






今天,我们将探讨如何手工计算Transformer模型的参数量。
计算参数的前提是需要对模型架构有一个清晰透彻的理解。本文力求通俗,希望帮助大家更好地理解Transformer的内部结构以及参数计算的逻辑。
好,接下来我们一起热身大喊:模型这么大,我想去算算 ~~ 出发!

一、自注意力机制回顾
今天我们讨论的主角是由Google Brain团队在2017年发布的Transformer模型。它的横空出世震撼了整个自然语言处理领域,彻底颠覆了传统的网络架构,并奠定了当今大模型的基石。
自注意力机制是Transformer模型的核心,也是其成功的关键。其核心思想是计算每个词与其他词之间的相关性,并根据相关性的大小分配注意力权重,从而更加关注对于当前词来说相对重要的信息。
通俗来说,就像阅读一篇文章时,我们会试图理解每个词在句子中的作用和意义,同时也会关注它与文章中其他词的关系。
在自注意力机制中,我们站在每个词的视角上,评估该词对于理解整个句子或文章的重要性,并探索它与其他词之间的相互作用。
在这个过程中,我们计算每个词与其他词之间的关系紧密程度。根据关系的亲密度,模型会为这些关系分配不同的权重。权重越高,意味着两个词之间的关联性越强。模型会将注意力集中在与当前词联系最紧密的信息上,从而更精准地捕捉文章的核心意义和语境。
我们以句子“警察在雨中追捕逃跑的罪犯”为例,来讲解上述的自注意力机制。
在自注意力机制中,每个词都会与句子中的其他词进行关系评估。具体步骤如下:
- 计算关系紧密程度:模型会计算“警察”与“在”、“雨中”、“追捕”、“逃跑”、“罪犯”等词之间的关系紧密程度。例如,“警察”与“追捕”的关系紧密程度可能会比“警察”与“雨中”更高。
- 分配权重:根据计算出的关系紧密程度,模型会为每对词分配权重。权重越高,表示这对词的关系越紧密。例如,“警察”与“追捕”的权重更高,因为二者之间的关联性更强。
- 集中注意力:模型会根据分配的权重,将注意力集中在最相关的信息上。例如,当处理“警察”这个词时,模型可能会更多地关注“追捕”和“罪犯”,这有助于理解句子的核心意义和语境。
通过这种机制,模型能够捕捉到句子中词与词之间的重要关系,从而更好地理解句子的整体含义。在这个例子中,自注意力机制帮助模型识别出“警察”、“追捕”、“罪犯”是句子的关键要素,并通过这些要素来理解句子的核心意义。
下图以“追捕”为例画了一个示意图,每个点代表一个词,其中红色的点表示与“追捕”高度相关的词(“警察"和"罪犯”),蓝色的点表示其他的词。
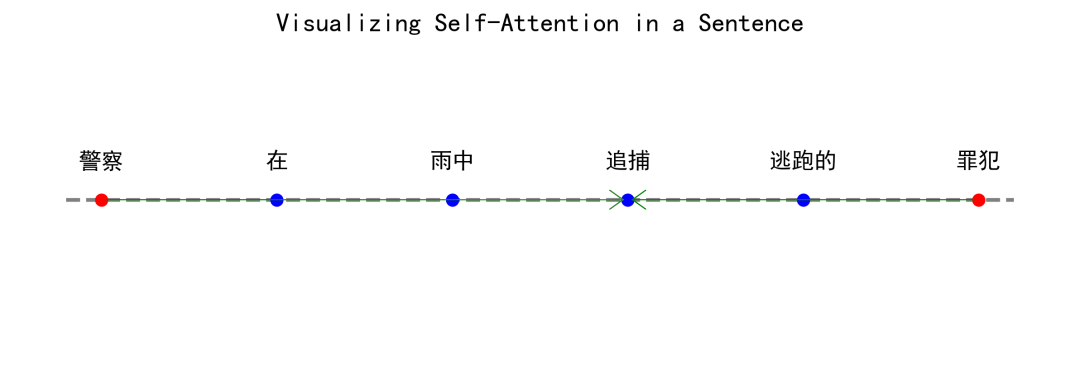
在上面,我们以“追捕”为例。不过大家要记住,自注意力机制其实是对句子中所有的词,都重复进行这个分析过程。
即,对于每个词,自注意力机制都会:
- 生成一个查询向量(Query),代表该词在句子中的重要性。
- 计算该词的查询向量与所有其他词的键向量(Key)的点积,得到相关性得分。
- 使用softmax函数对相关性得分进行归一化处理,得到其他词对于当前词的注意力权重。
- 基于注意力权重,聚焦于与该词密切相关的其他词。
- 综合相关词语的信息,深入理解该词的语义和句子的整体含义。
我们总结一下自注意力机制的本质:模型从全局视角理解每个词的重要性和相互关联程度,从而获得对句子更深刻和精确的语言理解。
这种方法不仅捕捉到了字面意义,还揭示了词语之间的隐含关系。
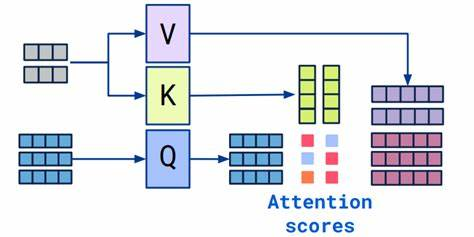
自注意力机制的核心流程示意如下所示,其中包括查询(Query)、键(Key)和值(Value)三个向量的生成和使用。具体解释如下:
- 输入嵌入:左侧灰色的方块代表输入的嵌入词向量。每个词通过嵌入层转换为一个向量表示。
- 生成Q、K、V向量:输入嵌入分别通过三个不同的线性变换层,生成查询向量(Q),键向量(K)和值向量(V)。图中的紫色方块表示值向量(V),黄色方块表示键向量(K),蓝色方块表示查询向量(Q)。
- 计算注意力得分:查询向量(Q)与键向量(K)进行点积操作,得到注意力得分(Attention scores)。这些得分表示输入中每个词对其他词的相关性。
- 归一化注意力得分:使用softmax函数对注意力得分进行归一化处理,得到注意力权重。这些权重用于衡量每个词在当前上下文中的重要性。
- 计算注意力输出:将注意力权重与对应的值向量(V)相乘,并对所有词的结果进行求和,得到最终的注意力输出。这一步聚焦于与当前词语相关的重要信息,从而更好地理解每个词的语义和整个句子的含义。
图中的流程展示了如何通过自注意力机制来计算每个词与其他词之间的关系,并基于这些关系来进行信息聚合和语义理解。
二、Transformer模型架构
了解了自注意力机制,现在我们从输入数据流的角度,整体回顾一下Transformer的模型架构。
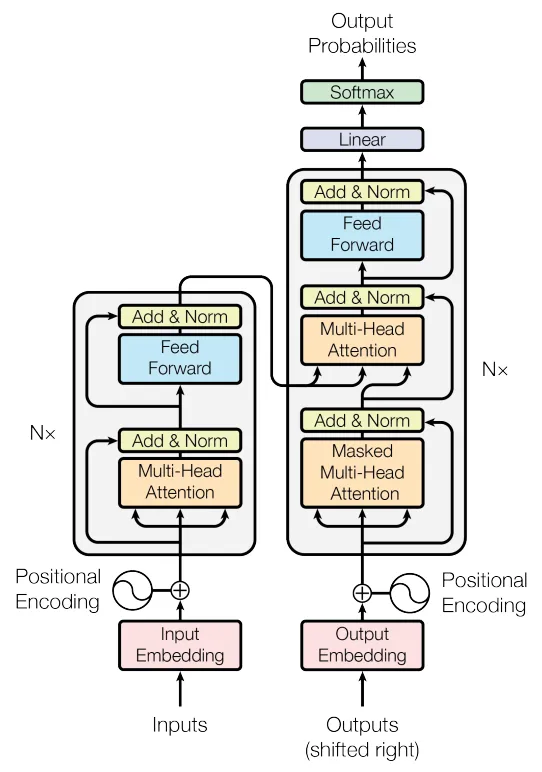
1. 输入处理:为模型理解文本做好准备
在自然语言处理中,我们需要首先将输入文本拆解为一个个基本的单元,称为词元(Token)。这些 token 可以是单个单词、字符或其他有意义的单位。这个过程被称为分词(Tokenization)。
Tokenization 能够将文本结构分解为更小的组成部分,使模型能够更容易地理解文本的结构和组成。例如,通过将句子分割成单词,模型可以识别句子中的主语、谓语、宾语等成分,从而更好地理解句子的含义。
分词之后,下一步进行词嵌入环节。
1) 词嵌入(Word Embedding):将词语转化为向量
在自然语言处理中,词语的含义往往无法用简单的符号来表示。因此,我们需要将词语转换为向量表示,每个向量代表词语的语义信息。这个过程称为词嵌入(Word Embedding)。
你可能会好奇,这个向量到底有多长呢?
词嵌入长度没有固定值,它取决于具体应用场景和数据集的大小。一般来说,词嵌入长度在几十到几百之间。
数据集越大,包含的词语越多,就需要更长的词嵌入向量来捕捉词语之间的细微差别。
不同的任务,也会有所不同。例如,机器翻译需要捕捉词语之间的细微语义差异,因此词嵌入长度会设置得更高;而文本分类任务可能只需要区分词语的基本类别,因此词嵌入长度可以设置得较低。
Transformer论文中,使用的词嵌入长度为512或者1024。
一些大型语言模型(例如GPT-3)使用词嵌入长度为1024或更高。
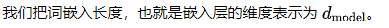
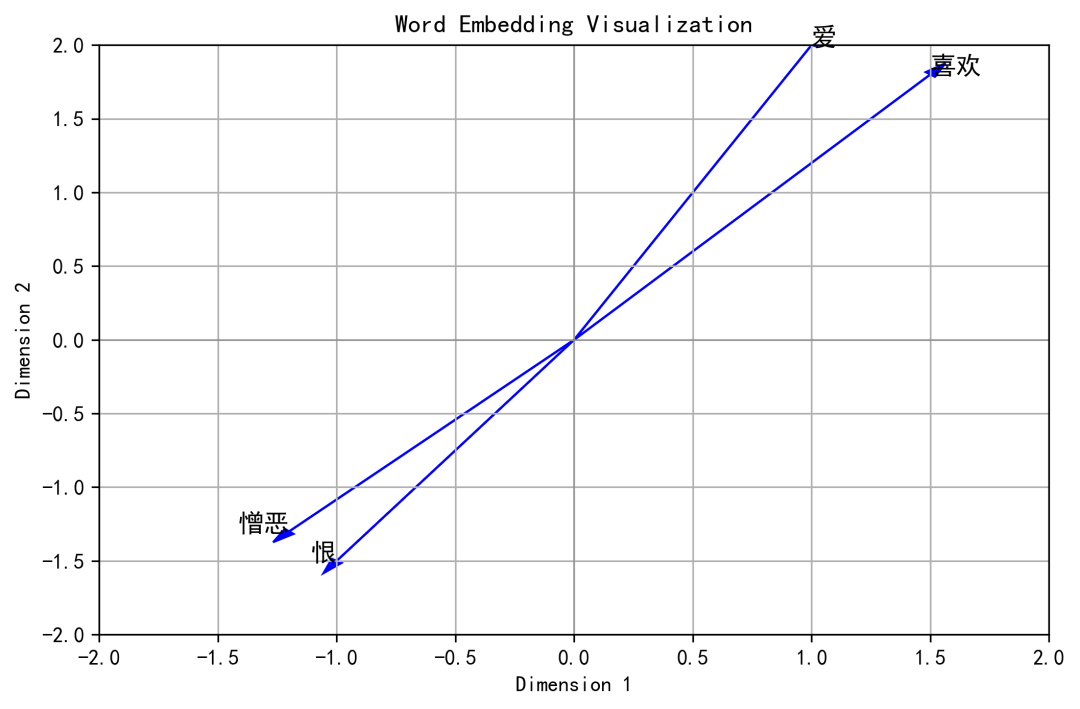
下面的图展示了词嵌入(Word Embedding)的表示。在图中,每个向量表示从原点到该点的箭头,象征不同词语(如“爱”、“喜欢”、“恨”、“憎恶”)在语义空间中的位置。不同的词的向量在多维空间中的方向和距离可以反映出词语之间的语义相似性和关系。
在这个简化的示意图中,每个词语被转换为一个二维的向量,以便于效果展示。可能有同学问能否用1024维去展示,这个么,臣妾真的做不到啊。
2) 位置编码(Positional Encoding):体现词语的顺序
我们知道,单词在句子中的位置非常重要,因此我们需要在模型中保持句子中每个单词的位置信息。Transformer模型没有显式地编码词语的顺序信息,因此需要加入位置编码来体现词语在句子中的相对位置。
常见的位置编码方法包括:
- 正弦编码(Sinusoidal Encoding): 使用正弦和余弦函数来编码词语的位置信息。这种方法简单易于实现,但缺乏灵活性。
- 学习嵌入(Learned Embeddings): 使用额外的参数来学习词语的位置信息。这种方法能够更加灵活地捕捉词语的顺序信息,但需要更多的训练数据。
通过词嵌入和位置编码,模型能够将输入文本转换为向量表示,这时原来的句子变成了计算机模型可以识别和处理的数值表示。这些向量表示保留了单词的语义信息和位置信息,兴奋而忐忑地等待下面最为核心的处理环节 —— 编码器。
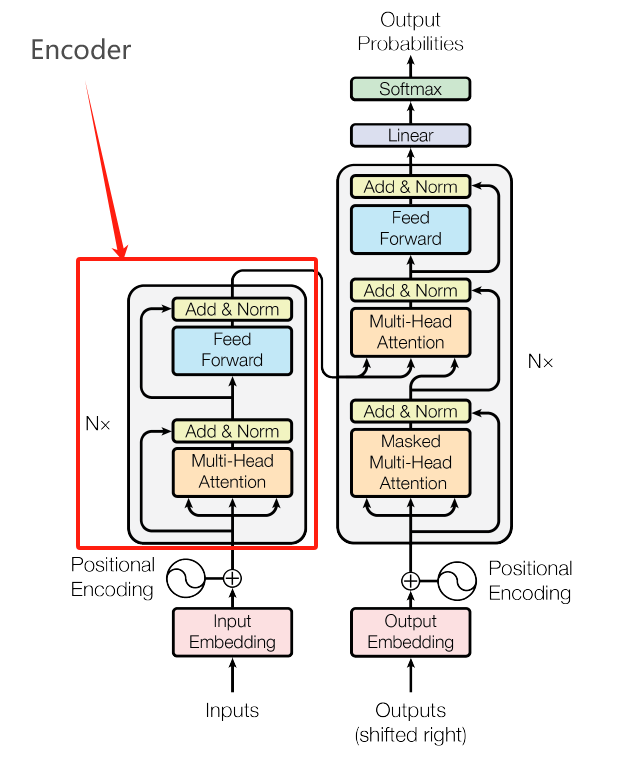
2. 编码器(Encoder)
编码器负责将输入文本转换为语义表示。它由多个相同的编码器层堆叠而成,也就是说,输入文本需要经过多个编码器层的处理,就像不断过关一样。每一层都会对输入进行进一步的处理和理解,逐步提取出更高层次的语义信息。这种多层堆叠的方式使得模型能够捕捉到复杂的语言结构和深层的语义关系,从而更好地理解输入文本。
那么,一般需要经过多少层,才能破茧成蝶,立地成佛呢?
在实际应用中,Transformer模型通常使用6到12层编码器层。这个层数可以根据具体任务和需求进行调整。
在经典的Transformer模型(如BERT和GPT)中,通常使用12层编码器。这个设置在很多任务上表现良好,是较为常见的配置。
对于更复杂的任务或者需要更高精度的应用,可以增加编码器的层数。例如,BERT的大型版本(BERT Large)使用了24层编码器。
对于一些简单的任务,或者为了提升计算效率,可以使用较少的编码器层数。例如,6层或8层的编码器在某些情况下也能达到令人满意的效果。
通过多层编码器的处理,模型逐步提取和聚合文本中的语义信息,最终能够生成丰富且精确的语义表示,宛若历经蜕变,破茧成蝶,最终彻底领悟输入文本的深刻含义。
每个编码器层包含以下两个子层:
- 多头自注意力机制(Multi-Head Self-Attention): 计算每个词与其他词的相关性,捕捉全局语义信息。
- 前馈网络(Feed Forward Network): 对每个词进行非线性变换,增强模型的表达能力。表达能力是指模型理解和生成复杂语言结构和语义关系的能力。通过引入非线性变换,前馈网络可以捕捉到输入文本中的复杂模式和特征,从而提高模型在各种语言任务中的表现。
每个编码器层的输出都会经过残差连接和层归一化操作。残差连接有助于避免梯度消失问题,层归一化则可以提升训练稳定性。
下面我们重点介绍多头自注意力子层。
1) 多头自注意力机制
多头自注意力(Multi-Head Self-Attention)的主要思想是利用多个注意力头,每个注意力头独立地进行自注意力计算,然后将这些注意力头的输出拼接起来,再通过线性变换映射回模型的输出维度。
通俗地说,多头自注意力机制可以比喻成一个团队在开会,每个人(注意力头)都专注于不同的任务,然后把各自的观点综合起来,形成一个完整的决策。
每个团队成员(注意力头)对自己所关注的方面进行独立的分析和思考,各自对信息进行处理。即每个注意力头独立地计算查询、键和值(Q, K, V)之间的关系,从而得出自己的注意力分布。
会议结束时,所有成员将自己的分析结果汇总在一起,形成一个完整的报告。这就类似于将多个注意力头的输出拼接在一起。
假设我们有一个句子:“猫在草地上玩耍”。模型中的多个注意力头会分别关注不同的词语组合和关系,比如:
- 一个头可能会专注于“猫”和“玩耍”之间的关系,理解谁在做什么。
- 另一个头可能会关注“草地上”和“玩耍”的关系,理解发生在什么地方。
通过这种方式,多头自注意力机制增强了模型处理复杂语言任务的能力,使得模型可以从多个角度和层次上理解输入文本。
2) 多头工作原理
对于多头原理这一段,略微有些复杂,我们讲解的目的主要是为了后续的参数计算。对于初步了解的同学,可以选择先行跳过。
在Transformer中,嵌入层的维度是。多头自注意力的所有子层(自注意力层和前馈网络层)的输入和输出维度也与这个维度保持一致。
使用一致的维度 使各个层之间的数据传递简单直观。每一层的输出可以直接作为下一层的输入,而不需要额外的变换或调整。这种设计简化了模型架构,使得层与层之间的连接更加顺畅。
输入线性变换
输入序列中的每个元素(词嵌入向量)首先通过线性变换生成查询(Query)、键(Key)和值(Value)向量。

计算缩放点积注意力
得到三个矩阵后,对于每个注意力头,使用查询向量、键向量和值向量计算缩放点积注意力(Scaled Dot-Product Attention)。这个计算包括以下步骤:

拼接和线性变换

综上所述,线性变换通过综合多头注意力的信息、转换维度和引入非线性变换,显著提高了Transformer模型的表达能力。
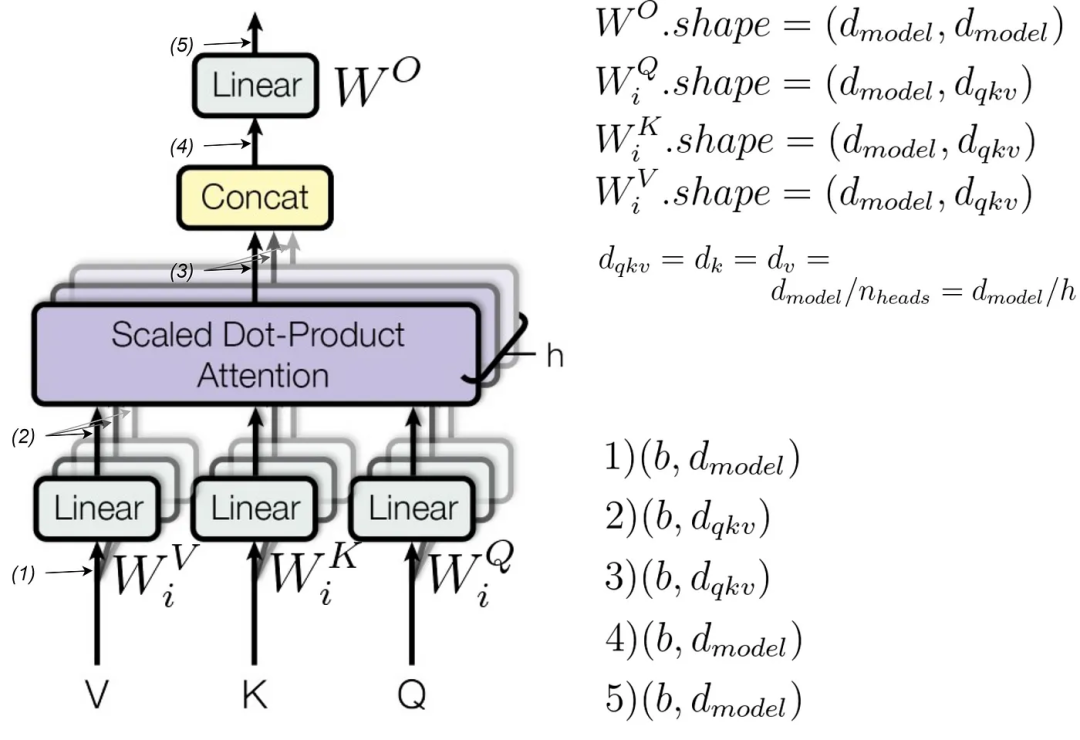
Transformer multi-head attention. Adapted from figure 2 from the public domain paper
Image Source: https://towardsdatascience.com/how-to-estimate-the-number-of-parameters-in-transformer-models-ca0f57d8dff0
总结一下,在编码器中我们一共使用了四个矩阵,分别是:

这些矩阵的参数是在模型训练过程中需要学习的,通过反向传播算法逐步优化,以提升模型在各种语言任务中的表现。
3. 解码器(Decoder)
解码器负责将编码器的语义表示转换为输出文本。它由多个相同的解码器层堆叠而成,每个解码器层包含以下三个子层:
- 掩蔽自注意力机制(Masked Self-Attention): 与编码器中的自注意力机制类似,但会屏蔽后续词语的信息,防止信息泄露。
- 多头编码器-解码器注意力机制(Multi-Head Encoder-Decoder Attention): 关注编码器的输出,获取语义信息。
- 前馈网络(Feed Forward Network): 对输出进行非线性变换。
每个解码器层的输出也都会经过残差连接和层归一化操作。
4. 输出层
输出层将解码器最终层的输出转换为预测的词语序列。通常会使用softmax函数将每个词的输出概率归一化,并选择概率最大的词作为预测结果。
三、Transformer模型参数计算
下面我们按照上面模型组成的介绍顺序,一一计算一下其是包含的模型参数。
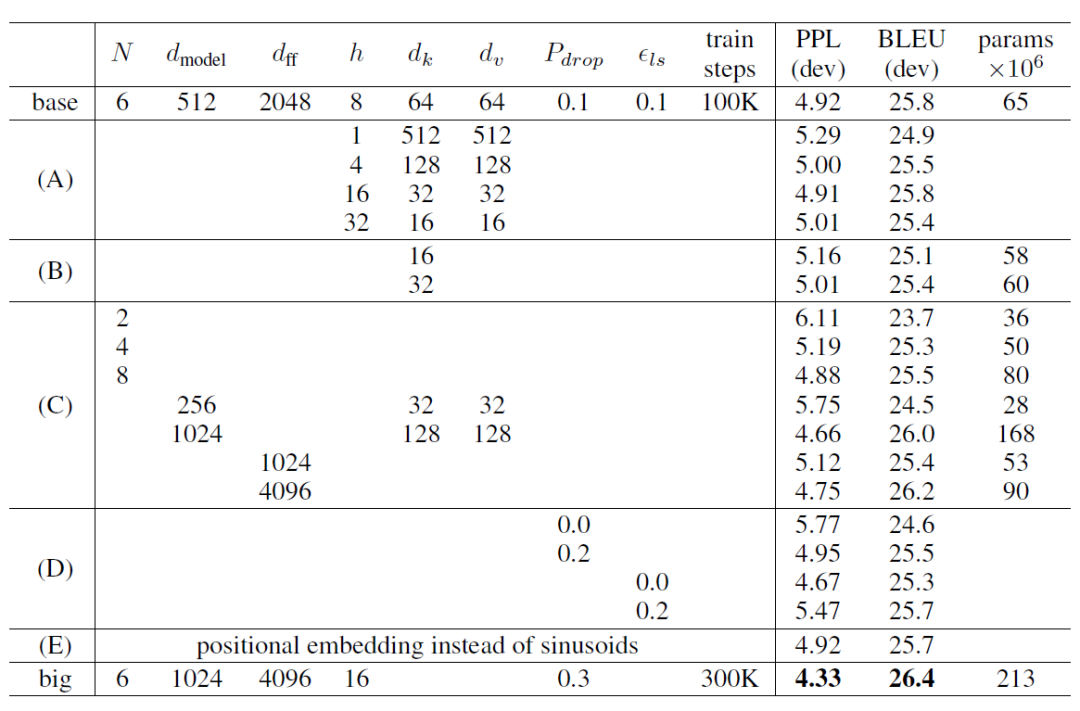
我们先以Transformer论文中的Base模型架构为例。
1. 输入处理参数计算
1) 词嵌入(Word Embedding)
在计算词嵌入(Word Embedding)层的模型参数之前,我们需要确定一些基本的配置信息,这通常包括词汇表的大小(即模型需要处理的不同词汇的数量)和嵌入维度(每个词向量的大小)。
以下是如何计算词嵌入层的参数的详细步骤:
参数计算步骤:
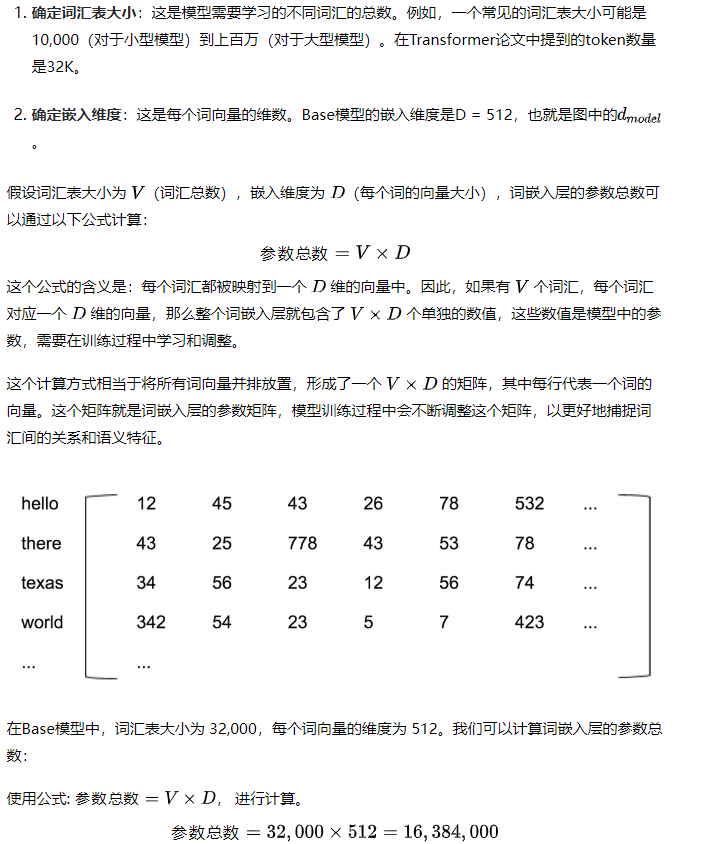
这意味着词嵌入层有 16,384,000 个可训练的参数。
2) 位置编码(Positional Encoding)
在Transformer模型中,位置编码扮演着至关重要的角色,它为模型提供了序列中每个词语相对位置的信息,帮助模型更好地理解词语之间的依赖关系。
位置编码的参数计算取决于其具体实现方式:
- 固定位置编码: 这种方式无需额外训练参数,因为它通过预定义的数学公式生成,例如正弦和余弦函数。
- 可学习位置编码: 这种方式将位置编码作为模型参数进行学习,因此需要引入额外的参数。
对于可学习位置编码,参数数量取决于位置编码的最大长度 (L) 和嵌入层的维度 (D):
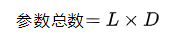

这意味着位置编码层将有262,144个可训练的参数。
综上,位置编码的参数计算完全依赖于它是固定生成还是作为模型参数进行学习。
下面这张图是“位置编码矩阵(Positional Encoding Matrix)”的示例,将一个简单的文本序列 "I am a robot"进行位置编码。
句子 “I am a robot” 中每个单词在句子中占据一个位置。Index of token是每个单词在句子中的索引,从0开始计数。Positional Encoding Matrix是位置编码矩阵,其中的每一行对应于句子中一个单词的位置编码。矩阵的每一列代表编码的一个维度。
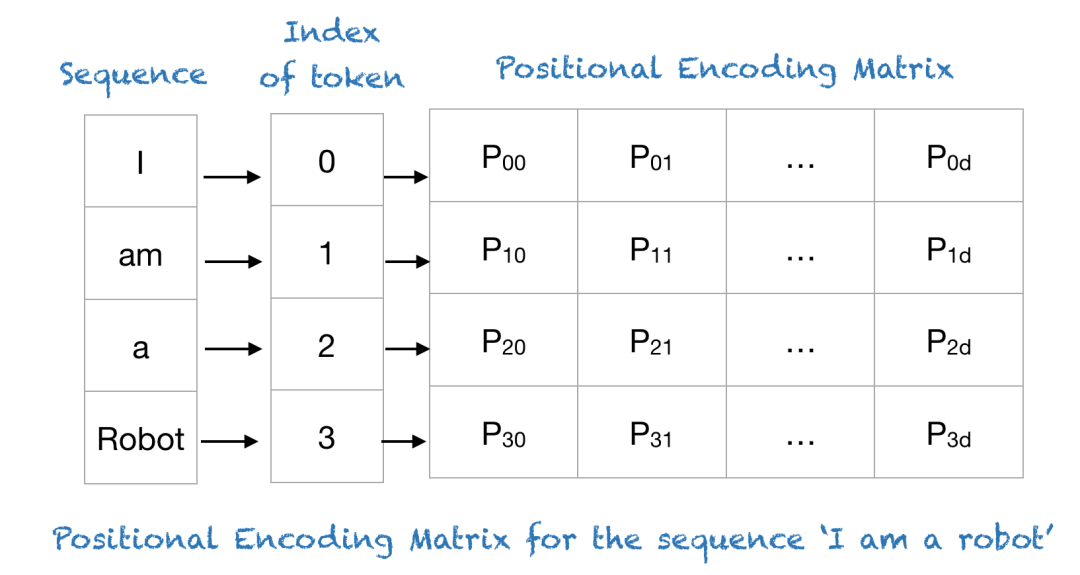
Image Source: https://machinelearningmastery.com/a-gentle-introduction-to-positional-encoding-in-transformer-models-part-1/
Transformer论文《Attention is All You Need》中,关于位置编码(Positional Encoding)的使用,具体设计是:

作者还试验了使用可学习的位置嵌入,与固定的正弦余弦位置编码在效果上几乎没有区别。
2. 编码器(Encoder)的参数
在上面的步骤中,每个单词被转换为预定义维度的连续向量。这些词向量随后通过位置编码进行增强,以注入序列中的位置信息。
Transformer的每个编码器层则对这些表示进行进一步的处理,通过自注意力机制(Multi-Head Self-Attention)和前馈神经网络(Feedforward Neural Network),逐层提炼和丰富这些表示。
最终,这些连续的表示捕捉了输入文本的深层次语义和结构特征,为解码器生成输出提供必要的信息。
一个典型的Transformer编码器由多个相同的层堆叠而成,每层包含两个主要的子结构:多头自注意力机制(Multi-Head Self-Attention)和前馈神经网络(Feedforward Neural Network)。此外,每个子结构后面通常还有规范化层(Normalization Layer)和残差连接(Residual Connection)。
1) 编码器中的参数
每个编码器层的参数主要来源于以下几个部分:
多头自注意力机制(Multi-Head Self-Attention)
多头自注意力机制(Multi-Head Self-Attention)的参数我们上面刚刚总结过。
我们一共使用了四个矩阵,分别是:


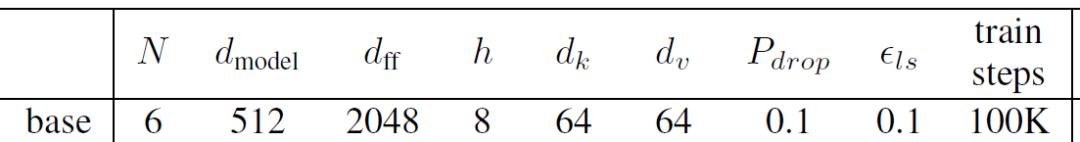
对于论文中的Base模型,我们使用上面中的参数,可以计算出encoder的参数量。
表格提供的参数包括:

3)计算参数
多头自注意力机制的参数计算:
所有头的参数总数:
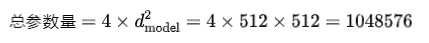
前馈神经网络的参数计算:
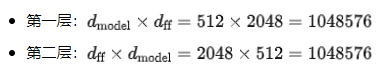
前馈网络的总参数:
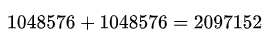
规范化层和残差连接的参数:

编码器每层的总参数:
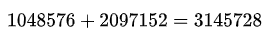
整个编码器的参数总数:
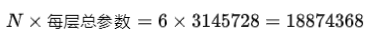
这样,根据给出的参数,可以计算出整个Transformer编码器的参数总数大约为18,874,368个参数。
3. 解码器(Decoder)
在Transformer模型中,解码器(Decoder)部分的设计与编码器(Encoder)相似,但包含额外的子层来处理编码器输出的信息。一个典型的Transformer解码器也由多个相同的层堆叠而成,每层主要包括三个子结构:
- 掩蔽多头自注意力机制(Masked Multi-Head Attention):防止解码器提前“看到”未来的输入。
- 编码器-解码器自注意力机制(Encoder-Decoder Attention):让解码器能够关注到编码器输出的适当部分。
- 前馈神经网络(Feedforward Neural Network):与编码器中相同。
1)解码器的参数计算
以下是每层解码器中各部分的参数计算:
掩蔽多头自注意力机制
与编码器中的自注意力机制相似,每个头的参数由查询(Query)、键(Key)、值(Value)矩阵组成。
编码器-解码器自注意力机制
与上面的自注意力相似,但专门用于整合来自编码器的信息。
前馈神经网络
与编码器相同:
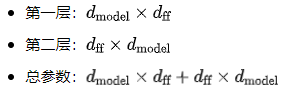
2) 总参数计算(每层解码器)
综合上述三个部分,每层解码器的参数计算如下:
这里的乘以2是因为有两个自注意力结构(掩蔽自注意力和编码器-解码器自注意力),每个都计算一次。
3)整个解码器的参数总数
如果解码器有 层,则整个解码器的参数总数为:
解码器参数总数每层总参数
每层解码器通常参数量大于编码器,因为它涉及额外的编码器-解码器注意力机制。
根据论文Base提供的表格,我们可以计算Transformer模型的解码器部分的参数量。参数包括:
- (解码器层数) = 6
- (模型维度) = 512
- (前馈网络维度) = 2048
- (注意力头数) = 8
- (键维度) = 64
- (值维度) = 64
4)解码器各部分的参数量计算
掩蔽多头自注意力机制和编码器-解码器自注意力机制
两种自注意力层的总参数量(因为每个解码器层有两个自注意力结构):
前馈神经网络
每层解码器的总参数
整个解码器的参数量
解码器包含 层:
每层总参数
因此,整个解码器的参数总量约为 25,165,824 个参数。这包括了掩蔽多头自注意力、编码器-解码器自注意力,以及前馈神经网络的所有参数。
4. 输出层参数
在Transformer模型中,输出层通常位于解码器的最顶部,负责将解码器的输出转换成最终的输出序列,如翻译生成的文本或其他任务的结果。
输出层的主要组成通常是一个线性层,后接一个softmax层,用于生成概率分布来预测每个可能的下一个词或标记。
1)输出层参数
线性层
线性层(也称为全连接层或仿射层)将解码器最后一层的输出映射到一个与词汇表大小相同的维度上。这是通过矩阵乘法实现的,矩阵的维度为 ,其中 是词汇表的大小。
- 参数数量:参数量等于线性变换的权重矩阵中的元素数,即 。
Softmax层
Softmax层本身不包含任何可训练参数,它仅用于将线性层的输出转换成概率分布。Softmax函数按元素操作,将输入值转化为非负且和为1的概率值,适用于多分类任务。
2) 参数总计
假设词汇表大小为 ,模型的 为 512,如在前面的参数配置中给出的,输出层的参数总数为:
参数总数
在Base模型中,给定词汇表大小 且每个词向量的维度为 ,我们可以计算输出层的参数量。
3) 参数计算
线性层
因此,输出层的线性变换包含大约 16.38 百万个参数。
通过线性层的权重,模型可以将解码阶段的复杂语义信息转换为具体的词汇输出,这一过程涉及到大量的参数,尤其是在词汇表较大时。
5. Transformer参数总计
在Transformer模型中,词嵌入层和输出层一般是共享参数,这意味着输入文本的词嵌入表示和最终输出预测的词嵌入表示使用相同的权重矩阵。这样做有以下几个好处:
- 参数共享:减少了模型中需要学习的参数数量,从而降低了模型的复杂性。
- 一致性:确保输入和输出的表示方式一致,提升模型的效果。
如果不共享参数,则需要为词嵌入层和输出层分别学习独立的权重矩阵,这会增加计算和存储的开销。
在论文中,也提到了共享参数:
“In our model, we share the same weight matrix between the two embedding layers and the pre-softmax linear transformation.”
现在我们累加各个部分的参数量。因为共享参数,我们无需计算输出层的参数量。
将输入层、编码器、解码器的参数加在一起:
因此,Transformer Base模型的总参数量大约为60M参数。
这个估计假设词嵌入层和输出层共享参数,如实际不共享则需相应调整计算。
结语
在分析Transformer模型参数之后,我们更加清晰地理解了这种架构及其工作原理。
Transformer模型以其独特的多头自注意力机制和前馈网络,有效地处理序列数据,并在捕捉复杂的依赖关系方面表现出卓越的性能。
每层编码器和解码器都集成了多头自注意力、前馈网络以及规范化层等关键组件。此外,通过维持一致的维度 和实施残差连接,模型确保了信息在层间的顺畅传递,同时也有效防止了在深层网络中常见的梯度消失问题。
今天的学习和参数计算方法不仅适用于Transformer,同样可以扩展到基于Transformer的其他大型模型,如BERT和GPT等。这些模型在处理各种复杂任务时继承了Transformer的强大功能,并通过特定的优化进一步提高了性能。
对于感兴趣的同学,可以继续尝试探索这些模型的内部结构以及参数计算。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。 

四、100+套大模型面试题库

五、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 515
515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









