







目录
微软亚洲研究院(Microsoft Research Asia)
克利夫兰州立大学(Cleveland State University)
微软亚洲研究院(Microsoft Research Asia)
数据处理增强(Data Processing Enhancement)
数据检索增强 Data Retrieval Enhancement
响应生成增强 Response Generation Enhancement
克利夫兰州立大学(Cleveland State University)
克利夫兰州立大学(Cleveland State University)
什么是RAG
RAG的来源与定义
Meta
2020年5月,检索增强生成(RAG)框架在Meta发布的论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》中首次被提出,作者认为:“通过一种通用的微调方法赋予预训练的参数化记忆生成模型非参数化记忆,称之为检索增强生成(RAG)。”
We endow pre-trained, parametric-memory generation models with a non-parametric memory througha general-purpose fine-tuning approach which we refer to as retrieval-augmented generation (RAG).
通过一种通用的微调方法赋予预训练的参数化记忆生成模型非参数化记忆,我们称之为检索增强生成(RAG)。
We build RAG models where the parametric memory is a pre-trained seq2seq transformer, and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever.
建立了RAG模型,其中参数内存是一个预训练的seq2seq转换器,而非参数内存是维基百科的密集向量索引,使用预训练的神经检索器访问。
【原文地址】
[2005.11401] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
同济大学 & 复旦大学
2023年12月,同济大学、复旦大学发表的综述《Retrieval-Augmented Generation for Large Language Models A Survey》中给出的RAG定义为:“检索增强生成,通过语义相似度计算从外部知识库中检索相关文档块来增强LLMs。通过引用外部知识,RAG有效地减少了生成事实性错误内容的问题。”
Retrieval-Augmented Generation(RAG) enhances LLMs by retrieving relevant document chunks fromexternal knowledge base through semantic similarity calculation.By referencing external knowledge,RAG effectively reduces the problem of generating factually incorrect content.
【原文地址】
[2312.10997] Retrieval-Augmented Generation for Large Language Models: A Survey
微软亚洲研究院(Microsoft Research Asia)
2024年9月,微软亚洲研究院发表的论文《Retrieval Augmented Generation (RAG) and Beyond: A Comprehensive Survey on How to Make your LLMs use External Data More Wisely》中给出的RAG定义为:“检索-增强生成是指语言模型在生成过程中通过动态检索外部信息来增强其自然语言生成能力的一种方法。该技术融合了LLMs的生成能力和从广泛的数据库或文档中检索信息的能力。该过程通常实现为数据索引构建、检索系统构建和答案生成。”
Retrieval-Augmented Generation refers to a methodology where a language model augments its natural language generation capabilities by dynamically retrieving external information during the generation process. This technique blends the generative capabilities of LLMs with the information retrieval from extensive databases or documents. The process is typically implemented as data index construction, retrieval system construction and answer generation.
【原文地址】
卡内基梅隆大学
2024年10月,卡内基梅隆大学发表的综述《A Comprehensive Survey of Retrieval-Augmented Generation (RAG): Evolution, CurrentLandscape and Future Directions》中给出的RAG定义为:“检索增强生成是一种新兴的混合架构,旨在解决纯生成式模型的局限性。RAG集成了两个关键组件:( i )检索机制,从外部知识源中检索相关文档或信息;( ii )生成模块,处理这些信息以生成类人文本。这种结合使得RAG模型不仅可以生成流畅的文本,而且可以在真实世界的、最新的数据中建立它们的输出。”
Retrieval-Augmented Generation (RAG) is an emerging hybrid architecture designed to address the limitations of pure generative models. RAG integrates two key components: (i) a retrieval mechanism,which retrieves relevant documents or information from an external knowledge source, and (ii) ageneration module, which processes this information to generate human-like text (Lewis et al. 2020). Thiscombination allows RAG models to not only generate fluent text but also ground their outputs inreal-world, up-to-date data.
【原文地址】
克利夫兰州立大学(Cleveland State University)
2025年1月,克利夫兰州立大学发表的综述《AGENTIC RETRIEVAL-AUGMENTED GENERATION: A SURVEY ONAGENTIC RAG》中给出的RAG定义为:“检索增强生成结合了大语言模型的生成能力和实时数据检索能力,代表了人工智能领域的重大进步。虽然LLMs在自然语言处理方面表现出了卓越的能力,但它们依赖于静态的预训练数据,往往会导致过时或不完整的响应。RAG通过从外部资源中动态地检索相关信息并将其纳入生成过程来解决这一限制,从而实现上下文准确和更新的输出。”
Retrieval-Augmented Generation (RAG) represents a significant advancement in the field of artificial intelligence,combining the generative capabilities of Large Language Models (LLMs) with real-time data retrieval. While LLM shave demonstrated remarkable capabilities in natural language processing, their reliance on static pre-trained dataoften results in outdated or incomplete responses. RAG addresses this limitation by dynamically retrieving relevant information from external sources and incorporating it into the generative process, enabling contextually accurate andup-to-date outputs.
【原文地址】
[2501.09136] Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG
《大模型RAG实战》
作者王鹏在书中定义RAG为:“该框架可以使模型访问超出其训练数据范围之外的信息,使得模型在每次生成时可以利用检索提供的外部更专业、更准确的知识,从而更好地回答用户问题。”
RAG的组成
Meta
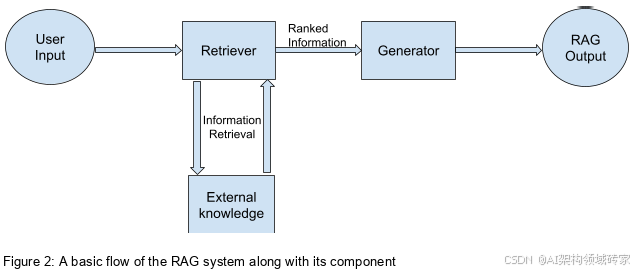
根据Meta发布的论文中的介绍,如图所示。RAG由两个部分组成:检索器(Retriever)、生成器(Gemerator)。
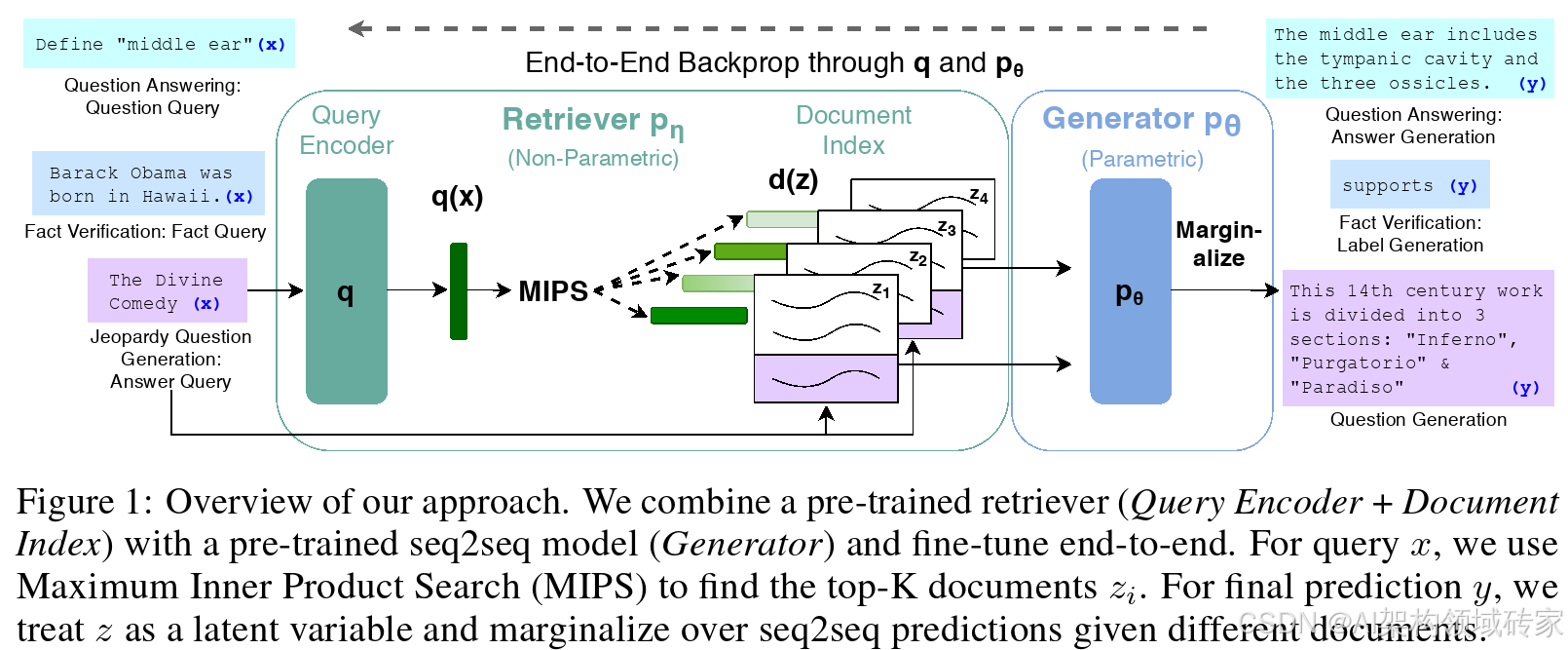
检索器(Retriever)
检索器组件是基于稠密段落检索技术(DPR,Dense Passage Retrieval)。
生成器(Gemerator)
生成器组件可以使用任何编码器-解码器建模。
同济大学 & 复旦大学
根据论文中的介绍,RAG核心组件为:检索(Retrieval)、生成(Generation)、增强(Augmentation)。
检索(Retrieval)
在RAG的背景下,从数据源中高效地检索相关文档是至关重要的。其中涉及到几个关键问题,如检索源、检索粒度、检索的预处理以及相应嵌入模型的选择等。
In the context of RAG,it is crucial to efficiently retrieve relevant documents from the data source.There are several key issues involved,such as the retrieval source,retrieval granularity,pre-processing of the retrieval,and selection of the corresponding embedding model.
生成(Generation)
在检索之后,直接将所有检索到的信息输入到LLM中回答问题并不是一种很好的做法。需要调整检索内容(Context Curation)和调整LLM(LLM Fine-tuning)。
- 内容管理(Context Curation):包括重排序(Reranking)、内容选择/压缩(Context Selection/Compression)。
- LLM微调(LLM Fine-tuning):在LLMs上根据场景和数据特征进行有针对性的微调可以产生更好的效果。
增强(Augmentation)
在RAG领域,标准的做法往往涉及一个单一的检索步骤,然后生成,这可能导致效率低下,有时对于需要多步推理的复杂问题来说通常是不够的,因为它提供的信息范围有限。许多研究针对这一问题对检索过程进行了优化,如图所示。具体包括迭代检索(Iterative Retrieval)、递归检索(Recursive Retrieval)、自适应检索(Adaptive Retrieval)。
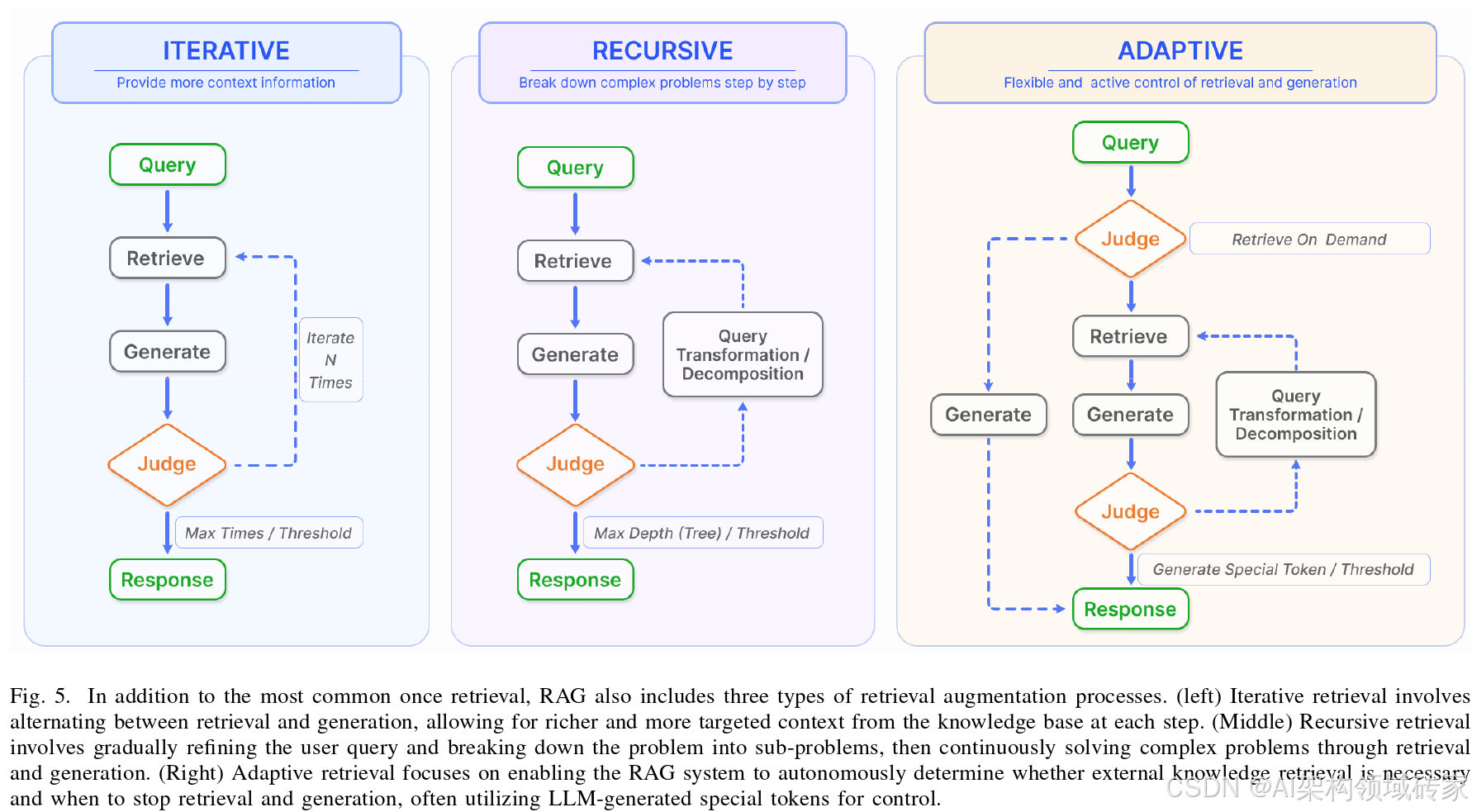
微软亚洲研究院(Microsoft Research Asia)
数据处理增强(Data Processing Enhancement)
该级别的文档解析通常涉及以连贯的方式从文本、表格和图形中提取信息,以确保相关片段被准确识别和检索。
数据检索增强 Data Retrieval Enhancement
信息检索( Information Retrieval,IR )技术可以平滑地移植到RAG应用中。涉及的主要步骤包括建立数据索引、处理查询、检索匹配、重排序和评估。
索引这个步骤的目的是建立从检索词到文本片段的映射,确定检索系统运行的逻辑。索引方法大致分为三类:稀疏(Sparse Retrieval)、稠密(Dense Retrieval)和混合检索。
响应生成增强 Response Generation Enhancement
生成响应需要确定检索到的信息是否足够或是否需要额外的外部数据。
卡内基梅隆大学
RAG集成了两个关键组件:检索机制、生成模块。
检索机制
从外部知识源中检索相关文档或信息。使用稠密段落检索技术( DPR )或传统BM25检索算法等技术从语料库中检索最相关的文档。
生成模块
处理这些信息以生成类人文本。它将检索到的文档合成为连贯的、上下文相关的响应。
克利夫兰州立大学(Cleveland State University)
RAG系统的体系结构集成了三个主要组成部分:
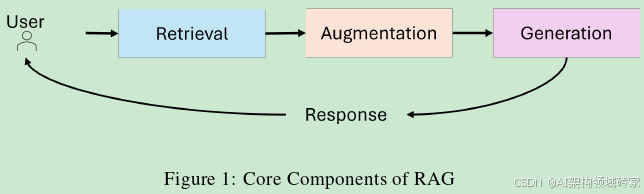
检索(Retrieveal)
负责查询外部数据源,如知识库、API或矢量数据库等。高级检索器利用密集向量搜索和基于Transformer的模型来提高检索精度和语义相关性。
增强(Augmentation)
对检索到的数据进行处理,提取和总结最相关的信息,使其与查询上下文对齐。
生成(Generation)
将检索到的信息与LLM的预训练知识相结合,以生成连贯的、上下文适当的响应。
北京大学
2024年2月,北京大学发表的综述《Retrieval-Augmented Generation for AI-Generated Content: A Survey》认为,整个RAG系统由两个核心模块组成:检索器和生成器,其中检索器从数据存储中搜索相关信息,生成器产生所需内容。
【原文地址】
[2402.19473] Retrieval-Augmented Generation for AI-Generated Content: A Survey
检索器
检索是在给定信息需求的情况下,识别并获取相关信息。具体来说,可以概念化为键值存储的信息资源,其中每个键对应一个值(键和值可以是相同的)。给定一个查询,目标是使用一个相似度函数搜索前k个最相似的键,并获得配对值。根据相似度函数的不同,现有的检索方法可以分为稀疏检索、稠密检索等。在广泛使用的稀疏和稠密检索中,整个过程可以分为两个不同的阶段:
( i )每个对象首先被编码成一个特定的表示;
( ii )构建索引来组织数据源进行高效的搜索
生成器
不同的生成模型适用于不同的场景,如文本到文本任务的Transformer模型、图像到文本任务的Visual GPT、文本到图像任务的Stable Diffusion、文本到代码任务的Codex等。RAG中经常使用的4种典型生成器:Transformer模型、LSTM、扩散模型和GAN。
RAG工作流
同济大学 & 复旦大学
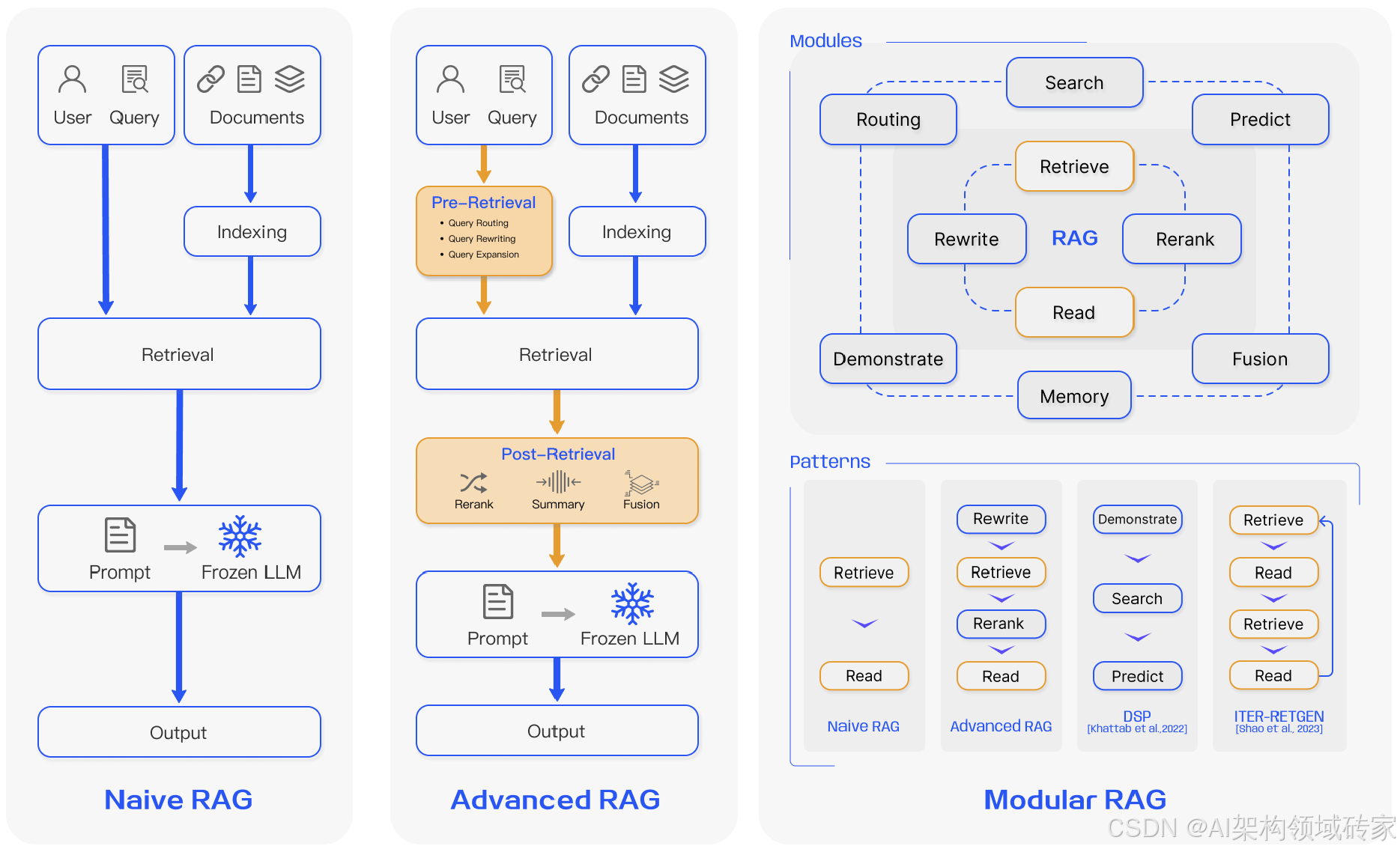
- 朴素RAG(Naive RAG):遵循索引、检索和生成的传统流程,也被称为“检索-阅读”框架。
The Naive RAG follows a traditional process that includes indexing,retrieval,and generation,which is also characterized as a “Retrieve-Read” framework。
- 高级RAG(Advanced RAG):高级RAG引入了特定的改进来克服朴素RAG的局限性。以提高检索质量为重点,采用了检索前策略和检索后策略。
Advanced RAG introduces specific improvements to over-come the limitations of Naive RAG.Focusing on enhancing re-trieval quality,it employs pre-retrieval and post-retrieval strategies.
- 模块化RAG(Modular RAG):模块化RAG架构超越了前两种RAG范例,提供了增强的适应性和多功能性。它采用多种策略来改进其组件,例如为相似搜索添加搜索模块,并通过微调来改进检索器。
The modular RAG architecture advances beyond the former two RAG paradigms,offering enhanced adaptability andversatility.It incorporates diverse strategies for improving itscomponents,such as adding a search module for similaritysearches and refining the retriever through fine-tuning.
卡内基梅隆大学
RAG及其组件的基本流程。
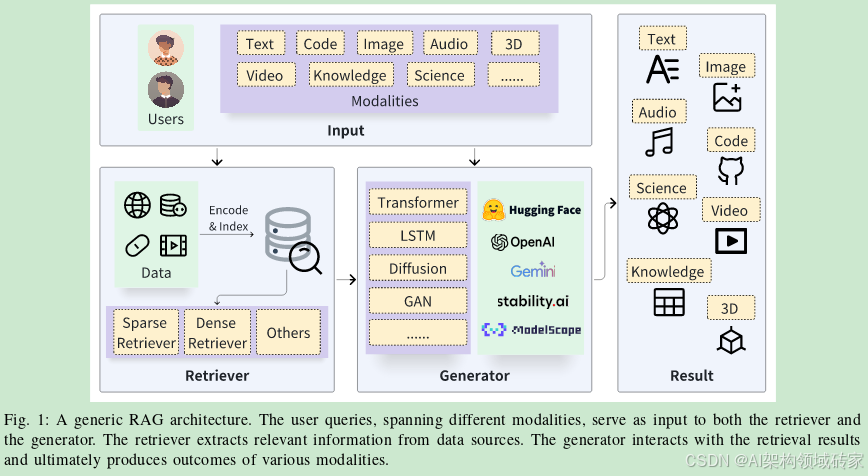
北京大学
RAG过程如下:( i )检索器最初接收输入的查询并搜索相关信息;( ii )然后,通过特定的增强方法将原始查询和检索结果输入生成器;( iii )最后,生成器产生期望的结果。
The RAG process unfolds as follows: (i) the retriever initially receivesthe input query and searches for relevant information; (ii) then,the original query and the retrieval results are fed into thegenerator through a specific augmentation methodology; (iii)finally, the generator produces the desired outcomes.
根据检索器如何增强生成器,将RAG分为4类:
- 基于查询的RAG(Query-based RAG):源自于prompt增强的思想,它将用户的查询与检索信息中的见解无缝地结合在一起,直接反馈到生成器输入的初始阶段。该方法在RAG应用中较为普遍。在检索后,将得到的内容与用户的原始查询合并形成复合输入,然后由生成器处理以创建响应。基于查询的RAG广泛用于各种模态。
Stemming from the idea of prompt augmentation, query-based RAG seamlessly integrates the user’s query with insights from retrieved information, feeding it directly into the initial stage of the generator’s input. This method is prevalent in RAG applications. Post-retrieval, the obtained content is merged with the user’s original query to form a composite input, which is then processed by the generator to create a response. Query-based RAG is widely employed across various modalities.
- 基于潜在表示的RAG(Latent Representation-based RAG):在基于潜在表示的RAG框架中,检索对象作为潜在表示被纳入到生成模型中。这增强了模型的理解能力,提高了生成内容的质量。
In latent representation-based RAG framework, retrieved objects areincorporated into generative models as latent representations.This enhances the model’s comprehension abilities andimproves the quality of the generated content.
- 基于Logit的RAG(Logit-based RAG):在基于logit的RAG中,生成式模型在解码过程中通过logit整合检索信息。通常,通过简单的求和或模型组合logits来计算分步生成的概率。
In logit-based RAG, generative models integrate retrieval information through logits during the decoding process. Typically, the logits are combined through simple summation or models to compute the probabilities for step-wise generation.
- 推测式RAG(Speculative RAG):推测式RAG寻求使用检索而不是纯生成的机会,旨在节约资源和加快响应速度。
Speculative RAG seeks opportunitiesto use retrieval instead of pure generation, aiming to save resources and accelerate response speed.
克利夫兰州立大学(Cleveland State University)
RAG范式的发展,呈现了关键的发展阶段——朴素RAG、高级RAG、模块化RAG、图RAG和Agentic RAG。其中,朴素RAG、高级RAG、模块化RAG引用的同济大学、复旦大学综述中的概念。
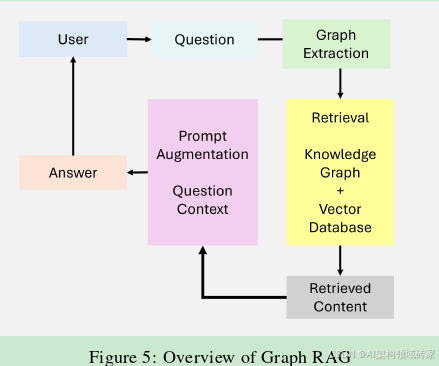
- 图RAG(Graph RAG):通过集成基于图的数据结构,扩展了传统的检索增强生成系统,如图所示。这些系统利用图数据中的关系和层次结构来增强多跳推理和上下文丰富。通过结合基于图的检索,Graph RAG可以实现更丰富、更准确的生成输出,特别是对于需要关系理解的任务。
- 代理RAG(Agentic RAG):通过引入能够进行动态决策和工作流优化的自治Agent,代表了一种范式的转变。与静态系统不同,Agentic RAG采用迭代求精和自适应检索策略来处理复杂、实时和多领域的查询。该范式在引入Agent自主性的同时,利用了检索和生成过程的模块化。


















 6093
6093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









