









想要掌握如何将大模型的力量发挥到极致吗?叶梓老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具(限时免费)。
1小时实战课程,您将学习到如何轻松上手并有效利用 Llama Factory 来微调您的模型,以发挥其最大潜力。
CSDN教学平台录播地址:https://edu.csdn.net/course/detail/39987
想快速掌握自动编程技术吗?叶老师专业培训来啦!这里用Cline把自然语言变代码,再靠DeepSeek生成逻辑严谨、注释清晰的优质代码。4月12日,叶梓老师将在视频号上直播分享《用deepseek实现自动编程》。
视频号(直播分享):sphuYAMr0pGTk27 抖音号:44185842659
在人工智能领域,大模型 如今已成为研究热点。这些模型凭借其庞大的参数规模,在处理各种任务时展现出了惊人的能力。然而,随着模型规模的不断扩大,一个关键问题逐渐凸显:如何让这些大模型更高效地进行思考?最近的一项研究综述《A Survey of Efficient Reasoning for Large Reasoning Models: Language, Multimodality, and Beyond》为我们提供了深入的见解。
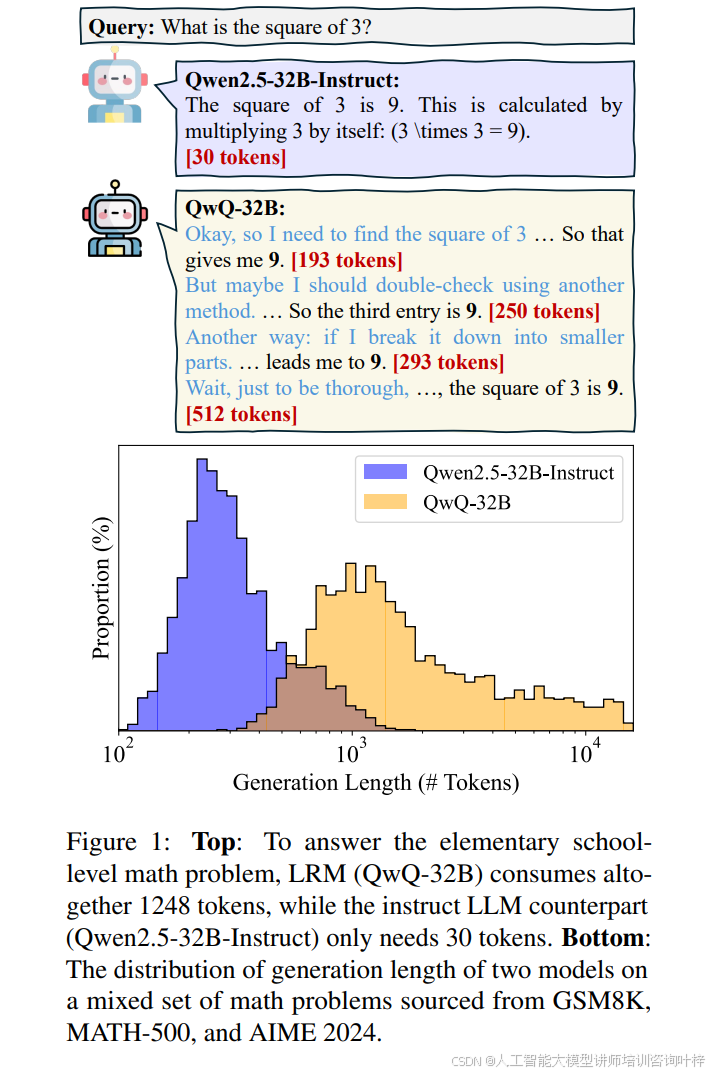
在推理阶段,大模型的冗长推理痕迹是一个显著问题。图1展示了大模型在解答小学数学题时的推理长度对比,其中QwQ-32B模型产生了1248个令牌的冗长推理过程,而Qwen2.5-32B-Instruct模型仅使用了30个令牌。这一对比直观地揭示了大模型在推理过程中存在的冗余问题,尤其是在处理简单问题时。这种冗余不仅增加了计算成本,还可能降低模型的性能。
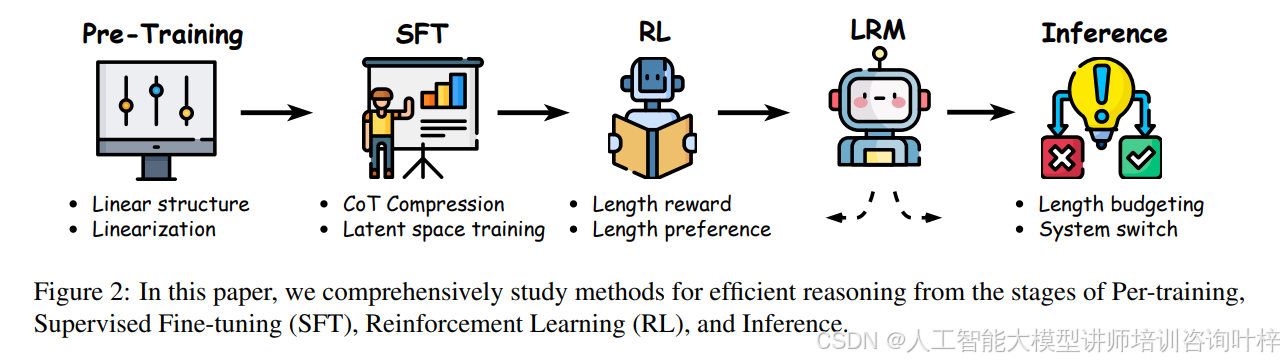
为了应对这一挑战,研究者们从大模型的生命周期角度出发,提出了多种策略。图2全面研究了从预训练(Pre-Training)、监督微调(SFT)、强化学习(RL)到推理(Inference)阶段的高效推理方法。图中清晰地展示了不同阶段可采取的策略,如预训练阶段的线性结构化方法、SFT阶段的推理链压缩技术、RL阶段的长度奖励机制,以及推理阶段的长度预算和系统切换策略。这些方法旨在通过优化模型的推理过程,减少冗余并提高效率。
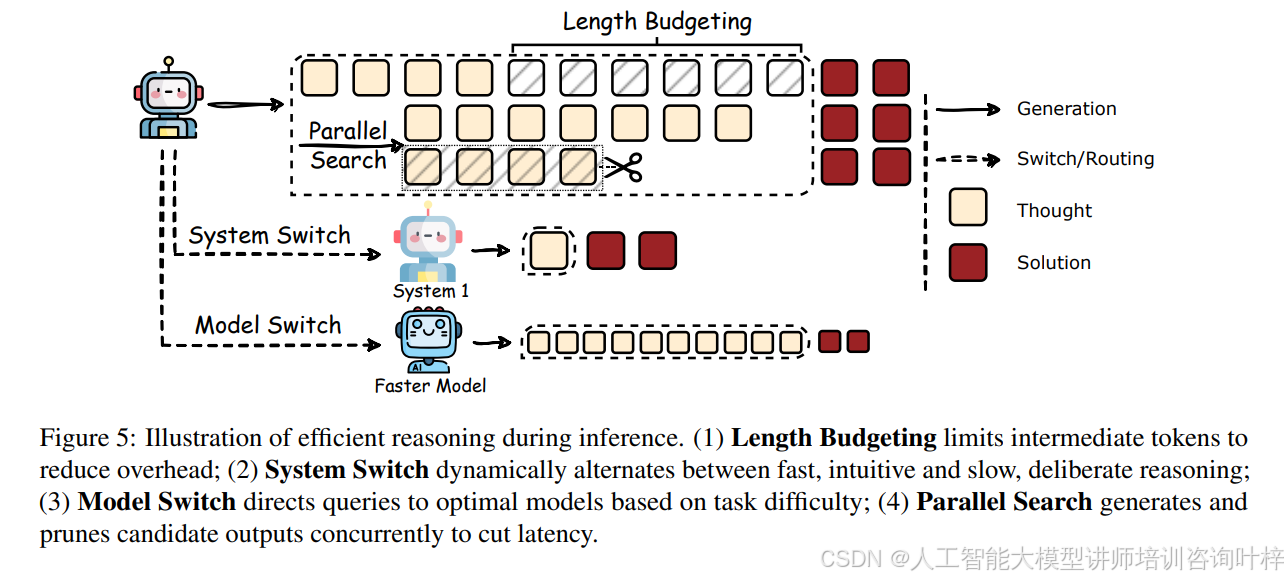
在推理阶段,图5以图解的形式说明了四种主要策略:长度预算限制中间令牌以减少开销、系统切换在快速直观和慢速深思熟虑推理之间动态交替、模型切换根据任务难度将查询导向最优模型,以及并行搜索通过同时生成和修剪候选输出来减少延迟。这些策略通过动态调整推理资源的分配,优化了推理过程,减少了不必要的计算。
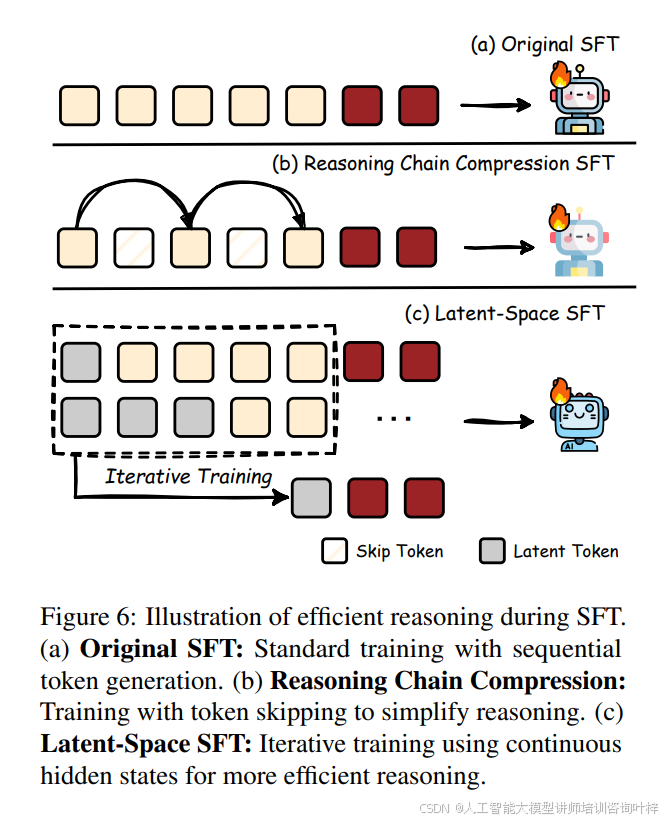
在监督微调阶段,图6展示了如何通过压缩推理链和在潜在空间中进行训练来实现高效推理。图中对比了原始SFT方法、推理链压缩方法和潜在空间SFT方法,清晰地展示了不同方法在推理效率上的差异。推理链压缩方法通过构建目标数据集,其中包含经过简化的推理路径,然后使用监督微调让模型学习这种简洁的推理模式。潜在空间SFT方法则通过在连续的隐藏状态中进行推理,逐步用隐式表示取代显式的推理步骤,从而减少推理过程中的令牌开销。
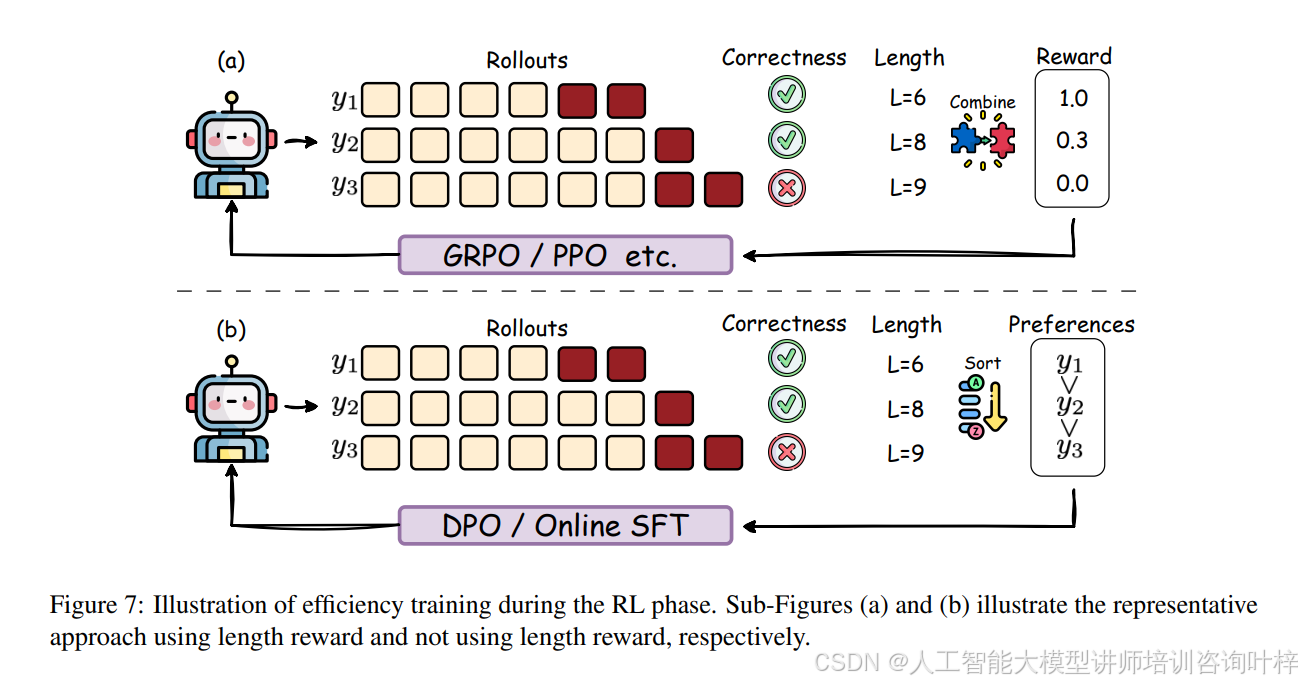
在强化学习阶段,图7通过两个子图分别展示了使用长度奖励和不使用长度奖励的两种方法。这些方法通过设计特定的奖励函数来平衡推理的准确性和长度,从而优化推理效率。例如,O1-Pruner通过估计模型的基线性能,并设计长度奖励来控制推理长度。这些方法通过引入长度奖励,直接优化了推理长度,提高了推理效率。

表2对比了多种使用长度奖励的RL方法,包括O1-Pruner、LCPO、L1、Kimi-1.5、DAST等。表中详细列出了每种方法的RL算法类型、是否使用长度奖励以及具体的奖励函数形式。
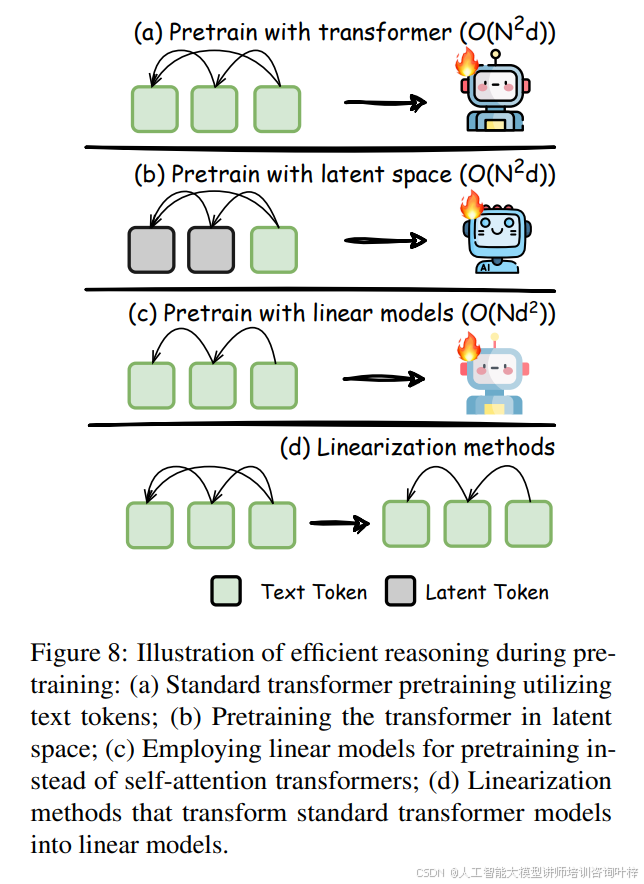
在预训练阶段,图8探讨了多种方法,包括在潜在空间中进行预训练、使用亚二次注意力机制的线性模型预训练,以及将Transformer模型线性化的线性化方法。这些方法旨在从模型架构的底层提升推理效率。例如,潜在空间预训练方法通过使用连续的潜在表示来代替传统的基于令牌的预训练,从而提高模型的理解深度和推理效率。亚二次注意力机制则通过替换标准的自注意力机制,减少处理序列时的计算成本。



















 125
125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











