







点击进入专栏:
《人工智能专栏》 Python与Python | 机器学习 | 深度学习 | 目标检测 | YOLOv5及其改进 | YOLOv8及其改进 | 关键知识点 | 各种工具教程
文章目录
- 网络结构
- 实验结果
- 源代码
- 修改方式
- `yolov5-neck-3-LSK.yaml`
- `yolov5-spp-LSK.yaml`

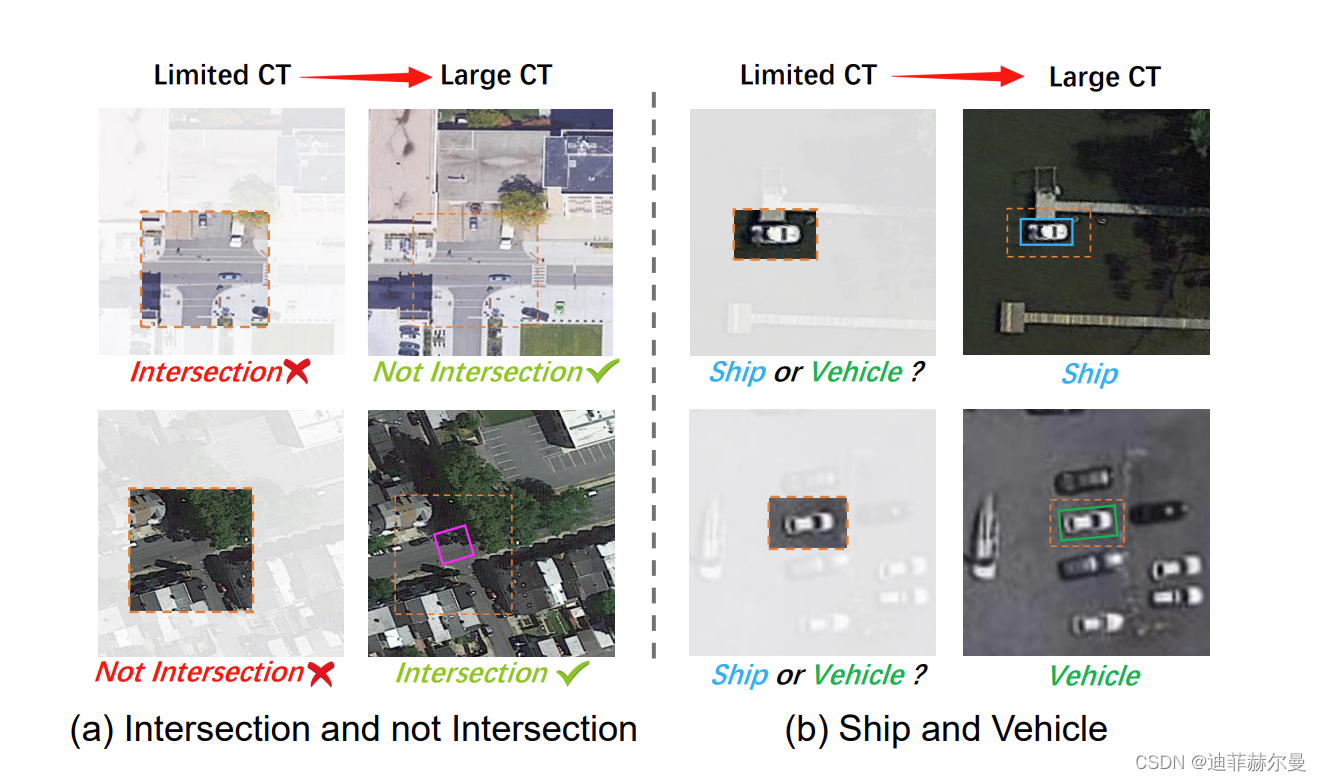
论文地址:https://arxiv.org/pdf/2303.09030.pdf
代码地址:https://github.com/zcablii/LSKNet
近期遥感目标检测的研究主要集中在改进有向边界框的表示,但忽视了遥感场景中存在的独特先验知识。这种先验知识是有用的,因为在没有足够长程上下文参考的情况下,微小的遥感目标可能被错误地检测出来,并且不同类型的目标所需的长程上下文可能会有所不同。在本文中,我们考虑了这些先验知识,并提出了"大型选择性核网络"(LSKNet)。LSKNet能够动态调整其大的空间感受野,更好地建模遥感场景中各种目标的范围上下文。据我们所知,这是首次在遥感目标检测领域探索大型和选择性核机制。LSKNet在标准基准测试上取得了新的最先进成绩,即HRSC2016(98.46% mAP),DOTA-v1.0(81.85% mAP)和FAIR1M-v1.0(47.87% mAP)。基于类似技术,我们在2022年大湾区国际算法大赛中获得第二名。
网络结构
基于Transformer的模型(例如Vision Transformer(ViT),Swin Transformer 和PVT)由于在图像识别任务中的有效性而受到计算机视觉领域的欢迎。研究表明,大的感受野是它们成功的关键因素。鉴于此,最近的研究表明,设计良好的具有大感受野的卷积网络也可以与基于Transformer的模型竞争力十足。例如,ConvNeXt 在其骨干网络中使用了7×7的深度卷积,从而在下游任务中取得了显著的性能改进。此外,RepLKNet甚至通过重新参数化使用了31×31的卷积核,取得了令人信服的性能。随后的研究SLaK 通过核分解和稀疏组技术将核大小进一步扩展到51×51。VAN引入了一种高效的大核分解卷积注意力。类似地,SegNeXt 和Conv2Former 表明大核卷积在调节卷积特征以获得更丰富上下文方面发挥着重要作用。
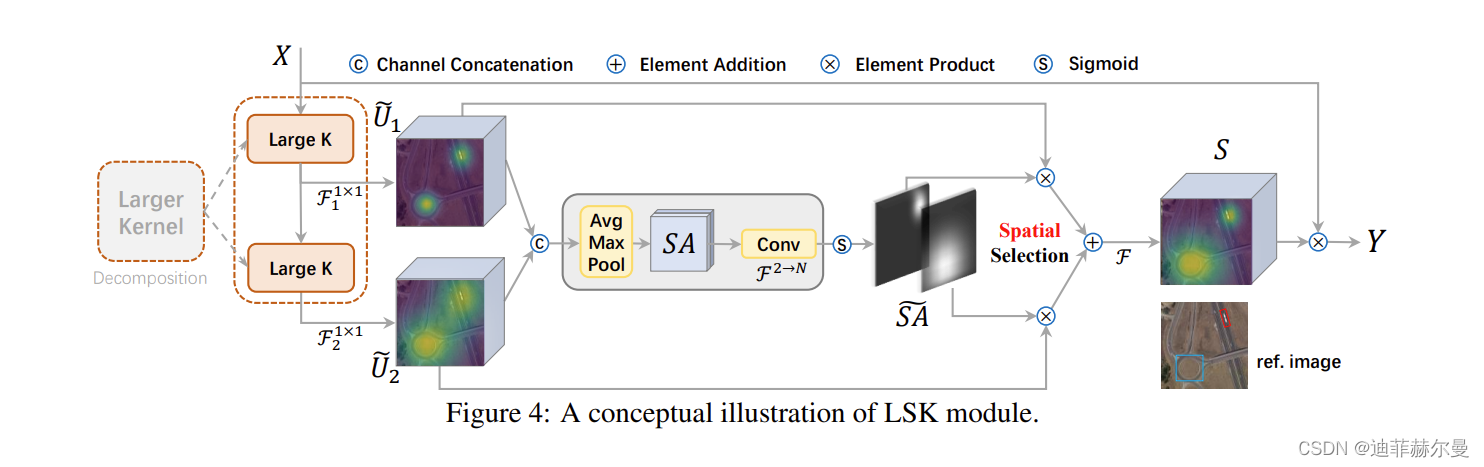
图展示了LSK模块的详细概念示意图,我们直观地演示了大型选择性核如何通过自适应地收集不同目标的相应大感受野。
实验结果
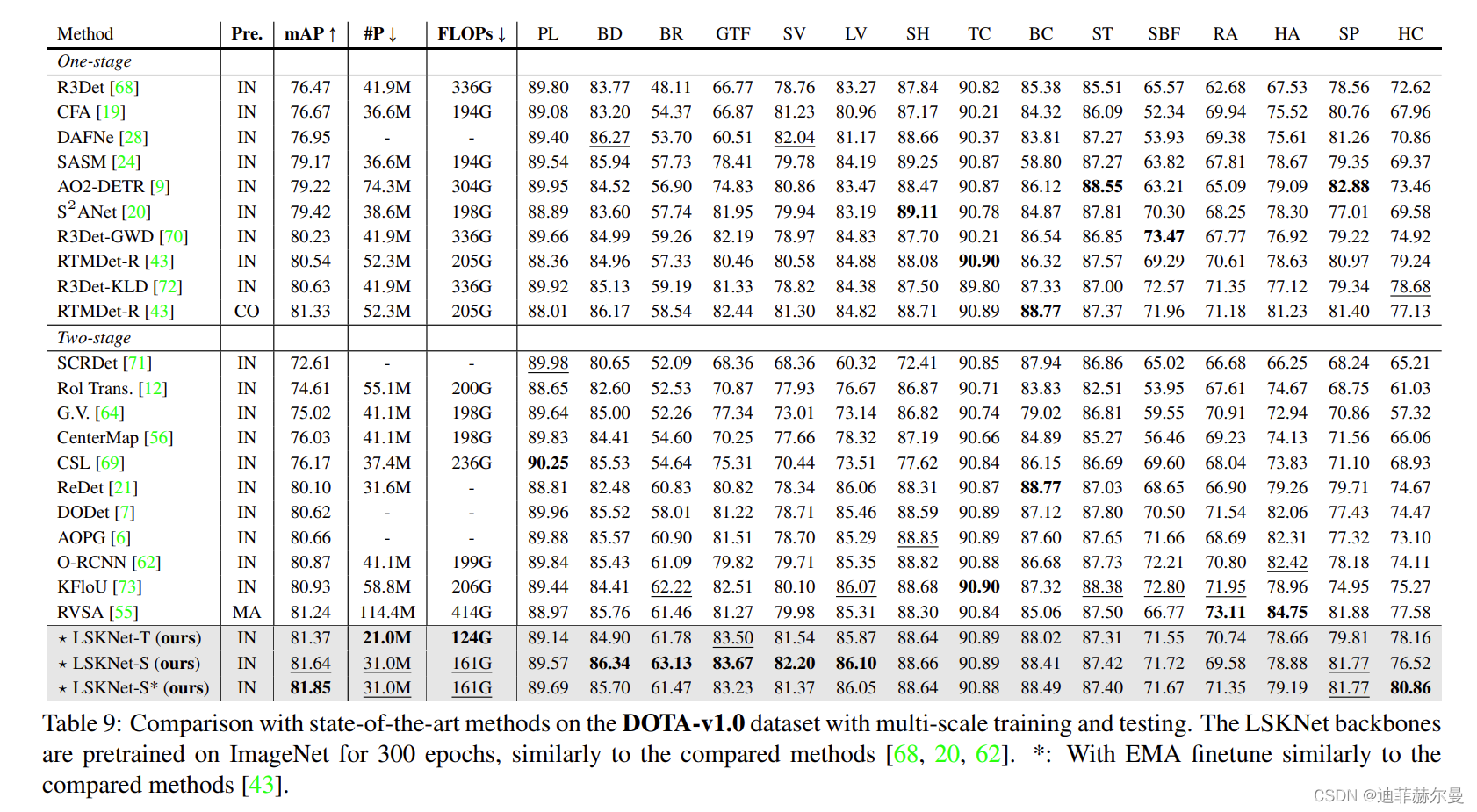
在DOTA-v1.0数据集上进行多尺度训练和测试的最先进方法比较。LSKNet的骨干网络在ImageNet上进行了300个时期的预训练,与其他比较方法相似。*:通过指数移动平均(EMA)微调,与其他比较方法相似。
源代码
from torch import nn
import torch
class LSKblock(nn.Module):
def __init__(self, dim):
super().__init__()
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
self.conv_spatial = nn.Conv2d(dim, dim, 7, stride=1, padding=9, groups=dim, dilation=3)
self.conv1 = nn.Conv2d(dim, dim//2, 1)
self.conv2 = nn.Conv2d(dim, dim//2, 1)
self.conv_squeeze = nn.Conv2d(2, 2, 7, padding=3)
self.conv = nn.Conv2d(dim//2, dim, 1)
def forward(self, x):
attn1 = self.conv0(x)
attn2 = self.conv_spatial(attn1)
attn1 = self.conv1(attn1)
attn2 = self.conv2(attn2)
attn = torch.cat([attn1, attn2], dim=1)
avg_attn = torch.mean(attn, dim=1, keepdim=True)
max_attn, _ = torch.max(attn, dim=1, keepdim=True)
agg = torch.cat([avg_attn, max_attn], dim=1)
sig = self.conv_squeeze(agg).sigmoid()
attn = attn1 * sig[:,0,:,:].unsqueeze(1) + attn2 * sig[:,1,:,:].unsqueeze(1)
attn = self.conv(attn)
return x * attn
修改方式
- 将上述源代码添加到
common.py - 在
yolo.py的nn.BatchNorm2d下面添加如下代码:
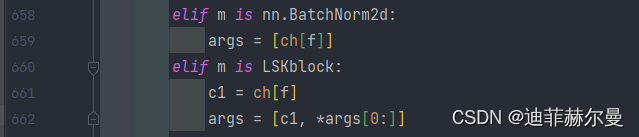
elif m is LSKblock:
c1 = ch[f]
args = [c1, *args[0:]]
- 修改
yaml文件
yolov5-neck-3-LSK.yaml
# by CSDN 迪菲赫尔曼
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024,5]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, LSKblock, []], # 18 ---> You can add your attention module name here
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 21 (P4/16-medium)
[-1, 1, LSKblock, []], # 22 ---> You can add your attention module name here
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # 24 cat head P5
[-1, 3, C3, [1024, False]], # 25 (P5/32-large)
[-1, 1, LSKblock, []], # 26 ---> You can add your attention module name here
[[18, 22, 26], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
yolov5-spp-LSK.yaml
# by CSDN 迪菲赫尔曼
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 1 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, LSKblock, []], # ---> You can add your attention module name here
[-1, 1, SPPF, [1024, 5]], # 10
]
# YOLOv5 v6.1 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 14
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 18 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 15], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 21 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 24 (P5/32-large)
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]















 5602
5602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









