







相关资料
论文:Remote Sensing Vision-Language Foundation Models without Annotations via Ground Remote Alignment
项目地址:GRAFT
摘要
我们介绍了一种无需使用任何文本注释即可训练遥感图像的视觉-语言模型的方法。我们的关键见解是使用地面上的互联网图像作为中介,连接遥感图像和语言。具体来说,我们训练了一个遥感图像的图像编码器,使其与CLIP的图像编码器对齐,使用大量配对的互联网和卫星图像。我们的无监督方法使得首次能够以两种不同的分辨率训练用于遥感图像的大规模视觉语言模型(VLM)。我们展示了这些VLM能够使卫星图像进行零样本、开放词汇表的图像分类、检索、分割和视觉问答。在每项任务中,我们无需文本注释训练的VLM都优于现有使用监督训练的VLM,分类上提高了20%,分割上提高了80%。我们的代码、数据和其他资源可在 https://graft.cs.cornell.edu 获取。
引言
我们的关键见解是利用地面上的互联网图像作为文本和卫星图像之间的中介。卫星图像捕捉了地球上某个特定位置的状况。同样的位置也可以通过人类在地面上的相机捕捉。通过利用与地面图像相关的地理标签(geotags),我们可以轻松地将卫星图像与它们联系起来,创建一个大规模的地面-卫星图像对数据集。结合CLIP的预训练互联网图像编码器,我们使用这些数据训练一个vision transformer,该vision transformer可以将卫星图像映射到CLIP编码器的特征空间。我们对这些对使用对比损失进行训练。由于这个特征空间也是CLIP文本编码器共享的,卫星编码器允许对卫星图像进行图像级文本理解,完全绕过了训练遥感VLM所需的文本注释的需求(见图1)。
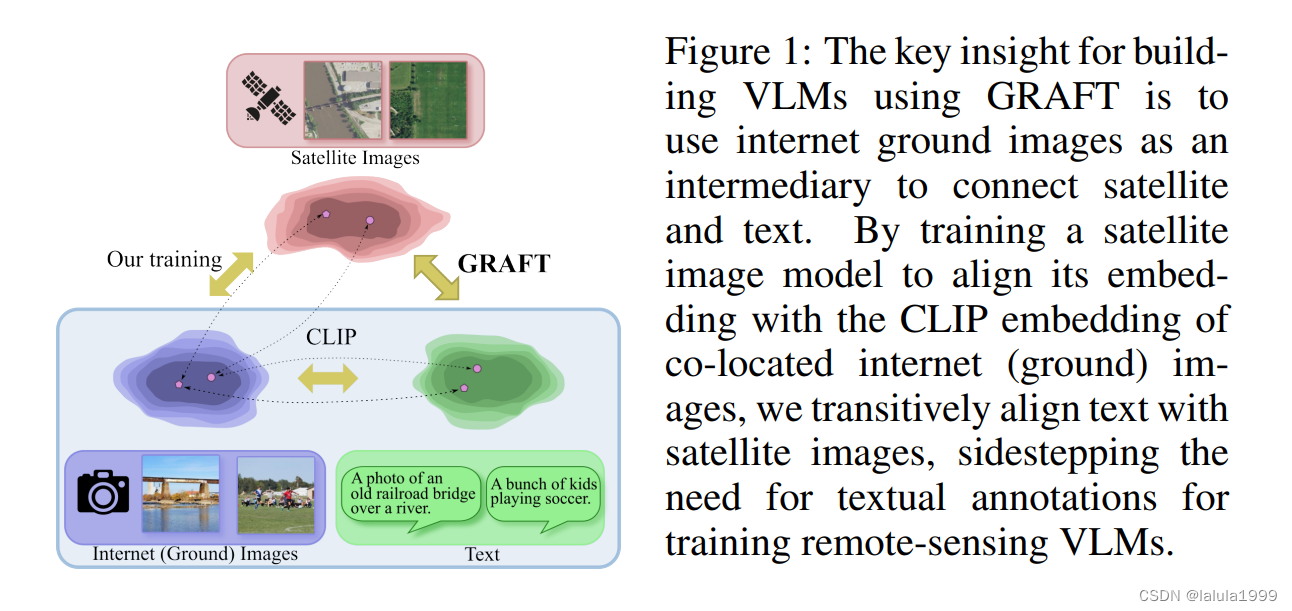
考虑到卫星图像能够捕捉比地面图像更大的物理空间(例如,地面图像只能捕捉到湖泊的一部分,而卫星图像可以捕捉到整个湖泊),我们进一步开发了一个基于文本到补丁检索的模型,使用我们的地面-卫星图像对。具体来说,利用与地面图像相关的地理标签,我们可以识别出地面图像在卫星图像上被捕获的像素位置。然后,我们构建了一个vision transformer,它可以输出与地面图像的CLIP表示对齐的补丁表示。这个模型不仅允许分类,还允许定位:我们展示了如何使用这个表示来识别与特定文本查询相关的补丁,或者通过利用如SAM这样的基础分割模型来执行文本到图像分割。
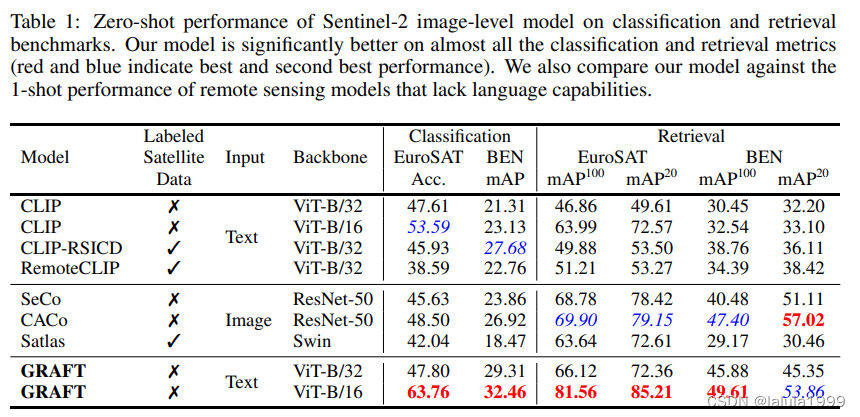
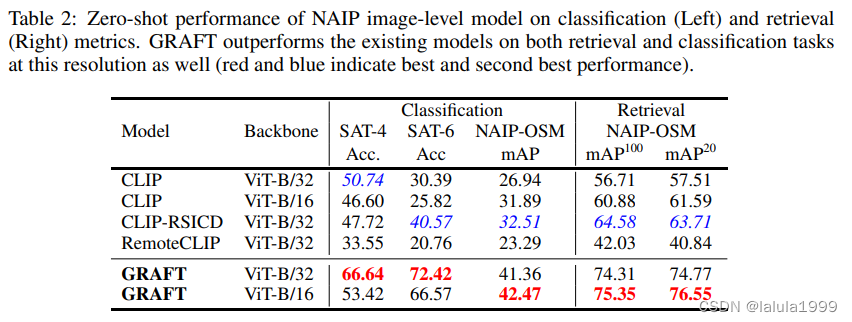
GRAFT可以在零样本的情况下执行分类、检索、语义分割(结合SAM)和视觉问答(VQA)(结合如ViperGPT等工具),所有这些任务都是在零样本的情况下完成的。我们在这些任务上广泛评估了我们的VLM,并展示了在各种文本到图像检索(比基线提高高达20%的相对改进)和文本到分割基准测试(比基线提高超过80%的相对改进)上的最先进的零样本性能。我们的贡献总结如下:
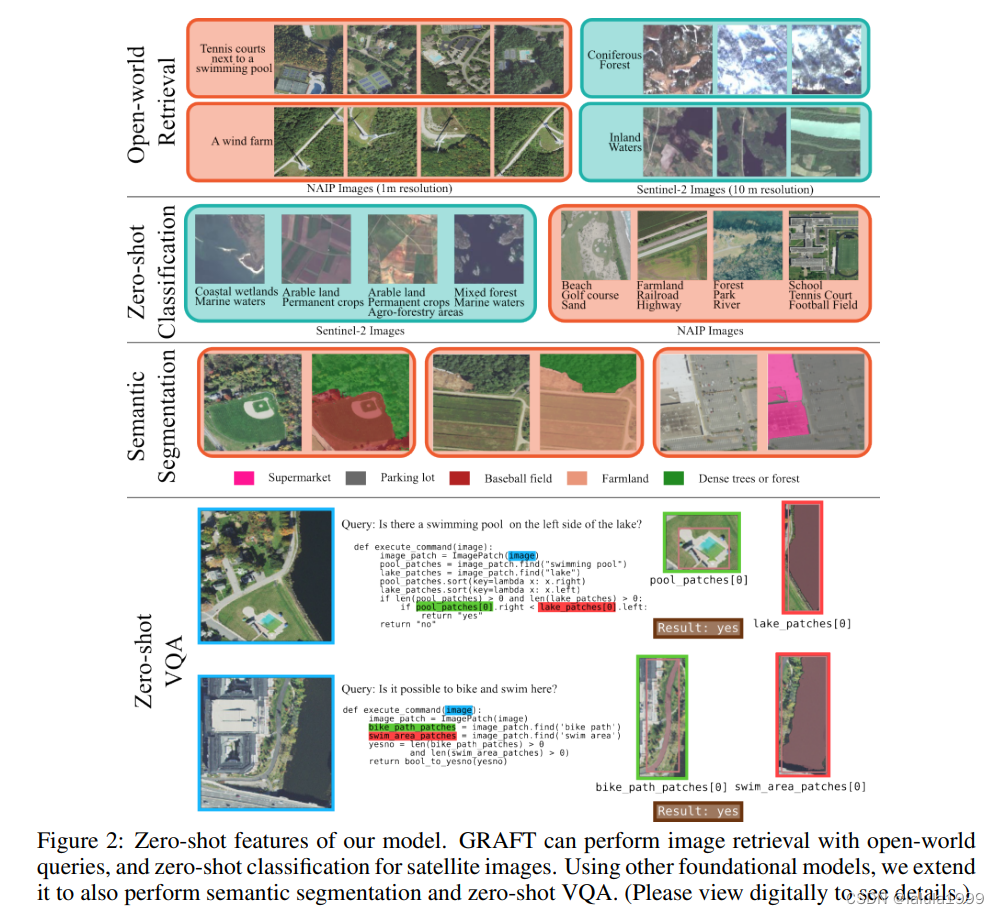
- 我们介绍了GRAFT,它能够无需任何文本注释来训练遥感VLM。
- 利用GRAFT,我们收集了两个不同分辨率(NAIP为1米,Sentinel-2为10米)的遥感图像的两百万像素级数据集。
- 利用GRAFT和我们的数据集,我们开发了基础的视觉语言模型,用于理解卫星图像中的开放世界概念,这些模型在不同分辨率下都能理解,并在各种图像级和像素级理解任务上显著优于先前的工作。
- 我们通过将我们的VLM与ViperGPT框架扩展,提出了解决卫星图像零样本VQA问题的方案。
方法
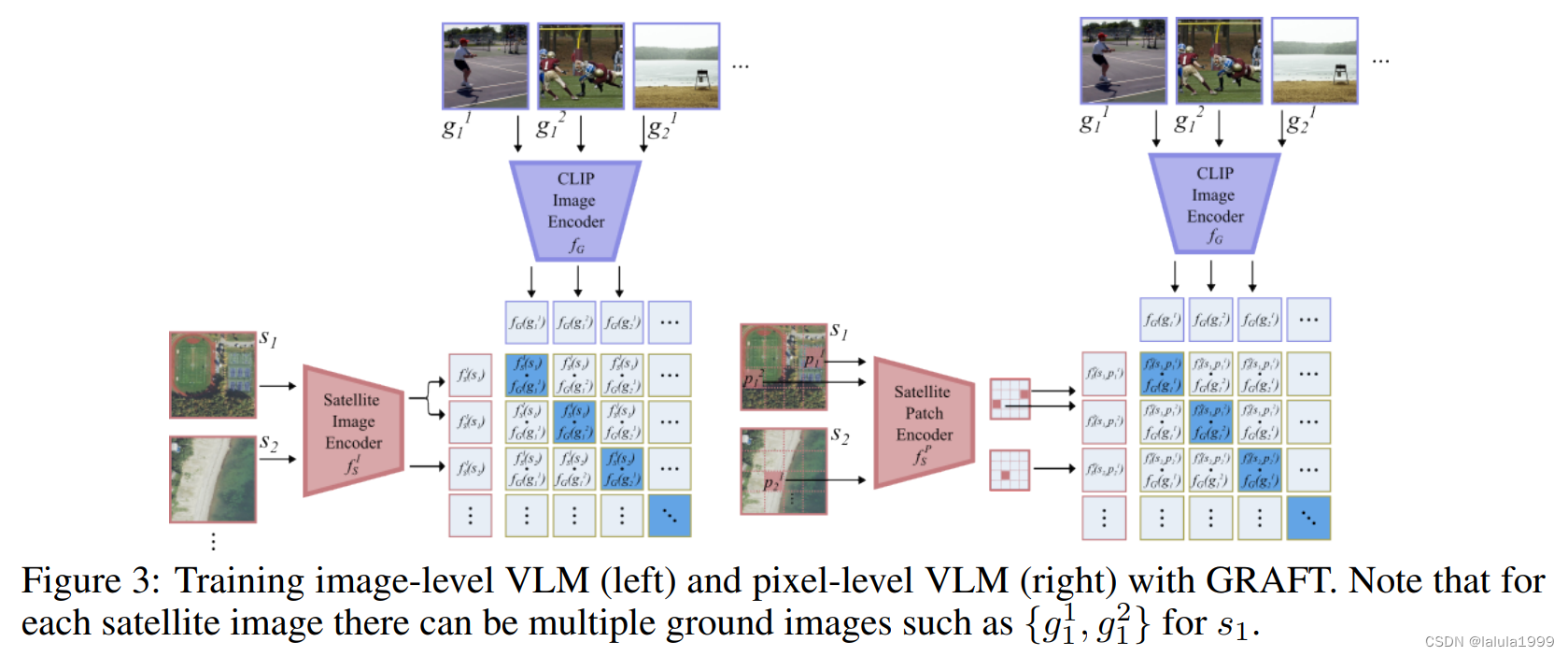
我们构建了两种类型的VLMs,它们在不同的理解层面上运作:图像级和像素级。图像级模型可用于执行需要将卫星图像作为一个整体理解的任务,例如文本到图像的检索和零样本图像分类;像素级模型则在需要精确定位时使用,例如零样本分割和视觉问答(对于测量某些特征区域的面积等问题)。
图像级VLMs
我们希望构建一个图像级特征提取器
f
S
I
f^I_S
fSI,将卫星图像映射到
(
f
G
,
f
T
)
(f_G, f_T)
(fG,fT)的相同表示空间。我们可以使用像CLIP一样的对比损失,将卫星图像和地面图像的对应对拉近,并将负样本推开。然而,原始的对比学习设置假设一个模态(卫星图像)中的数据点映射到另一个模态(互联网图像)中的一个单一点。不幸的是,卫星图像捕捉的区域更大,并且与它们关联的是多个地面图像。因此需要一个新的公式。
我们假设卫星图像的嵌入应该与在该区域内拍摄的所有地面图像接近,并且与其它卫星图像的地面图像远离。具体来说,对于一个数据批次
B
=
{
s
i
,
{
g
i
j
}
j
=
1
N
i
}
i
=
1
N
B
B = \{s_i, \{g^j_i\}^{N_i}_{j=1}\}^{N^B}_{i=1}
B={si,{gij}j=1Ni}i=1NB(其中
s
i
,
i
=
1
,
.
.
.
,
N
B
s_i, i = 1, ..., N_B
si,i=1,...,NB是卫星图像,
g
i
j
,
j
=
1
,
.
.
.
,
N
i
g^j_i, j = 1, ..., N_i
gij,j=1,...,Ni是
s
i
s_i
si捕获的地理区域内拍摄的
N
i
N_i
Ni个地面图像)。我们使用以下损失函数捕捉我们的直觉:
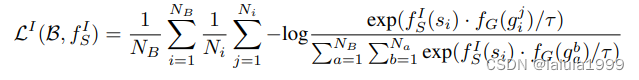
像素级VLMs
许多卫星图像理解任务,如分割,需要像素级的定位。为了实现像素级的理解,我们转向之前部分中忽略的另一个信息源:地面图像 g j i g^i_j gji拍摄的精确地理位置,这可以映射到卫星图像 s i s_i si中的像素位置 p j i p^i_j pji。
为了利用这个信号,我们假设了一个网络架构
f
S
P
f^P_S
fSP,它可以为卫星图像s中的每个像素
p
p
p产生一个特征向量
f
S
P
(
s
)
[
p
]
f^P_S(s)[p]
fSP(s)[p]。我们使用ViT实现
f
S
P
f^P_S
fSP,为卫星图像的非重叠补丁产生特征向量。然后,
f
S
P
(
s
)
[
p
]
f^P_S(s)[p]
fSP(s)[p]就是包含像素p的补丁的输出特征向量。我们使用类似的损失函数来训练这个特征提取器:
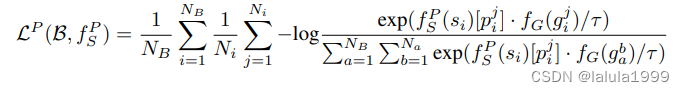
收集地面-卫星图像对

为了进行训练,我们需要一个地面-卫星图像对的数据集。我们为两种不同类型的遥感图像收集了这样的数据集:NAIP(美国地质调查局,2022年)(高分辨率,每像素1米)和Sentinel-2(Drusch等人,2012年)(低分辨率,每10米1像素)。我们下面描述我们的数据收集过程。
-
地面图像:我们从Flickr收集地面图像。为了获得来自多样化地区(而不仅仅是人口密集的地方)的代表性图像,我们均匀选择地点,并采样具有精确地理标签(街道级精度)的非重复图像。我们使用室内-室外分类器(在SUN397(Xiao等人,2010)上训练的ResNet18)去除室内图像。虽然我们发现使用“全部”和“室外”图像之间没有明显的区别,但我们为了实验的便利性进行了过滤。
-
卫星图像:我们以地面图像的地理标签为中心采样卫星图像。所有地理标签落在这个卫星图像中的地面图像都被分配给它。此外,我们不使用已经被分配的地面图像来采样卫星图像。因此,我们避免了卫星图像之间的高度重叠(至少相隔112像素)。
除了地面和卫星图像之间的地点一致性外,我们还将时间一致性融入到Sentinel-2数据中。具体来说,我们收集了互联网图像所在地点的时间上最接近的图像(包含<1%的云)。我们无法为NAIP这样做,因为NAIP的重访时间要长得多(每2年一次,而Sentinel-2每5天一次)。
用基础模型增强GRAFT VLMs
-
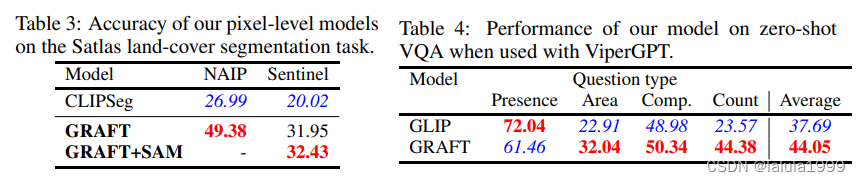
零样本图像分割。虽然像素级模型已经可以用于执行分割,但我们可以利用像SAM(Kirillov等人,2023)这样的自底向上分割模型来提高其性能。为了增强像素级模型与SAM的性能,我们首先使用我们的模型选择最高分的补丁,然后将补丁的中心作为点提示输入到SAM。
-
视觉问答(VQA)。虽然GRAFT可以用来回答简单的问题,如“哪张卫星图像包含棒球场?”,但更微妙的问题可能需要复杂的推理。为了允许更复杂的问题,我们将我们的VLM与ViperGPT结合起来。ViperGPT使用一个大型语言模型(LLM)将自然语言查询转换为程序,该程序又调用一个开放词汇的对象检测器。我们**将Viper-GPT中基于GLIP的检测器替换为我们在NAIP数据上训练的像素级GRAFT模型。**为了产生检测输出,我们阈值化像素级分数并检索连通组件以获得实例,然后像以前一样使用SAM进一步完善每个实例。
实验
图像级理解
像素级理解















 1703
1703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









