







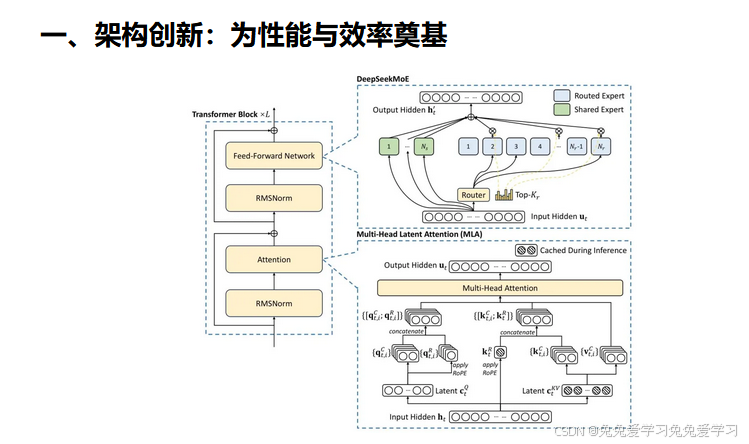
(一)Multi-head Latent Attention(MLA)
DeepSeek-V3 采用了 MLA 架构来高效处理长文本。传统 Transformer 中的注意力机制在处理长文本时会面临 KV Cache 过大导致显存占用高的问题。MLA 通过将 Key(K)和 Value(V)联合映射至低维潜空间向量(cKV),显著降低了 KV Cache 的大小。在 DeepSeek-V3 中,MLA 的 KV 压缩维度(dc)设置为 512,Query 压缩维度(d’)设置为 1536,解耦 Key 的头维度(dr)设置为 64。这种设计在保证模型性能的同时,大幅减少了显存占用和计算开销,使得模型能够更高效地处理长文本,为后续的长上下文扩展训练奠定了基础。
二)DeepSeekMoE 架构
为了实现模型容量的高效扩展,DeepSeek-V3 采用了 DeepSeekMoE 架构。该架构通过细粒度专家、共享专家和 Top-K 路由策略,让模型在不显著增加计算成本的情况下拥有庞大的模型容量。具体来说,每个 MoE 层包含 1 个共享专家和 256 个路由专家,每个 Token 选择 8 个路由专家,最多路由至 4 个节点。这种稀疏激活的机制,使得 DeepSeek-V3 在处理大规模数据时能够更加灵活地分配计算资源,提升了整体的训练效率和性能表现。
(三)无额外损耗的负载均衡策略
在 MoE 架构中,负载均衡是一个关键问题。传统的辅助损失方法虽然可以实现负载均衡,但会对模型性能产生负面影响。DeepSeek-V3 提出了一种创新的无额外损耗负载均衡策略,通过引入并动态调整可学习的偏置项(Bias Term)来影响路由决策。该策略的偏置项更新速度(γ)在预训练的前 14.3T 个 Token 中设置为 0.001,剩余 500B 个 Token 中设置为 0.0;序列级平衡损失因子(α)设置为 0.0001。这种策略使得模型在训练过程中能够更好地平衡各专家的负载,避免了因负载不均衡导致的性能下降,同时也不会对模型性能产生额外的损耗。


二)高效的跨节点全节点通信实现
跨节点 MoE 训练的一大挑战是巨大的通信开销。DeepSeek-V3 通过一系列精细的优化策略,有效地缓解了这一瓶颈。具体包括:
首先,采用了节点限制路由(Node-Limited Routing),将每个 Token 最多路由到 4 个节点,有效限制了跨节点通信的范围和规模。
其次,定制了高效的跨节点 All-to-All 通信内核,这些内核充分利用了 IB(InfiniBand)和 NVLink 的带宽,并最大程度地减少了用于通信的 SM(Streaming Multiprocessors)数量。
此外,还采用了 Warp 专业化(Warp Specialization),将不同的通信任务分配给不同的 Warp,并根据实际负载情况动态调整每个任务的 Warp 数量,实现了通信任务的精细化管理和优化。
最后,通过自动调整通信块大小,减少了对 L2 缓存的依赖,降低了对其他计算内核的干扰,进一步提升了通信效率。
这些通信优化策略的综合运用,使得 DeepSeek-V3 在大规模分布式训练中能够高效地进行数据交换,减少了通信延迟,加快了训练速度。
(三)极致的内存节省
DeepSeek-V3 在内存管理方面也做到了极致,通过多种策略最大程度地减少了内存占用:
RMSNorm 和 MLA 上投影的重计算:在反向传播过程中,DeepSeek-V3 会重新计算 RMSNorm 和 MLA 上投影的输出,而不是将这些中间结果存储在显存中。这种策略虽然会略微增加计算量,但可以显著降低显存占用。
CPU 上的 EMA:DeepSeek-V3 将模型参数的 EMA 存储在 CPU 内存中,并异步更新。这种策略避免了在 GPU 上存储 EMA 参数带来的额外显存开销。
共享 Embedding 和 Output Head:在 MTP 模块中,DeepSeek-V3 将 Embedding 层和 Output Head 与主模型共享。这种设计减少了模型的参数量和内存占用。
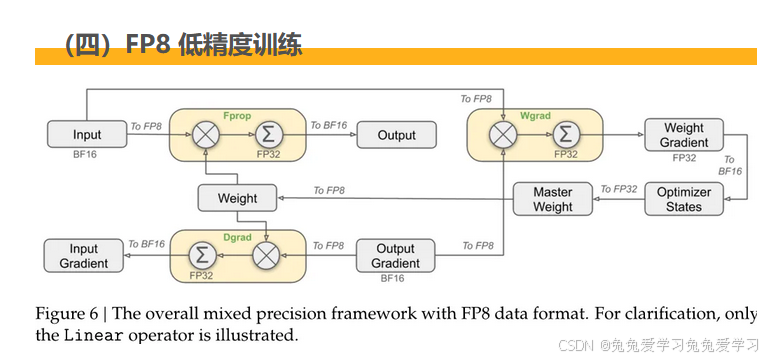
为了进一步降低训练成本,DeepSeek-V3 采用了 FP8 混合精度训练。FP8 是一种低精度的数据格式,相较于传统的 FP32 或 BF16,它能够显著减少显存占用和计算开销。然而,低精度训练也面临着精度损失的问题。DeepSeek-V3 通过一系列创新的方法,解决了这一难题。
首先,对于模型中对精度较为敏感的组件(如 Embedding、Output Head、MoE Gating、Normalization、Attention 等),仍然采用 BF16 或 FP32 进行计算,以保证模型的性能。
其次,采用了细粒度量化(Fine-Grained Quantization),对激活值采用 1x128 tile-wise 量化,对权重采用 128x128 block-wise 量化,这种策略可以更好地适应数据的分布,减少量化误差。
此外,为了减少 FP8 计算过程中的精度损失,DeepSeek-V3 将 MMA(Matrix Multiply-Accumulate)操作的中间结果累加到 FP32 寄存器中,提高了累加精度。
最后,将激活值和优化器状态以 FP8 或 BF16 格式进行存储,并在通信过程中也使用这些低精度格式,进一步降低了显存占用和通信开销。
通过这些策略,DeepSeek-V3 在保证模型精度的同时,大幅降低了训练成本,提高了训练效率。
三、预训练策略:构建高质量数据与优化训练过程
(一)构建高质量数据
DeepSeek-V3 的预训练语料库规模达到了14.8 万亿 Token,这些数据经过了严格的筛选和清洗,以确保其高质量和多样性。相比于前代模型 DeepSeek-V2,新模型的数据构建策略更加精细,主要体现在以下几个方面:
提升数学和编程相关数据占比:大幅提升了数学和编程相关数据在整体数据中的占比,这直接增强了模型在相关领域的推理能力,使其在 MATH 500、AIME 2024 等数学基准测试和 HumanEval、LiveCodeBench 等代码基准测试中表现突出。
扩展多语言数据覆盖范围:进一步扩展了多语言数据的覆盖范围,超越了传统的英语和中文,提升了模型的多语言处理能力。
最小化数据冗余:开发了一套完善的数据处理流程,着重于最小化数据冗余,同时保留数据的多样性。
文档级打包方法:借鉴了近期研究中提出的文档级打包方法,将多个文档拼接成一个训练样本,避免了传统方法中由于截断导致的上下文信息丢失,确保模型能够学习到更完整的语义信息。
Fill-in-Middle (FIM) 策略:针对代码数据,DeepSeek-V3 借鉴了 DeepSeekCoder-V2 中采用的 FIM 策略,以 0.1 的比例将代码数据构造成 <|fim_begin|> pre<|fim_hole|> suf<|fim_end|> middle<|eos_token|> 的形式。这种策略通过“填空”的方式,迫使模型学习代码的上下文关系,从而提升代码生成和补全的准确性。
(二)优化训练过程
分词器与词表
DeepSeek-V3 采用了基于字节级 BPE 的分词器,并构建了一个包含 128K 个 token 的词表。为了优化多语言的压缩效率,DeepSeek 对预分词器和训练数据进行了专门的调整。
与 DeepSeek-V2 相比,新的预分词器引入了将标点符号和换行符组合成新 token 的机制。这种方法可以提高压缩率,但也可能在处理不带换行符的多行输入时引入 token 边界偏差。
为了减轻这种偏差,DeepSeek-V3 在训练过程中以一定概率随机地将这些组合 token 拆分开来,从而让模型能够适应更多样化的输入形式,提升了模型的鲁棒性。
模型配置与超参数:
模型配置
DeepSeek-V3 的 Transformer 层数设置为 61 层,隐藏层维度为 7168。所有可学习参数均采用标准差为 0.006 的随机初始化。
在 MLA 结构中,注意力头的数量 (nh) 设置为 128,每个注意力头的维度 (dh) 为 128,KV 压缩维度 (dc) 为 512,Query 压缩维度 (d’) 为 1536,解耦的 Key 头的维度 (dr) 为 64。
除了前三层之外,其余的 FFN 层均替换为 MoE 层。每个 MoE 层包含 1 个共享专家和 256 个路由专家,每个专家的中间隐藏层维度为 2048。每个 Token 会被路由到 8 个专家,并且最多会被路由到 4 个节点。
多 Token 预测的深度 (D) 设置为 1,即除了预测当前 Token 之外,还会额外预测下一个 Token。此外,DeepSeek-V3 还在压缩的潜变量之后添加了额外的 RMSNorm 层,并在宽度瓶颈处乘以了额外的缩放因子。
训练超参数
优化器:DeepSeek-V3 采用了 AdamW 优化器,β1 设置为 0.9,β2 设置为 0.95,权重衰减系数 设置为 0.1。最大序列长度设置为 4K。
学习率方面:采用了组合式的调度策略:在前 2K 步,学习率从 0 线性增加到 2.2 × 10^-4;然后保持 2.2 × 10^-4 的学习率直到模型处理完 10T 个 Token;接下来,在 4.3T 个 Token 的过程中,学习率按照余弦曲线逐渐衰减至 2.2 × 10^-5;在最后的 500B 个 Token 中,学习率先保持 2.2 × 10^-5 不变,然后切换到一个更小的常数学习率 7.3 × 10^-6。梯度裁剪的范数设置为 1.0。
Batch Size 方面:采用了动态调整的策略,在前 469B 个 Token 的训练过程中,Batch Size 从 3072 逐渐增加到 15360,并在之后的训练中保持 15360 不变。
负载均衡:为了实现 MoE 架构中的负载均衡,DeepSeek-V3 采用了无额外损耗的负载均衡策略,并将偏置项的更新速度 (γ) 在预训练的前 14.3T 个 Token 中设置为 0.001,在剩余的 500B 个 Token 中设置为 0.0。序列级平衡损失因子 (α) 设置为 0.0001,以避免单个序列内的极端不平衡。多 Token 预测损失的权重 (λ) 在前 10T 个 Token 中设置为 0.3,在剩余的 4.8T 个 Token 中设置为 0.1。
长上下文扩展与多 Token 预测:
图片
长上下文扩展
为了使 DeepSeek-V3 具备处理长文本的能力,DeepSeek 采用了两阶段的训练策略,将模型的上下文窗口从 4K 逐步扩展到 128K。他们采用了 YaRN 技术,并将其应用于解耦的共享 Key (k)。
在长上下文扩展阶段:DeepSeek-V3 的超参数保持不变:scale 设置为 40,β 设置为 1,ρ 设置为 32,缩放因子设置为 0.1 ln n + 1。
第一阶段 (4K -> 32K):序列长度设置为 32K,Batch Size 设置为 1920,学习率设置为 7.3 × 10^-6。
第二阶段 (32K -> 128K):序列长度设置为 128K,Batch Size 设置为 480,学习率设置为 7.3 × 10^-6。上图的 "Needle In A Haystack" (NIAH) 测试结果清晰地展示了 DeepSeek-V3 在处理长文本方面的卓越能力。
多 Token 预测:DeepSeek-V3 还采用了多 Token 预测策略,要求模型在每个位置预测未来的多个 Token,而不仅仅是下一个 Token。
这种策略增强了模型的预见能力,并提供了更丰富的训练信号,从而提升了训练效率。
四、后训练:知识蒸馏与强化学习的强化
在预训练阶段之后,DeepSeek-V3 进入了后训练阶段,这一阶段主要包括监督微调(Supervised Fine-Tuning, SFT)和强化学习(Reinforcement Learning, RL),通过这两个阶段的训练,DeepSeek-V3 的性能得到了进一步的提升,使其能够更好地理解和生成符合人类偏好的文本。
(一)监督微调(SFT)
监督微调是后训练阶段的第一步,其目的是通过大量标注数据对模型进行微调,使其能够更好地理解人类的语言和指令。
DeepSeek-V3 的 SFT 数据集包含了 150 万条来自多个领域的标注数据,这些数据涵盖了数学、编程、逻辑推理、创意写作、角色扮演和简单问答等多个领域。为了生成高质量的 SFT 数据,DeepSeek 团队采用了以下方法:
推理数据生成:对于数学、编程和逻辑推理等需要复杂推理的任务,DeepSeek 团队利用内部的 DeepSeek-R1 模型生成数据。R1 模型虽然在推理准确性方面表现出色,但存在思考过多、格式不佳和回答过长等问题。为了平衡 R1 模型的高准确性和清晰简洁的格式,DeepSeek 团队开发了一种专家模型,通过 SFT 和 RL 训练流程,生成高质量的 SFT 数据。具体来说,对于每个实例,专家模型会生成两种类型的 SFT 样本:一种是将问题与原始回答配对,格式为 <问题,原始回答>;另一种是在系统提示、问题和 R1 回答之间插入系统提示,格式为 <系统提示,问题,R1 回答>。系统提示经过精心设计,旨在引导模型生成具有反思和验证机制的响应。
非推理数据生成:对于创意写作、角色扮演和简单问答等不需要复杂推理的任务,DeepSeek 团队使用 DeepSeek-V2.5 生成回答,并由人工标注员验证数据的准确性和正确性。在 SFT 训练过程中,DeepSeek-V3 使用了 AdamW 优化器,学习率采用余弦衰减策略,从 5 × 10^-6 逐渐降低到 1 × 10^-6,并进行了两个 epoch 的训练。为了确保每个序列中的样本相互独立,DeepSeek 团队采用了样本掩码策略。



















 2487
2487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









