







一、什么是损失函数
损失函数用来评估模型预测值和真实值之间的差异。模型的损失越小,模型的鲁棒性越好。
二、模型与常用损失函数
| 损失函数 | 模型 |
|---|---|
| 感知损失Perceptron Loss | PLA |
| Hinge损失Hinge Loss | SVM |
| 对数损失Log Loss | 逻辑回归 |
| 平方损失Square Loss | 回归模型 |
| 绝对值损失Absolute Loss | 回归模型 |
| 指数损失Exponential Loss | Adaboost |
三、常用的损失函数
1、0-1损失函数失函数 (Zero-one Loss)
预测值和目标值不相等为1,否则为0:
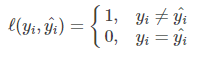
2、感知损失(Perceptron Loss)
感知机原理是0-1损失。但是由于相等这个条件太过严格,因此放宽条件,即满足 |Y−f(X)|<T 时认为相等。
t
t
t是一个超参数阈值,如在
P
L
A
(
P
e
r
c
e
p
t
r
o
n
L
e
a
r
n
i
n
g
A
l
g
o
r
i
t
h
m
,
感
知
机
算
法
)
PLA(Perceptron Learning Algorithm,感知机算法)
PLA(PerceptronLearningAlgorithm,感知机算法)中取
t
=
0.5
t=0.5
t=0.5。
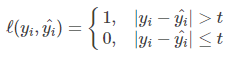
3、Hinge损失函数 (Hinge Loss)
Hinge损失可以用来解决间隔最大化问题,如在SVM中解决几何间隔最大化问题。其定义如下:
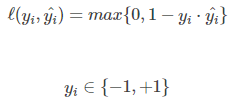
4、对数损失函数(Log Loss)
在使用似然函数最大化时,其形式是进行连乘。为了方便计算通常都是先取对数再求导找极值点,将连乘转化为求和。损失函数表达:
ℓ
(
Y
,
P
(
Y
∣
X
)
)
=
−
l
o
g
(
P
(
Y
∣
X
)
)
\displaystyle \ell ( Y,P( Y|X)) =-log( P( Y|X))
ℓ(Y,P(Y∣X))=−log(P(Y∣X))
表示样本
X
X
X在分类
Y
Y
Y的情况下,使概率
P
(
Y
∣
X
)
P(Y|X)
P(Y∣X)达到最大值(换言之,就是利用已知的样本分布,找到最有可能(即最大概率)导致这种分布的参数值;或者说什么样的参数才能使我们观测到目前这组数据的概率最大)。因为
l
o
g
log
log函数是单调递增的,所以
l
o
g
P
(
Y
∣
X
)
logP(Y|X)
logP(Y∣X)也会达到最大值,因此在前面加上负号之后,最大化
P
(
Y
∣
X
)
P(Y|X)
P(Y∣X)就等价于最小化了。
如在洛基回归中使用交叉熵(Cross Entropy)作为其损失函数。即:
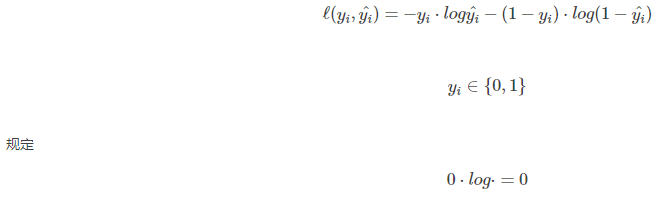
5、平方损失函数(Square Loss)
最小二乘法认为,最优拟合直线应该是使各点到回归直线的距离和最小的直线,即平方和最小。距离是用的是欧氏距离
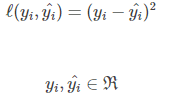
6、绝对值误差(Absolute Loss)
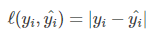
7、指数损失函数 (Exponential Loss)
指数损失函数(exp-loss)的标准形式如下:
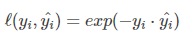
Adaboost算法,前向分步加法算法的特例,是一个加和模型,损失函数就是指数函数。在Adaboost中,经过m此迭代之后,可以得到:
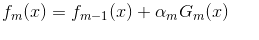
Adaboost每次迭代时的目的是为了找到最小化下列式子时的参数 和G:
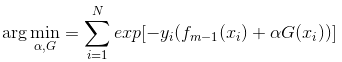
可以看出,Adaboost的目标式子就是指数损失,在给定n个样本的情况下,Adaboost的损失函数为:
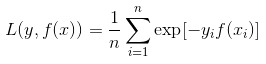
四、各种损失函数的图像:

参考文献:
1、机器学习总结(一):常见的损失函数:https://blog.csdn.net/weixin_37933986/article/details/68488339
2、机器学习中常见的损失函数:https://blog.csdn.net/heyongluoyao8/article/details/52462400
3、机器学习损失函数:https://blog.csdn.net/flowerboya/article/details/53202193
4、机器学习中的损失函数:https://blog.csdn.net/shenxiaoming77/article/details/51614601















 229
229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









