









A Survey of Pre-trained Language Models for Processing Scientific Text
用于处理科学文本的预训练语言模型调查
paper: https://arxiv.org/abs/2401.17824
github: https://github.com/Alab-NII/Awesome-SciLM
介绍了学术领域的110+个预训练模型: 领域:生物医学领域,化学领域,学术多领域 方向:NER,分类,RE,QA,NLI
架构:基于bert,基于生成,基于其他架构
文章目录~
- 原文阅读
- Abstract
- 1. Introduction
- 2. Preliminary Information
- 3. Existing LMs for Processing Scientific Text
- 4. Effectiveness of LMs for Processing Scientific Text
- 5. Current Challenges and Future Directions
- 6 CONCLUSION
原文阅读
Abstract
用于处理科学文本的语言模型 (LM) 数量正在增加。跟上科学语言模型 (SciLM) 的快速增长已成为研究人员的艰巨任务。迄今为止,尚未对 SciLM 进行全面调查,因此这个问题尚未得到解决。鉴于新 SciLM 不断涌现,评估最新技术以及它们之间的比较在很大程度上仍是未知数。这项工作填补了这一空白,并对 SciLM 进行了全面回顾,包括对其在不同领域、任务和数据集中的有效性的广泛分析,以及对未来挑战的讨论。
1. Introduction
预训练语言模型(PLMs)和大型语言模型(LLMs)对 NLP 研究的格局产生了深远影响,在各种 NLP 任务中展示了其显著效果。这种转变促使人们开发能够解决复杂任务的 LMs,这些任务通常涉及一般和特定领域的语言理解、逻辑推理或常识推理。科学领域的情况尤其如此,许多经过深入研究的任务,如命名实体识别(NER)、关系提取(RE)、问题解答(QA)、文档分类或摘要等,都受益于 LMs 的应用。促成这些成功的一个关键因素是科学文本的丰富可用性。例如,2022 年,PubMed 上新增了近 200 万的生物医学文章,累计发表了 3600 万篇论文。科学文献数量的不断增长使 LMs 能够有效地学习和吸收科学知识,从而提高其在各种任务中的能力。
然而,尽管有关处理科学文本的 LMs(以下简称 SciLMs)的研究非常丰富,但目前还没有关于这一主题的全面调查。因此,目前还缺乏对科学语言模型在过去几年中演变的完整描述,导致人们对这些模型的实际进展状况认识不清。本文旨在弥合这一差距,并首次对科学语言模型进行全面评述。它对过去几年中发表的 110 多个模型进行了描述,对这些模型在不同领域、任务和数据集中的有效性进行了广泛分析,并就未来研究可能面临的挑战展开了讨论。
在本节的其余部分,我们首先展示了我们调查的整体结构。然后,我们概述了我们的研究范围,重点关注六个方面:时间范围、目标语言模型、目标领域、目标科学文本、目标语言和目标模式。随后,我们解释了如何收集相关论文。随后,我们澄清了我们的调查与现有调查之间的区别。最后,我们以进化树的形式概述了过去几年科学语言模型的发展状况。
1.1.Structure of the Paper
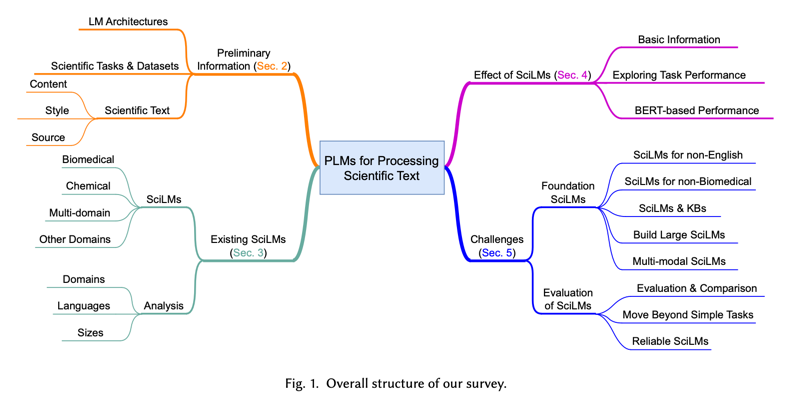
图 1 显示了我们调查的整体结构。
-
我们在第 2 部分提供了背景信息,包括 LM 架构和现有科学任务的详细信息,以及科学文本与其他领域文本之间的区别。
-
在第 3 节中,我们系统回顾了 2019 年至 2023 年 9 月期间处理科学文本的所有现有 PLM 和 LLM,并根据领域、语言和规模三个主要方面分析了它们的受欢迎程度。
-
我们在第 4 节中通过考虑不同任务和数据集的性能随时间的变化,分析了科学语言文本的有效性。最后,
-
我们在第 5 节中强调了当前面临的挑战和未来研究的开放性问题。
1.2.Survey Scope
研究范围:
Time Scope:BERT模型于2018年10月发布。我们的重点是探索处理科学文本的 PLM;因此,我们主要考虑 2019 年至 2023 年 9 月发布的论文。
Target LMs:最近,针对NLP任务的大多数最先进(SOTA)方法都基于PLMs和LLMS。它们对科学研究产生了重大影响;例如,GPT-4的发布改变了 NLP 的研究方向。在本文范围内,我们使用 “语言模型”(LMs)一词泛指 PLM 和 LLM。我们将为处理科学文本而提出的 PLM 和 LLM 称为 SciLM。在我们旨在强调 LLMs 的有效性的特定情况下,我们可以使用两个术语:LLMs 和 SciLLMs,而不是 LMs 和 SciLMs。需要注意的是,我们并不认为对科学下游任务进行微调的一般 LMs 是 SciLMs。此外,我们只关注神经网络 LMs,因为神经网络 LMs 广受欢迎,而且与非神经网络 LMs 相比,神经网络 LMs 在许多任务中的性能更优越。例如,我们在研究中没有考虑 n-gram、条件随机场和隐马尔可夫模型。
Target Domains:我们调查的目的是探索用于处理科学文本的 LM;因此,在本文的范围内,我们的目标是涵盖尽可能多的科学领域。具体来说,我们调查中的科学语言模型涉及多个领域,包括计算机科学(CS)、生物医学、化学和数学。如果有其他领域提出新的 SciLMs,我们将继续扩大我们的研究领域。
Target Scientific Text:在本调查中,当一个LM的训练数据包括科学文本时,我们就将其视为 SciLM。在化学等专业领域,有一些特定类型的文本用于表示和交流该领域特有的信息,如 SMILE或 SEFIE中的分子结构。本研究也考虑了在这些字符串上训练的 LM。
Target Languages: 与 "目标领域 "类似,我们的目标也是尽可能多地涵盖不同语言的可用科学语言工具,以便对用于处理科学文本的语言工具进行全面审查。
Target Modalities: 除了科技论文中的文本,还有其他类型的信息,如图片或表格。不过,在本文的范围内,我们主要关注科学文本的 LM。有关多模态 PLM 的更全面讨论,请读者参阅此处提供的广泛调查[225, 253]。
1.3.Papers Collection
相关论文的收集方式:
由于该主题发展迅速,在第一阶段(从 2019 年到 2023 年 2 月)全面获取相关论文后,我们还将进行第二阶段,以更新列表中的新 SciLM。
第一阶段:2019 年至 2023 年 2 月 我们使用 SciBERT作为种子论文,然后手动检查SciBERT的引用论文。在撰写本文时,SciBERT 有 1,857 次引用。此外,为了确保调查的覆盖范围,我们还使用 BERT 作为种子论文,然后使用 Google Scholar 的“在引用文章中搜索”功能手动检查 BERT 的引用论文,使用三个关键词:‘scientific text’, ‘scientific papers’, 和 ‘scientific articles’。此外,在阅读相关论文和相关综述论文时,我们还会检查论文中提到的论文,如果我们发现缺少任何相关论文,我们会将其添加到我们的研究中。
第二阶段:2023 年 2 月至 2023 年 9 月。 在此阶段,我们仅检查 Google Scholar 中自 2023 年以来 SciBERT 的引用论文。在检查时(9 月 13 日),SciBERT 有 639 次引用。我们手动检查了这些引用论文的标题和/或摘要,以找到新发布的 SciLM。
1.4.Related Surveys
相关的综述论文:
Han 等人 [66]、Kalyan 等人 [91]、Wang 等人 [220, 223] 和 Zhao 等人 [259] 的论文与我们最为相似。具体而言,[66] 和 [223] 都深入研究了PLM 本身,讨论了相关主题,例如PLM 的历史和 LM 架构。同时,[91] 和 [220] 都专注于调查生物医学领域的 PLM。他们总结了许多现有的 PLM,我们也在第 3 节中介绍了这些 PLM。然而,我们的论文更侧重于探索所有领域的 PLM,而不仅仅是生物医学领域。此外,我们还包括将科学文本与其他领域的文本进行比较(第 2.3 节)并分析 SciLM 的有效性(第 4 节)的部分。相比之下,Zhao 等人 [259] 总结了新发布的 LLM,但不像我们的论文那样强调科学文本。
1.5.Landscape of SciLMs
学术模型的领域范围:
图 2 展示了一棵树,展示了 2019 年至 2023 年 9 月 SciLM 的概况。我们观察到以下几点:
- 这棵树相当大且密集,表明在 2019 年至 2023 年 9 月期间存在大量已提出的 SciLM。此外,每年提出的模型越来越多,表明每年的模型数量都在增加。
- 大多数 SciLM 都是基于编码器的模型(91 个模型),其中最常用的是基于 BERT 的模型。这表明对 SciLM 的研究仍然主要集中在基于编码器的架构上,尚未推广到其他架构。
- 如树所示,许多节点为蓝色(生物医学领域节点),表明大多数 SciLM 都是为生物医学领域提出的。
有关我们研究中所有 SciLM 的详细信息,以及对现有 SciLM 的其他观察,请参阅第 3 节。
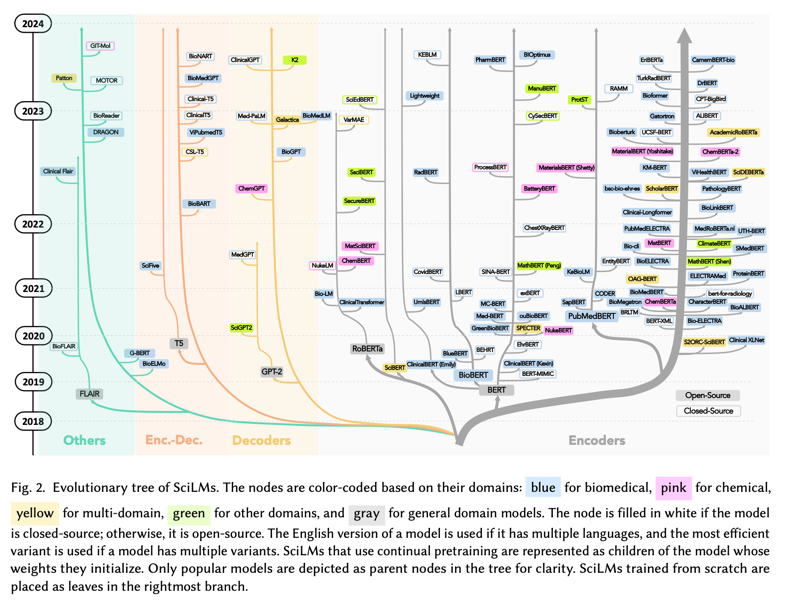
图 2. SciLM 的进化树。节点根据其领域进行颜色编码:蓝色代表生物医学,粉色代表化学,黄色代表多领域,绿色代表其他领域,灰色代表通用领域模型。如果模型是闭源的,则节点用白色填充;否则,它是开源的。如果模型有多种语言,则使用英语版本,如果模型有多个变体,则使用最有效的变体。使用持续预训练的 SciLM 表示为其初始化权重的模型的子节点。为了清晰起见,只有流行的模型才被描绘为树中的父节点。从头开始训练的 SciLM 被放置在最右边的分支中作为叶子。
2. Preliminary Information
- 我们首先简要总结了现有的 LM 架构和其他相关信息。
- 然后,我们介绍处理科学文本的现有任务。
- 最后,我们介绍了科学文本与其他领域文本的区别。
2.1.A Brief Summary of Existing LM Architectures
2.1.1. The core backbone
现有 LM 架构的简要概述—核心backbone(Transformer):
如今,几乎所有的 LM 都依赖于 Transformer 架构。Transformer 是一种专为序列建模而设计的神经网络。该架构背后的核心思想是使用自注意力机制,而无需使用循环或卷积网络。这样可以高效地计算输入和输出序列的表示,而不管它们的长度如何。
Transformer 由两类模块组成:编码器和解码器。这两个模块都由堆叠的网络层组成,每个网络层由一个自注意力子层和一个前馈子层组成。Transformer 架构的一个显著特点是其多头注意力机制,可以并行计算不同的注意力模式。
2.1.2. Types of architecture
现有 LM 架构的简要概述—架构类型:
当前的 LM 可以分为四种不同的类型:编码器-解码器样式、仅编码器样式、仅解码器样式和其他样式。以下小节简要介绍每种类型的 LM。
Encoder-Decoder style:
Encoder-Decoder style:遵循编码器-解码器样式的 LM 基于 Transformer 架构,并根据其预训练目标而有所不同。例如:
- T5是在跨度损坏预测任务上进行训练的,
- BART 是在五个任务上进行训练的,这些任务可以大致分为文本填充和句子置换。
Encoder-only style:
Encoder-only style:只使用编码器的 LM 建立在 Transformer 编码器的基础上,并根据所选的预训练目标而有所不同。屏蔽语言建模(MLM)、下句预测(NSP)、句序预测(SOP)和替换标记预测(RTP)是基本目标。例如:
- 仅编码器 LM 的起源是 BERT,它由 MLM 和 NSP 训练而成。
- 旨在改进 BERT 的 RoBERTa仅采用 MLM 进行训练。
- ELECTRA使用 RTP 和较小的 LM,生成标记替换的句子,并预测替换后的句子。
这种类型的语言模型本质上可以利用句子的所有信息(此功能有时称为双向),并且经常用于分类任务。
Decoder-only style:
Decoder-only style:仅解码器样式的 LM 基于 Transformer 解码器,其主要预训练目标是下一个标记预测 (NTP)。此类模型用于生成任务,例如问答、对话生成等。
Other types of LMs:
Other types of LMs:在本部分中,我们介绍了几个出现在表 6、14 或 15 中但不属于上述三种类型的 LM。
- ELMo是一种连接前向和后向 LSTM 表示的 LM。ELMo 引入了上下文化词嵌入的概念,该概念后来在基于 Transformer 的 LM 中得到了标准化。
- Flair 是一个支持各种类型 LM(包括不使用 Transformer 架构的 LM)的文本嵌入库。
- 图神经网络 (GNN) 是一种用于处理图结构的神经网络。 GNN 经常与 LM 结合使用,以同时处理文本和知识图谱。
2.2.Existing Tasks and Datasets in Scientific Articles
科学文章领域现存的任务和数据集:
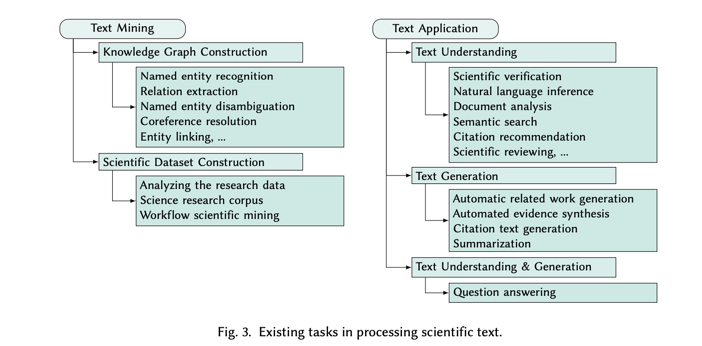
我们将科学文章中的现有任务分为两个分组:科学文本挖掘和科学文本应用。图 3 显示了我们分类中每组任务的摘要。
2.2.1 Scientific Text Mining
任务1—科学文本挖掘:
该组的目的是挖掘现有的科学文章以提取知识,例如从非结构化文本中构建科学数据集或知识图谱 (KG)。我们首先讨论与 KG 构建相关的任务,例如 NER 和 RE。然后,我们将介绍我们所知的现有科学研究数据集列表的基本信息。
1.Knowledge Graph Construction—知识图谱的构建:
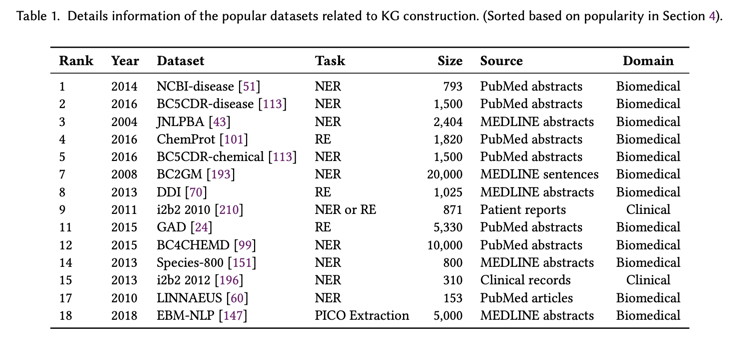
Knowledge Graph Construction:与 KG 构建相关的任务有很多。如图 3 所列,这些任务中的大多数涉及 KG 中的实体或关系,例如 NER、实体链接和 RE。在第 4.1 节中,当我们分析 SciLM 的有效性时,我们发现该组中的许多任务都位列用于评估的 20个最受欢迎的任务之列。具体而言,这些任务包括 NER、RE、PICO 提取、实体链接、消歧和依赖项解析。我们还观察到,在用于评估的前 20 个最受欢迎的数据集中,许多属于 KG 构建组。我们在表 1 中提供了与这些数据集相关的重要信息。
2.Scientific Dataset Construction—科学数据集构建:
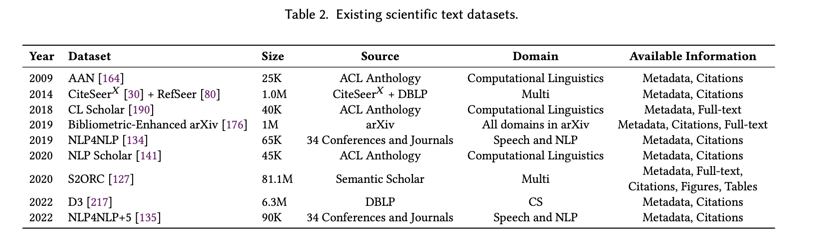
Scientific Dataset Construction:随着研究界的快速发展,每天都有大量论文发表。因此,在处理科学文本时,收集和处理现有研究论文以用于下游任务或 LM 起着至关重要的作用。表 2 列出了我们所知道的科学研究数据集。
2.2.2. Scientific Text Application
科学文本的应用:
这一组的目的是关注与科学理解和科学文本生成相关的高级任务。我们进一步将这一组分为以下三个子类别。
1 .Text Understanding,文本理解:
Text Understanding:科学文本理解通常比一般文本理解更具挑战性,因为它需要领域知识来理解特定术语。目前,有多种任务被用来测试模型对科学文本的理解能力,包括科学主张验证、自然语言推理(NLI)、文档分析和论文评估。有关更多任务,请读者参阅图 3。
2.Text Generation,文本生成:
Text Generation: 该组强调自动生成科学文本的能力。该组的任务包括自动生成相关工作、自动证据综合、生成引文文本和摘要。
3.Text Understanding and Generation,文本理解和生成:
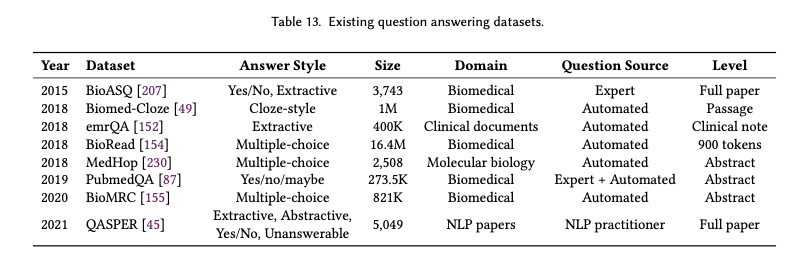
Text Understanding and Generation:我们认为质量保证任务属于这一类,因为它要求同时具备理解和生成能力。从第 4.1 节中我们可以发现,在用于评估 SciLM 的前 20 个流行数据集中,只有两个质量保证数据集。不过,与其他任务的数据集相比,这些数据集出现的频率并不高。具体来说,PubMedQA 被使用了 10 次,BioASQ 被使用了 7 次,而 NCBI-disease 被使用了 27 次。我们认为,质量保证任务包括测试理解和生成,是未来科学语言模型的重要评估标准。因此,我们在表 13(附录 A.1)中简要总结了现有 QA 数据集的重要信息。
2.3.Comparison between Scientific Text and Text in Other Domains
科学文本和其他领域文本的比较:
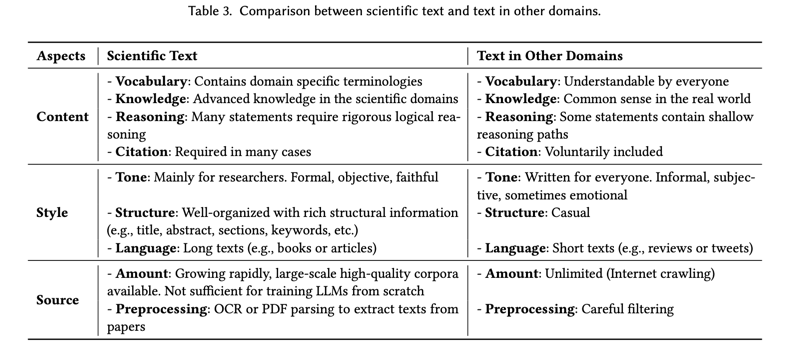
与其他领域的文本相比,科学文本具有许多特殊性。在本节中,我们将从内容、风格和来源三个方面对其进行讨论,以说明科学文本与其他领域文本的主要区别,以及这些特点如何帮助科学语言识别器在某些场景中实现卓越性能。请注意,我们只讨论文本,而不讨论图和表等其他模式,因为这超出了本文的讨论范围。表 3 总结了我们对科学文本和其他领域文本的比较。
2.3.1. Content
1.从文本词汇内容层面:
Vocabulary: 根据科学文本的定义,它是一种书面文本,包含讨论概念、理论或其他一系列基于医学、生物学和化学等科学知识的主题的信息。因此,与其他领域的文本相比,科学文本通常具有更大的词汇量,包括许多术语。例如,生物医学领域的文本包含相当数量的特定领域专有名词(如 BRCA1、c.248T>C)和术语(如转录、抗菌),大多数生物医学研究人员都能理解这些专有名词和术语。其中一些词汇是以前的新词。需要注意的是,与社交网站(SNS)等其他领域的新词不同,这些新术语通常在 "导言 "等部分有明确的定义和详细的解释,或者可以在引用的参考文献中找到。因此,在自成体系的科学文本中进行预训练有利于新词发现。
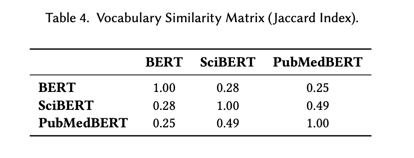
基于这一特点,一些从头开始采用预训练的 LM [15, 111, 127] 可以设计出具有特定领域词汇的标记化器,并学习到更好的术语表征。其他一些研究 [132, 199, 242] 则选择在进行连续预训练时为扩展词汇添加新的嵌入。表 4 显示了 SciLM 和 LM 在一般领域的重叠率。我们可以看到,SciBERT 和 BERT 之间的词汇重叠率低于 SciBERT 和 PubMedBERT 之间的重叠率。这种低 Jaccard 指数表明,许多科学领域的词汇或术语并没有包含在一般领域的 LMs 所使用的词汇集中。此外,这也反映出科学领域和一般领域的分布是不同的,这也增强了对科学文本进行预训练的必要性。
2.从Knowledge知识层面:
Knowledge: 科学文本的主要目的是以清晰、易懂和符合逻辑的方式,向相关领域的专业人士分享和报告先进的研究成果、理论、知识和分析。研究人员通常通过阅读期刊和会议上发表的论文来追赶科学的先进发展,并获得一些用于药物发现等特定任务的卓越知识。因此,要使用 LMs 解决这些专业而具有挑战性的任务,我们还需要用包含许多先进技术和新知识的科学文本对 LMs 进行预训练。例如,在科学论文中预训练的许多特定领域 LMs 可以应用于药物发现与开发、分子合成和材料发现。当针对同一领域的下游任务对这些 LM 进行微调时,它们更容易适应,而且通常比那些只在一般领域预训练过的 LM 性能更好。
3.从Reasoning推理层面:
Reasoning:与一般文本相比,科学文本通常比较复杂。正如我们在上一节中所描述的,科学论文的核心目的之一是向其领域内的同行提出新的观点。因此,大多数科学论文的内容都是以复杂的推理过程来描述研究成果的。此外,有些科学论文还包含复杂的公式,这在一些数学和化学论文中也能找到。然而,目前大多数科学 LM 都没有使用这类信息。利用这些信息可以更好地理解复杂概念和推理。
4.从Citation引用层面:
Citation:在科学领域,很多情况下都需要包含辅助材料。例如,在科学论文中,研究人员需要引用相关文献来支持他们的陈述。除了提供辅助信息外,这类引文还包含内容与辅助材料之间的关系。Yasunaga 等人利用引文中的信息,引入了一个新的训练目标–文献关系预测,以提高其模型的语言理解能力。
2.3.2 Style
1.Tone 层面:
Tone:科学文本的受众主要是研究人员、学者和对特定研究领域有所了解的学术界人士,而新闻等其他领域的文本则面向所有人。因此,撰写科学文本的首要考虑因素是文本是否正式、客观、忠实地传达信息并用证据支持作者的论点。相反,博客或小说等其他领域的文本可能是非正式的、主观的和情绪化的,强调娱乐性、说服力或表达作者的个人观点。因此,经过科学领域预训练的 LM 可以学习生成流畅、专业的科学文本,用于协助学术写作等多种应用。同时,随着开放科学和公共知识的日益普及,许多研究人员也在努力向更广泛的受众(包括学生、记者、决策者和普通大众)宣传他们的工作。为了实现这一目标,“科学文本简化”(Scientific Text Simplification)近来成为一个很有前途的研究课题,其目的是为非专业读者简化科学文本[54, 148]。
2.Structure结构层面:
Structure:科学论文结构严谨,结构信息丰富,包括标题、摘要、内容、表格等。例如,在健康科学领域,Sollaci 和 Pereira指出,科学写作中广泛采用一种非常标准化的结构,即引言、方法、结果和讨论(IMRAD)。特别是从这种结构信息中可以提取一些有用的知识。例如,标题和摘要通常提供了整篇论文的丰富语义。因此,一些工作提取了摘要或标题作为科学论文的摘要,以进行有效的预训练。此外,一些研究还采用了关键词作为有用的元素,从预训练语料库中过滤不需要的论文。值得注意的是,其他一些领域的文本也有结构信息。例如,新闻文章通常以某种方式撰写,读者通过阅读首句(也称为引导句)就会被吸引。因此,这些句子可被视为新闻摘要的代表。然而,这些注释并不总是可靠的,以前在一般领域中有关 PLM 的工作通常会忽略这些信息。
3.Language语言层面:
Language:与其他领域的文本相比,科学文本篇幅较长,通常像书籍和小说一样包含多个页面。我们在一般领域和科学领域中选择了几个流行的预训练语料库,并计算了它们的语言统计数据。在下面的分析中,我们计算了 Pile的所有子集的统计量,其中包含 22 个通用和科学领域的语料。由于该语料库种类繁多且易于获取,我们认为它可以作为常用预训练语料库的代表集。请注意,不同的标记化器会产生不同的统计结果,如不同的标记数。因此,在不失一般性的前提下,我们使用 NLTK库中的 PunktSentenceTokenizer 和 NLTKWordTokenizer分别根据标点符号将文档分割成句子,以及主要根据空格将句子分割成单词。统计结果见表 5。
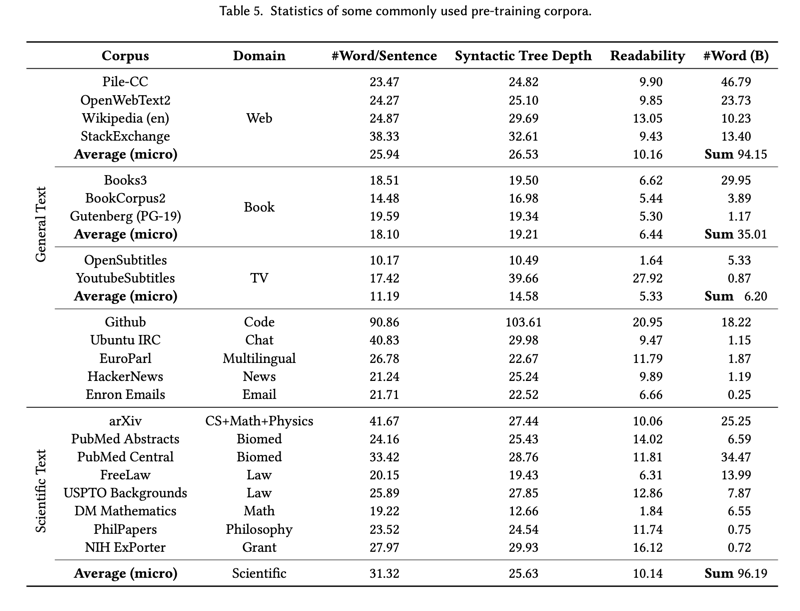
一般来说,我们使用从互联网上抓取的文本进行预训练。我们注意到,互联网上的句子通常平均长度较短(25.94 个字),这对于预训练 LM 来解决需要长期一致性能力的任务来说是不够的。虽然 GitHub 和 Ubuntu IRC 中的句子有很多单词,但我们认为这是因为句子中有很多标点符号,产生的 "单词 "比实际的要多。
此外,我们还计算了句法树的深度和每个句子的可读性,以显示科学文本和其他领域文本的复杂性。我们采用 spacy来计算句子的句法树深度,并计算 Flesh-Kincaid Grade来评估句子的可读性。通过这些指标,我们发现科学文本的复杂度与互联网文本相似,但科学文本的复杂度远高于书籍、电视、新闻、电子邮件等其他领域的文本,因此适合用于提高科学语言模型的推理能力。
此外,科学论文,尤其是同行评审论文,都是经过多次人工讨论和校对后发表的,因此与 SNS 等其他领域的文本相比,质量极高。它们中的大多数仅仅存在语法问题。因此,使用科学文本预训练的语言模型也能生成高质量的文本。
2.3.3. Source
Amount数量:
Amount: 在科学文本领域,可以免费获得大规模的无监督语料库,而且其数量仍在快速增长。Lee 等人使用的 PubMed 摘要数据集和 PMC 全文文章分别包含 45 亿和 13.5 个tokens,而整个英文维基百科只包含 25 亿个tokens。此外,根据 Hoffmann 等人的建议,高质量净化数据集 Pile 的 PubMed 子集包含 50B tokens,足以训练中等规模的 LM(例如 2.7B)。
但我们也应该意识到,随着LLMs的发展,目前从头开始预训练科学词法的数量可能不够。与一般领域的文本相比,通过精心设计的过滤策略,来自互联网的文本成为预训练的主要资源。例如,Brown 等人使用的经过过滤的 CommonCrawl 包含 410B 个tokens,远远超过科学领域现有的语料库。此外,在某些科学领域,收集足够多的高质量数据仍是一项挑战。例如,在核科学领域,Jain 等人[81]仅收集了 7k 份内部报告。经过预处理后,他们只获得了800万个words用于语言建模的预训练,这是很有限的。因此,如何发掘更多的科学文本进行预训练,如何利用有限的科学文本预训练出优秀的科学基础模型,是不久的将来很有希望的方向。我们将在第 5.1.4 节中对这一挑战进行详细讨论。
2.预处理层面:
Preprocessing:除生物医学领域外,要获得高质量的科学文本,通常需要进行仔细的预处理。对于一些多年前发表的旧论文,我们需要执行 OCR或 PDF 解析来提取文本。最常用的 PDF 解析工具是 Grobid [1],它也被用于 S2ORC 数据集的预处理。其他一些模型(如 VILA [186])和数据集(如 PubLayNet [260])也被提出来支持高精度的 PDF 解析。
3. Existing LMs for Processing Scientific Text
现有的处理科学文本的语言模型:
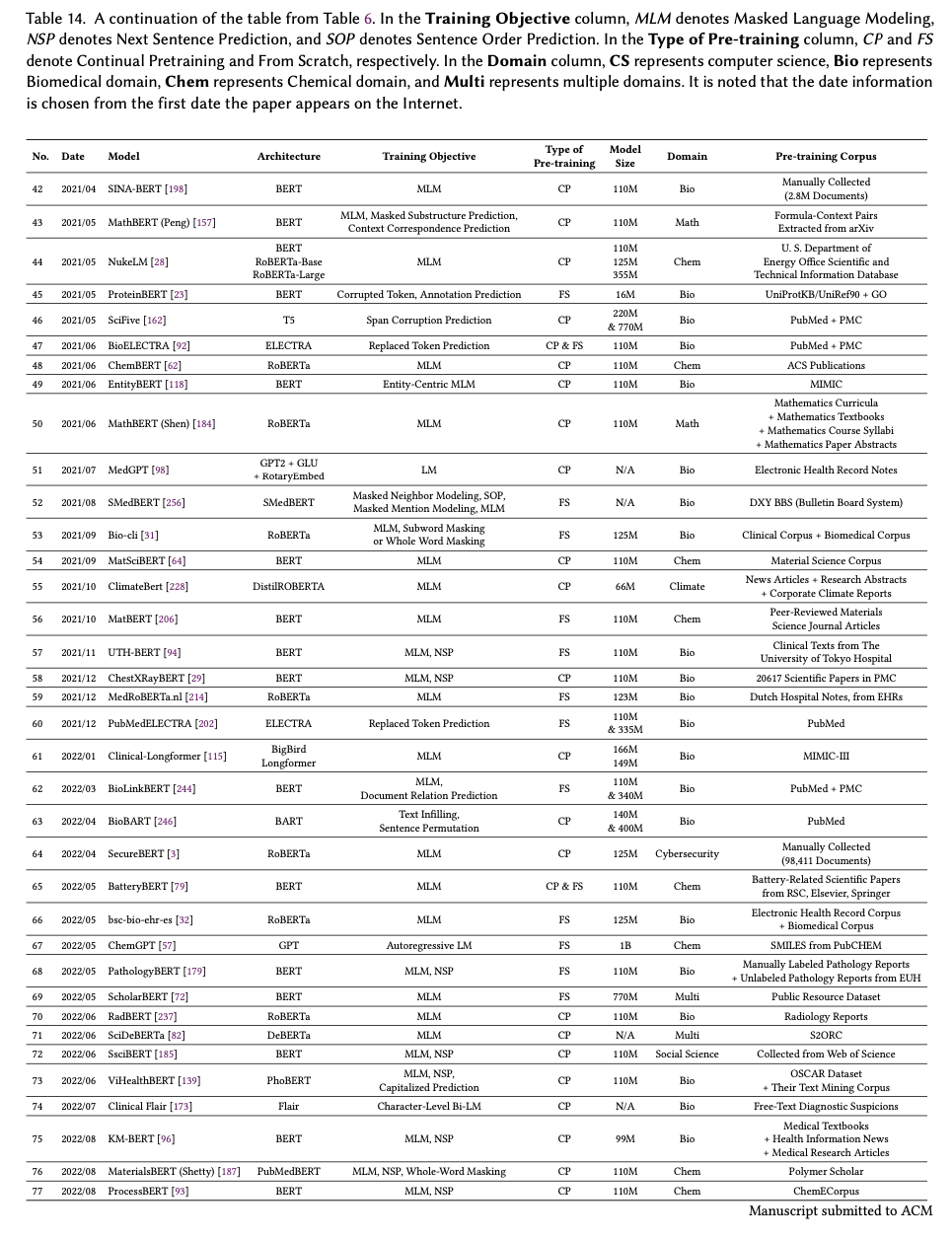
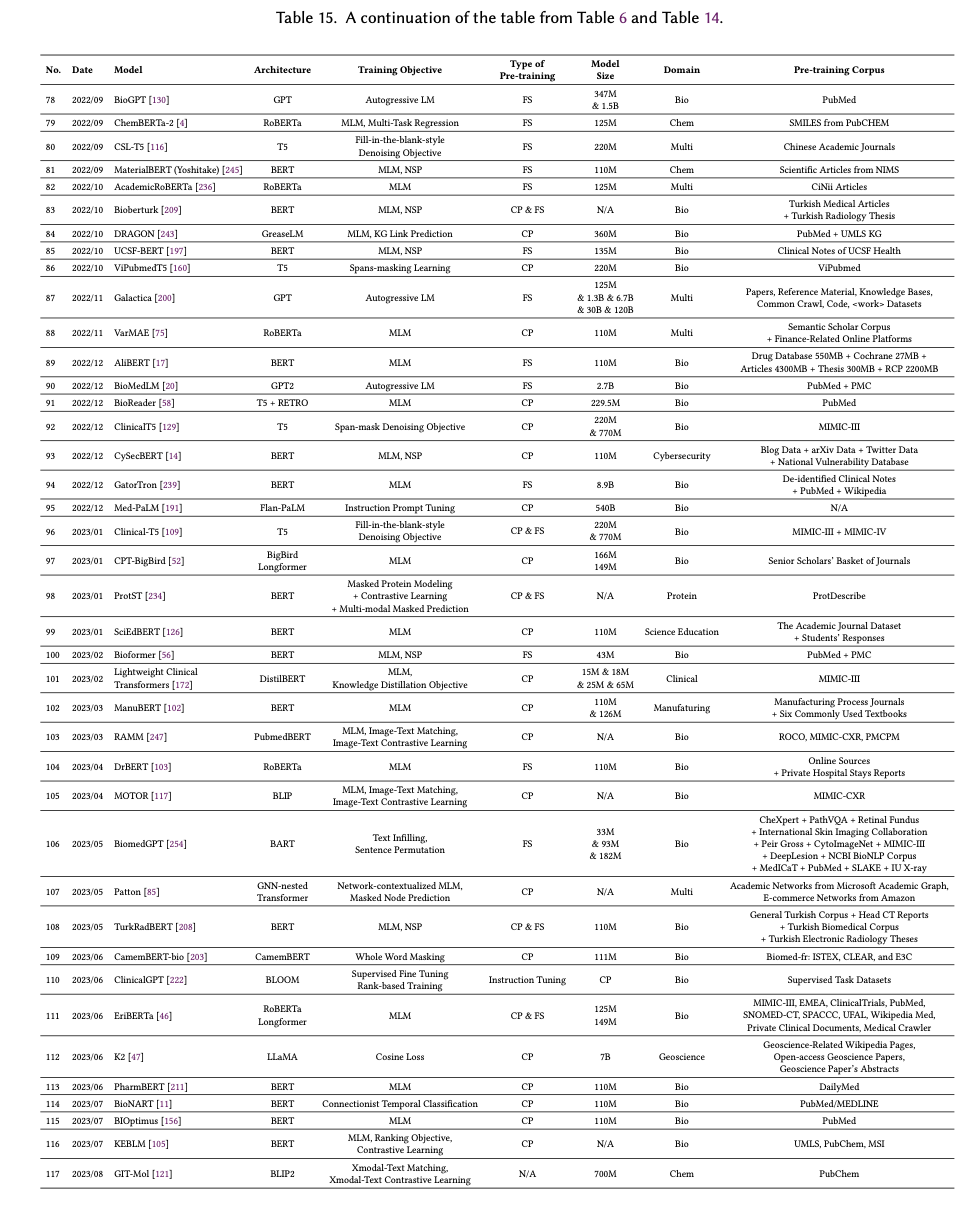
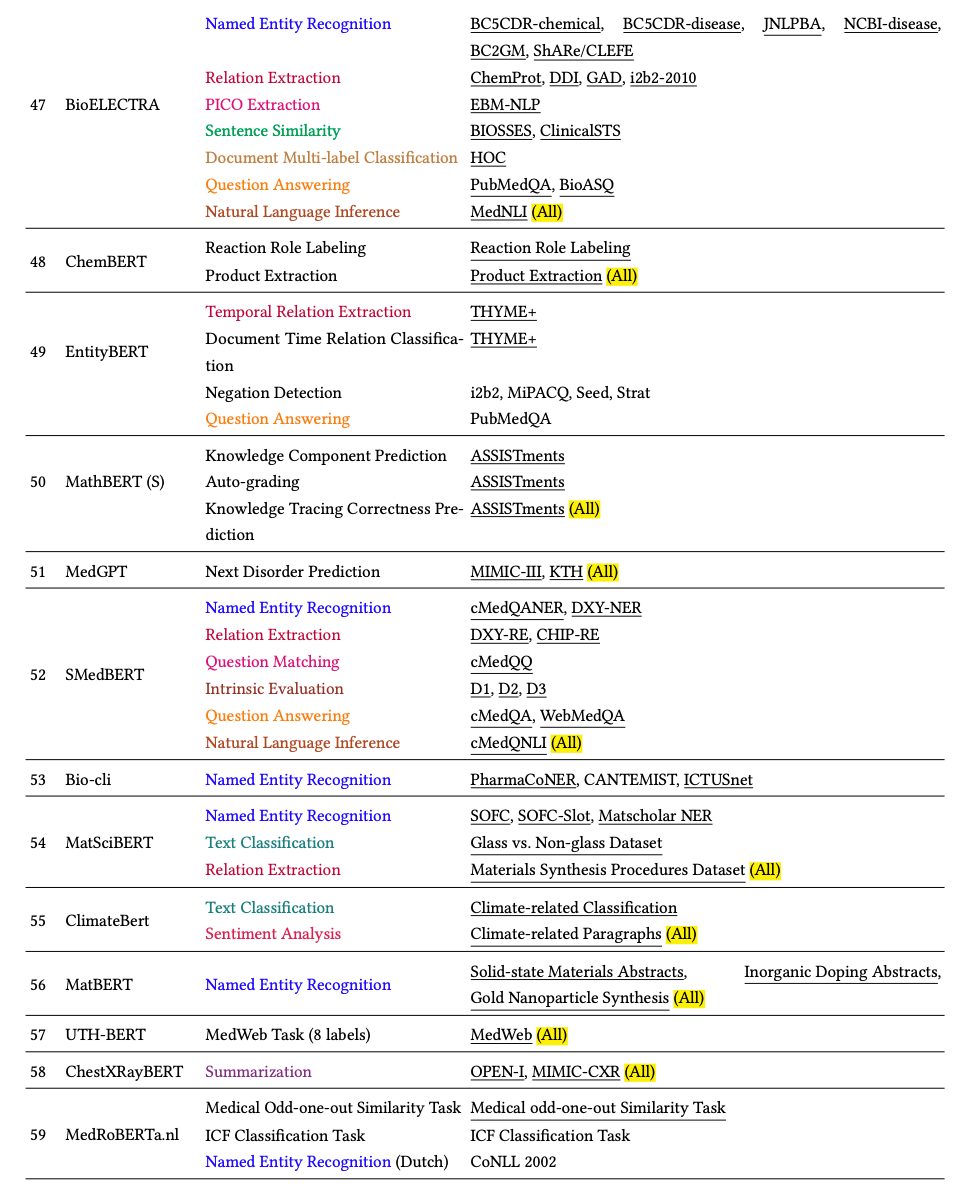
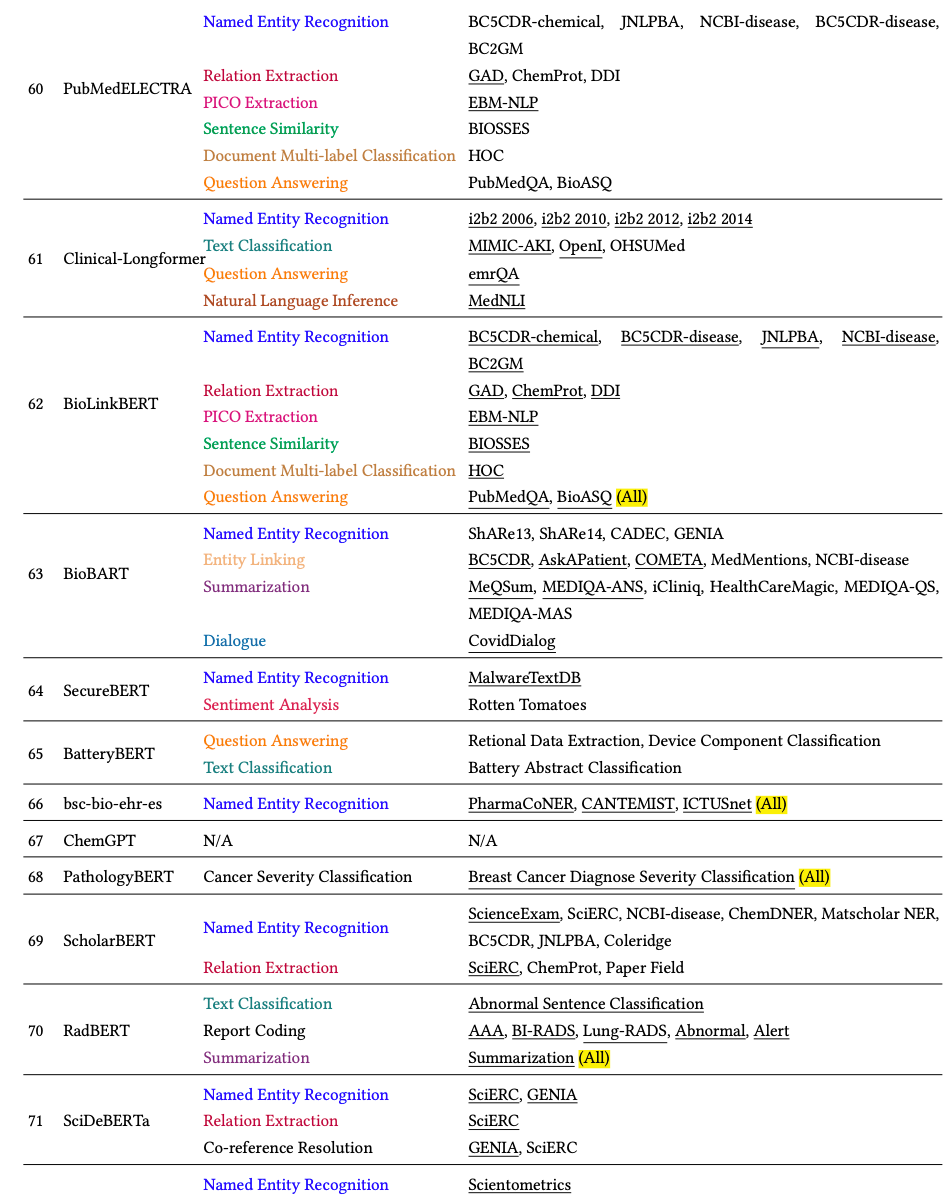
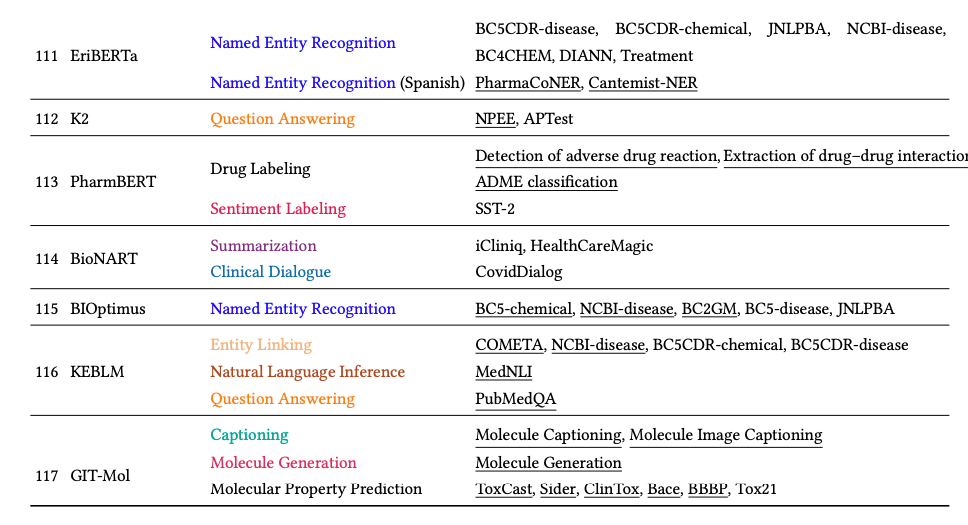
我们系统地整理并在表 6、14 和 15 中展示了 117 个 SciLM。由于篇幅限制,表 14 和 15 列在附录 B 中。我们根据预训练语料库将调查的 SciLM 分为四个部分:生物医学、化学、多领域和其他科学领域。最后,我们进一步分析和讨论了数据域、语言和模型大小等各个方面的受欢迎程度。除了探索 SciLM,我们还概述了在同一时期对非科学文本进行训练的 LM。我们在附录 B.1 中总结了这些模型,以便更详细地了解 LM 概况。
3.1.Biomedical Domain
生物领域的LMs:
本小节详细总结了专门在生物医学语料库上进行预训练的 SciLM,这些语料库包括:
- PubMed、MIMIC-III 和 ClinicalTrials 等广泛认可的来源,
- 到 COVID-19 相关数据集和人工构建的数据集。
自 BERT发布以来,我们已经在生物医学领域发现了 85 个现有的 SciLM,展示了各种不同的模型架构、预训练目标和预训练策略。随着时间的推移,这些 SciLM 的架构已经从基于 LSTM 的架构发展到基于 Transformer 的架构,如 BERT、ALBERT和 RoBERTa。此外,这些模型的规模也有了显著增长,从最初的 12M个参数增长到了令人印象深刻的 540B 个参数。有趣的是,BERT 等模型及其变体具有约 110M和 340M 个参数,由于其成本效益高且在下游任务中性能卓越,已成为生物医学研究的首选。
3.1.1. Bidirectional Language Modeling (Bi-LM)
Bi-LM 是 Transformer 兴起之前的一个常见预训练目标,它结合了前向和后向 LM,根据前一个和未来的单词计算单词概率。自 2019 年以来,一些研究利用基于 LSTM 的架构为生物医学领域预训练 LM。例如,BioELMo使用 ELMo 架构从头开始预训练,而 BioFLAIR [183] 和 Clinical Flair [173] 则使用 FLAIR架构和持续预训练策略进行预训练。
3.1.2. Masked Language Modeling (MLM)
MLM 和 NSP 是 BERT 论文中引入的两个预训练目标。MLM 涉及随机屏蔽输入序列的标记,并使用屏蔽的输入预测屏蔽的标记。另一方面,NSP 旨在预测给定的句子是否是下一个句子。
MLM-Based Models - Continual Pretraining:(持续预训练)
MLM-Based Models - Continual Pretraining:自 2019 年以来,BERT 架构已成为 NLP 中 PLM 的流行架构。已经使用 BERT 架构开发了多个 SciLM,包括 BioBERT 、BERT-MIMIC、Clinical BERT (Emily) 、ClinicalBERT (Kexin)、BlueBERT、BEHRT 、EhrBERT 、MC-BERT、exBERT、LBERT、CovidBERT、ChestXRayBERT、KM-BERT和 ClinicalTransformer。MC-BERT 和 KM-BERT 分别是为中文和韩语设计的。除了原始的 BERT 之外,一些研究还尝试从预训练过程中消除 NSP 目标。这一修改的动机是,有研究结果表明 NSP 目标可能会引入不可靠性,并可能阻碍下游任务的性能。这方面的著名研究包括 UmlsBERT、SINA-BERT、PharmBERT、BIOptimus、CamemBERT-bio和 EntityBERT。SINA-BERT 是为波斯语设计的,使用全词掩码而不是子词掩码。EntityBERT 提出了一种使用 XML 标记标记输入中的所有实体的方法,称为以实体为中心的 MLM [118]。
尝试利用基于 BERT 的紧凑型模型旨在解决环境问题、实现实时处理、提供更轻更快的替代方案、支持边缘计算、优化参数使用、克服内存和速度限制以及提高 NLP 任务的性能。例如:
- Lightweight Clinical Transformers 使用 DistilBERT 架构在预训练阶段提炼知识,从而将 BERT 模型的大小减少了 40%,同时保留了 97% 的语言理解能力。
- 同样,BioALBERT 使用 ALBERT 架构,它基于 BERT,但参数少得多。BioALBERT 有 12M-18M 个参数,是我们调查中最小的生物医学模型。此外,它使用 ALBERT 中提出的 SOP 自监督损失,这有助于保持句子间的连贯性。
基于 BERT 的替代方案比 BERT 更先进,也已应用于生物医学领域。一些研究依靠 Longformer 或 BigBird 架构来处理较长的输入。例如:
- Clinical-Longformer、CPT-Longformer 和 EriBERTa-Longformer 使用 Longformer 架构,
- 而 Clinical-BigBird和 CPT-BigBird 使用 BigBird 架构。
- 此外,RadBERT使用 RoBERTa 架构,它扩展了 BERT,并对预训练进行了更改,包括动态掩蔽和无 NSP。
已经使用 BERT 作为基础模型开发了几种专门定制的架构:
- DRAGON、G-BERT、KeBioLM 和 CODER专注于通过 GNN、KG 链接任务或对比学习等方法整合 KG。
- 此外,还开发了几种针对特定用例的 LM。这些模型包括 MOTOR 和 RAMM,它们使用额外的对比学习和图像-文本匹配目标来预训练多模态 LM。
- ViHealthBERT 结合大写预测来改进越南语的 NER。
- GreenBioBERT使用 CBOW Word2Vec 并提出词向量空间对齐来扩展通用领域 PLM 的词块向量。
- SapBER提出了自对齐预训练来学习自对齐同义的生物医学实体。
- KEBLM 结合了轻量级适配器模块,将领域知识编码到骨干 PLM 的不同位置。
- 最后,BioNART 提出了一种非自回归 LM,可以实现快速文本生成。
MLM-Based Models - Pretraining From Scratch: (从头预训练)
MLM-Based Models - Pretraining From Scratch:这里,我们还有几个利用原始 BERT 架构的 SciLM:
- 这些包括 BRLTM、AliBERT和 Gatortron,其中 AliBERT 适用于法语,而 Gatortron 的模型大小为 8.9B,比该领域的平均模型大小高出 40 多倍。
- 另一方面,没有 NSP 目标的各种模型包括 BERT-XML、ouBioBERT、UTH-BERT、PathologyBERT、UCSF-BERT、PubMedBERT和 Bioformer,其中 UTH-BERT 适用于日语,而 PubMedBERT 使用全词掩码。
使用 BERT 的变体开发了其他几个 LM,例如 Bio-LM、MedRoBERTa.nl、bsc-bio-ehr-es 、DrBERT、EriBERTa 和 Bio-cli。这些模型使用 RoBERTa 架构在生物医学数据上进行预训练。
- MedRoBERTa.nl、DrBERT 和 Bio-cli 分别是为荷兰语、法语和西班牙语设计的。
- 此外,Bio-cli 使用全词掩蔽而不是子词掩蔽。
- SMedBERT是一个在中文语料库上预训练的 LM。它结合了来自链接实体邻近结构的深度结构化语义知识,其中包括实体类型和关系。它利用了诸如掩蔽邻居建模、掩蔽提及建模、MLM 和 SOP 之类的目标。
此外,BERT 还存在不同的自定义架构。例如,CharacterBERT消除了词片系统,而是利用与 ELMo 第一层表示类似的 CharacterCNN 模块来表示任何输入标记,而无需将其拆分为词片。另一方面,Med-BERT结合了特定领域的预训练任务来预测住院时间延长 (Prolonged LOS)。此任务可帮助模型为每个输入就诊序列学习更多临床和情境特征,并促进某些任务。就诊序列是指患者 EHR 数据中就诊的顺序。同时,ProteinBERT的预训练将语言建模与基因本体注释预测的新任务相结合,使其能够捕获广泛的蛋白质功能。最后,BioLinkBERT利用文档链接来捕获跨多个文档的知识依赖关系或连接。
MLM-Based Models - Both Pretraining Strategies:(两种训练策略)
MLM-Based Models - Both Pretraining Strategies:我们还考虑了尝试过这两种预训练策略的 SciLM。一些模型,如 bert-for-radiology、BioMedBERT、Bioberturk和 TurkRadBERT,使用了原始的 BERT 架构 - Bioberturk 和 TurkRadBERT 是为土耳其语设计的。另一方面,BioMegatron [188] 实现了一种简单而有效的层内模型并行方法,可以训练具有数十亿个参数的 Transformer 模型。
3.1.3. Replaced Token Detection (RTP)
RTP预训练任务:代替词发现
BioELECTRA、Bio-ELECTRA、ELECTRAMed和 PubMedELECTRA等模型利用 ELECTRA的预训练目标从头开始预训练其模型。ELECTRA 是一种用更高效的预训练任务 RTP 取代 MLM 的模型。它训练两个transformer模型:生成器和鉴别器。生成器替换序列中的标记,鉴别器尝试识别被生成器替换的标记。BioELECTRA 还发现,在大多数 BLURB和 BLUE基准任务上,FS 策略的表现优于 CP 策略。
3.1.4. Generation-Based Models
基于生成的预训练任务:
基于自回归预训练目标,已经开发了几种基于生成的 SciLM。SciFive、ClinicalT5、Clinical-T5、BioReader 和 ViPubmedT5均基于 T5架构,该架构使用预训练目标,即以自回归方式生成给定序列,并将掩码序列作为输入。
- 除 Clinical-T5 外,所有模型都是基于初始模型权重进行预训练的,而不是从头开始预训练。此外,Clinical-T5 还尝试了这两种预训练策略。
- ClinicalGPT 是一个基于 BLOOM 的模型,它采用基于等级的训练进行强化学习,并通过人工反馈进一步提高性能。
- 在另一项工作中,BioReader 使用检索增强型文本到文本 LM 进行生物医学研究,该 LM 通过从以 PubMed 为中心的约 6000 万个标记的神经数据库中获取和组装相关科学文献块来增强输入提示。
- 另一方面,ViPubmedT5 是在越南语语料库上进行预训练的。
- 此外,BioBART 利用 BART架构(一种去噪自动编码器)通过持续预训练对生物医学文本到文本 LM 进行预训练。
- 另一方面,BiomedGPT、BioGPT和 BioMedLM使用 GPT架构从头开始进行预训练,
- 而 MedGPT使用持续预训练。
- 最后,使用自回归 Transformer 的两个生物医学 PLM 是 Clinical XLNet和 Med-PaLM 。
- Clinical XLNet 使用 XLNet 架构进行持续预训练,该架构利用双向上下文进行掩码词预测。与 GPT 等自回归模型不同,XLNet 考虑了输入序列的所有可能排列,使其能够捕捉单词之间双向的依赖关系,从而更好地理解上下文。
- 另一方面,Med-PaLM 是专门用于医学领域的最大 LM,具有 5400 亿个参数。它是 Flan-PaLM的指令提示调整版本。
3.2.Chemical Domain
化学领域:
我们现在专注于化学领域的 SciLM,总结了那些在 PubChem、材料科学、NIMS 材料数据库、ACS 出版物或自定义数据集等语料库上进行预训练的 SciLM。我们还考虑了在与材料科学、核能和电池相关的领域进行预训练的 SciLM,因为这些领域属于化学领域。最终,我们总共收集了13 个合格的 SciLM。我们的调查显示,化学领域的 PLM 主要依赖于 BERT 架构。在调查的 13 个模型中,有 11 个基于 BERT,参数范围从 110M 到 355M。这表明化学领域 LM 预训练的模型架构选择多样性有限。
1.BERT-Based Models:
基于 BERT 的模型。NukeBERT和 ProcessBERT都是从 BERT 检查点进行预训练的。相比之下,MaterialsBERT (Shetty) 是从 PubMedBERT检查点进行预训练的,使用全词掩码而不是子词掩码,这两个模型都旨在专门研究化学领域。
- 同时,MaterialBERT (Yoshitake) 利用 BERT 架构在化学语料库上从头开始进行预训练。
此外,已经使用 BERT 的不同变体(例如非 NSP BERT 或 RoBERTa)进行了各种研究。例如:
- MatSciBERT和 NukeLM是非 NSP BERT 模型
- 而 ChemBERT 和 NukeLM 的变体使用 RoBERTa 架构在特定领域的数据上持续进行预训练。
- 另一方面,MatBERT和 ChemBERTa分别基于非NSP BERT 和 RoBERTa,使用从头开始预训练的策略。
- 此外,ChemBERTa 的变体ChemBERTa-2采用多任务回归作为附加目标。还值得一提的是,非 NSP BERT 模型 BatteryBERT 同时采用了这两种预训练策略。
2.Generation-Based Models:
基于生成的模型:已经开发了几种用于分子建模的架构。其中一个模型是 ChemGPT,这是一个基于 GPT 的大型化学模型,具有超过 10 亿个参数。它用于生成分子建模,并在包含多达一千万个独特分子的数据集上从头开始进行预训练。
3.Multi-Modal Models:
多模态模型。GIT-Mol是一个集成了图形、图像和文本信息的多模态 LLM。为了执行此任务,刘等人。 [121]提出了一种名为GIT-Former的新架构,它可以将所有模态映射到统一的潜在空间中。
3.3.Multi-domain
多领域模型:
本小节介绍了在多领域语料库上预训练的 SciLM,这些语料库结合了来自不同领域的文本数据。为简单起见,这些模型被称为“多领域”,它们利用丰富的数据,适应各种领域,并允许针对特定领域进行进一步微调。例如,SciBERT是在来自 Semantic Scholar 语料库的 1.14M 篇生物医学和 CS 论文全文上进行预训练的。自 BERT 推出以来,我们已经确定了 11 个多领域 SciLM。大多数使用 BERT 或类似的架构,而另外两个采用基于生成的架构。大多数模型都倾向于 110M 的参数大小,但 Galactica除外,它的参数大小从 125M 到 120B 不等,是该领域中最大的。
1.BERT-Based Models:
基于 BERT 的模型:多项研究使用 BERT 架构为多个领域创建通用 PLM。例如:
- SciBERT 和 S2ORC-SciBERT使用 BERT 从头开始预训练他们的模型。
- 其他作品如 OAG-BERT和 ScholarBERT 则取消了 NSP 预训练目标,因为它对下游任务性能的贡献有限。AcademicRoBERTa和 VarMAE 采用了 RoBERTa 架构。
值得一提的是,VarMAE 采用持续预训练策略,而 OAG-BERT、ScholarBERT 和 AcademicRoBERTa 则从头开始。
- AcademicRoBERTa 是为日语打造的。
- 另一方面,SciDEBERTa使用科学技术领域语料库进一步预训练了 DeBERTa。这种基于 Transformer 的架构旨在通过两种技术改进 BERT 和 RoBERTa 模型:解缠注意力机制和增强型掩码解码器。
2.Specialized Architecture-Based Models:
基于专门架构的模型:一些研究定制了预训练目标。例如:
- SPECTER是一个使用 SciBERT初始化的新 LM,它添加了 Triple-loss,通过合并引文来学习高质量的文档级表示。
- 另一个例子是 Patton,它采用了持续预训练和 GNN 嵌套的 Transformer 架构。它的架构包括两个预训练目标:网络上下文化的 MLM 和 Masked Node Prediction,这使得创建 LLM 能够捕获文档间结构信息。
3.Generation-Based Models:
基于生成的模型。已经做出了一些努力来使用基于生成的架构预训练多领域 LLM。例如:
- CSL-T5是使用 T5 从头开始为中文进行预训练的,
- 而 Galactica是一个 120B 自回归 LM,旨在存储、组合和推理科学知识。该模型是在大量科学论文、参考资料、知识库和其他来源的基础上从头开始进行预训练的。
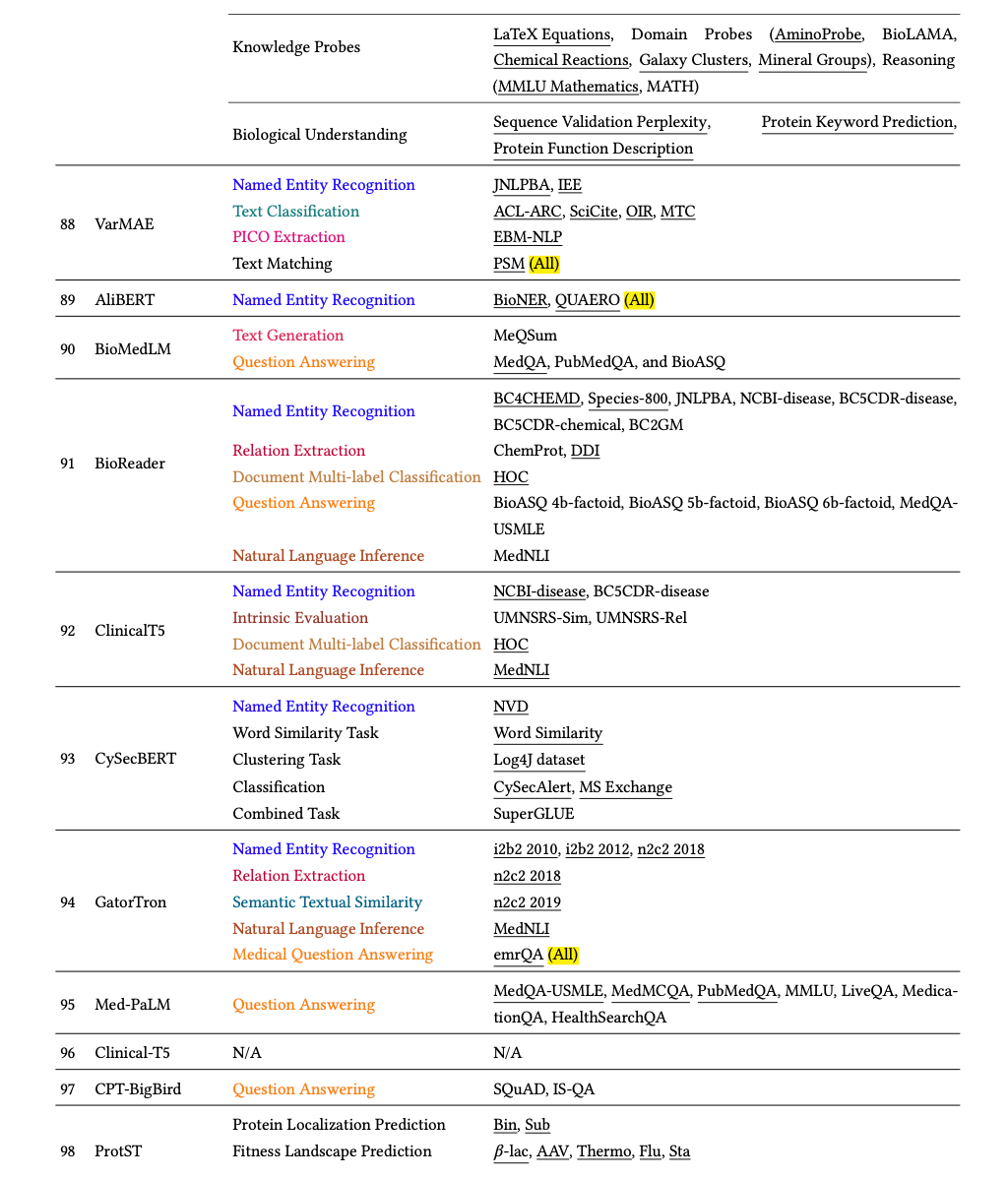
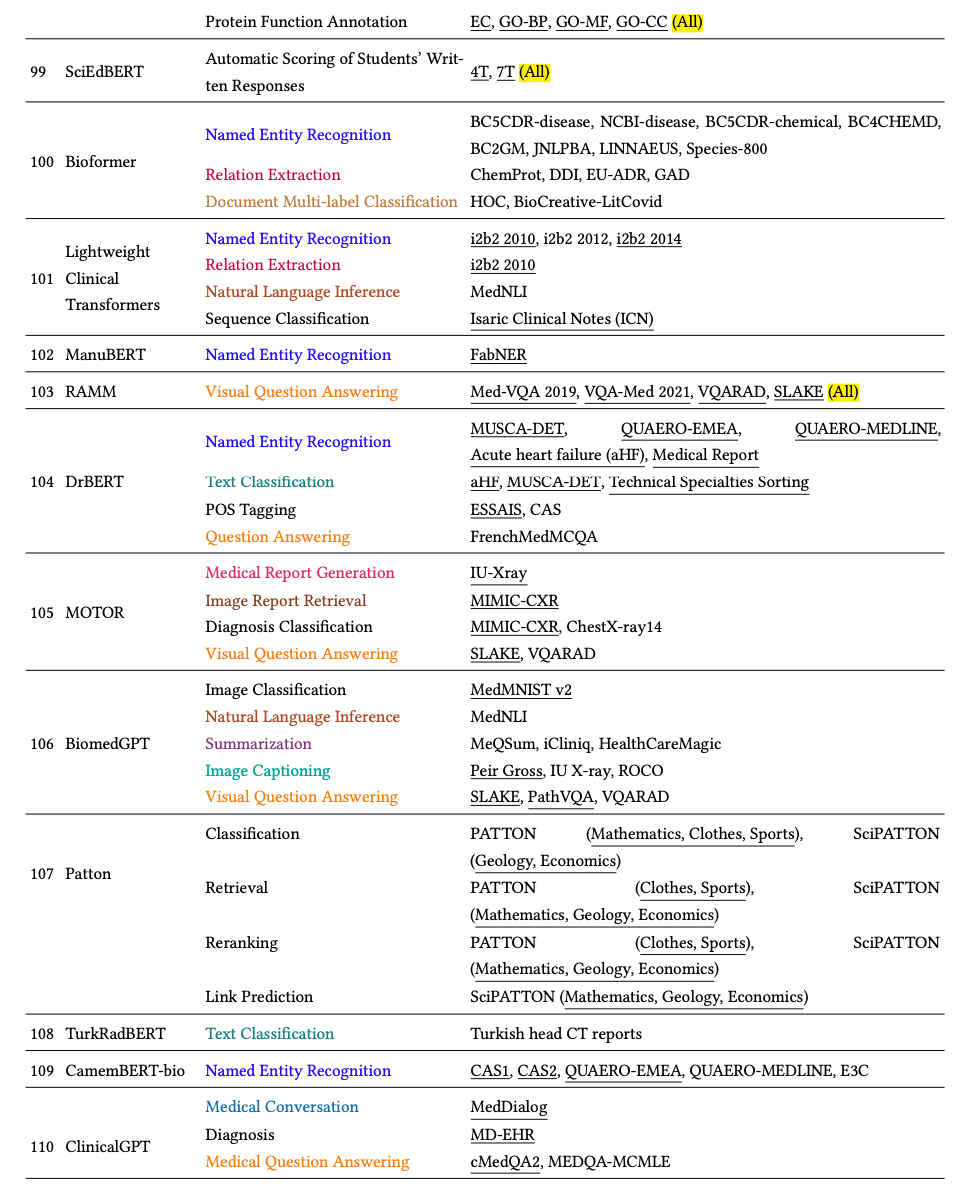
3.4.Other Scientific Domains
其他科学领域模型:
除了前面提到的那些探索较多的领域外,我们的调查还全面概述了在气候、计算机科学、网络安全、地球科学、制造、数学、蛋白质、科学教育和社会科学等探索较少的领域进行预训练的科学语言模型。在这些领域中,除了一个包含 7B 个参数的 LLM 外,我们发现模型规模普遍偏好为 110M。
1.BERT-Based Models::
基于 BERT 的模型:有多种基于 BERT 架构的模型,其中一些使用原始 BERT,而另一些则使用非 NSP BERT 和 RoBERTa 等高级变体。例如:
- CySecBERT、SsciB- ERT、ManuBERT和 SciEdBERT分别是为网络安全、社会科学、制造业和科学教育设计的持续预训练 SciLM。CySecBERT 和 SsciBERT 使用原始 BERT 架构,而 ManuBERT 和 SciEdBERT 则使用不含 NSP 目标的 BERT。
- 此外,ClimateBert 、SecureBERT 和 MathBERT (Shen)利用 RoBERTa 架构,分别对气候、网络安全和数学语料进行了进一步的预训练。请注意,ClimateBert 是 RoBERTa 基础模型的提炼版本,其训练过程与 DistilBERT 相同。
2.Specialized Architecture-Based Models:
基于专门架构的模型:存在各种专门为特定用例设计的基于 BERT 的模型。
- MathBERT (Peng)是一个基于 BERT 的持续预训练模型的示例,该模型利用 MLM、上下文对应预测和掩蔽子结构预测来学习表示并捕获数学公式的语义级结构信息。
- 另一方面,ProtST是一个基于 BERT 架构构建的框架,用于蛋白质序列和生物医学文本的多模态学习。它包括掩蔽蛋白质建模、对比学习和多模态掩蔽预测等任务,以将不同粒度的蛋白质属性信息合并到蛋白质 LM 中。ProtST 在蛋白质语料库上进行了持续预训练。
3.Generation-Based Models:
基于生成的模型:有几种基于 GPT 的模型可用。
- SciGPT2是专门为 CS 领域设计的模型,它是通过对 GPT2 模型进行持续预训练而创建的。
- 另一个例子是 K2,它是一个包含 7B 参数的 LLaMA 模型,并在特定于地球科学的文本语料库上进行了进一步预训练。
3.5.Summary and Discussion
本小节将讨论专为处理科学文本而设计的 LLM 的受欢迎程度。我们的分析考虑了各种因素,如领域、语言和模型大小。我们使用从科学语言模型调查中获得的统计数据来展示我们的研究结果,这些数据如表 8、表 7 和图 4 所示。
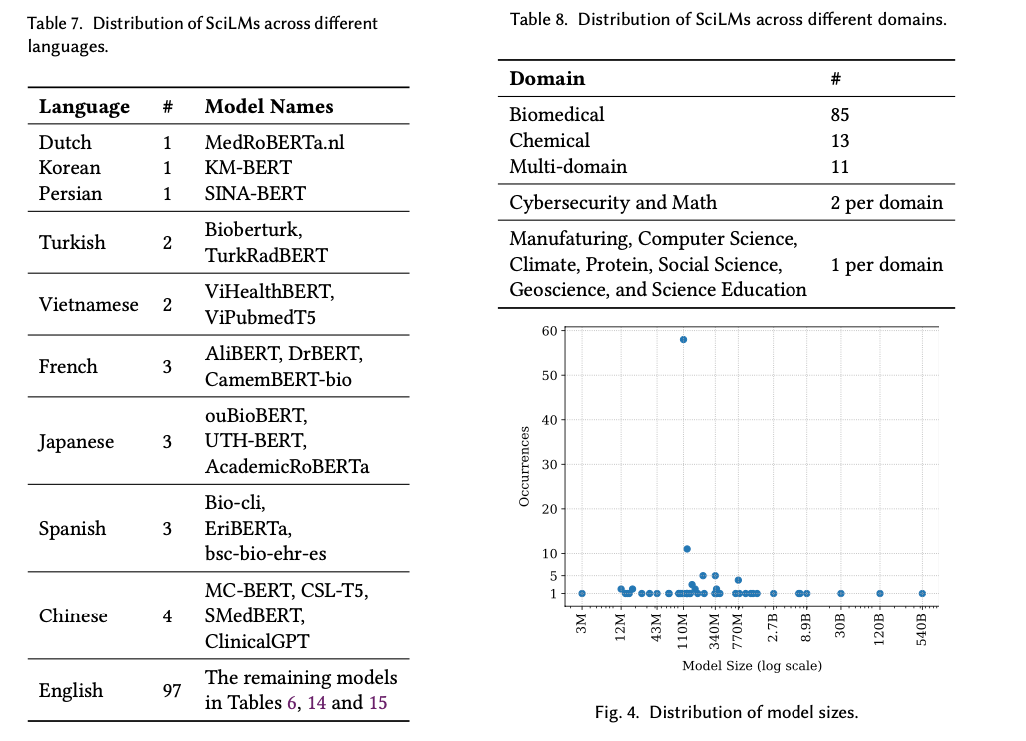
3.5.1. Domain-wise Distribution of SciLMs
1.SciLM 的领域分布:
1.1.生物医学领域:
表 8 概述了不同领域的 SciLM 分布情况。生物医学领域现有模型数量最多,共有 85 个。这种优势归因于生物医学领域拥有大量的科学文献,PubMed 就是一个典型例子,占 Pile 数据集的 17.5%。特定领域(例如生物医学领域)拥有大量高质量数据,这使得开发特定领域的 LLM 变得更加容易,这些 LLM 在下游特定领域的 NLP 任务中表现良好。因此,研究人员有动力为生物医学领域创建预训练的 LLM,从而推动了该领域的 SciLM 的增长。
1.2.化学领域:
化学领域有 13 个现有模型,是所有其他领域中模型数量第二多的领域。有趣的是,化学和生物医学领域之间存在显着的重叠,如 BC5CDR、JNLPBA、BC4CHEMD 等各种生物医学或化学数据集所示。这种重叠提供了一个机会,可以利用生物医学领域的大量数据来促进为化学相关任务开发更有效的语言模型。此外,在化学领域,语言模型开发还有许多潜在的应用,例如自主化学研究、药物发现、材料设计和化学空间探索。这些强调了语言处理在化学相关研究中的重要性。
1.3.多领域:
还有 11 个多领域模型,旨在满足更广泛的科学领域。此外,使用混合领域对 LLM 进行预训练可以增强其推广到不同任务和数据集的能力。通过吸收广泛的知识,这些模型可以更好地理解多个主题,从而为各种下游任务提供更好的性能和更大的通用性。网络安全、数学、气候、计算机科学、地球科学、制造业、蛋白质、科学教育和社会科学等其他领域各有一或两个模型,表明未来研究和开发的潜在领域。
3.5.2. Language-wise Distribution of SciLMs
科学语言模型的语言分布:
表 7 显示了 SciLM 在各个语言中的流行程度。英语以 97 种模型占据主导地位,凸显了其作为科学交流主要语言的作用。其他语言,如中文、西班牙语、日语和法语,也占有相当大的份额,并且已开发了多种用于科学文本处理的模型。然而,荷兰语、韩语、波斯语、土耳其语和越南语的专用模型较少,这表明这些语言的科学文本处理需求最近才引起社区的关注。语言使用的多样化凸显了科学研究的全球性,也凸显了多语言 LM 的重要性,以满足来自不同语言背景的研究人员的需求。值得注意的是,科学文本可以有多种形式,例如医疗记录、论文、文章、演讲、教科书和书籍,这些文本通常以专门的技术语言或非英语语言编写,以面向目标受众。
3.5.3. Distribution of Model Sizes
模型大小的分布:
模型大小分布如图 4 所示。大小在 100M 到 400M 以下的模型最受欢迎,共有 103 个。其中,大小为 110M 和 125M 的模型分别占 58 个和 11 个。这种受欢迎程度可以归因于效率和有效性之间的平衡。这些模型中的许多都基于成熟的架构,如 BERT-Base 和 BERT-Large,使研究人员能够利用先前的工作,同时平衡计算成本和性能。有 13 个模型的大小小于 100M,它们可能因其成本效益和适合设备应用而受到青睐。研究人员通常在计算资源有限时选择这些模型,专注于较轻模型就足够的任务。有 6 个相对较大的模型,大小从 700M 到不到 1B。这些模型在处理复杂的科学语言细微差别方面提供了增强的能力;然而,它们的大小在训练成本和计算要求方面带来了挑战。最近,人们尝试构建大规模 LM 的人数激增,其规模从 1B 到 540B 不等,有 11 个模型代表了这些模型。这些模型代表了语言处理技术的前沿,但也带来了重大挑战,包括需要大量语料库、大量的训练时间和大量的计算资源。虽然这些模型提供了卓越的性能,但它们在科学界广泛采用的可行性和实用性仍然是活跃的研究和辩论主题。
4. Effectiveness of LMs for Processing Scientific Text
语言模型处理科学文本的有效性:
在本节中,我们首先介绍了与 SciLMs 使用的任务和数据集相关的基本信息,重点介绍了前 20 个热门任务和数据集(第 4.1 节)。然后,我们将探讨五项任务的性能随时间的变化: NER、Classification、RE、QA 和 NLI(第 4.2 节)。此外,我们还讨论了优于以前的模型或达到 SOTA 的模型的详细信息,例如它们使用的任务和数据集的数量。最后,我们将对模型结构固定时的性能进行进一步放大(第 4.3 节)。
4.1.Basic Information
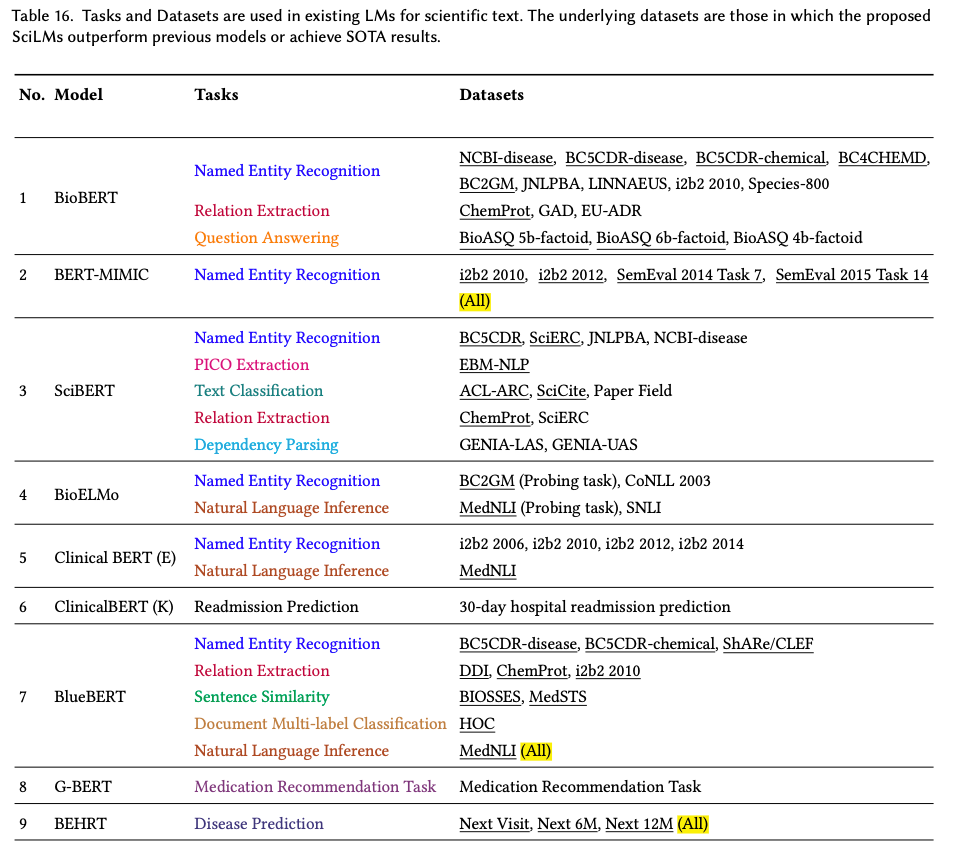
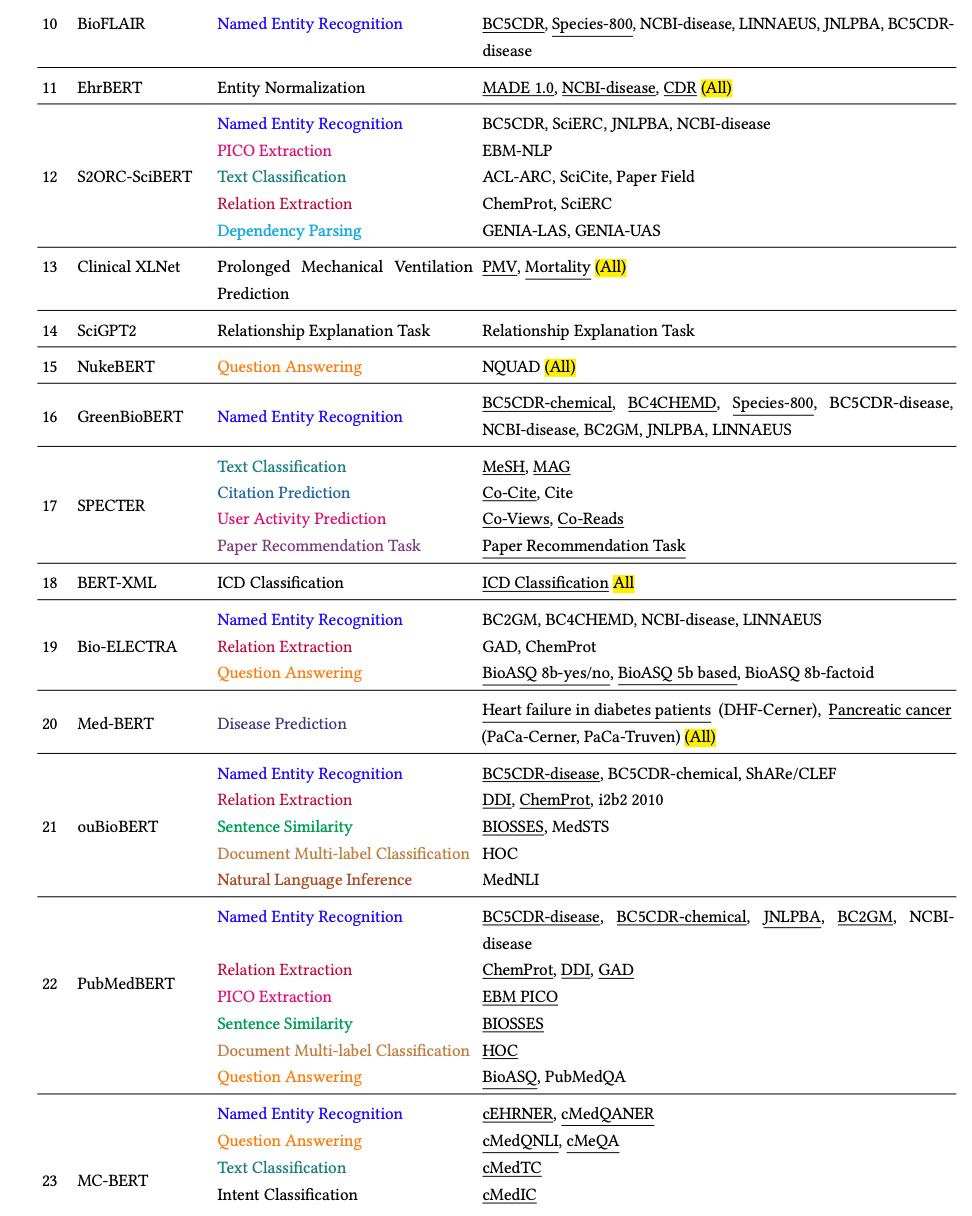
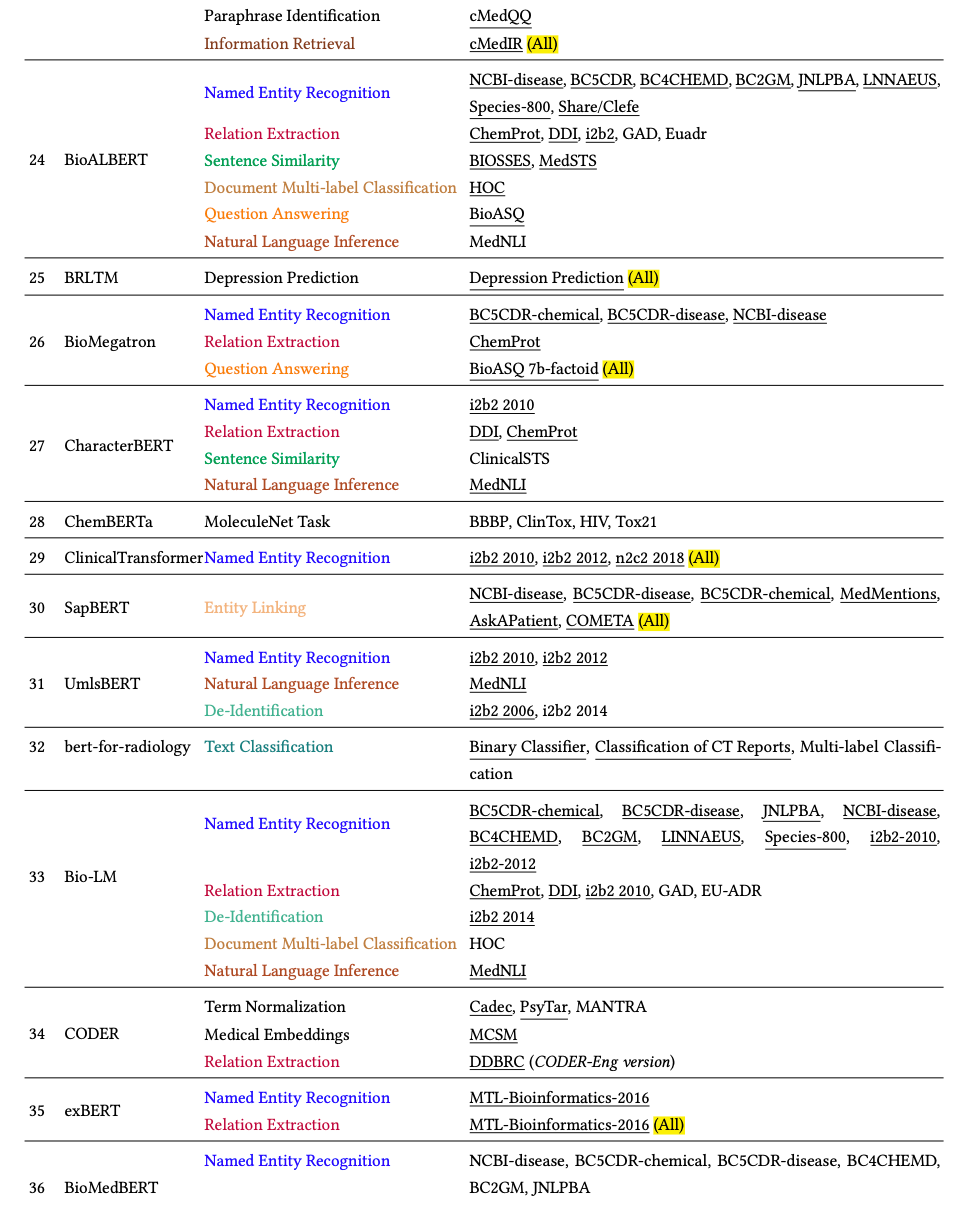
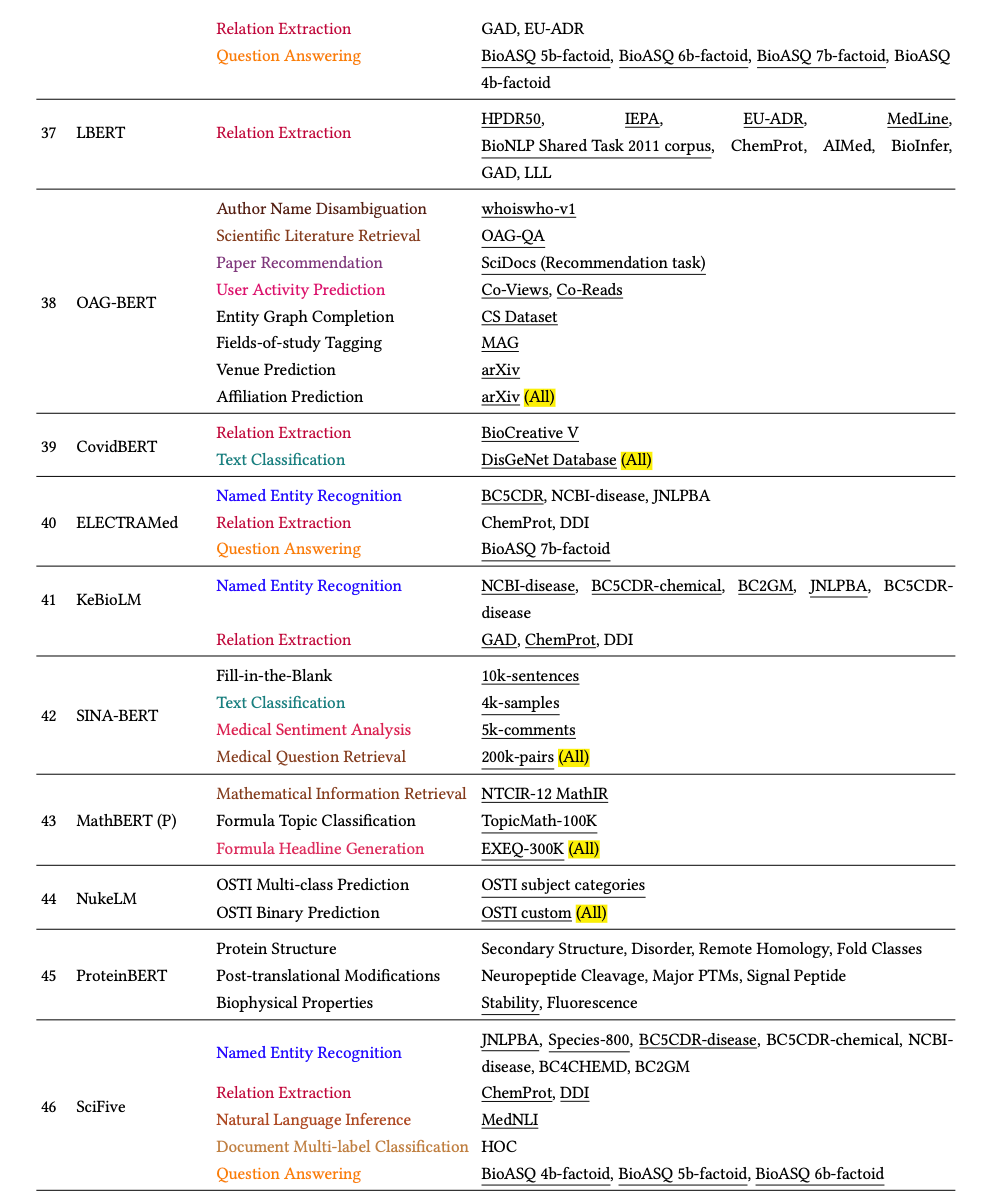
由于科学论文的写作风格和术语存在差异,许多任务和数据集都标有不同的名称,例如“关系提取”和“关系分类”,或者 EU-ADR 数据集可以写成“EU-ADR”或“EUADR”。为了确保分析的一致性,我们对任务和数据集的名称进行了规范化。如果任务名称不同但数据集名称相似,我们会仔细检查任务名称以确定是否应将它们分组或分开。经过这个繁琐的手动过程,我们发现许多不同的任务名称仍然看起来相似。因此,我们依靠启发式方法来对任务名称进行分组。具体来说,我们依靠“分类”等提示词将名称任务归类到我们预定义的任务名称列表中。例如,如果任务名称包含“分类”(例如“序列分类”),我们将其归类为分类任务。表 9 列出了我们的方法生成的任务名称组的示例。需要注意的是,这种方法不能完美地将所有不同的任务分组,例如,任务“关系解释任务”是一种生成任务,但任务名称中不包含“生成”一词。为简单起见,我们保留其原始任务名称。所有 SciLM 的任务和数据集名称的详细信息均列在附录 C.1 中的表 16 中。
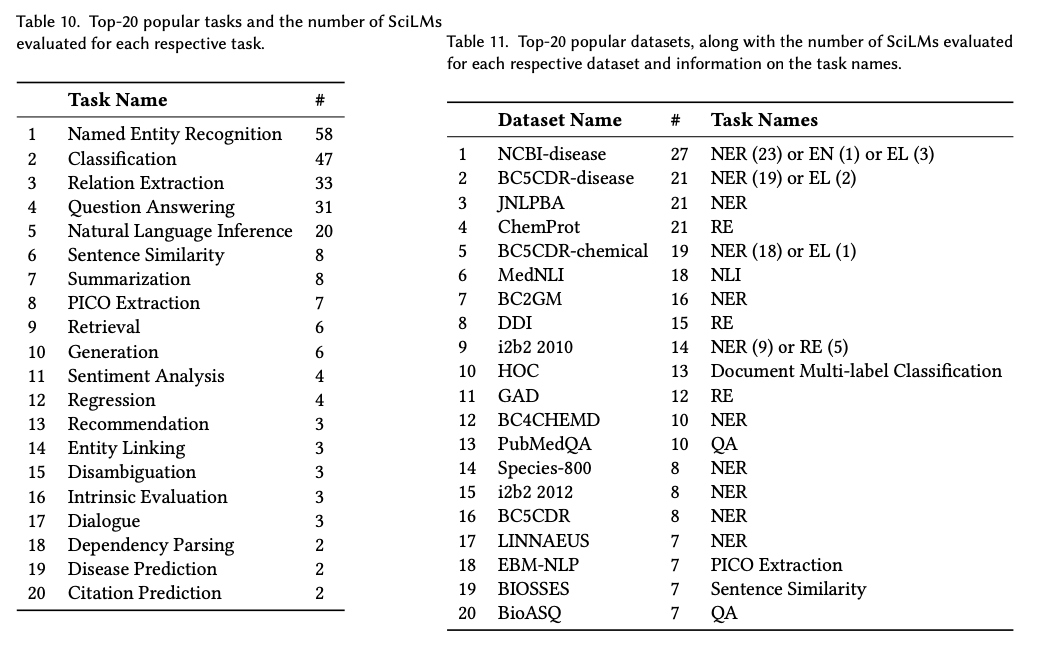
总之,经过分组后,我们调查中的 117 个 SciLM 评估使用了 79 个任务和 337 个数据集。值得注意的是,如果仔细检查细节,这 79 个任务可以进一步分组。但是,我们发现这个过程是不必要的,所以我们选择跳过它。表 10 和表 11 列出了最受欢迎的前 20 个任务和数据集,以及针对每个任务和数据集评估的 SciLM 数量。我们观察到 NER、分类、RE、QA 和 NLI 成为最受欢迎的前五大任务。具体来说:
- NER 任务的前五个数据集是 NCBI-disease、BC5CDR-disease、JNLPBA、BC5CDR-chemical 和 BC2GM。
- 对于 RE 任务,ChemProt 和 DDI 脱颖而出,成为排名前两位的数据集。
- MedNLI 在 NLI 任务中占据首位,
- 而 HOC 则是文档多标签分类任务中最受欢迎的数据集,该任务属于分类任务。
- 对于 QA 任务,PubMedQA 和 BioASQ 被认为是两个最受欢迎的数据集,尽管与其他数据集相比,在这些数据集上评估的 SciLM 较少。
在下一小节中,我们将深入探讨 SciLM 在这些流行任务和数据集上的任务表现。
4.2.Exploring Task Performance
在本节中,我们首先展示五项最热门任务的图表,以直观地展示 SciLM 性能随时间的变化情况。然后,我们分析了表现优于先前模型或取得 SOTA 结果的 SciLM 列表。
4.2.1. Performance Changes Over Time
随着时间性能的变化:
1.NER 任务:
NER 任务:如表 10 和表 11 所示,NER 是用于评估 SciLM 的最流行的任务。在 SciLM 用于评估其性能的前 20 个数据集中,有 11 个流行的 NER 数据集,我们使用其中五个来绘制图表。从表 16中,我们获得了在这五个 NER 数据集上进行评估的 SciLM 列表。随后,我们评估了以下 SciLM 的性能:BioBERT、GreenBioBERT、PubMedBERT、BioALBERT、Bio-LM、BioMedBERT、KeBioLM、SciFive、BioELECTRA、PubMedELECTRA、BioLinkBERT、BioReader、Bioformer 和 BIOptimus。为清楚起见,我们在图 5 中显示了所有五个数据集的平均性能(F1 分数)变化。五个数据集中每个数据集的性能变化在图 13中有详细说明。
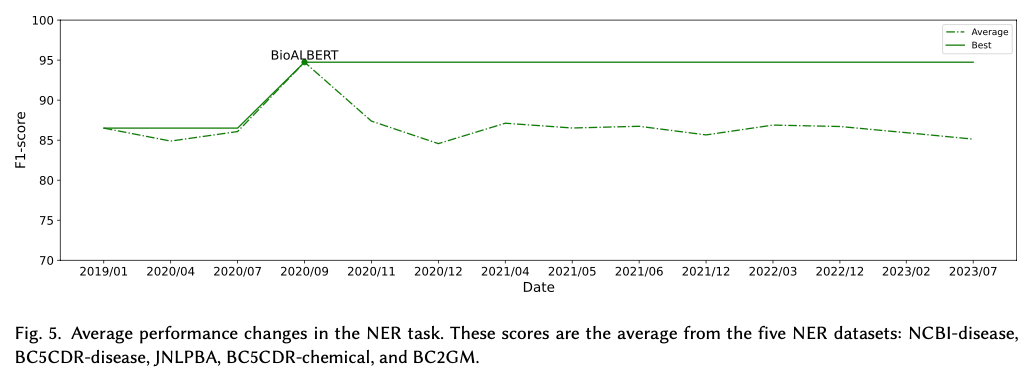
我们注意到五个数据集的平均性能变化呈现出一致的模式。2020 年 9 月,BioALBERT 获得了最高分,平均 F1 分数为 94.7。到目前为止,BioALBERT 在这些 NER 数据集上的表现仍然无法与任何提出的模型相提并论。我们的观察提出了两个与 NER 任务和数据集相关的主要研究问题。
第一个问题是:这是否意味着当前的 SciLM 已经解决了 NER 任务?
- 我们认为答案是否定的。根据图 13(附录 C.2)中的详细结果,我们观察到 BioALBERT 在 JNLPBA 数据集上的 F1 分数仅为 84.0。这表明其他数据集上的高分可能是由于 BioALBERT 的训练数据与这些 NER 数据集之间的过度拟合造成的。此外,进一步评估模型也会很有趣,例如评估它们在对抗集上的表现。
第二个问题是:为什么新提出的模型无法超越 BioALBERT 的性能?
- 我们认为造成这种情况的原因有很多,这里我们讨论我们认为最重要的两个原因:(1)后期的 SciLM 架构有所不同;他们可能会尝试其他架构,例如对 SciFive 使用 T5,对 BioELECTRA 使用 ELECTRA,对 PubMedELECTRA 使用 ELECTRA。(2)研究重点各不相同;后续研究可能会探索解决任务的其他方法,而不仅仅是追求最高性能。例如,Yasunaga 等人通过将文档之间的链接信息纳入训练数据集和损失提出了新型 LM。此外,Pavlova 和 Makhlouf通过使用课程学习计划进行预训练引入了 SciLM。
2.Classification Task:
分类任务:如表 10 所示,分类任务是第二受欢迎的任务。但是,分类任务有很多种类型,例如引用意图分类(例如 ACL-ARC)或公式主题分类(例如 TopicMath-100K)。这解释了为什么只有一个分类数据集(即 HOC)出现在用于评估 SciLM 的前 20 个最受欢迎的数据集中。HOC 表示“癌症特征”;HOC 数据集由 1,499 篇经专家注释的癌症相关 PubMed 摘要组成。它包括 10 个类别,每个类别对应一个癌症特征。这是一个多标签分类任务,我们注意到 F1 分数和微 F1 分数通常用于比较。我们观察到只有 BioLinkBERT 获得了这两个分数。因此,我们为两个 SciLM 列表创建了两个图表。 HOC 数据集的性能变化如图 6 所示。左侧使用 F1-score 进行评估,SciLM 列表如下:BlueBERT、ouBioBERT、BioALBERT、Bio-LM、SciFive、BioLinkBERT 和 BioReader。右侧使用 micro F1-score 进行评估,SciLM 列表如下:PubMedBERT、BioELECTRA、PubMedELECTRA、BioLinkBERT、BioGPT 和 clinicalT5。我们认为,当某些模型在一种指标上显示分数,而其他模型在另一种指标上显示分数时,很难得出任何可靠的结论。
3.RE任务:
RE 任务:第三个流行的任务是 RE。三个流行的 RE 数据集(ChemProt、DDI 和 GAD)出现在前 20 个数据集中。然而,在合并在这三个数据集上评估的模型列表后,数量相当少,只剩下 9 个模型。因此,我们只为前两个数据集 ChemProt 和 DDI 绘制了一个图表,其中 SciLM 列表如下:BlueBERT、ouBioBERT、BioALBERT、CharacterBERT、Bio-LM、KeBioLM、ELECTRAMed、SciFive、BioELECTRA、PubMedELECTRA、BioLinkBERT、BioReader 和 Bioformer。图 7 展示了这两个数据集的性能变化。与 NER 任务类似,BioALBERT 在 2020 年 9 月取得了 SOTA 结果。然而,对于 RE 任务,有一些提出的模型已经超过了 BioALBERT 的得分。具体来说,在 ChemProt 数据集上,SciFive 于 2021 年 5 月获得 SOTA,至今仍保持 SOTA 头衔。在 DDI 数据集上,BioReader 于 2022 年 12 月获得 SOTA,Bioformer 于 2023 年 2 月获得 SOTA。
4.QA任务:
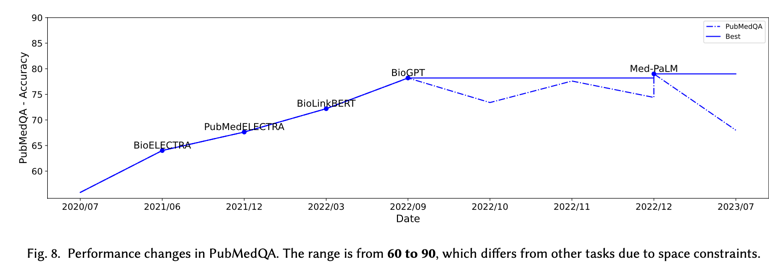
QA 任务:在前 20 个热门数据集中,只有两个 QA 数据集(PubMedQA 和 BioASQ)。但是,这两个数据集并不像其他数据集(例如 MedNLI 或 HOC)那么常见。很少有 SciLM 在 BioASQ 数据集上进行评估;因此,我们决定只为 PubMedQA 数据集绘制图表。图 8 展示了 PubMedQA 中的性能变化。我们观察到,SciLM 在 PubMedQA 上的性能随着时间的推移逐渐提高。BioELECTRA 的得分超过了 PubMedBERT(55.8),并取得了更好的性能(64.0)。随后,PubMedELECTRA 超过了 BioELECTRA 的得分,表现出更好的性能(67.6)。通过利用引文链接信息训练 SciLM,BioLinkBERT 的表现优于所有先前的模型,并在 2022 年 3 月获得了新的最佳分数 (72.2)。然而,这些模型中的大多数都缺乏生成能力。通过使用新一代生成模型 GPT,Luo 等人 [130] 提出了 BioGPT,并在 PubMedQA 数据集上取得了新的 SOTA 结果,达到 78.2。随后,又引入了几种提出的 SciLM,但它们的分数仍然低于 BioGPT 的分数。最近,Singhal 等人 通过在 Flan-PaLM 模型上执行指令提示调整引入了 Med-PaLM。然而,这里的改进小于从 BioLinkBERT 到 BioGPT 的改进。
5.NLI任务:
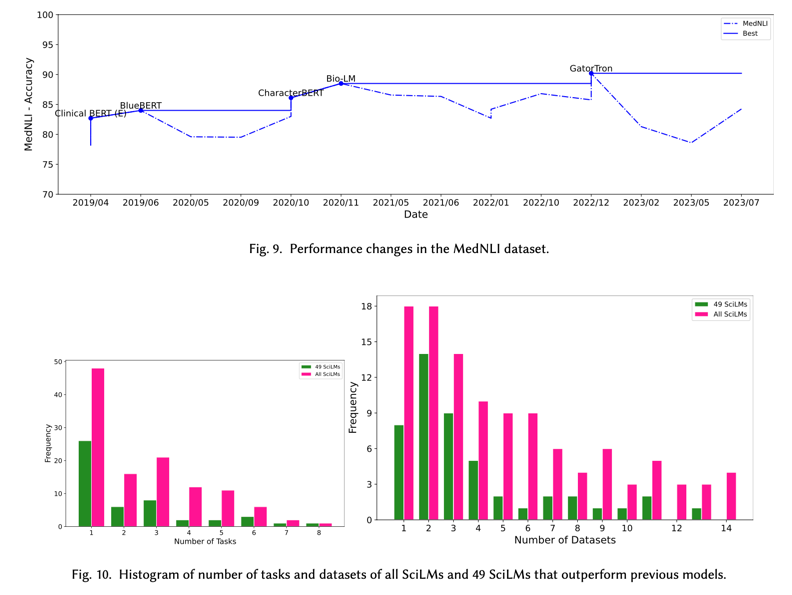
NLI 任务:最后一个流行的任务是 NLI。直到最近 Jullien 等人引入 NLI4CT 数据集之前,MedNLI 一直是专注于处理英语科学文本的 NLI 任务的唯一数据集。此外,还有其他针对不同语言的 NLI 数据集,例如针对越南语的 ViMedNLI。从 2019 年 4 月至今,许多模型都对 MedNLI 进行了评估。图 9 显示了 MedNLI 数据集中的性能变化。如图所示,2019 年 4 月,Clinical BERT (Emily) 在 MedNLI 数据集上获得了 82.7 的 SOTA 分数。随后,在 2019 年 6 月,BlueBERT 超越了 Clinical BERT (Emily) 的得分,并获得了 84.0 的新 SOTA。CharacterBERT 超越了 BlueBERT 的得分,并于 2020 年 11 月获得了 SOTA(86.1)。一个月后,Bio-LM 以 88.5 分创下新的 SOTA。最近,GatorTron 超越了 Bio-LM,以 90.2 分创下新的 SOTA。
4.2.2. Number of Models Outperform Previous Models or Achieve SOTA Results
许多模型的表现优于之前的模型或达到 SOTA 结果:
分别精确获取所有不同数据集上 SOTA 的 SciLM 数量非常困难且耗时。在每篇拟议的 SciLM 论文中,作者经常会提到他们的模型是否达到了 SOTA 结果或是否优于之前的模型。因此,我们利用这些信息进行分析。如果 SciLM 优于之前的模型或达到了 SOTA 结果,我们会在附录 C.1 中表 16 中每个模型的“数据集”列末尾添加突出显示词 (全部)。总结一下,在 117 个 SciLM 列表中,有 49 个 SciLM 优于之前的模型或达到了 SOTA 结果。然而,仅凭这个数字并不能全面了解 SciLM 的有效性。在某些情况下,SciLM 仅对一个数据集或一项任务进行评估,这使得比较不公平。为了有效地表示这个数字,我们进行了统计分析:
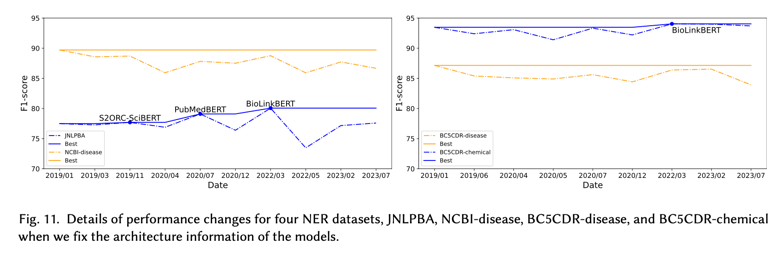
计算这 49 个 SciLM 在评估中使用了多少数据集和任务。图 10 显示了这 49 个 SciLM(绿色柱)的任务数量(左)和数据集数量(右)的直方图。如图所示,许多 SciLM 仅对一项任务(49 个 SciLM 中的 26 个)或少数数据集(49 个中的 8 个在一个数据集上,49 个中的 14 个在两个数据集上)进行了评估。这些数字提出了两个主要问题:(1)所提模型的泛化能力仍不清楚;(2)比较所提模型的性能可能没有意义。对于第一个问题,如果仅在一项任务上评估模型,则表明模型在其他任务上的能力尚未得到充分评估。对于第二个问题,如果在两三个数据集上进行比较,并且它非常特定于领域,那么即使模型获得了 SOTA 分数或优于以前的模型,在这种情况下也很难得出任何可靠的结论。
受上述观察的启发,为了更好地了解已发现问题的严重性,我们还为 117 个 SciLM 的完整列表中的任务和数据集数量创建了直方图。这些直方图是图 10 中的粉色柱状图。如图所示,许多 SciLM 在有限数量的任务和数据集上评估了他们的模型。这引发了人们对对这些 SciLM 进行的评估的可靠性的担忧,这将在第 5.2.1 节中讨论。
4.3.Variations in BERT-based Models Performance Across Tasks
基于 BERT 的模型在不同任务中的表现差异:
在本节中,我们将广泛探讨固定模型架构的性能随时间的变化。
1.NER 任务:
NER 任务。从第 4.2.1 节中的 SciLM 列表中,我们选择了使用 BERT 架构的模型子集。我们发现这些模型中只有七个评估了它们在 BC2GM 上的性能。因此,在本部分中,我们仅针对四个 NER 数据集绘制了图表:JNLPBA、NCBI-disease、BC5CDR-disease 和 BC5CDR-chemical。JNLPBA 和 NCBI-disease 数据集的 SciLM 列表为:BioBERT、SciBERT、S2ORC-SciBERT、GreenBioBERT、PubMedBERT、BioMedBERT、BioLinkBERT、ScholarBERT、Bioformer 和 BIOptimus。 BC5CDR-disease 和 BC5CDR-chemical 数据集的 SciLM 列表为:BioBERT、BlueBERT、GreenBioBERT、ouBioBERT、PubMedBERT、BioMedBERT、BioLinkBERT、Bioformer 和 BIOptimus。
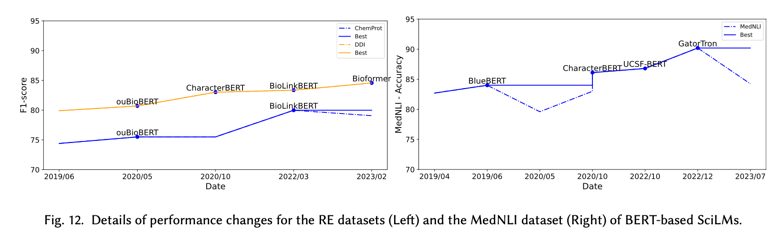
图 11 详细说明了具有固定模型架构的 JNLPBA、NCBI-disease、BC5CDR-disease 和 BC5CDR-chemical NER 数据集的性能变化。对于 NCBI-disease 和 BC5CDR-disease 数据集(橙色线),我们观察到没有任何提出的模型能够超越 2019 年 1 月推出的 BioBERT 的性能。对于 BC5CDR-chemical 数据集,2022 年 3 月提出的 BioLinkBERT 可以提高 BioBERT 的性能,但改进幅度很小。对于 JNLPBA 数据集,我们观察到性能变化随着时间的推移缓慢但稳定地发展。具体来说,2019 年 11 月提出的 S2ORC-SciBERT 略微提升了 BioBERT 的性能(从 77.5 提高到 77.7)。随后,2020 年 7 月推出的 PubMedBERT 大幅超越 S2ORC-SciBERT,从 77.7 提升至 79.1。2022 年 3 月,BioLinkBERT 的表现优于所有之前基于 BERT 的模型,与仅基于 BERT 的模型相比,F1 得分为 80.1,获得了迄今为止的最佳成绩。
2.分类任务:
分类任务。我们观察到只有三个基于 BERT 的模型(BlueBERT、ouBioBERT 和 Bi- oLinkBERT)使用 F1 分数,而有两个基于 BERT 的模型(PubMedBERT 和 BioLinkBERT)使用微 F1 分数进行评估。因此,我们决定不为 HOC 数据集绘制图表。在模型性能方面,从BlueBERT(87.3 F1分数)到BioLinkBERT(88.1 F1分数)有所提升。
3.QA任务:
QA 任务。与分类任务类似,PubMedQA 数据集也只有三个基于 BERT 的模型(PubMedBERT、BioLinkBERT 和 KEBLM)。因此,我们没有为其绘制图表。我们观察到从 PubMedBERT(55.8% 准确率)到 BioLinkBERT(72.2% 准确率)的改进,但 KEBLM 的性能下降,准确率仅为 68.0%。主要原因可能是 KEBLM 专注于提出可以整合多种知识类型的信息的模型,而不是仅仅依赖于非结构化文本。
4.RE任务:
RE 任务。从第 4.2.1 节中的 SciLM 列表中,我们仅保留使用 BERT 架构的模型。这样产生了五个 SciLM:BlueBERT、ouBioBERT、CharacterBERT、BioLinkBERT 和 Bioformer。图 12(左)说明了 DDI 和 ChemProt 数据集的性能变化。我们观察到 RE 任务在过去四年中性能逐渐提高。具体来说,对于 DDI 数据集,BioBERT 首先优于 BlueBERT,然后 CharacterBERT 超越 BioBERT。此后,BioLinkBERT 和 Bioformer 也表现出比之前的 SciLM 更好的性能。**ChemProt 显示出与 DDI 数据集非常相似的模式。但是,CharacterBERT 和 ouBioBERT 的性能相似(75.5 F1 分数),并且 Bioformer 在 ChemProt 数据集上的表现并不优于 BioLinkBERT。
5.NLI任务:
NLI 任务。与之前的任务类似,我们仅保留使用 BERT 架构的模型。这产生了八个 SciLM:Clinical BERT (Emily)、BlueBERT、ouBioBERT、UmlsBERT、CharacterBERT、UCSF-BERT、GatorTron 和 KEBLM。图 12(右)说明了 MedNLI 数据集的性能变化。我们观察到从 2019 年 4 月到 2022 年 12 月,MedNLI 数据集的性能明显提高。BlueBERT 超越了 Clinical BERT (Emily),其次是 CharacterBERT 比所有之前的 SciLM 都有所提高。随后,UCSF-BERT 和 GatorTron 也比所有之前的 SciLM 有所改进。目前,GatorTron 是 MedNLI 数据集的最佳 BERT 架构模型。
5. Current Challenges and Future Directions
5.1.Foundation SciLMs
5.1.1. SciLMs for non-English Language
非英语的科学语言模型:
近年来,非英语语言的多语言和单语言模型研究受到了广泛关注。此类 LM 试图解决非英语语言在解决 NLP 任务方面的局限性。其他语言的单语言 PLM 的开发也出现了大幅增长。这种演变提高了 PLM 在各种下游任务中的表现,例如英语以外的语言的分类、摘要和机器阅读理解。因此,许多基准数据集和评估都是用资源匮乏的语言执行的,并使 NLP 研究界受益匪浅。
对于科学文本,大多数文档都是用英语编写的;因此,SciLM 最初设计用于仅处理英文文本。很少有人尝试研究多语言 SciLM 在提交给 ACM 语言的其他稿件中的表现。表 7 总结了当前不同语言的 SciLM。我们发现,除英语外,还有九种语言已经预训练了 SciLM。其中,中文是使用最多的语言;因此,它受到了研究人员的广泛关注。法语、日语和西班牙语也是 SciLM 评估的热门语言。其他语言研究的缺乏可能是由于缺乏大规模科学数据集。一种可能的解释是,大多数研究文章和科学报告都是用英语撰写的,因此收集和创建非英语语言的数据集是一项耗时的任务。机器翻译模型的发展正在迅速推进,并且可以集成到未来的 SciLM 中。然而,据我们所知,资源匮乏的语言的模型无法捕捉科学短语和学术写作风格;因此,对多语言或非英语 SciLM 进行更多研究至关重要。
5.1.2. SciLMs for non-Biomedical Domain
非生物医学领域语言模型:
科学语言模型的范围超出了生物医学领域,涵盖了各种科学学科。在化学领域,有 13 个专门的科学语言模型,主要基于 BERT 架构。调查范围扩展到气候、计算机科学、网络安全、地球科学、制造业、数学、蛋白质、科学教育和社会科学等不太常见的领域。在多领域类别中,SciBERT、S2ORC-SciBERT、OAG-BERT、ScholarBERT、AcademicRoBERTa 和 VarMAE 等模型旨在处理不同的领域。尽管取得了进展,但科学领域之间的科学语言模型代表性仍然存在显著差距。虽然生物医学领域有 85 个已确定的模型,但其他领域通常只有一两个专用模型,这导致人们担心其通用性有限、忽视特定领域的细微差别以及阻碍特定领域的应用。生物医学 SciLM 的主导地位引发了人们对其在不同科学学科中的普遍性的质疑,可能缺乏对其他领域准确表达的背景理解。
为了应对这些挑战,策略包括鼓励特定领域的研究合作、开放获取专业数据集、结合迁移学习技术以及建立共享评估基准。NLP 研究人员和领域专家之间的合作可以促进针对特定科学领域的 SciLM 的发展。开放获取专业数据集和利用迁移学习技术可以适应特定领域,即使数据有限。共享基准可以激励研究人员,鼓励他们为各个领域的 SciLM 发展做出贡献,并推动科学学科的研究。
5.1.3. Integrating Knowledge into SciLMs
将知识融入科学语言模型:
将外部知识(特别是知识库 (KB))集成到 SciLM 中的探索填补了现有文献中的一个重要空白。知识库在增强 LM 在科学领域的能力方面发挥着关键作用,提供结构化信息检索、领域特定精度、上下文丰富、知情推理和任务绩效改进。知识库针对科学学科量身定制,提供全面的知识覆盖范围,丰富 LM 的背景。
表 12 总结了关键模型,例如 UmlsBERT、ProteinBERT、DRAGON、KeBioLM、CODER 和 SapBERT,每个模型都针对特定领域和预训练任务量身定制。集成过程涉及的方法分为关键方法,例如将知识集成到训练目标中以及将知识集成到 LM 输入中。UmlsBERT、KeBioLM、CODER 和 DRAGON 代表了前者,在预训练期间将知识直接嵌入到学习过程中。另一方面,ProteinBERT 与后者更加一致,将外部知识(例如基因本体注释)整合到 LM 输入中以增强上下文和语义。
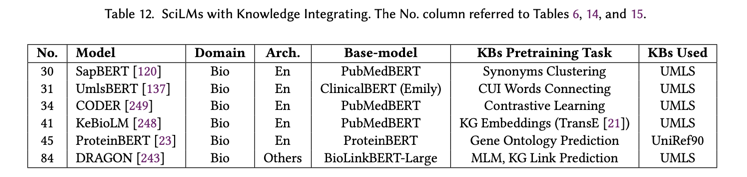
知识集成的挑战包括知识噪声、领域不匹配、可解释性和覆盖率问题。知识噪声是指知识库中不相关或嘈杂的信息所带来的挑战,包括过时或不正确的数据、含糊不清的术语和不相关的概念,这些挑战会严重影响 SciLM 的精度,对准确性和精度至关重要的科学领域构成特殊挑战。领域不匹配解决了知识库语言和科学文本细微差别之间的差异,需要导航才能有效整合。可解释性涉及在整合后保持决策的透明度,这对于验证可靠性至关重要。覆盖率问题源于知识库的规模有限,需要制定策略来处理知识缺口,以便做出准确的预测。成功克服这些挑战对于提高 SciLM 处理科学文本的效率至关重要,从而获得可靠和精确的结果。
5.1.4. Build Large SciLMs
构建科学大语言模型:
如图 4 所示,大多数现有 SciLM 的参数都少于 1B(即 BERT 级别)。原因之一是基于 BERT 的 SciLM 在预算有限的各种下游任务中表现相对较好。另一个原因是构建更大的 SciLM 需要更多的计算资源和数据。Galactica 是首次尝试将 SciLM 扩展到 100B+ 参数。然而,与 BERT 类模型相比,训练如此大的模型需要大量的数据和计算资源。
SciBERT 使用具有 8 个核心的单个 TPU v3(类似于 2 个 A100 GPU)进行预训练,而 Taylor 等人使用 128 个 A100 GPU 来预训练他们的 Galactica-120B。因此,如今,寻找有效的预训练 SciLM 解决方案是一个巨大的挑战,尤其是对于在大学工作的研究人员而言。
自从出现了高质量的开源 LLM以来,一些研究人员非常重视使用这些 LLM 进行包含额外科学文本的持续预训练,从而减少了收集大规模科学语料库的需要,并减少了从头开始训练 SciLM 时对大量计算资源的需求。因此,有效的持续预训练是构建大型 SciLM 的一个有前途的方向。Meditron包含了 Llama-2使用的一小部分原始预训练语料,以避免在对医学领域的数据进行持续预训练时出现遗忘。已经进行了一些尝试来指导通用领域的持续预训练,然而,专门为科学领域设计的实用方法仍然很少。
Beltagy 等人发现,从头开始训练 SciLM 可以从为科学领域设计特定领域的标记器中受益,从而实现更好的性能。与其他语言相比,已经有大量用于预训练 SciLM 的英文科学文本。但是,如果我们想从头开始训练大型 SciLM(即具有超过 100B 个参数),现有数据的规模可能不够。具体来说,SciBERT 在预训练期间仅使用了 3.17B 个tokens,而 Galactica 通过在大约四个时期内重复 106B 个tokens总共消耗了 450B 个tokens,这比训练类似 BERT 的模型多 140 倍。根据 Chinchilla Scaling Laws,具有 63B 参数的 LLM 需要 1.4T 个 token 进行预训练,使用去重文本进行预训练的语言模型具有更好的泛化能力,而 The Pile [59] 中的科学文本包含的 token(96B)比推荐数量少得多。因此,如何收集足够的科学文本来预训练大型 SciLM 仍然是当今的挑战。
5.1.5. Multi-modal SciLMs
近年来,能够处理语言和非语言信息(如图像、音频和视频)的 LM 受到了广泛关注。值得注意的是,视觉和语言模型字幕 和根据文本指令生成图像。最近,随着 GPT-4 等 LLM 的成功部署,许多研究都强调训练适配器,这些适配器可以将非语言信息转换为在与语言相同的嵌入空间中处理 [44, 262]。预计此类架构将处理非语言数据,同时保留 LLM 广泛的问题解决能力。
在科学领域,多模态模型的出现也势头强劲。可以通过在一般领域对单模态或多模态 PLM 进行额外训练来构建多模态 SciLM,从而利用一般领域模型的稳健性能。然而,仍有一些挑战需要克服。例如,与一般领域相比,科学领域可用的数据较少,这使得对多模态 SciLM 进行充分训练或微调变得困难。此外,在科学领域,预计模型将处理两种以上的模态。通常,科学论文包含许多不同类型的信息,例如表格、方程式、图形和代码。因此,将它们多模态集成到 SciLM 中应被视为向前迈出的关键一步。此外,包含 CT、MRI 和超声波等广泛数据的生物医学 SciLM 是理想的。然而,处理三种以上模态的研究相对较少。
应对这些挑战需要制定策略来增加可用的训练数据量,包括 PDF 和 LaTeX 文件。应鼓励探索整合外部知识的数据增强技术和学习方法。此外,最近 LLM 的激增也意味着需要在科学领域开发基于公开可用的 LLM(例如 Llama 2)的多模态 SciLM。建立这样的模型将使我们更接近充分发挥多模态模型在学术研究中的巨大潜力。
5.2.Evaluating the Effectiveness, Efficiency, and Trustworthiness of SciLMs
5.2.1. Issues with Evaluation and Comparison
评估和比较的问题:
如第 4.2.2 节所述,许多 SciLM 在有限数量的任务和数据集上评估其模型。这引发了与评估和比较相关的问题。首先,关于评估,当提出的 SciLM 仅在一个或几个任务上评估其模型时,这意味着他们的模型没有经过全面测试,并且其性能可能仅对某些任务有效,而在其他任务上表现不佳。这可以通过以下事实来解释:大多数现有的 SciLM 都基于基于编码器的架构,例如 BERT,而不是像 T5这样的文本到文本模型。因此,他们的模型不易适应各种 NLP 任务的评估。关于第二个比较问题,如果我们仅在一个或几个数据集上比较不同的 SciLM,那么得出任何可靠的结论都具有挑战性。
增强不同模型评估和比较的一个有希望的方向是创建一个包含各种任务和数据集的基准。在通用领域,GLUE 和 SuperGLUE被引入作为标准化基准进行对比。受此启发,在生物医学领域,Peng 等人和 Gu 等人 分别引入了 BLUE 和 BLURB 基准。BLUE 基准包含五个不同的任务,这些任务中有十个数据集,而 BLURB 基准包含六个不同的任务,这些任务中有十三个数据集。然而,我们观察到,目前在我们列出的 117 个 SciLM 中,只有少数 SciLM 对这些基准进行了评估(对于 BLUE,模型为:BlueBERT、ouBioBERT、BioALBERT 和 BioELECTRA;对于 BLURB,模型为:PubMedBERT、BioELECTRA、PubMedELECTRA 和 BioLinkBERT)。可能是因为这些基准中的许多数据集已经获得了高分,研究人员可能不太愿意对它们进行评估。然而,我们相信,创建具有多样化任务和数据集的基准是未来研究的一个有前途的方向,可以实现公平可靠的比较。我们鼓励未来的研究人员开发具有更多任务和数据集的基准,甚至跨不同领域。
5.2.2. Move Beyond Simple Tasks
超越简单的任务:
如表 10 和表 11 所示,大多数现有的 SciLM 都专注于评估 NLP 中的简单任务,例如 NER 和 RE。在用于评估 SciLM 的 20 个热门数据集中,有 11 个 NER 数据集,但只有一个 NLI 数据集和两个 QA 数据集。众所周知,NER 和 RE 是 NLP 中的基本任务,而 NLI 和 QA 则强调语言理解,测试模型更广泛的理解能力。然而,这两个任务的数据集并不常用。
针对当前的问题,我们建议未来的 SciLM 工作应将重点转移到评估 NLP 中更复杂的理解任务,例如 NLI 和 QA。为此,第一步是创建专门为 NLI 和 QA 任务设计的额外数据集,作为 SciLM 之间进行有意义比较的基准。从一般领域中学习,我们可以采取一些方向。例如,对于问答任务,我们可以提出用于测试不同技能的数据集,例如基于多个文档的推理和对话式问答。就 NLI 任务而言,过去几年只有一个专用于英文科学文本的数据集:MedNLI 数据集。最近,Jullien 等人 [89] 引入了一个用于临床试验报告的 NLI4CT 数据集。该数据集的一个显著特点是,它是第一个用于处理科学文本的 NLI 任务的带有解释的数据集。然而,数据集的大小相当小,只有 2,400 个实例。我们相信,引入更多规模更大、包含对抗样本的 NLI 数据集将有助于评估 SciLM。
5.2.3. Reliable SciLMs
除了评估和比较问题外,我们还需要关注其他三个方面——稳健性、泛化和解释性——以获得更可靠的 SciLM。在稳健性方面,我们观察到,没有多少 SciLM 接受过各种对抗性测试的评估。正如在一般领域任务中所见,许多模型在原始数据集上表现出色,但在这些数据集的对抗性版本上性能显著下降 [83, 84, 170]。因此,为了确保稳健性,在模型开发期间对 SciLM 进行对抗性测试至关重要。
对于第二个方面,泛化,我们也观察到与稳健性类似的情况,没有多少提出的 SciLM 考虑测试其模型的泛化能力。值得注意的是,有多种方法可以定义模型的泛化能力。在本研究中,我们简化了定义,仅考虑在同一任务中从一个数据集推广到另一个数据集的能力,无论是在同一领域还是不同领域。关于泛化能力的另一个担忧是缺乏可用于跨任务测试模型的数据集。例如,在 NLI 任务中,只有一个数据集 MedNLI 可用(幸运的是,最近 Jullien 等人 [89] 引入了一个 NLI4CT 数据集)。因此,研究人员无法测试其模型的泛化能力——例如,在一个数据集上进行训练,在另一个数据集上进行评估。我们建议未来的研究重点是评估训练集中具有不同分布的多个数据集上的模型。通过这样做,我们可以更清楚地了解模型的泛化能力。
对于第三个方面,我们还观察到缺乏对 SciLM 的研究,这些研究强调了解释方面。在 NLP 领域,解释被认为是“为什么 [输入] 被分配 [标签]”的原因,它们对于确保模型的可靠性至关重要。然而,这一点在科学领域并没有得到很好的讨论和强调。例如,据我们所知,目前科学领域只有四个数据集包含解释信息——PubMedQA [87](长答案可视为解释)、SciFact、QASPER 和 NLI4CT 。我们认为,为了增强 SciLM 的解释能力,应该提出更多专门用于解释的数据集,用于评估和分析模型的能力。
6 CONCLUSION
我们调查了现有的用于处理科学文本的 LM。具体来说,我们审查了 117 个跨不同科学领域、语言和架构的 SciLM。我们对这些 SciLM 进行了广泛的分析,强调了以前的研究普遍偏向生物医学领域和基于 BERT 的编码器,以及非英语 SciLM 的兴起。我们还对 SciLM 在常用任务和数据集上的当前 SOTA 性能及其近年来的发展提供了新的见解。最后,我们讨论了挑战并展示了两个潜在的方向。第一个方向是建立基础 SciLM,为此我们提供了提高其性能的实用建议,例如集成知识库、开发更大的模型或利用科学论文中存在的多模态内容。此外,我们还提出了针对低资源语言的 SciLM 开发的可行建议,这些建议不仅限于英语和生物医学领域。第二个方向是改进 SciLM 的评估,我们建议纳入更广泛的任务、数据集和更具挑战性的评估标准。我们还强调迫切需要在各个领域和任务之间建立标准化基准,以确保对所提出的 SciLM 进行公平可靠的比较。



















 1822
1822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









