Joint Adaptation。
- Spatial Adaptation
- 在已有的ViT Block之上,参数全部锁住,只在Self-Attention后面加一层Adapter。
- 目的:不想着添加什么视频理解的能力,或者时序建模的能力,只想加一些可学习的参数,看看模型能不能从图像学习到的特征迁移到视频数据集,能不能解决domain gap的问题。
- 事实上看后面的实验结果,这一步就已经很有用了。但是因为缺少时序建模的能力,在很多video的数据集上,效果还是差一点,比不上之前的full fine tuning的模型。
- Temporal Adaptation
- 下一步就是加时序建模的能力。先复用一下Self-Attention,现在就变成了两个Self-Attention+一个MLP,这两个的参数是完全一致,而且是锁住的。只不过我们想让它一个去处理Spatial信号,一个去处理Temporal信号。
- 怎么实现一会儿关注Spatial dimension,一会儿关注Temporal dimension? 使用Reshape操作,输入进来的时候,先reshape一下,让自注意力在时序这个维度上做。之后,再把这个数据reshape回来,接下来再做自注意力的时候就是在196+1那个序列维度上去做了,就是正常的空间上的自注意力。
- 输入就是变了变如何确保一个就是学Spatial,一个就是学Temporal呢? 又额外加了一个Adapter,两个Adapter的目的就是希望其可以学习少量的参数去更多的关注Spatial或Temporal维度的信息,这样就至少有两套可以学习的参数。
- 实验中可以看到,再加入这个Temporal Adaptation之后,性能就非常强了,基本上已经能够match之前的full fine tuning的模型,甚至能够超越他们了。
- Joint Adaptation
- 为了将性能再提升一点,之前一般都会做一次joint modeling,这里也是在MLP旁边加了一个Adapter。
- 希望就是刚开始做temporal,然后现在是做的special,然后你这两步都做完之后,最后希望做一层special-temporal,也就是说让这三个adapter各司其职,各自去管各自那一部分,学各自该学的,尽量让这个优化问题变得更简单一些。
2. Prompt Tuning
Prompt在之前在讲CLIP的时候就说过,这里再借用CoOp这篇论文里的图一再回顾一下Prompt。

具体来说Prompt就是一个提示,就是你给模型一个提示,让模型去做你想让他做的事情。
以CLIP模型举例,比如现在有一张图片,想对这个图片进行分类,怎么去给这个Prompt呢?最简单的方式就是把可能的class类别名称,都一个一个给这个模型,看最后哪个class和图片的相似度最高,那这个文字大概率就是这个图片描述的类别了。
Prompt Tuning的Tuning体现在哪? 就是给定的这个Prompt可以各种各样的调,它有可能对最后的这个性能影响非常之大。比如说在CoOp中,如上图(a)所示,这里的图片是一个飞机,如果用propmt:a [class] 就是一个飞机,它其实准确率非常高,那如果像CLIP里默认的用的是 a photo of [class] 飞机,那其实准确率反而下降了。更神奇的是,如果你给这个prompt中of后面再加一个a,a photo of a 飞机,这个准确率又一下从80提升到86了。
不论是在分类任务里,还是在这些图像生成的任务里,这个Prompt Tuning对最后的这个性能影响是非常非常巨大,最后能否得到你想要的那个结果,很大程度上取决于你有没有选择一个很好的prompt。
hard prompt与soft prompt
之前这种手工写的prompt,其实都叫做hard prompt,就是一旦写就写死了,不能动也不能学,比如a photo of [class]。你可以随便写,但是这种需要你有一些先验知识,但我们并不是总有这个先验知识的,而且我们也不知道这些先验知识到底是有用还是没用。所以这个时候大家肯定就开始想,既然我们是深度学习时代,那万物都可学习,那我们来学这个prompt不就行了吗?
所以说这也就是CoOp这篇文章的想法,就是把这个hard prompt变成soft prompt,我去学习它,那具体来说就是它有一个可学习的向量 [ V ] 1 [ V ] 2 … [ V ] M [ CLASS ] [\text{V}]_1[\text{V}]_2 \dots [\text{V}]_M [\text{CLASS}] [V]1[V]2…[V]M[CLASS],这是一个learnable vector。然后在模型的训练过程中,整个模型我是锁住不动的,我只根据最后这个loss去调整我这个prompt,最后我就希望我学到这个prompt能够泛化到各种各样的情形里去,从而我就不用手动的去每次写这个prompt。
那如果想再了解的清楚一点,我们来看后面它这个总览图:
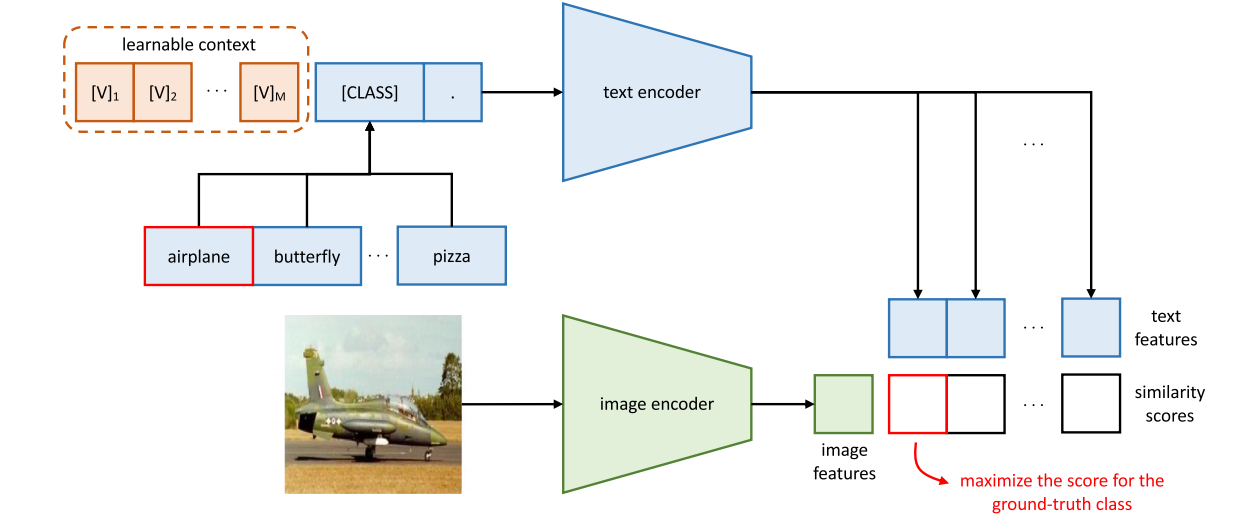
其实就跟CLIP模型之前在做推理的时候画出来是一模一样,上面是这个文本的分支,一个prompt进这个文本编码器,然后得到很多文本特征,图像进这个图像编码器得到一个图像特征,然后这个图像特征和这些文本特征去做相似度,然后最后看哪个最高选哪个。但是这里跟CLIP模型在做推理时候的区别就在于, 是在训练的,文本端输入的不再是固定的 a photo of [class]了,而是一个可学习的context。
是在训练的,文本端输入的不再是固定的 a photo of [class]了,而是一个可学习的context。
所以就通过这种方式——就是把这个原来的模型都锁住,只学习prompt这种方式,能够大幅度的降低计算量,而且还能帮我们在transfer learning的时候学到一个很好的prompt,从而避免我们在做下游任务的时候,去给每一个下游任务手工的设计这些prompt,当然这只是prompt tuning,或者说soft prompt最简单最基本的一个形式,后续还有很多改进的工作。他们自己也又推出了cocoop这个工作,如果感兴趣的话可以自己有时间再去看。
那这里面讨论还是在这个文本端的这个prompt,就是它还是一个多模态的工作,它有一个图像编码器,有一个文本编码器,这个prompt还在文本这边,更多的还是像一个NLP的工作。
纯视觉的prompt
那如果我是一个纯视觉的工作,只有一个纯视觉的这个图像编码器,那能不能用prompt?那其实也是有的,在22年年初的时候就有一篇叫visual prompt tuning的方法,就把prompt用到了纯视觉的任务里,就是VPD论文的模型。
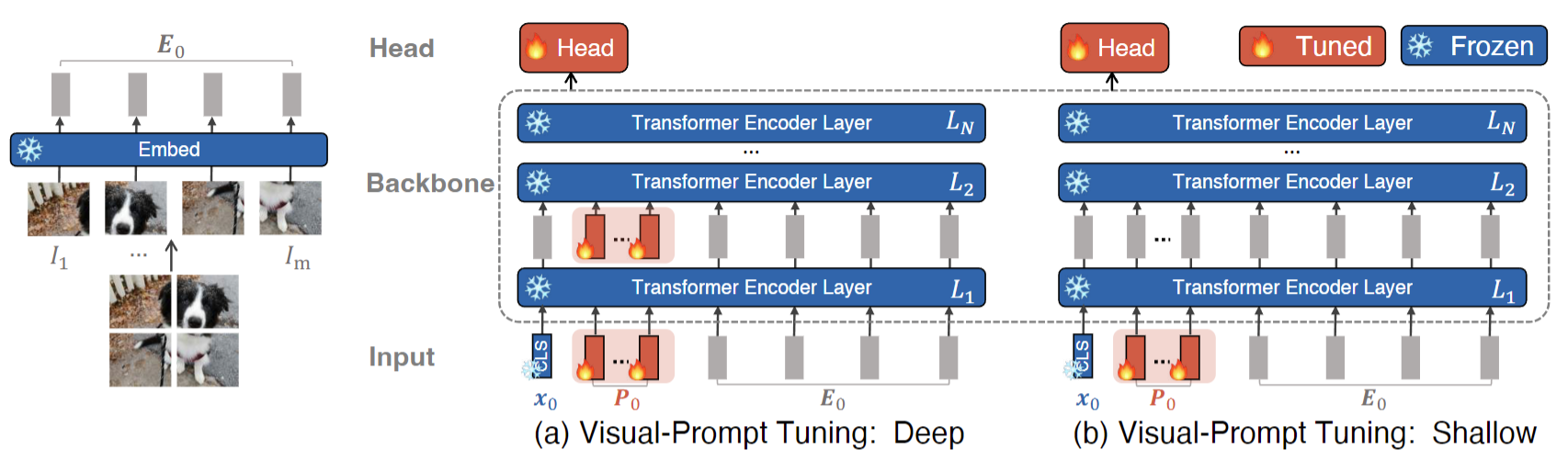
首先输入就是一个图片,所有蓝色的部分,就是已经训练好的模型,包括embedding层和后续的Transformer层。那我们现在要使用prompt,这个prompt应该加在哪?VPT这篇论文提出了两种方式:VPT Deep和VPT Shallow。
VPT Shallow 就跟文本那边非常像,就是在输入端加了一个learnable prompt ![]() 。具体来说,给定一个图片,首先将其打成patch,然后这些patch通过embedding层就得到了输入的这些sequence(比如原来是224×224的图片,打成patch之后,它就变成了长度为196的token sequence,也就是准备给整个Transformer的输入,也就是这里的E0)。如果我们将E0看成是文本端那边那个class name的话,很容易就能想到这个prompt就应该加载它之前,跟文本那边一模一样。后续的操作也跟文本那边一模一样,就只有这个prompt是在学习的,剩下所有的过程中模型的参数都是锁住的,那最后的目标函数也只用来优化这个prompt,这个P0。
。具体来说,给定一个图片,首先将其打成patch,然后这些patch通过embedding层就得到了输入的这些sequence(比如原来是224×224的图片,打成patch之后,它就变成了长度为196的token sequence,也就是准备给整个Transformer的输入,也就是这里的E0)。如果我们将E0看成是文本端那边那个class name的话,很容易就能想到这个prompt就应该加载它之前,跟文本那边一模一样。后续的操作也跟文本那边一模一样,就只有这个prompt是在学习的,剩下所有的过程中模型的参数都是锁住的,那最后的目标函数也只用来优化这个prompt,这个P0。
VPT Deep在每一层输入输出的时候都加上这个learnable prompt,这样就无形的增加了这个可学习的参数量。所以说在他们后续的实验中,这个VPT Deep的效果一般是要比VPT Shallow要好的。
3. PEFT总结
总之,不论是Adapter,还是Hard Prompt,Soft Prompt,还是Visual Prompt,它们的共通性就是当你有一个已经训练好的大模型的时候,希望这个模型是锁住不动的,这样不光有利于训练而且有利于做部署,做这个下游任务的transfer,而且它的性能还不降,很多时候它不降反升。
由于近几年非常受追捧,huggingface也开放了用来做PEFT的一个包,可以在GitHub上找到 (https://github.com/huggingface/peft),它的目的就是当你只有很少量的硬件,或者当你的GPU内存不高的时候,如何去fine tuning或者使用这些billion scale的模型。所以如果你还没有在你的问题中试过PEFT,或者你对PEFT很感兴趣,那我非常推荐你来玩一玩,般如果只是刚开始做实验的话,一张卡就可以。

这里面就不再过多介绍这个PEFT的这个方法,如果感兴趣,也可以去看一下之前一篇比较类似于综述论文的工作,写得非常好,他就把最近这个PEFT的方法全都总结了一下,从一个统一的观点(unified view)做了一些总结和归纳,非常值得一读。

思路二:Existing Stuff (pretrained model) + New directions,尽量避免预训练,借助已有的东西
当你没有足够多的资源的时候,尽量不要去碰 Pre-training,能 Zero-shot 就 Zero -shot,不能 Zero-shot 就 few-shot,实在不行你就fine-tuning,但是千万别碰预训练,因为预训练现在这个规模是越做越大。20 年或者 21 年的时候可能还有一些工作能够一个8卡机训练个两三天完成,但是现在这个规模的实验已经不太可能了。预训练的这个模型和数据的规模全都上去了,如果用小模型和小数据是很吃亏的,而且很多时候如果只用小模型和小数据,很有可能本来有一些能大力出奇迹的东西也出不来了,所以你也不知道你的方法有效还是没效。
总之,
- 尽量不要预训练,尽量用人家已经训练好的模型,比如CLIP。很多工作CLIP 出来之后这么短的时间内能把Detection, Segmentation, depth, action, Audio 所有的这些工作全都拓展开来,其实还是因为直接利用 CLIP 预训练好的模型,不去做预训练,只做 fine tuning 这个计算资源是能节省很多的。
- 尽量选一些新的方法或者新的Topic去做。尤其是那些你觉得或者大家也觉得还比较超前的那些topic,这就非常好。因为往往在那些领域里可能还没有很大的一些数据集,一些成熟的这个benchmark,所以你这个数据,这些 setting 都可以自己选,这个规模就可以降下来。第二个就是也没有那么多已有的工作需要去竞争,那这样就能专心在提高自己的方法之上,而不用成天担心比不过别人,所以这篇论文中不了。
以ICLR2023年的论文Unsupervised Semantic Segmentation with Self-supervised Object-centric Representations。利用了已经训练好的网络抽特征,节省了大量计算资源。此外,Object-Centric Learning这个方向并不是很新的Topic,但是还是属于一个正在蓬勃发展的一个topic,玩家不是那么多,数据集也不是那么大。
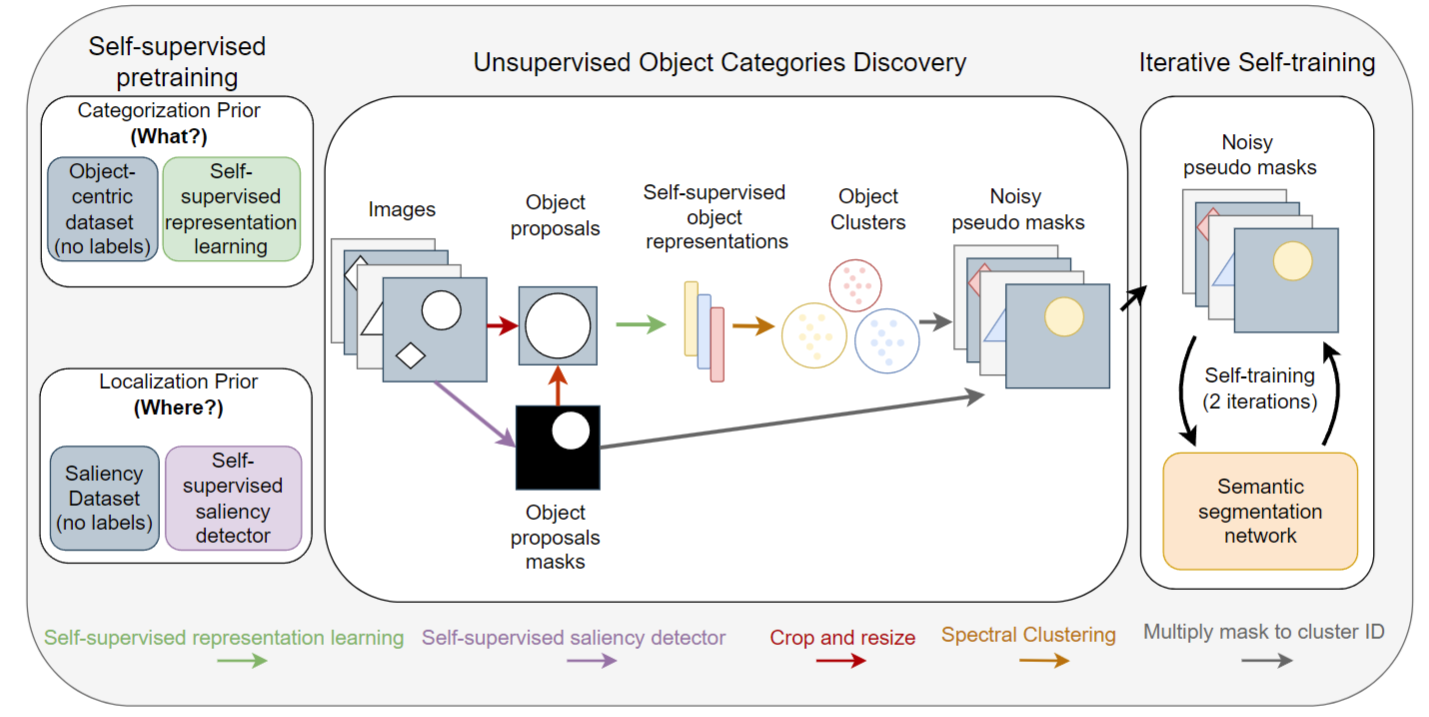
最主要的就是Unsupervised Object Category Discovery,就是怎么样能让这个模型无监督的情况下去找到这个新的物体。
这个 object centric learning 其实最近很多人都很感兴趣。因为他们觉得,如果你理解一个图片,就是整体去理解,整体抽一个特征的话,其实不是那么合理。那像我们人在感受这个世界的时候,其实看东西都会有一个聚焦的点,都会先看一些人,或者看一些物体,然后再看人和物体之间怎么去做交互,然后通过这些关系来感知这个世界,然后来预判接下来会发生什么。很多人就觉得这个 object level 的这个representation,就是object centric learning 其实比 global learning 要更有效。那如果还能unsupervised 或者 self-supervised 的去学习这个特征,那就更完美了。
1. 定位——借助已有模型获取mask信息
Unsupervised其实并不是真正的无监督,它是人为的通过设计了一些这个任务,或者人为的设计了一些label,从而让这个模型能够去学习的。
在这里也不例外,你如果想学习一个 segmentation 的网络,你肯定是需要某种程度上的mask information。那这个最初始的这个 mask information 到底应该从哪来呢?
这个就借助了之前Saliency Detection的工作,直接用了DeepUSPS这个工作,就可以直接给定一张图片,然后它给你生成这张图片里比较显著性的物体的mask是什么样子的。虽然比较粗糙,也不准备,但至少有一个起始点了,有一些mask的信息了。就跟图里画的一样,如果这张图片里有一个圆圈,有一个菱形。那用了这个显著区域检测之后,它就把这个圆圈给detect出来了,这个其实相当于有一个 masked label 了。
2. 分类——借助已有模型抽取特征,判断类别
那解决完这个定位问题之后,我们又要解决这个分类问题。也就是说。当我把这个圆圈从这个图片里抠出来之后。我现在想要知道这个圆圈到底是哪一类的时候,这个时候我们就借助于之前的DINO这个工作,去抽它的特征,从而来判断到底这个物体是什么物体。
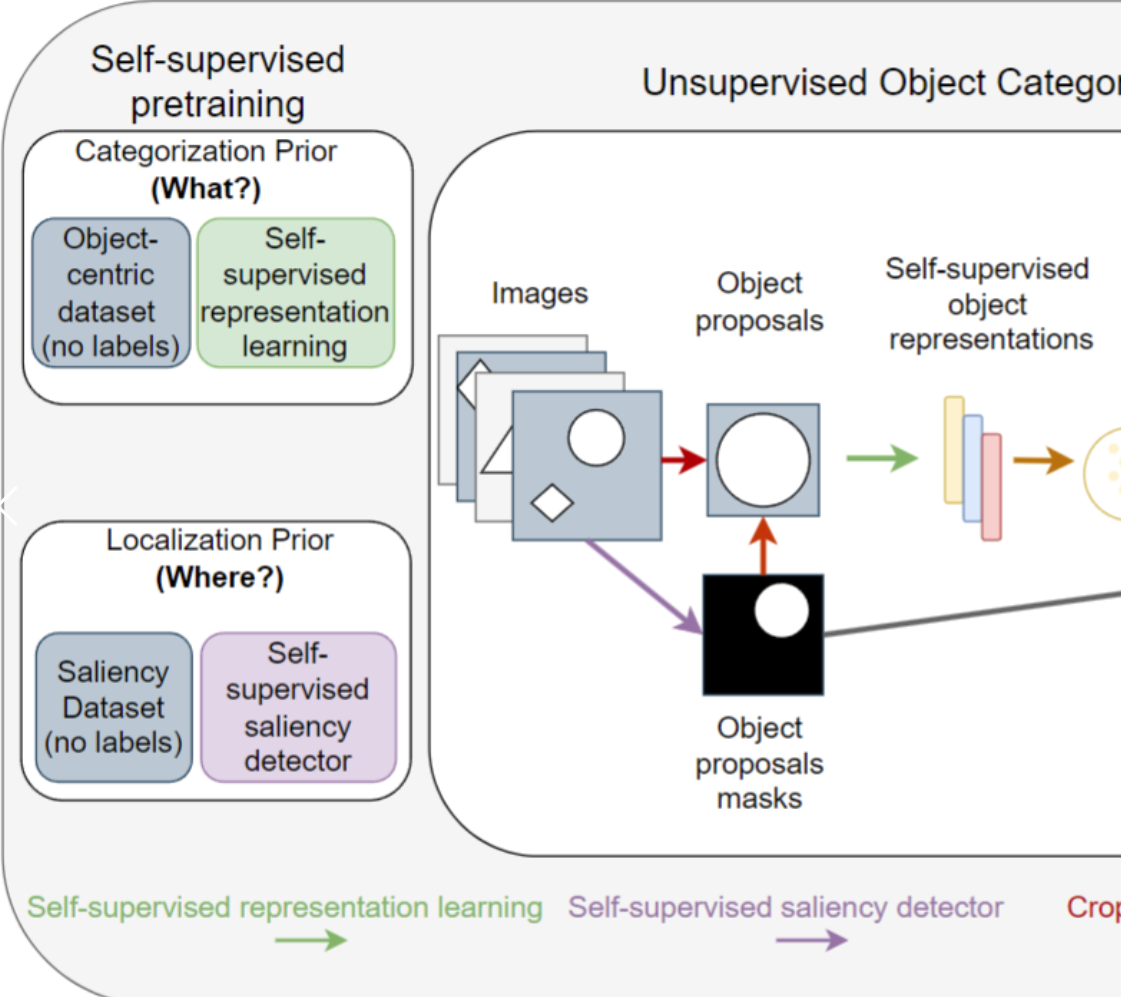
简单来说,整个流程就是,比如说图中这张图片可能就抠出来两张图,一张是圆形,一张是菱形。当抠出来这两张图片之后,再把它的图片大小 resize 成 224×224,变成正常的图片大小。然后我把这个图片直接扔给 DINO这个网络,这个DINO就还给我一个 1024×1的一个global representation。
接下来把这些特征全扔过去做一次这个clustering。因为聚类是无监督的算法,所以说它就能无监督的告诉我这些物体到底是什么(它不是真的告诉你这些物体是什么,只是给你一些这个物体的这个ID,比如说0123)。因为它只是聚了个类,所以这里称这些是 Noisy Pseudo masks。但是即使它只是聚这个类,它还是能告诉你这是类0,这是类1,这是类2,那这样其实变相你就有了这些 mask label 了。
那这个时候你有了原来的这个图像,你又有了 mask label, 就可以直接去训练一个Semantic Semitation Network。
那这里因为不光是想对一张图片里的单个物体进行分割,还想分割多个物体,所以又做了 self training,就来了好几个轮回,这样通过不停的自训练,网络就能学到更多物体的分类,甚至能学到新的类别,这也就是 object centric learning 想达到的目的了。
思路三:Plug-and-play即插即用模块
尽量做一些通用的,可以即插即用的模块。这个模块既可以是模型上的一个模块,也可以是一个目标函数,或者输入层面的数据增强。
数据增强的方法往往是很通用,它一般不受限于你的这个任务,很多时候它甚至不受限于模态。
为什么说做这个方向对计算资源的要求会少呢? 因为证明一个方法的有效性,不一定说我非要拿到某个数据集上第一。因为即使你拿到某个数据集上第一,有可能你只是overfit,所以反而还不能证明你有多有效。往往是那些很简单的,能够泛化到各种各样的任务,各种各样的数据集上才是真正有效的方法。那这个时候你就可以很选择很多baseline,然后可以自己定一个setting,让他们能够公平的比较。那这个 setting 可大可小,可以根据你的计算资源来定,那只要在这个 setting 里边,你在所有的 baseline 上加上这个即插即用的模块之后,都能有统一的涨点,你也能给出合适的分析,那就非常有说服力了。所以从这个角度上来说,它是一个在你没有足够的计算资源的情况下,一个还不错的研究方向。
在多模态大模型中,很多都没有用数据增强,有的只是用了很基础的数据增强。这是为什么呢? 原因是数据增强之后,原来的图像文本对,可能就不再是一对了。
比如当你有一个这个图片文本对的时候,比如这个图片里说有一个白色的狗在一个湖的右边在玩耍,旁边还有一棵绿色的树,你的文本就是这句话。但这个时候,如果只对图片做数据增强的话,比如做了一个 color gitering,那它的颜色就变了,这个狗就不再是白狗了,你的树也不再是绿树了,那这个时候你的文本和图片它就不匹配了。那同样的道理,当做这个 random flip,比如说水平方向的 flip 或者竖直方向的 flip 之后,你的这个上下左右这种位置性的词它的意义也全都颠倒了,那这个时候 flip 过后的图片和原来的这个文本它就不再是一个对了。
怎么才能让这个信息不丢失,怎么才能最大程度上把这个信息给保留起来呢?
那我们可以先一个模态来想,那图像这边如果想保留所有的信息,尽量不去毁坏它原来的东西,其实一个比较天然的选择就是 mixup。 mixup 就是把两张图片线性的插值到一起。虽然在人眼看起来,有时候这个生成的图片可能比较诡异,但是它毕竟只是把两张图片直接就这么加了起来,所以该有的信息都还在里面,所以算是很大程度上保留了原来的信息。
文本那边怎么样最大程度的保留信息呢?当然文本那边也是有 mixup 的,还有 random erasing,或者说 random insertion,或者说 back translation,各种各样的数据增强的方法。但如果我们的目标是尽可能的保留更多的信息,那为什么不直接把两个句子就直接拼接在一起呢?那这样什么信息都不会丢失,所有的单词都还在新生成的这个句子里面,这样不就最大程度地保留了原来文本的信息吗?这就是MixGen的主要思想。

如图所示,对于一个多模态数据集,假设其中 ( I 1 , T 1 ) (I_1, T_1) (I1,T1) 和 ( I 2 , T 2 ) (I_2, T_2) (I2,T2) 两个图片文本对。
- 在图片这边对 I 1 I_1 I1 和 I 2 I_2 I2 做Mixup,做Linear Interpolation(线性插值),就能得到新的图片 I 3 I_3 I3,它在很大程度上保留了两个图片里的物体,包括背景、context等。
- 在文本这边直接将 T 1 T_1 T1 和 T 2 T_2 T2 拼接起来,那这个样子什么信息都不会丢失。
通过这种方法,得到了一个新的训练样本 ( I 3 , T 3 ) (I_3, T_3) (I3,T3)。这两个图片也有可能描述的是两个完全不相关的概念,句子也可能是完全不能搭到一起的句子,读起来很别扭,上下文不连贯。但是从整体信息量上来说,它最大程度的保留了之前的信息量,从而保证了新生成的图像文本对尽可能还是一个match的pair。

实验结果也可以看出,在各种setting、dataset和task下都有统一的提升。
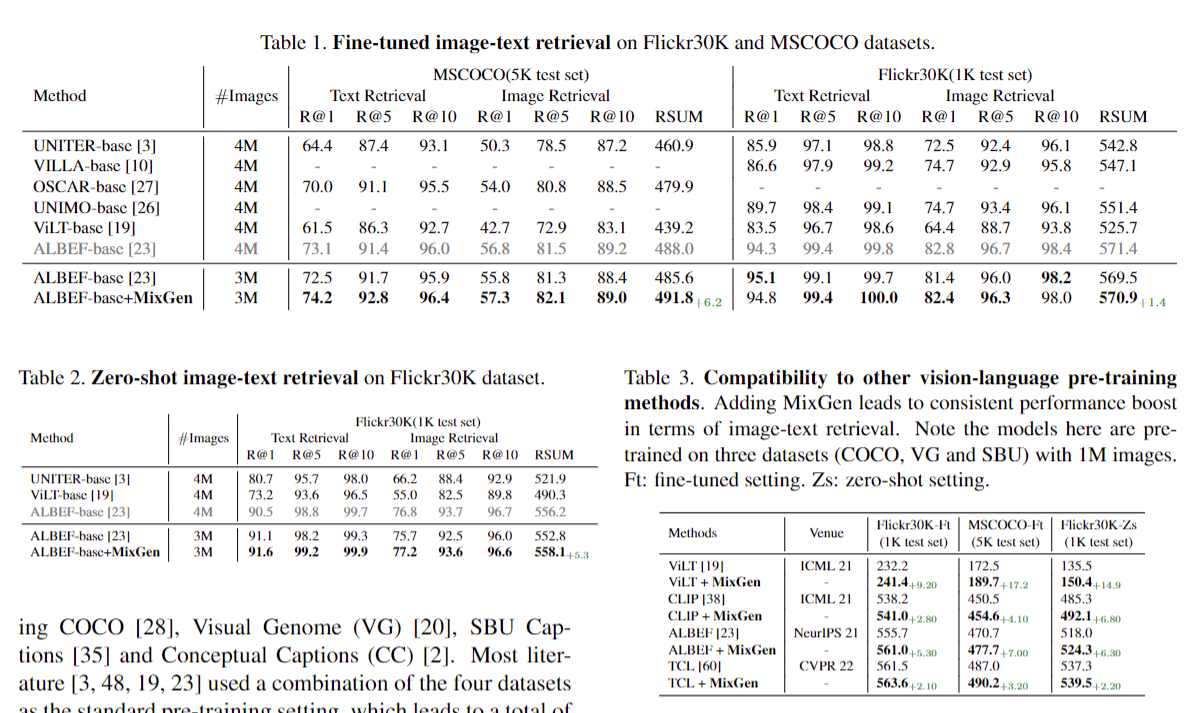
很可惜,这个论文第一次投稿NeurIPS并没有中,三个审稿人都觉得这个方法太简单了。有一个审稿人给出的意见还是蛮有建设性意义:数据增强一般是在没有足够多的数据的时候才去做的一个选择。但是在多模态的预训练里,因为已经有大量的数据存在了,那确实像CLIP 论文里说的那样,你有可能不需要这种数据增强。但是相反的在多模态下游任务里,当你做 transfer 的时候,因为下游任务的数据集不多,所以是不是应该考虑在这个 fine tuning 的时候用这个数据增强?
思路四:做一个数据集、分析为主的论文或综述性论文
最后一个方向,对计算资源的要求是最少的,很多时候都不需要大量的计算资源,甚至只是断断续续,偶尔需要一些计算资源就可以了。比如说就是做一个数据集,做一些纯evaluation 为主的论文,纯分析的论文,甚至就是写一篇综述论文。
1. 做一个新的数据集
大家可能很多人一听说要造个数据集,那这个代价太大了,这可能需要很多人需要花很多钱才能做一个很大的数据集,但其实也不一定。
比如说像[BigDetection: A Large-scale Benchmark for Improved Object Detector Pre-training]这篇论文里就是把三个已有的数据集LVIS、OpenImage 和 Object365 给合到了一起,当然不是简单的合到一起了,因为它的每个数据集的 class 也不是完全一样的。所以你得考虑到底怎么去 merge 这些class,或者怎么去重新分布这些类别?而且根据你的这个任务的需求,你到底是想做预训练还是想做下游任务?你到底想 target 哪一个domain?这个也决定了你这个物体的这个类别到底该多细粒度?所以这些都是可以做的研究方向,都可以写成论文的。
这个BigDetection最后处理完,就是一个有600类的目标检测数据集,里面有超过340万个训练图片,3600万个bounding box annotation,算是当时最大的目标检测数据集了,而且在上面可以预训练各种各样的目标检测器。因为训练数据多,所以训练出来的目标检测器泛化性能,还有few shot的能力都非常好。
2. 写一个分析为主的论文或综述论文
写这种以 evaluation 为主,或者这种综述论文其实是非常有好处的。它有助于帮助你理解已有的这些方法,它们的这个优点、缺点都在哪?现在所有的方法的这些 limitation 都在哪?现在的痛点以及未来的这些 future work 该在哪些方向上发力?其实都是通过这种evaluation 的工作,大家才能找到这些 insight 的。
绝对是对你的科研有百利 而无一害的。而且这些论文往往不太需要那么多计算资源。 evaluation 的话有时候可能只是做inference,就算有的时候要做一下训练,更多的时候可能也只是 fine tuning,或者在小范围上做这个训练。那对于综述论文来说,那就更是不需要计算资源了,主要考验的是你的写作能力和你对这个问题理解的清晰程度。


















 1474
1474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









