







相关资料
论文:Efficient Remote Sensing with Harmonized Transfer Learning and Modality Alignment
代码:https://github.com/seekerhuang/HarMA
摘要
随着视觉和语言预训练(VLP)的兴起,越来越多的下游任务采用了先预训练后微调的范式。尽管这一范式在各种多模态下游任务中展示了潜力,但在遥感领域的实施遇到了一些障碍。具体来说,同模态嵌入倾向于聚集在一起,阻碍了高效的迁移学习。为了解决这个问题,我们从统一的角度回顾了多模态迁移学习在下游任务中的目标,并基于三个不同的目标重新考虑了优化过程。我们提出了“Harmonized Transfer Learning and Modality Alignment (HarMA)”,一种方法,它同时满足任务约束、模态对齐和单模态统一对齐,同时通过参数高效的微调最小化训练开销。值得注意的是,HarMA无需外部数据进行训练,就在遥感领域的两个流行的多模态检索任务中实现了最先进的性能。我们的实验表明,HarMA仅使用最少的可调参数就能实现与完全微调模型相媲美甚至更优越的性能。由于其简单性,HarMA可以集成到几乎所有现有的多模态预训练模型中。我们希望这种方法能够促进大型模型在广泛的下游任务中的高效应用,同时显著降低资源消耗。
引言
先预训练后全面微调局限性:
- 全面微调一个大型模型极其昂贵且不可扩展。
- 预训练模型已经在大型数据集上训练了很长时间,而在小型数据集上进行全面微调可能导致泛化能力降低或过拟合。
参数高效微调局限性:
- 集中在单模态特征上。
- 在建模视觉-语言联合空间时忽视了潜在的语义不匹配。
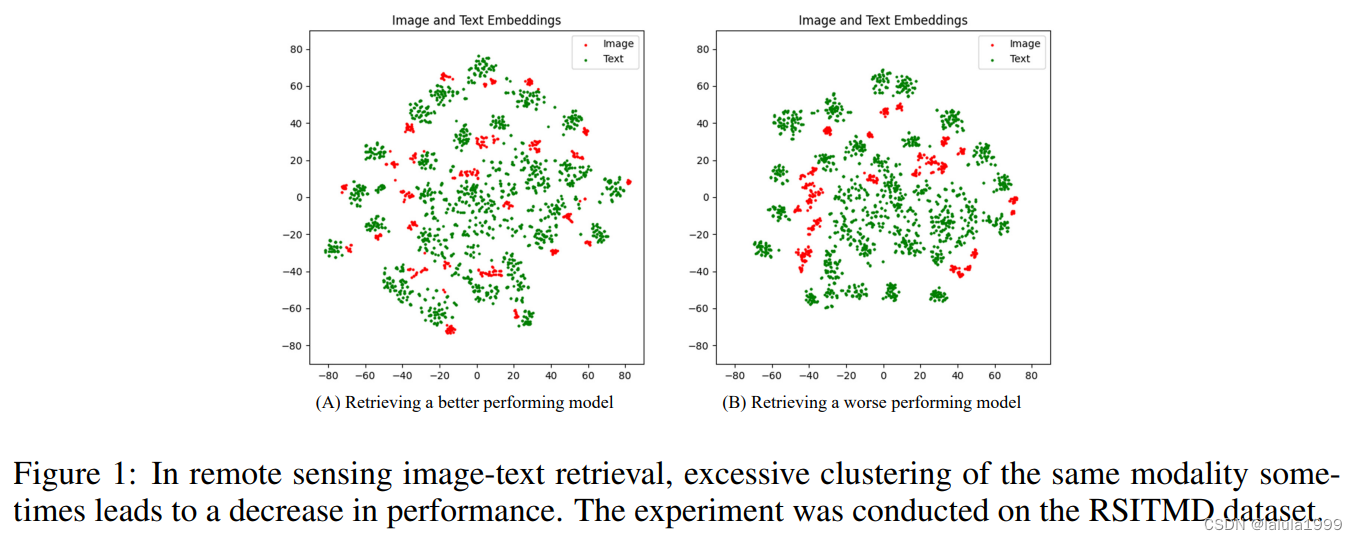
我们观察到,表现不佳的模型有时在其同模态嵌入内部表现出聚类现象。图1展示了在遥感图像-文本检索领域中两个性能不同的模型的最后一层嵌入的可视化;与左侧图像相比,右侧图像中的聚类现象更为明显。我们假设这可能归因于遥感图像的高类内和类间相似性,导致在建模低秩视觉-语言联合空间时出现语义混淆。
类似于人脑的信息处理方法,我们设计了一个带有迷你适配器的分层多模态适配器。该框架模仿人脑利用共享的小型区域处理来自视觉和语言刺激的神经冲动的策略。它通过分层共享多个迷你适配器,从低到高级别地建模视觉-语言语义空间。最后,我们引入了一个新的目标函数,以缓解同一模态内部特征的严重聚类。由于其简单性,该方法可以轻松集成到几乎所有现有的多模态框架中。
方法
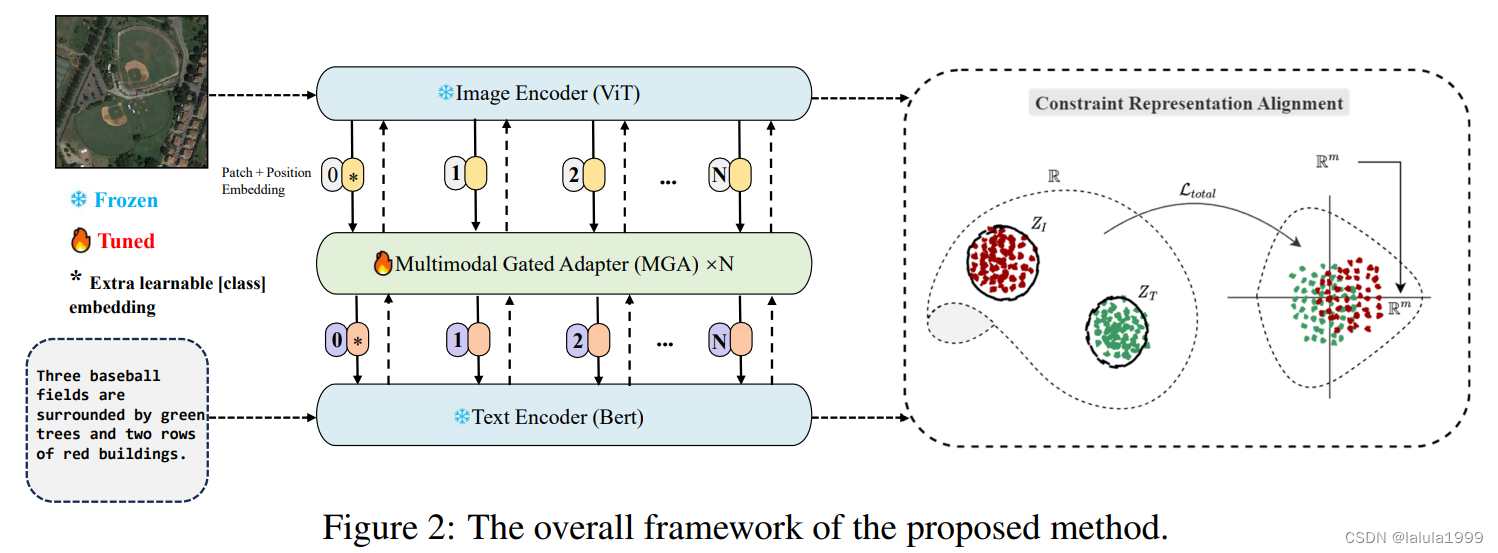
我们提出的 HarMA 框架首先使用图像和文本编码器提取表示,类似于 CLIP。然后这些特征通过我们独特的多模态门控适配器进行处理以获得精炼的特征表示。与使用的简单线性层交互不同,我们采用了共享的迷你适配器作为整个适配器内的交互层。之后,我们使用对比学习目标和我们的自适应三元损失进行优化。
多模态门控适配器
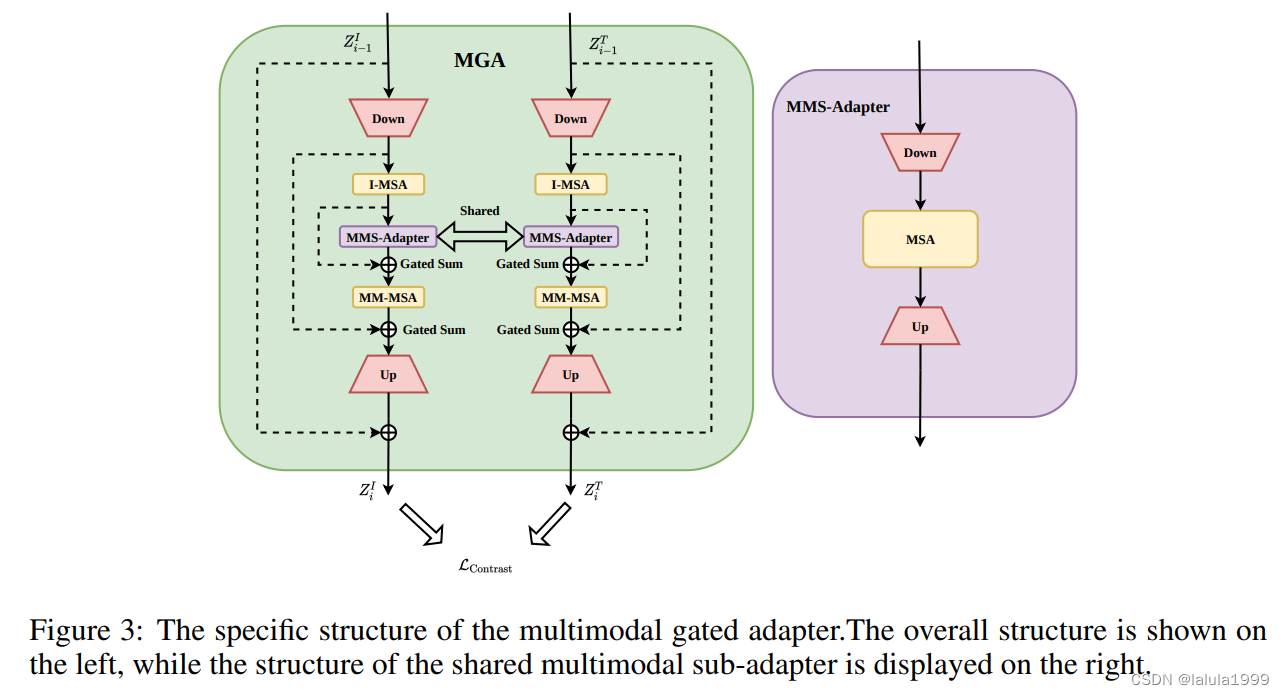
在这个模块中,提取的特征 z I z^I zI 和 z T z^T zT 首先被投影到低维嵌入中。不同的特征 z I z^I zI ( z T z^T zT) 在经过非线性激活和随后的 I-MSA 处理后,特征表达得到了进一步增强。I-MSA 及其后的 MM-MSA 共享参数。然后,这些特征被送入我们设计的多模态子适配器 (MMS-Adapter) 进行进一步交互,该模块的结构在图 3 的右侧显示。
多模态子适配器 (MMS-Adapter)类似于标准适配器,通过共享权重自注意力对齐多模态上下文表示。然而,这些对齐表示的直接后投影输出对图像-文本检索性能产生负面影响,可能是因为在特征的低维流形空间中的非对角线语义关键匹配。这与对比学习目标相矛盾。
为了解决这个问题,已经对齐的表示在 MSA 中进一步使用共享权重进行处理,从而减少模型参数并利用先前的模态知识。为了确保图像和文本之间的更细粒度的语义匹配,我们在 MGA 输出中引入了早期图像-文本匹配监督,显著减少了上述问题的发生。
最终,特征被重新投影回其原始维度,然后添加跳跃连接。最后一层初始化为零,以在训练的初始阶段保护预训练模型的性能。算法 1 概述了提出的方法。

算法1 多模态门控适配器(MGA)用于跨模态交互。
输入:分别来自图像和文本编码器的特征张量 Z I Z_I ZI 和 Z T Z_T ZT。
参数:权重矩阵 W 1 , W 2 , W i W_1, W_2, W_i W1,W2,Wi,偏置向量 b 1 , b 2 , b i b_1, b_2, b_i b1,b2,bi,以及可学习的门控参数 λ 1 , λ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1287
1287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









