







B站账号@狼群里的小杨,记得点赞收藏加关注,一键三连哦!
一、 实验目的
- 掌握CAMP相关概念
- 掌握量化选股方法
- 掌握 收益、 收益的计算
二、 实验内容
(1)根据输入数据,使用python 编程,CAPM 方程拟合;
(2)对拟合结果进行解释:是否存在阿尔法收益?贝塔收益?并进行对比,按你的理解分析为何这5只股票出现这种差异。
(3)将程序运行结果贴图。
(4)将代码粘贴附后。
三、 实验步骤
1、准备工作
安装tushare库

- 安装statsmodels库

- 查看贵州茅台的股票代码

中国石油股票代号查询

五粮液股票代号查询

泸州老窖股票代号查询

招商银行股票代号查询

美的集团股票代号查询
2、五家企业的CAMP模型拟合代码介绍
首先写一个函数modelCAMP(code, name),传入的参数code为企业股票代号,name为企业名称。
从tushare第三方库中获取上证指数和企业2018-01-01~2021-01-01的数据
sh = ts.get_hist_data('sh', start='2018-01-01', end='2021-01-01') # 获取上证指数数据
stock = ts.get_hist_data(code, start='2018-01-01', end='2021-01-01') # 获取企业三年的股票数据
- 将获取到的数据融合成DataFrame形式的数据
ret_merge = pd.merge(pd.DataFrame(sh.p_change), pd.DataFrame(stock.p_change), left_index=True, right_index=True, how='inner')
计算日无风险利率
Rf_year =0.04 # 以2018 年中国三年期国债年化收益率为无风险利率
Rf = (1+Rf_year)**(1/365)-1 # 年利率转化为日利率
计算风险溢价
Eret = ret_merge-Rf
Eret.head()
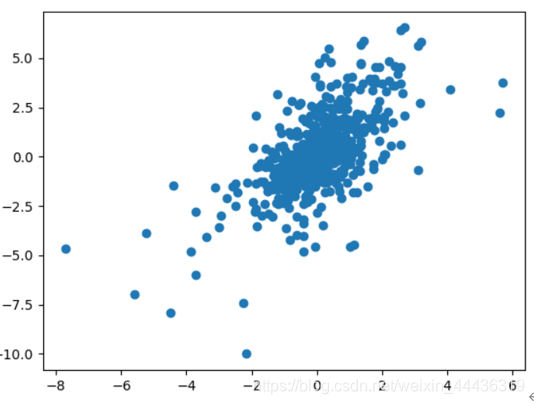
画出两个风险溢价的散点图
plt.scatter(Eret.values[:, 0], Eret.values[:, 1])
plt.show()
利用最小二乘法进行线性回归,拟合CAPM 模型
md_capm = sm.OLS(Eret.p_change_y[1:],sm.add_constant(Eret.p_change_x[1:]))
result = md_capm.fit()
result.summary()
print("\n{}CAMP建立".format(name))
print(result.summary())
3、计算结果和可视化
贵州茅台的CAMP模型拟合结果
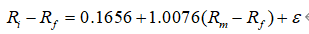
贵州茅台年α为
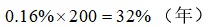
贵州茅台的程序计算结果如图所示

贵州茅台和大盘风险溢价的散点图
4、结果分析与解释
首先从总体来看六只股票如表1所示。

完整代码
'''
python3.7
-*- coding: UTF-8 -*-
@Project -> File :Code -> CAMP
@IDE :PyCharm
@Author :YangShouWei
@USER: 296714435
@Date :2021/3/25 15:41:37
@LastEditor:
'''
import pandas as pd
import tushare as ts
import matplotlib.pyplot as plt
import statsmodels.api as sm
def modelCAMP(code, name):
# 资本资产进价模型(CAPM)
# Ri -Rf = β*(Rm-Rf) + ε
# 载入股指数据
sh = ts.get_hist_data('sh', start='2018-01-01', end='2021-01-01') # 获取上证指数数据
stock = ts.get_hist_data(code, start='2018-01-01', end='2021-01-01') # 获取企业三年的股票数据
ret_merge = pd.merge(pd.DataFrame(sh.p_change), pd.DataFrame(stock.p_change), left_index=True, right_index=True, how='inner')
# 计算日无风险利率
Rf_year =0.04 # 以2018 年中国三年期国债年化收益率为无风险利率
Rf = (1+Rf_year)**(1/365)-1 # 年利率转化为日利率
# 计算风险溢价:Ri-Rf
Eret = ret_merge-Rf
Eret.head()
# 画出两个风险溢价的散点图,查看相关性
plt.scatter(Eret.values[:, 0], Eret.values[:, 1])
plt.show()
# 利用最小二乘法进行线性回归,拟合CAPM 模型
md_capm = sm.OLS(Eret.p_change_y[1:],sm.add_constant(Eret.p_change_x[1:]))
result = md_capm.fit()
result.summary()
print("\n{}CAMP建立".format(name))
print(result.summary())
if __name__ == "__main__":
# 依次调用函数计算企业的CAMP拟合结果
modelCAMP('600036', "招商银行")
modelCAMP("600519", "贵州茅台")
modelCAMP("601857", "中国石油")
modelCAMP("000858", "五粮液")
modelCAMP("000568", "泸州老窖")
modelCAMP("000333", "美的集团")














 555
555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









