






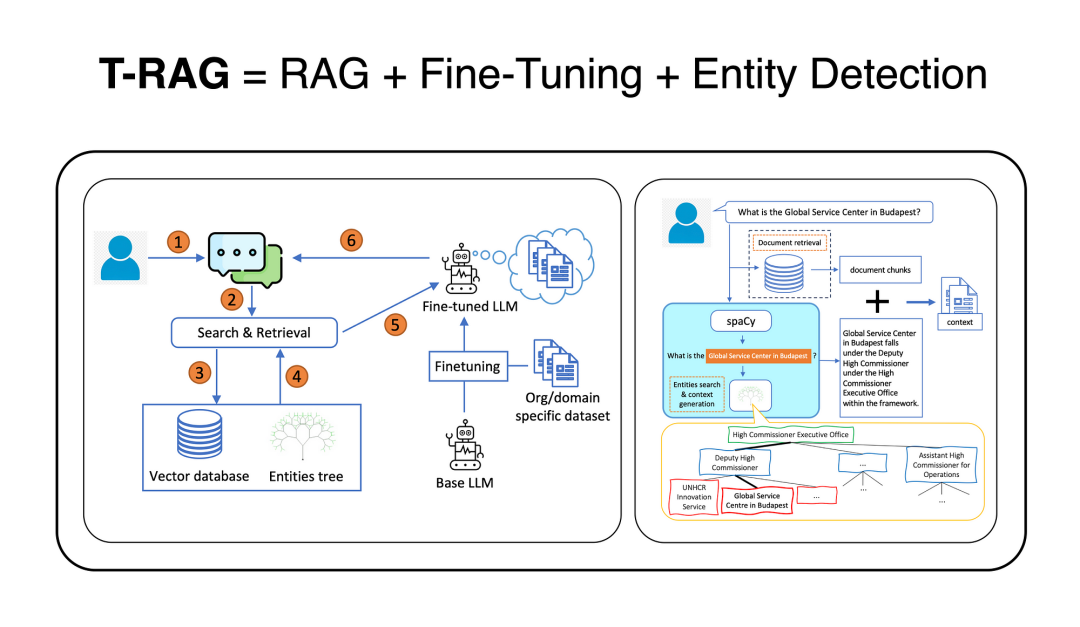
T-RAG技术将 RAG 架构与开源的微调语言模型 (LLM) 和实体树向量数据库相结合的基础之上,用于支持语境检索。
图片
背景介绍
大型语言模型 (LLM) 在各个领域得到越来越广泛的应用,尤其在使用私有企业文档的问答场景中。但由于数据安全性和模型稳定性至关重要,定制化成为必然。
本文分享了针对企业私有文档、使用 Tree-RAG (T-RAG) 系统部署 LLM 问答应用的经验。
这种方法集成了实体层级信息以获取更优异的表现,而评估结果验证了它的有效性。这些经验对于将 LLM 落地到实际应用中具有实际指导意义。
数据隐私
由于文档的敏感性,安全风险成为首要考虑。为避免数据泄露,使用公有 API 调用私有 LLM 模型的方法变得行不通。这就需要使用可以部署在内部的开源模型。此外,有限的计算资源和基于现有文档建立的小型训练数据集都会带来相应的挑战。
如何在这样的环境下确保对用户问询提供可靠、准确的响应,就需要大量的定制化工作,进而衍生出了一系列复杂的考量因素。
技术亮点
这项研究的价值在于,他们提出了一种结合检索增强生成 (RAG) 方法和基于企业文档数据集微调的开源 LLM 模型的应用。
此外,本研究还提出了一个新的评估指标,称为“Correct-Verbose”。旨在评估所生成回复的质量。该指标既考察答复的正确性,也兼顾答案是否涵盖了问题范围之外的其他相关信息。
T-RAG
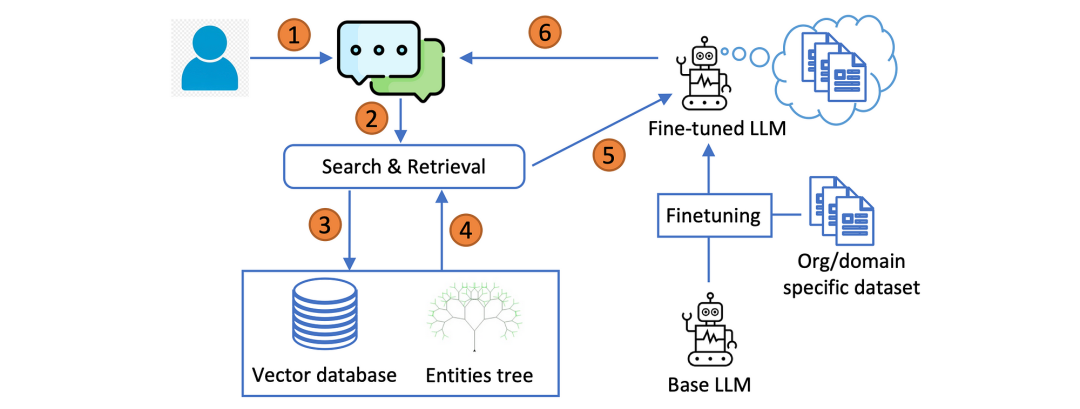
Tree-RAG (T-RAG) 的工作流程如下...
在面对用户的问题时,系统先从向量数据库中搜索相关的文档片段用作 LLM 的背景知识。
如果查询中提到了任何与组织相关的实体,系统将从实体树中提取关于这些实体的信息并添加到背景知识中。随后,经过微调的 Llama-27B 模型会根据已呈现的信息生成答复。
图片
实体树
T-RAG 的一个显著特点是在向量数据库之外引入了实体树 (entities tree) 来辅助语境检索。这个实体树中储存了与企业组织相关实体的详细信息以及它们的层级结构。树中的每个节点都代表一个实体,父节点表明该实体所属的组别。
在检索过程中,T-RAG 可以利用实体树来增强从向量数据库中检索到的语境信息。实体树的查询和语境生成过程如下:
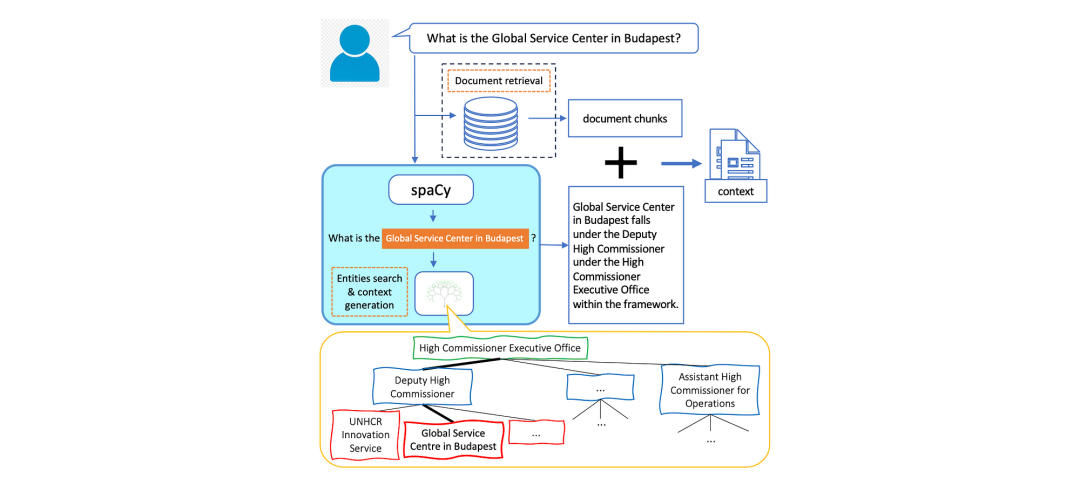
首先,一个解析器模块会在用户的查询中扫描与组织内部实体名称相对应的关键字。
如果识别出一个或多个匹配项,会从实体树中提取关于每个匹配实体的详细信息。
这些细节被转化为文本语句,提供关于该实体及其在组织层级结构中位置的信息。
随后,这些信息会与从向量数据库中检索到的文档块相结合,以构建最终的语境。
通过这种方法,当用户提出关于特定实体的问题时,模型可以获取有关这些实体及其在组织中的层级位置的结构化知识。
图片
结合上图,我们用一个组织结构图中的实例来直观说明语境生成过程中的树搜索和检索过程。
除了获取相关的背景文档,系统还使用 spaCy 库以及自定义规则识别出组织内的命名实体。
如果查询中包含一个或多个这样的实体,那么系统会从实体树中提取出关于该实体层级位置的相关信息,并将其转化为文本语句。
这些语句随后与检索到的文档一起被整合为最终的语境。
值得注意的是,如果用户的查询中没有提及任何实体,那么系统将会跳过树搜索步骤,仅使用从检索文档中获取的语境。
总结
这项研究具有一定的启发性,因为它将 RAG 方法、模型微调与实体识别相结合。一方面,通过使用内部部署的开源模型来解决数据隐私问题;另一方面,有效地降低了推理延迟、token 使用成本,同时也兼顾了不同地区的用户需求。
此外,研究中采用了 spaCy 框架进行实体搜索和语境生成,这一方法也很有借鉴意义。而最重要的是,这不仅仅是一项理论研究,更是基于构建实际 LLM 应用的经验总结,具有很高的实践价值。















 988
988











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









