







deep adversarial subspace clustering
前提知识
1. 子空间聚类
随着大数据时代的到来,产生了大量不一致数据、混合类型数据和部分值缺失的数据等。典型的聚类算法对这些数据集聚类时遇到难题。例如在高维稀疏数据中,簇类只存在部分属性构成的子空间中,这些数据集从全维空间来讲根本不存在簇类。一般来说,样本之间的差异往往是由若干个关键的特征所引起的,如果能恰当的找出这些重要特征,对建立合理的聚类或分类模型都将起到积极的作用。因此提出了子空间聚类。
子空间聚类算法是指把数据的原始特征空间分割为不同的特征子集,从不同的子空间角度考察各个数据簇聚类划分的意义,同时在聚类过程中为每个数据簇寻找到相应的特征子空间。总得来说,子空间聚类的任务主要有两个:
- 发现可以聚类的子空间(属性子集);
- 在相应的子空间上聚类。
子空间聚类算法实际上是将传统的特征选择技术和聚类算法进行结合,在对数据样本聚类划分的过程中,得到各个数据簇对应的特征子集或者特征权重。
子空间聚类可以分为硬子空间聚类和软子空间聚类两种形式。
-
硬子空间聚类
能识别不同类所在的精确子空间 -
软子空间聚类
不需要为每一个类找到精确的子空间,而是给每个类的特征赋予不同的权值,利用这些权值来衡量每维特征在不同类中的贡献,即软子空间聚类为每类找到一个软子空间
硬子空间聚类中,一个属性必须且只能属于一个子空间,聚类在这些子空间中进行,属性在每个子空间中的权值要么是0,要么是1。软子空间聚类是在全维空间对整个数据集聚类,每个子空间包含所有属性,但是每个属性被赋予[0,1]不同的权值,属性权值描述了属性与对应子空间之间的关联程度,权值越大说明该属性在这个子空间越重要,与该子空间的关联性也就越强。
2.LRR(低秩表示)
基本思想:一个数据(如图像或图像特征等)可以表示为干净数据部分和噪声部分,其中干净数据部分又可以采用字典和系数表示的形式。此时要求干净数据的系数表示部分是低秩的,噪声部分是稀疏的。此时,如果用数据本身作为字典,那么其系数部分就可以描述原始数据间的相似度。
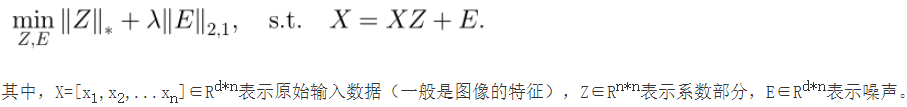
那么这个式子与聚类有什么关系呢?关系是,假设待聚类的数据分布于多个线性子空间,那么通过求解上述式子的最小化问题,我们可以得到数据X间的相似度矩阵Z,有了相似度矩阵我们就可以对输入数据X=[x1,x2,…xn]进行聚类。
因此,实现对多个d维数据xi的聚类,LRR方法采用的方法是,将xi按列组合成X,然后通过优化上述式子,得到Z,最后将Z输入到谱聚类算法中,就可以得到最终的聚类结果。
方法
对于图像做聚类,我们采用的方法是,对图像提取特征,然后得到特征表示,组成X,然后采用LRR原理进行聚类。但是这种先提取特征再进行聚类的缺点是一个两阶段的过程,两者不能互相促进。
所以深度子空间聚类(DSC)将特征提取和相似度矩阵的学习融入到一个网络中进行统一学习。重新定义符号表示,用X表示输入数据,Z表示特征,θ表示待学习的参数相似度矩阵,DSC目标函数:
m
i
n
∣
∣
Z
−
Z
θ
∣
∣
F
+
λ
∣
∣
θ
∣
∣
F
min||Z-Z_\theta ||_F + \lambda ||\theta ||_F
min∣∣Z−Zθ∣∣F+λ∣∣θ∣∣F
以求得参数Z和θ 。
网络架构:

损失函数:
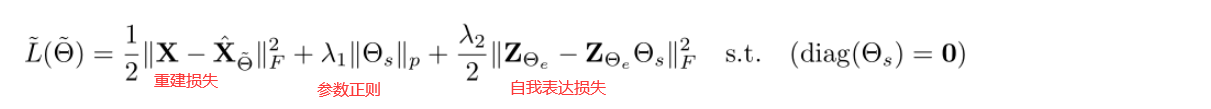
摘要
- 之前的子空间聚类需要手工选择表达方式,并且不知道隐藏空间的错误地方所在
- DASC(deep adversarial subspace clustering)= 子空间聚类的生成器 + 质量验证判别器(彼此对抗学习)
- generator:产生子空间估计和样本聚类
- discriminator:评估目前的聚类表现(通过采样)是否和子空间属性一致,让generator逐步产生和子空间一致的聚类。
第一个将GAN运用到子空间聚类上面
introduction
将深度学习运用到无监督学习的子空间聚类上面。传统方法局限于线性子空间,深度子空间聚类优势更加明显。深度子空间聚类可以提供更加强大样本表示并且有效的聚类来自非线性子空间的样本。更具有泛化性。
- 传统方法: 依靠自我表达作为监督,如果遇到不友好的分布表现也不会很好,并且不考虑所得聚类所存在的潜在错误,导致了有噪声的学习表示,从而降低了聚类性能。
-out method:用GAN去做聚类

generator:
- 使用Auto-encoder将原始输入示例转换为更好的表示形式,通过自表达层在线性子空间的联合集中
- 生成器基于内部自表达层产生的样本亲和矩阵产生子空间聚类结果。
- 它通过从估计的集群中采样来生成新的“假”样本,并将它们提供给鉴别器进行微分,以相应地评估子空间聚类的质量。
discriminator:
- 区分生成的“假”样本与提供的真实样本
- 根据线性子空间的性质来评估聚类结果的质量。
该论文的主要贡献:
- 引入对抗性学习来做子空间聚类
Method
DASC = DSC + GAN
问题:为什么引入GAN
传统聚类并不确定迭代到多少次效果比较好,也不能确定下次迭代就比上次得到的Z好。
用GAN来指导DSC的学习,使其每次都朝着效果更好的方向发展。
原理
前提知识:
一是,把处于同一子空间的数据,进行线性组合得到新的数据,那么新的数据依然处于该子空间。反之,处于不同子空间的数据,进行线性组合得到的数据跟原始数据处在不同子空间。

二是,处在同一子空间的数据,判别器(即分类器)分辨不出是真实数据还是伪造的数据,即输出概率为0.5。
所以
1. 聚类效果越好
2. 新数据仍然处于子空间
3. 判别器无法判别真假
我们希望,通过生成器得到的real data 和fake data(通过线性组合得到的假数据),输入到判别器中,经过对抗学习,得到更好的相似度矩阵θ 和特征表达Z,从而得到更好的聚类结果。

生成器
操作步骤:
-
通过encoder和self-expressive得到特征表示 Z i Z_i Zi , 然后得到亲和力矩阵,使用Ncut(一种聚类算法)得到 C i C_i Ci聚类。
-
计算聚类 C i C_i Ci中 Z i Z_i Zi到对应的子空间 S i S_i Si的投影残差 L r L_r Lr。这里的 S i S_i Si是由投影矩阵 U i U_i Ui来表示的, U i ( 可 以 说 是 S i ) U_i(可以说是S_i) Ui(可以说是Si)是判别器学习得到的,与生成器的学习没有关系。
-
选择投影残差 L r L_r Lr最小的80%~90%的 C i C_i Ci中的数据作为real data。
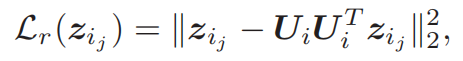
-
对我们得到的特征表示 Z i Z_i Zi经过随机线性组合计算得到与正品同等数量的fake data。(下面公式可以很直观的看出)
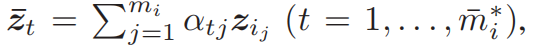
-
将real data和fake data给判别器D。

G的损失函数:
投影残差(后面判别器会解释到,为什么是这个公式)
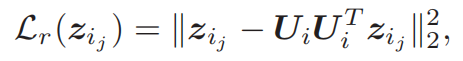

对于
L
a
L_a
La:就是希望G生成的fake data和real data越接近越好,也就是D不能区分fake data 和real data。
这里为什么是越小越好呢?这个得到的不是概率,是投影残差,投影残差越小代表说离子空间越接近。
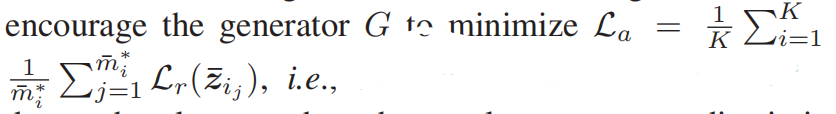
判别器
参数的学习
学习的参数为子投影矩阵Ui(代表子空间Si),用子空间来判别是正品还是次品。
投影残差
L
i
L_i
Li越小,说明是real data(文章中说能量越小)的概率越大,对判别器来说Loss的输出也应该越小。反之Loss就越大。
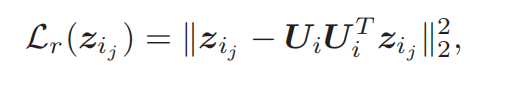
为什么这个损失函数是这个样子的呢?因为是判别器的结构。
- D的架构:两个全连接网络(共享参数 U i U_i Ui)
- 输入: Z j Z_j Zj
- 经过第一层得到: U i z j U_iz_j Uizj
- 经过第二层得到: U i U i T z j U_iU_i^{T}z_j UiUiTzj
- 损失——输入输出越接近越好
损失函数
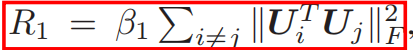

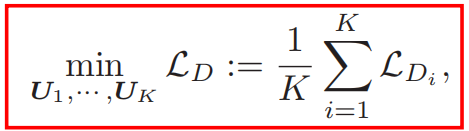
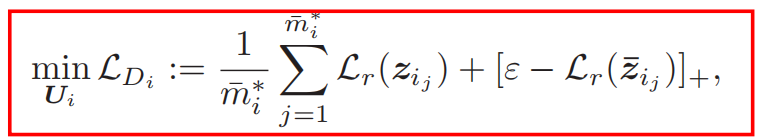
[
⋅
]
+
=
m
a
x
(
0
,
⋅
)
[·]_+ = max(0, ·)
[⋅]+=max(0,⋅)
details
- 投影矩阵Ui和类簇Ci并不是一一对应的关系,因为每次更新都需要找一下是否子空间投影矩阵是否有变化,所以需要Ci进行竞争Ui。
- 竞争的方式是,对每个类簇计算平均投影残差,然后选择具有最小平均残差的Ui作为自己的投影矩阵。
- 如果该Ui具有更小平均投影残差的类簇,那么原类簇则采用对Z进行QR分解来得到自己的Ui。
- 判别器采用两层全连接感知机。
训练
步骤:
- DSC预训练初始化DASC网络
- 用 Z i Z_i Zi的QR分解初始化 U i U_i Ui
- 联合交替更新DASC中的D和G,D更新5次,G更新一次。
总结
- 该文章采用了DSC+GAN的方式,是GAN在无监督聚类上的首次成功运用
- 文章对无监督的聚类进行了定性的评估:线性组合在同一子空间(不能被判别器正确识别)说明聚类效果好。
- 文章对无监督聚类进行了定量的评估:据子空间的投影残差越小说明属于真实数据的概率越大。















 1776
1776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









