







导读:本文可以看作是对分析transformer模型的参数量、计算量、中间激活、KV cache的详细说明
定性分析
GPU上都存了哪些东西
首先我们来从全局整体的角度看一看,在训练阶段GPU显存上都有哪些内容:
- Model States:模型训练过程中必须存储的states
- params(下面有时也叫做weights):模型参数,记参数量为 Φ \Phi Φ
- grads:模型梯度,梯度数量同参数量 Φ \Phi Φ
- optimizer states:Adam优化器中的momentum和variance,数量分别是 Φ \Phi Φ,共 2 Φ 2\Phi 2Φ
- Residual States:模型训练过程中,中间临时的、动态产生的states
- activation:中间激活值,这个部分可能在训练过程中占据很大一部分显存,下面会详细分析。但是激活值不是必须存储的,可以使用重计算(recompute,也叫做activation checkpoint),在反向算梯度的时候,再重新算一遍,当然计算增加了,时间换空间,实际使用中可以部分选择性的进行重计算。
- temporary buffers:临时存储,比如cuda、nccl等临时申请的显存。
- unusable fragment memory:内存碎片导致的内存浪费
推理阶段就相对简单一些,最主要的是Model States中的params和Residual States中的activation。
参考:图解大模型训练之:数据并行下篇( DeepSpeed ZeRO,零冗余优化)
混合精度训练
上面只是列出了训练过程中,显存中存放的内容和保存的数值数量,但是实际训练过程中,为了节省显存,以及考虑到训练过程中间某些过程对精度不是特别敏感,所以中间有些部分会使用fp32,有些部分会使用fp16/bf16。下面以Megatron为例,简单分析混合精度训练的一个大致流程。
首先我们来看一下不使用混合精度训练的场景,数值精度全使用fp32,作为一个分析的baseline。具体过程是:

占用显存为: 4 Φ 4\Phi 4Φ(fp32 weights)+ 4 Φ 4\Phi 4Φ(fp32 momentum)+ 4 Φ 4\Phi 4Φ(fp32 variance)+ 4 Φ 4\Phi 4Φ(fp32 grad)+fp32 activation(可能很大)= 16 Φ 16\Phi 16Φ Bytes + fp32 activation(4代表fp32的4Bytes,2代表fp16/bf16的2Bytes)
如果使用fp16的混合精度训练(bf16应该也可以,但是实际Megatron有点不同,下面会提到),具体过程是:

占用显存为: 4 Φ 4\Phi 4Φ(fp32 weights)+ 4 Φ 4\Phi 4Φ(fp32 momentum)+ 4 Φ 4\Phi 4Φ(fp32 variance)+ 2 Φ 2\Phi 2Φ(fp16 grad)+ 2 Φ 2\Phi 2Φ(fp16 scaled grad)+ 4 Φ 4\Phi 4Φ(fp32 unscaled and cliped grad)+fp16 activation(可能很大)= 20 Φ 20\Phi 20Φ Bytes + fp16 activation
需要说明的有两点:
- 当fp16 scaled grad转为为fp32 unscaled and cliped grad后,fp16 scaled grad就没用了,但是此时Megatron中仍然保留着一份fp16 scaled grad,所以显存占用中这两部分都会计算在内,这也符合Megatron offical readme中的描述:

-
注意到上面流程中多了一个scale/unscale的操作,这叫做“loss scaling”
在使用混合精度训练时,如果直接使用fp16的grad来更新fp16的梯度,一是会产生舍入误差(比如梯度很小,权重更新后,由于精度不够,累加上的lr * grad被舍入,权重没变,一句话来说就是大数吃小数),二是会产生梯度下溢(比如梯度过小,fp16范围不够,导致很小的梯度下溢成为0,而这样的小梯度占比很大,一句话来说就是下溢成0)。对于舍入误差,可以在更新权重时,将fp16的梯度转换为fp32,再更新fp32的权重,从而避免精度问题。对于梯度下溢,需要使用loss scale。
loss scale就是FWD计算出loss后,对loss放大若干倍,由于求导的链式法则,放大的若干倍同样会传导到fp16梯度,这样fp16梯度就不会产生梯度下溢。在更新权重时,将fp16的梯度转换为fp32,同时进行unscale。
刚才说到bf16有一点点特殊,我们看相应的代码:(Megatron中的arguments.py)
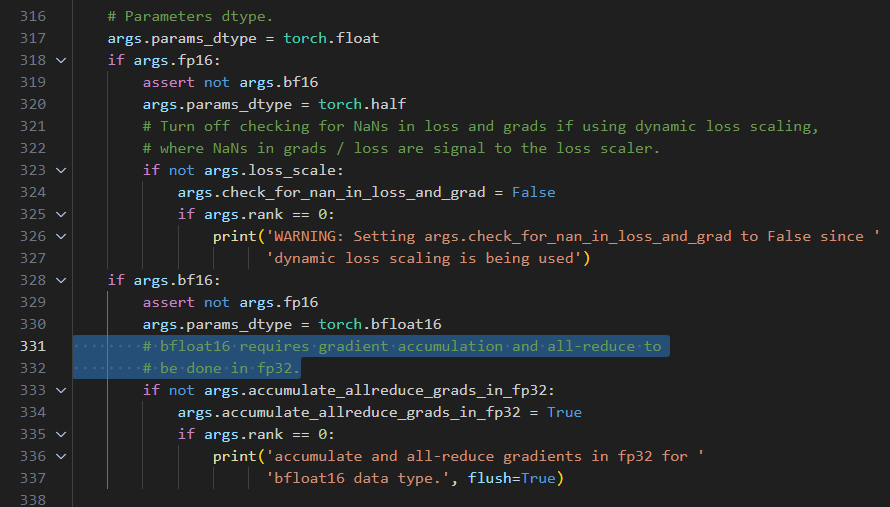
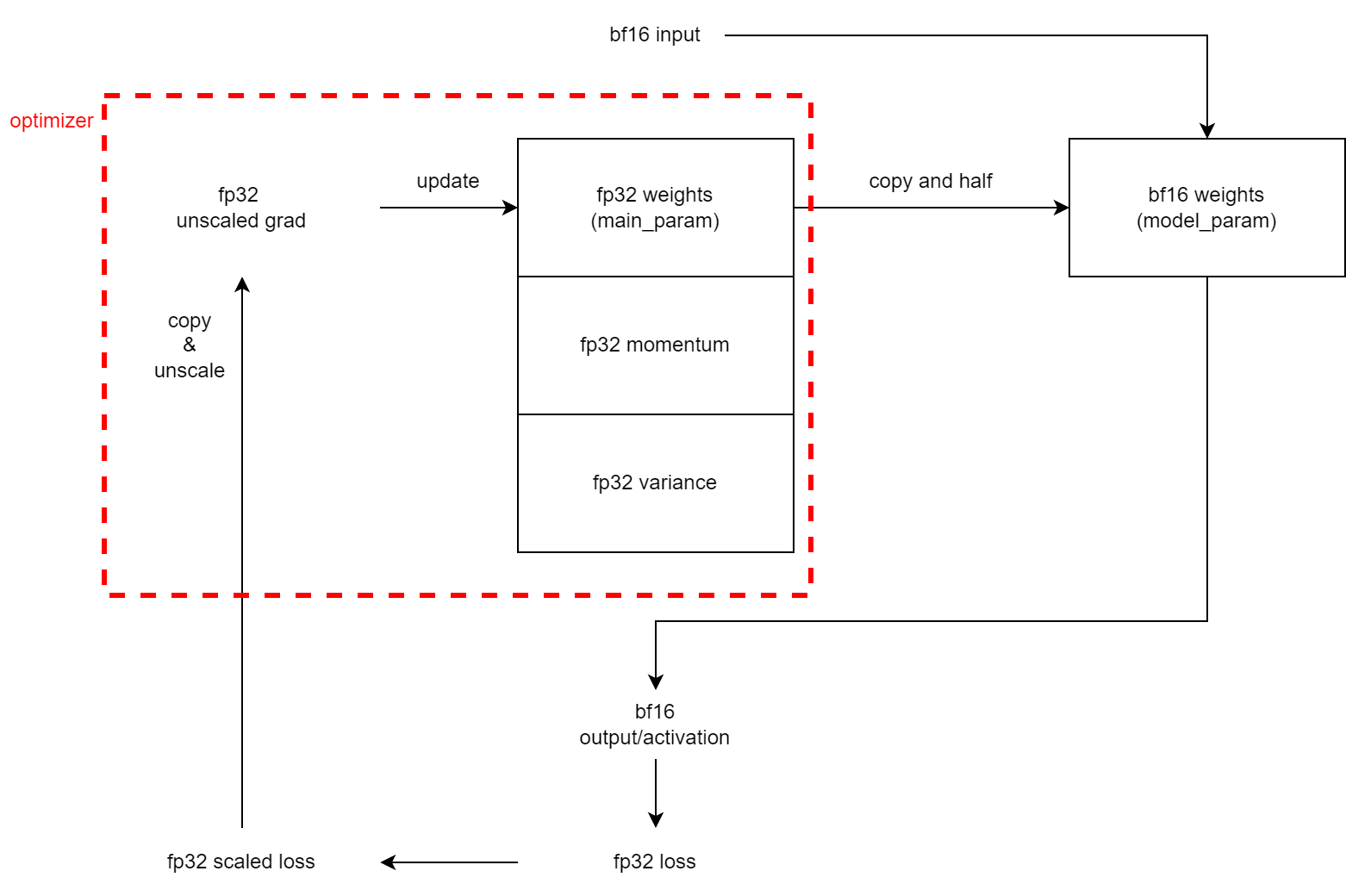
注意到如果使用bf16,那么会强行设置accumulate_allreduce_grads_in_fp32=True,这与上面Megatron offical readme截图(Distributed Optimizer)表格中的第二行【bf16 param, fp32 grads】相对应。具体过程应该是(not for sure, hope for discuss):
accumulate_allreduce_grads_in_fp32:If true, do the gradient accumulation and communication in fp32. from here
gradient accumulation:在若干次iteration中,每次都会反向得到一份梯度,将这若干次iteration得到的梯度进行累加、求平均,在最后一次iteration才更新权重。gradient accumulation与data parallel是等价的,gradient accumulation在时间维度上训练多个mini-batch,而data parallel在相同时间内将不同mini-batch放在不同的机器上训练,结果都是一样的。
参考:
这里找到一个为什么要将bf16与accumulate_allreduce_grads_in_fp32绑定的issue,里面提到“We found this to lead to more stable training before, but you could also try to perform the all-reduce in bf16 (it might hurt convergence but will be faster).”
参考:
- 图解大模型训练之:数据并行下篇( DeepSpeed ZeRO,零冗余优化)
- 图解大模型训练系列之:Megatron源码解读3,分布式混合精度训练
- NVIDIA Docs Hub:Train With Mixed Precision
- 全网最全-混合精度训练原理
量化分析
transformer结构详解
LLM中的transformer一般是decoder-only结构,所以下面的transformer block主要是decoder,但是与Vanilla Transformer中的decoder不同的是,这里没有了cross-attn,因此结构看起来反而有点像encoder(但不是,因为有casual mask)。
下面图中的Transformer,没有上kv-cache、GQA等优化,这部分后面会分析。其中,参数量 Φ \Phi Φ表示有多少个参数;中间激活值 A A A的单位是Bytes,主要参考的是分析transformer模型的参数量、计算量、中间激活、KV cache
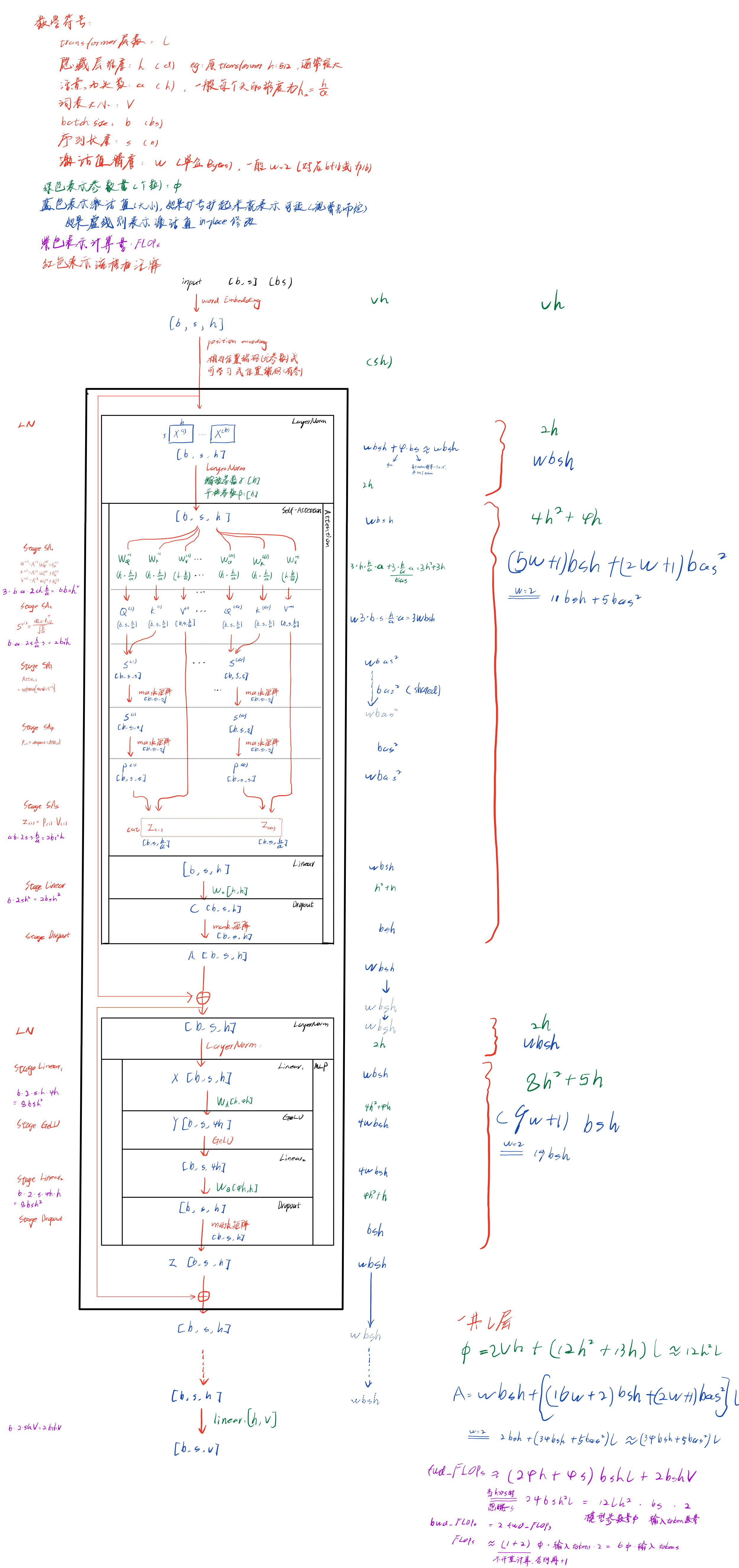
在Reducing Activation Recomputation in Large Transformer Models 4.1节中也对transformer激活值进行了一个分析,但是该论文中,self-attention block部分softmax之前没有加mask,上图中添加了mask,具体在Attention部分stage SA_3,其中mask由于是整个transformer共享的,所以就省略了, Q K T QK^T QKT的乘积被mask原地修改,所以 w b a s 2 wbas^2 wbas2也省略了,这样激活值与原论文中仍然是一样的。
KV cache对参数量、计算量、激活值的影响
关于KV Cache的来龙去脉,Encoder Decoder和decoder Only架构训练和推理浅析中简单捋了一下。简单来说,kv cache在推理过程中使用,而且模型只能是decoder-only架构。由于自回归的方式逐token生成,self-attention部分必须使用casual mask,因此Q矩阵部分只需要计算最新token的q向量即可,K、V矩阵部分只需要拼接新token的k、v向量即可:
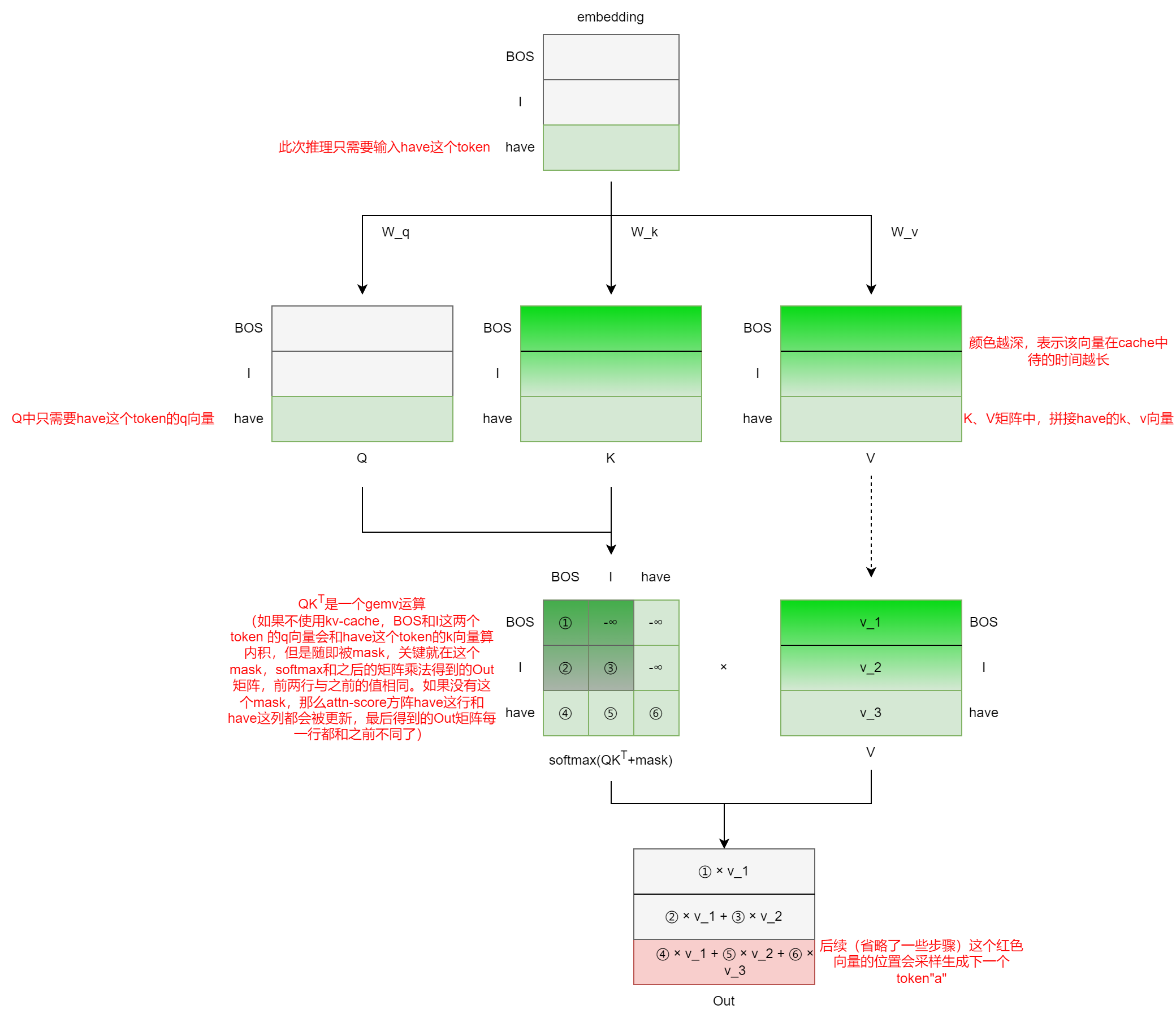
上面又重新回顾了一下kv cache。首先kv cache不会对参数量有影响,kv cache主要是用来减少不必要的计算的,显存因此也可能有相应的减少,上面只是一个示意图,中间省略了一些部分,详细的量化分析见下图,需要说明的有两点:
- kv cache使用场景是推理场景,LLM推理分为prefill阶段和decode阶段,prefill阶段创建kv-cache,decode阶段更新kv-cache。在输入prompt的这个prefill阶段中,with kv-cache和without kv-cache的计算量是相同的(显存占用由于分配kv-cache,可能with kv-cache会更多一点)。计算量的减少主要体现在decode阶段,因此下面的分析主要是针对单次decode阶段的,因此固定 s = = 1 s==1 s==1
- 下图中说的“相对于原来“指的是without kv-cache时,每次都输入之前所有的token,计算完整的attention-score方阵,因而此时的序列长度 s = s n ≤ s m s=s_n \le s_m s=sn≤sm。在最终分析时,取最大值 s = s m s=s_m s=sm进行比较,对应decode阶段的最后一个token的生成过程,有的博客可能会将输入序列长度(prompt长度)和输出序列长度分开,这里合起来了,注意区别。

| 原来(without kv-cache) | 现在(with kv-cache) | 变化 | |
|---|---|---|---|
| 参数量 | 2 V h + ( 12 h 2 + 13 h ) l 2Vh+(12h^2+13h)l 2Vh+(12h2+13h)l | 2 V h + ( 12 h 2 + 13 h ) l 2Vh+(12h^2+13h)l 2Vh+(12h2+13h)l | 不变 |
| 中间激活 | 2 b s h + ( 34 b s m h + 5 b a s m 2 ) l 2bsh+(34bs_mh+5bas_m^2)l 2bsh+(34bsmh+5basm2)l | 2 b s h + ( 30 b h + 4 b s m h + 5 b a s m ) l 2bsh+(30bh+4bs_mh+5bas_m)l 2bsh+(30bh+4bsmh+5basm)l | 减少了 ( 30 b h ( s m − 1 ) + 5 b a s m ( s m − 1 ) ) l (30bh(s_m-1)+5bas_m(s_m-1))l (30bh(sm−1)+5basm(sm−1))l,原来中间激活是最长序列长度 s m s_m sm的二次方,现在随着 s m s_m sm线性增长 |
| 计算量 | ( 24 h + 4 s m ) b s m h l + 2 b s m h V (24h+4s_m)bs_mhl+2bs_mhV (24h+4sm)bsmhl+2bsmhV | ( 24 h + 4 s m ) b h l + 2 b h V (24h+4s_m)bhl+2bhV (24h+4sm)bhl+2bhV | 减少了 ( 24 h + 4 s m ) b h l ( s m − 1 ) + 2 b h V ( s m − 1 ) (24h+4s_m)bhl(s_m-1)+2bhV(s_m-1) (24h+4sm)bhl(sm−1)+2bhV(sm−1),原来计算量是最长序列长度 s m s_m sm的二次方,现在随着 s m s_m sm线性增长 |
code: from 【手撕LLM-KVCache】显存刺客的前世今生–文末含代码
# author: xiaodongguaAIGC
# KV-Cache + Generation + decoder
import torch
import torch.nn.functional as F
from transformers import LlamaModel, LlamaConfig, LlamaForCausalLM
D = 128 # single-head-dim
V = 64 # vocab_size
class xiaodonggua_kv_cache(torch.nn.Module):
def __init__(self, D, V):
super().__init__()
self.D = D
self.V = V
self.Embedding = torch.nn.Embedding(V,D)
self.Wq = torch.nn.Linear(D,D)
self.Wk = torch.nn.Linear(D,D)
self.Wv = torch.nn.Linear(D,D)
self.lm_head = torch.nn.Linear(D,V) # LM_head
self.cache_K = self.cache_V = None # initial
def forward(self,X):
X = self.Embedding(X)
Q,K,V = self.Wq(X),self.Wk(X),self.Wv(X)
print("input_Q:", Q.shape)
print("input_K:", K.shape)
print("input_V:", V.shape)
# Easy KV_Cache
if self.cache_K == None: # first time
self.cache_K = K
self.cache_V = V
else:
self.cache_K = torch.cat((self.cache_K, K), dim = 1)
self.cache_V = torch.cat((self.cache_V, V), dim = 1)
K = self.cache_K
V = self.cache_V
print("cache_K:", self.cache_K.shape)
print("cache_V:", self.cache_K.shape)
# ignore proj/MLP/scaled/mask/multi-head when calculate Attention
attn =Q@K.transpose(1,2)@V
# output
output=self.lm_head(attn)
return output
model = xiaodonggua_kv_cache(D,V)
# 创建数据、不使用tokenizer
X = torch.randint(0, 64, (1,10))
print(X.shape)
for i in range(4):
print(f"\nGeneration {
i} step input_shape: {
X.shape}:")
output =  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 261
261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









