








CVPR 2022
Multi-level Feature Learning for Contrastive Multi-view Clustering
用于对比多视图聚类的多层次特征学习
0.摘要
多视图聚类可以从多个视图中探索共同的语义,受到越来越多的关注。然而,现有的工作惩罚了同一特征空间中的多个目标,它们忽略了学习一致的公共语义和重建不一致的视图私有信息之间的冲突。在本文中,我们提出了一种新的多级特征学习框架,用于对比多视图聚类来解决上述问题。我们的方法以无融合的方式从原始特征中学习不同层次的特征,包括低级特征、高级特征和语义标签/特征,从而可以有效地实现不同特征空间中的重建目标和一致性目标。具体地,重建目标是在低级特征上进行的。基于对比学习的两个一致性目标分别在高级特征和语义标签上进行。它们使得高层特征有效地挖掘公共语义,语义标签实现多视图聚类。结果,所提出的框架可以减少视图私有信息的不利影响。在公共数据集上的广泛实验表明,我们的方法实现了最先进的聚类效率。
1.引言
近年来,多视图聚类(MVC)越来越受到关注[22, 50, 52, 57],因为多视图数据或多模态数据可以提供公共语义来提高学习效率[3, 14, 27, 33, 36, 43]。在文献中,现有的MVC方法大致可以分为两类,即传统方法和深度方法。
传统的MVC方法基于传统的机器学习方法来执行聚类任务,并且可以是相等的贡献。细分为三个子组,包括子空间方法[6,18,24]、矩阵分解方法[45,53,56]和图方法[28,55,60]。许多传统的MVC方法存在表示能力差、计算复杂度高等缺点,导致在具有真实世界数据的复杂场景中性能有限[10]。
近期,深度MVC方法因其突出的表示能力逐渐成为社区的流行趋势[1,2,20,44,49,50,54]。以前的深度MVC方法可以细分为两个子组,即两阶段方法和一阶段方法。两阶段深度MVC方法(例如,[21,50])侧重于从多个视图中分别学习显著特征并执行聚类任务。然而,谢等人[48]提出聚类结果可以用来提高特征学习的质量。因此,单阶段深度MVC方法(例如[39, 59])将特征学习与聚类任务嵌入到统一的框架中,以实现端到端聚类。
多视图数据包含两种信息,即跨所有视图的公共语义和单个视图的视图私有信息。例如,可以组合文本和图像来描述公共语义,而文本中不相关的上下文和图像中的背景像素是用于学习公共语义的无意义的视图私有信息。在多视图学习中,学习公共语义,避免无意义的视图私有信息的误导是一个永远不变的话题。尽管现有的MVC方法已经取得了重要的进展,但它们有以下缺点需要解决:(1)许多MVC方法(例如[39, 59])试图通过融合所有视图的特征来发现潜在的聚类模式。然而,与公共语义相比,无意义的视图私有信息可能在特征融合过程中占主导地位,从而干扰聚类的质量。(2)一些MVC方法(例如,[18, 21])利用潜在特征的一致性目标来探索所有视图的公共语义。然而,它们通常需要相同的重建目标功能,以避免琐碎的解决方案。这导致了冲突,一致性目标试图尽可能多地学习所有视图中具有公共语义的特征,而重建目标希望相同的特征来维护单个视图的视图私有信息。
在本文中,我们提出了一种新的用于对比多视图聚类的多级特征学习框架(简称MFLVC)来解决上述问题,如图1所示。我们的目标包括(1)设计一个无融合MVC模型,以避免融合所有视图之间的不利视图私有信息,以及(2)为每个视图中的样本生成不同级别的特征,包括低级特征、高级特征和语义标签/特征。为此,我们首先利用自动编码器从原始特征中学习低级特征,然后通过在低级特征上堆叠两个MLP来获得高级特征和语义标签。每个MLP被所有视图共享,有利于过滤掉视图私有信息。此外,我们将语义标签作为锚,与高层特征中的聚类信息相结合,提高聚类效率。在该框架中,重建目标由低级特征实现,而两个一致性目标分别由高级特征和语义标签实现。此外,这两个一致性目标是通过对比学习进行的,这使得高级特征专注于挖掘所有视图的公共语义,并使语义标签分别表示用于多视图聚类的一致聚类标签。结果,缓解了重建目标和两个一致性目标之间的冲突。与以前的工作相比,我们的贡献如下:
•我们设计了一种无融合MVC方法,该方法在不同的特征空间中进行不同的目标,以解决重建和一致性目标之间的冲突。通过这种方式,我们的方法能够有效地探索所有视图的公共语义,并避免它们无意义的视图私有信息。
•我们提出了一个灵活的多视图对比学习框架,该框架可用于同时实现高级特征和语义标签的一致性目标。高级特征具有良好的流形并表示公共语义,这使得能够提高语义标签的质量。
•由于设计良好的框架,我们的方法对超参数的设置具有鲁棒性。我们详细进行消融研究,包括损失成分和对比学习结构,以理解所提出的模型。大量的实验表明,它实现了最先进的聚类效率。
2.相关工作
多视图聚类
MVC方法的第一类属于子空间聚类[18,24],它专注于为多个视图学习一个公共的子空间表示。例如,[6]扩展了传统的子空间聚类,其中作者提出了一种用于多视子空间聚类的多样性诱导机制。第二类MVC方法基于矩阵分解技术[23,56],该技术在形式上等同于K均值的松弛[26]。例如,Cai等[4]引入了多视图的共享聚类指示矩阵,并处理了一个约束矩阵分解问题。第三类MVC方法是基于图的MVC[28, 34],其中构建图结构以保持样本之间的邻接关系。第四类MVC方法基于深度学习框架,称为深度MVC方法,其已被越来越多地开发,可以进一步大致分为两组,即两阶段深度MVC方法[21,50]和单阶段深度MVC方法[20,51,59]。这些方法利用深度神经网络优异的表示能力来发现多视图数据的潜在聚类模式。
对比学习
对比学习[7, 42]是一种获得注意力的无监督表示学习方法,其思想是在特征空间中最大化正对的相似性,同时最小化负对的相似性。这种学习范式最近在计算机视觉中取得了有希望的性能,例如[29,40]。例如,[19]中提出了一种单阶段在线图像聚类方法,该方法明确地在实例级和聚类级进行对比学习。对于多视图学习,也有一些基于对比学习的工作[12,21,35,38]。例如,田等人[38]提出了一种对比多视图编码框架来捕捉底层场景语义。在[12]中,作者开发了一种多视图表示学习方法,通过对比学习来处理图分类。最近,一些工作研究了多视图聚类的不同对比学习框架[21, 31, 39]。
3.方法
原始特征。多视图数据集 { X m ∈ R N × D m } m = 1 M \{\mathbf{X}^m ∈ \mathbb{R}^{N×D_m} \}^M_{m=1} { Xm∈RN×Dm}m=1M包括 M M M个视图中的 N N N个样本,其中 x i m ∈ R D m x^m_i ∈ \mathbb{R}^{D_m} xim∈RDm表示来自第 M M M个视图的 D m D_m Dm维样本。数据集被视为原始特征,其中多个视图具有 K K K个待发现的公共聚类模式。
3.1 动机
多视图数据通常具有冗余和随机噪声,因此主流方法总是从原始特征中学习显著表示。特别是,autoencoder[13,37]是一种广泛使用的无监督模型,它可以将原始特征投影到可定制的特征空间中。具体地,对于第 m m m个视图,我们分别表示 E m ( { X m ; θ m ) E^m(\{\mathbf{X}^m; θ^m) Em({ Xm;θm)和 D m ( Z m ; φ m ) D^m(\mathbf{Z}^m; φ^m) Dm(Zm;φm)作为编码器和解码器,其中 θ m θ^m θm和 φ m φ^m φm是网络参数,表示 z i m = E m ( x i m ) ∈ R L z^m_i = E^m(x^m_i ) ∈ \mathbb{R}^L zim=Em(xim)∈RL作为第 i i i个样本的 L L L维潜在特征,并表示 L Z m \mathcal{L}^m_Z LZm作为输入 X m \mathbf{X}^m Xm和输出 X ^ m ∈ R N × D m \mathbf{\hat{X}}^m∈\mathbb{R}^{N×D_m} X^m∈RN×Dm之间的重建损失:
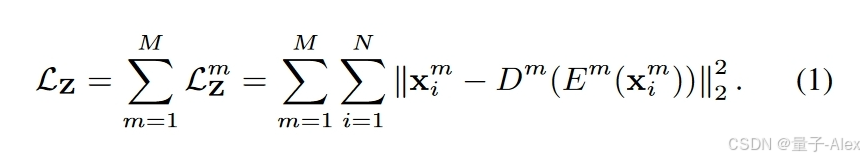
基于 Z m = E m ( X m ) m = 1 M {\mathbf{Z}^m = E^m(\mathbf{X}^m)}^M_{m=1} Zm=Em(Xm)m=1M,MVC旨在挖掘所有视图的公共语义,以提高聚类质量。为了实现这一点,现有的MVC方法仍然有两个挑战需要解决:(1)许多MVC方法(例如,[20,59])融合所有视图 { Z m } m = 1 M \{\mathbf{Z}^m\}^M_{m=1} { Zm}m=1M的特征,以获得所有视图的公共表示。这样,通过直接对融合后的特征进行聚类,将多视图聚类任务转化为单视图聚类任务。然而,每个视图 Z m \mathbf{Z}^m Zm的特征包含公共语义以及视图私有信息。后者是无意义的,甚至是误导性的,这可能会干扰融合特征的质量,导致聚类效果差。(2)一些MVC方法(例如,[8, 21])通过在 { Z m } m = 1 M \{\mathbf{Z}^m\}^M_{m=1} { Zm}m=1M上执行一致性目标,例如,最小化所有视图上相关特征的距离,来学习一致的多视图特征以探索公共语义。然而,他们也应用等式(1)惩罚 { Z m } m = 1 M \{\mathbf{Z}^m\}^M_{m=1} { Zm}m=1M上的约束,以避免模型崩溃并产生平凡解[11, 21]。一致性目标和重建目标被推到相同的特征上,使得它们的冲突可能限制 { Z m } m = 1 M \{\mathbf{Z}^m\}^M_{m=1} { Zm}m=1M的质量。例如,一致性目标旨在学习公共语义,而重建目标希望维护视图私有信息。
最近,对比学习变得流行,并且可以应用于实现多视图的一致性目标。例如,Trosten等人[39]提出了一种单阶段对比MVC方法,但其特征融合面临挑战(1)。林等人[21]提出了一种通过学习一致特征的两阶段对比MVC方法,但它没有考虑挑战(2)。此外,许多对比学习方法(例如,[19, 30, 40])主要通过数据扩充来处理单视图数据。这种特定的结构使得其难以应用于多视图场景。
为了解决上述挑战,我们提出了一个新的多级特征学习框架,用于对比多视图聚类(命名为MFLVC),如图1所示。特别是,为了减少视图私有信息的不利影响,我们的框架避免了直接的特征融合,并为每个视图建立了多级特征学习模型。为了缓解一致性目标和重建目标之间的冲突,我们建议在不同的特征空间中进行它们,其中一致性目标通过以下多视图对比学习来实现。
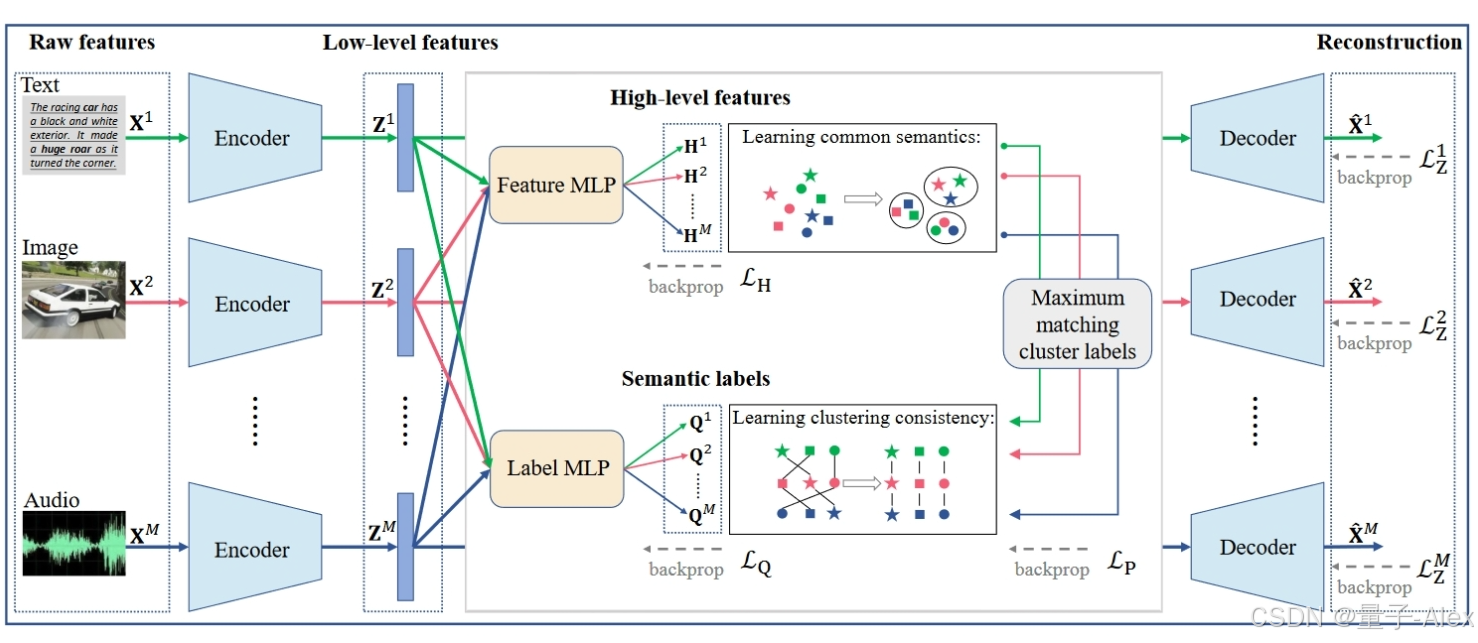
图1。MFLVC的框架。我们避免了多级特征学习中的直接特征融合,多级特征学习从每个视图的原始特征 X m \mathbf{X}^m Xm中学习低级特征 Z m \mathbf{Z}^m Zm、高级特征 H m \mathbf{H}^m Hm和语义标签 Q m \mathbf{Q}^m Qm。重建目标 L Z m \mathcal{L}^m_Z LZm在 Z m \mathbf{Z}^m Zm上单独进行。两个一致性目标(即 L H \mathcal{L}_H LH和 L Q \mathcal{L}_Q LQ)分别在 { H m } m = 1 M \{\mathbf{H}^m\}^M_{m=1} {
Hm}m=1M和 { Q m } m = 1 M \{\mathbf{Q}^m\}^M_{m=1} {
Qm}m=1M上进行。此外,优化 L P
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1535
1535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











