







在时间序列预测领域,模型的架构通常依赖于多层感知器(MLP)或Transformer架构。
总体而言,大概有三种时间序列的模型:
-
基于 MLP 的模型,如N-HiTS、TiDE和TSMixer,可以实现非常好的预测性能,同时保持快速训练。
-
基于Transformer的模型,如PatchTST和iTransformer也取得了良好的性能,但内存消耗更大,需要更多的时间来训练。
-
基于CNN的模型,CNN 已应用于计算机视觉,但其在预测方面的应用仍然很少,只有TimesNet和BiTCN是最新的例子。
本文提供一个三种模型的对比代码。
首先简短介绍下这些模型:
N-HiTS
(2023 AAAI)N-HiTS: Neural Hierarchical Interpolation for Time Series Forecasting
这是基于MLP的模型
随着预测长度(Horizon)的增加,NBEATS的速度变慢、参数量变多,而本文提出的N-HiTs则缓解了这两个问题。随着预测长度(Horizon)的增加,NBEATS的误差变大,这也很好理解,要预测很远的未来的话肯定更难预测,但本文提出的N-HiTs则缓解了这个问题。论文用分层次采样预测后插值的思想,用来缓解上述问题。
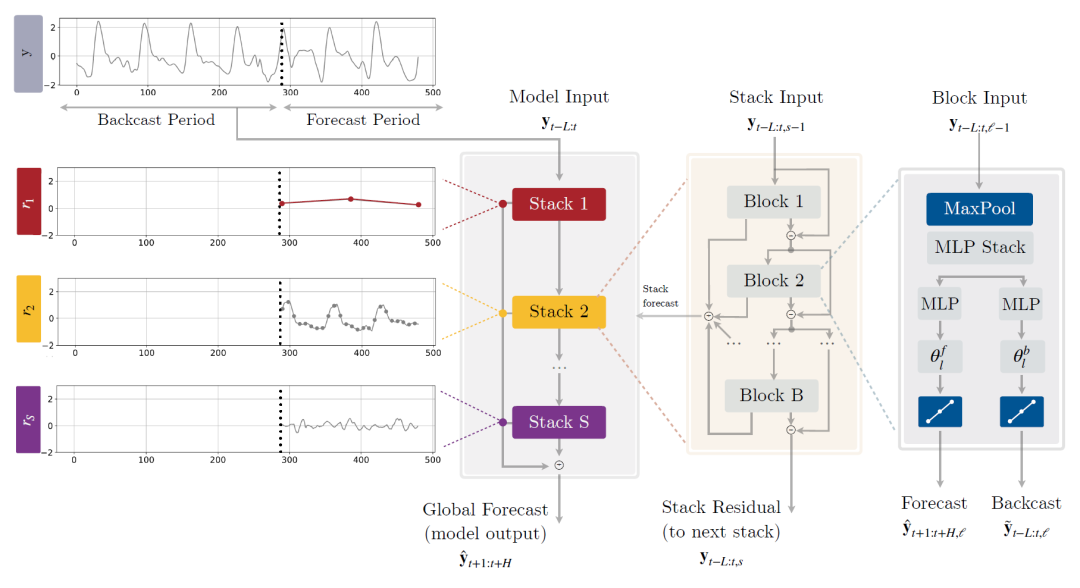
N-HiTS基于MLP的模型
PatchTST
(2023 ICLR) Time Series is Worth 64 Words: Long-term Forecasting with Transformers
这是基于Transformer的时间序列模型
本文的核心思想就是 Patching,这和 Preformer 中的核心思想很相似。分 patch 的结构如下图所示。对于一个单变量序列,将其划分 patch,每个 patch 的长度为 。
然后将每个 patch 视为一个 token,进行 embedding 以及加上位置编码,即可直接输入到普通的 Transformer 中。最后将向量展平之后输入到一个预测头(Linear Head),得到预测的单变量输出序列。
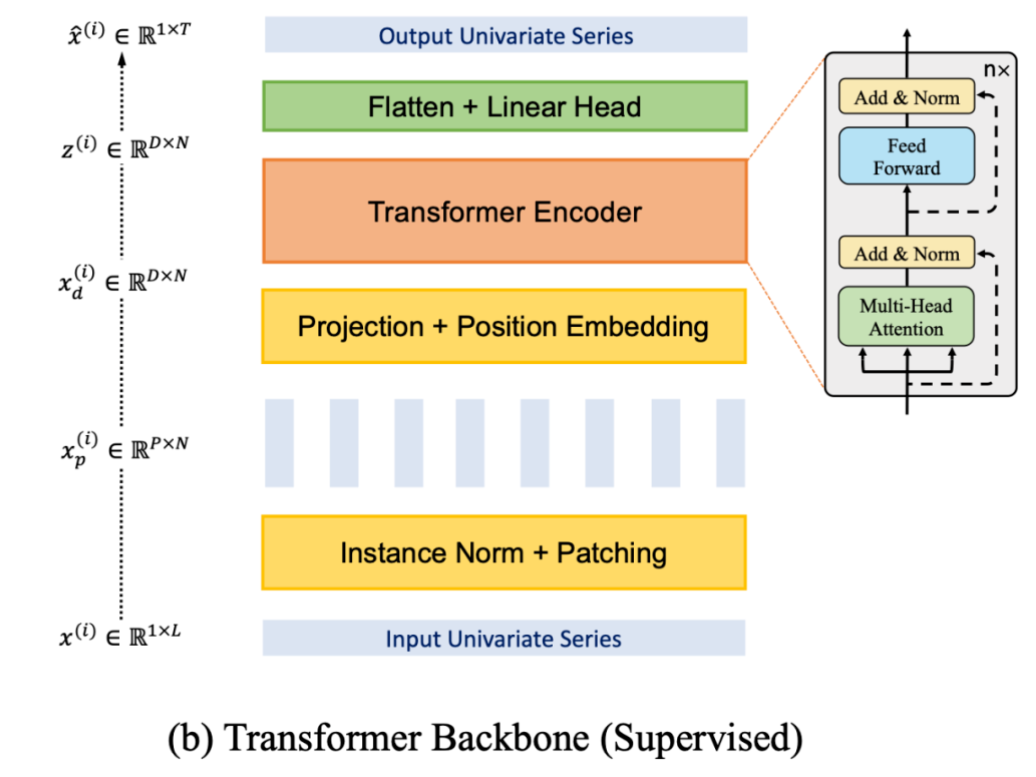
PatchTST基于Transformer
BiTCN
(2023 IJF)Parameter-efficient deep probabilistic forecasting
这是一种基于CNN的时间序列预测模型
BiTCN的架构由许多时间块组成,其中每个块由以下部分组成:
-
扩张卷积
-
GELU 激活函数
-
退出步骤
-
全连接层
时间块的一般架构如下所示。
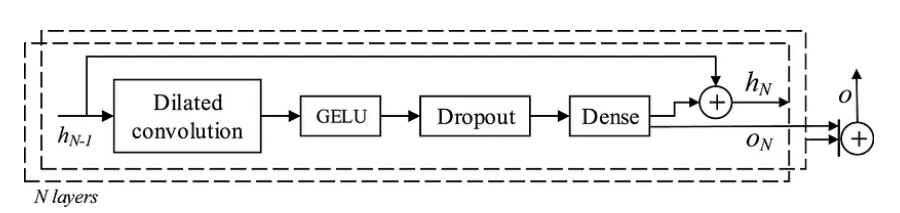
BiTCN总体架构
在上图中,我们可以看到每个时间块都会生成一个输出O。最终的预测是通过将堆叠在N层中的每个块的所有输出相加而获得的。
扩张卷积概念图如下,有助于扩大感受野。
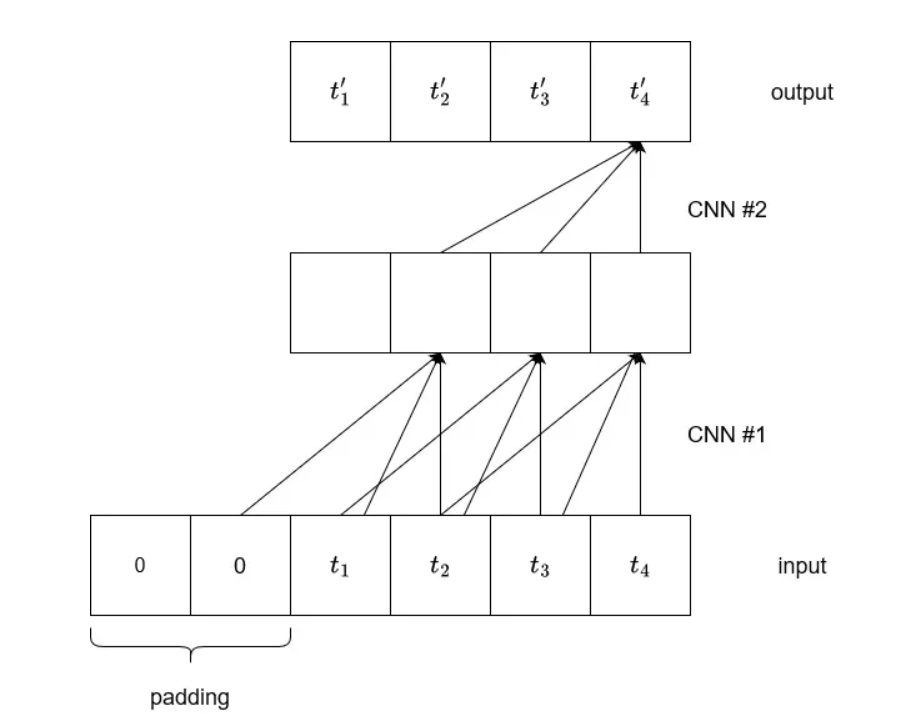
扩张卷积概念
然后,输出是来自滞后值和协变量的信息的组合,如下所示。
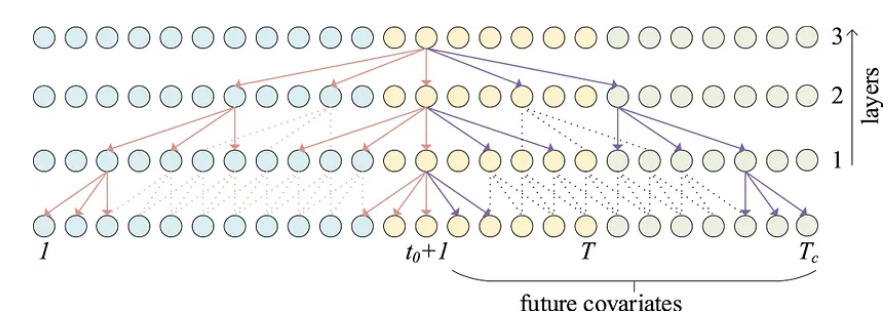
时间序列预测特征
蓝点代表输入序列,黄点代表输出序列,红点代表未来的协变量。我们可以看到带有扩张卷积的前瞻性时间块如何通过处理来自未来协变量的信息来帮助通知输出。
让我们来看看三种模型的表现:
代码
加载数据和预处理,一个无规律的时间序列数据
df = pd.read_csv('data/medium_views_published_holidays.csv')
df['ds'] = pd.to_datetime(df['ds'])
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
published_dates = df[df['published'] == 1]
holidays = df[df['is_holiday'] == 1]
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(df['ds'], df['y'])
ax.scatter(published_dates['ds'], published_dates['y'], marker='o', color='red', label='New article')
ax.scatter(holidays['ds'], holidays['y'], marker='x', color='green', label='US holiday')
ax.set_xlabel('Day')
ax.set_ylabel('Total views')
ax.legend(loc='best')
fig.autofmt_xdate()
plt.tight_layout()
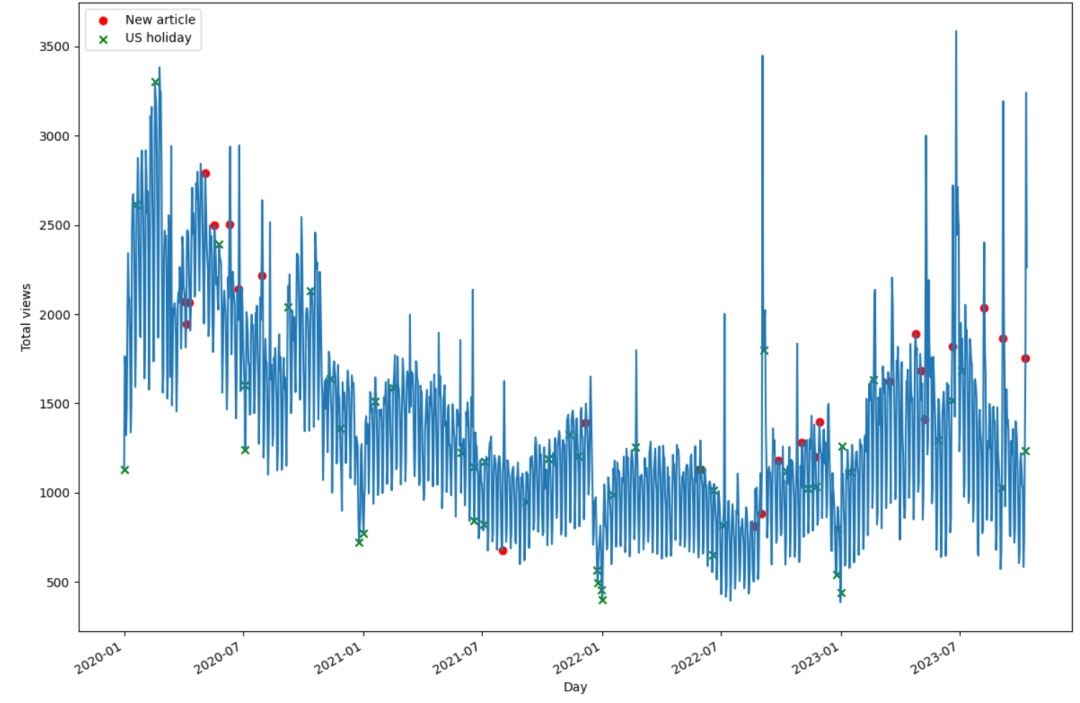
image-20240503231815396
加载模型:
horizon = len(test)
models = [
NHITS(
h=horizon,
input_size = 5*horizon,
futr_exog_list=['published', 'is_holiday'],
hist_exog_list=['published', 'is_holiday'],
scaler_type='robust'),
BiTCN(
h=horizon,
input_size=5*horizon,
futr_exog_list=['published', 'is_holiday'],
hist_exog_list=['published', 'is_holiday'],
scaler_type='robust'),
PatchTST(
h=horizon,
input_size=2*horizon,
encoder_layers=3,
hidden_size=128,
linear_hidden_size=128,
patch_len=4,
stride=1,
revin=True,
max_steps=1000
)
]
训练模型
nf = NeuralForecast(models=models, freq='D')
nf.fit(df=train)
查看模型的效果:
plt.plot(test_df['ds'], test_df['y'], label='ground truth')
plt.plot(test_df['ds'], test_df['NHITS'], label='NHITS')
plt.plot(test_df['ds'], test_df['BiTCN'], label='BiTCN')
plt.plot(test_df['ds'], test_df['PatchTST'], label='PatchTST')
plt.legend()
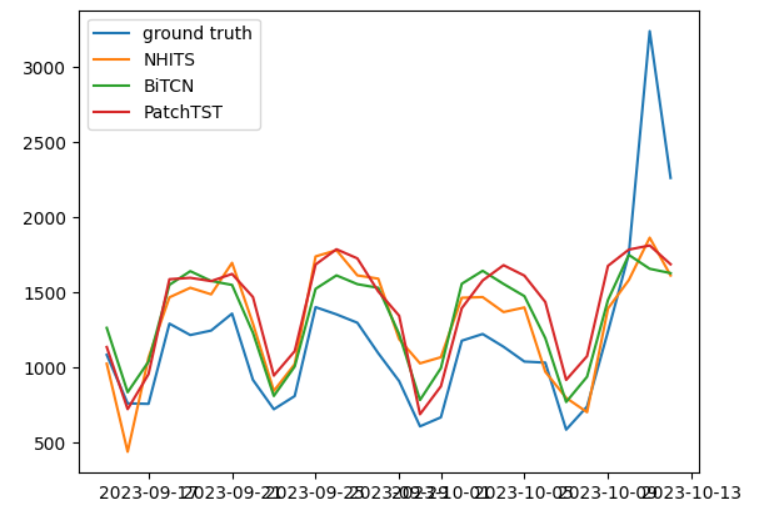
三种模型的测试结果
在上图中,我们可以看到所有模型似乎都在全局上高估了实际流量。实际上,Transformer模型并没有想象中的那么好,最好的似乎是CNN模型和MLP模型。。。
然后,我们测量平均绝对误差 (MAE) 和对称平均绝对百分比误差 (sMAPE),以找到性能最佳的模型。
from utilsforecast.losses import mae, smape
from utilsforecast.evaluation import evaluate
evaluation = evaluate(
test_df,
metrics=[mae, smape],
models=["NHITS", "BiTCN", "PatchTST"],
target_col="y",
)
evaluation = evaluation.drop(['unique_id'], axis=1)
evaluation = evaluation.set_index('metric')
evaluation.style.highlight_min(color='blue', axis=1)
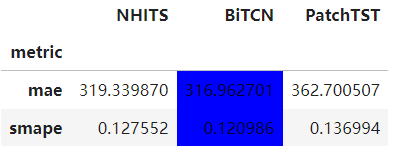
BiTCN竟然是SOTA!
最好的模型是BiTCN,一种基于CNN的模型,其次是NHITS,基于MLP的模型,最后是Transformer模型。
这其实也符合我们的认知,毕竟,Transformer在时间序列上,还不一定有想象的那么好!
延伸阅读~
1 用LSTM对降雨时间序列进行预测分析【代码分享,保姆级教程!】
2 从零搭建深度学习环境Tensorflow+PyTorch(附深度学习入门三大名著)
3 我把数据科学/深度学习资源做了个汇总...(PDF电子书+网课)
4 Transformer vs LSTM 股票时间序列预测(附代码)
5 一文详解Transformer注意力机制,华为盘古大模型Nature正刊方法!
戳我加群学习更多代码(私信小编添加微信群)
优质实惠的GPT4(师姐AI实习搞的,保障质量)















 5987
5987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









