







这里写目录标题
问题描述
salary.txt文件调查了32561名美国居民的信息,包括年龄,教育年限,工作类别,收入等,数据解雇如下所示

以薪水(salary)作为目标值,建立薪水预测模型
在这个模型中,要包括以下部分:
(1)去掉无用特征
(2)去掉缺失值所在的行
(3)将值为字符串的字段转化为one-hot编码
(4)标准化
(5)PCA降维
(6)划分数据集
(7)KNN预测
(8)交叉验证与网格化搜索,要调的参数包括:k,p,weights
(1)导入模块

(2)导入数据并初步选择特征
导入数据,并将无用的字段去掉
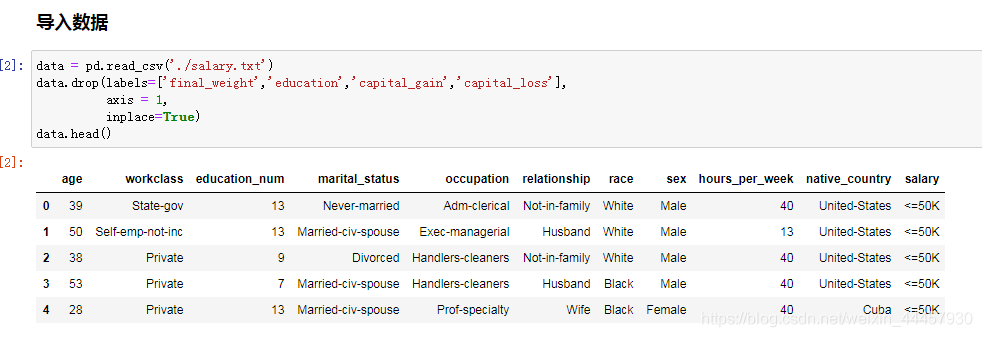
(3)数据预处理
a 缺失值处理
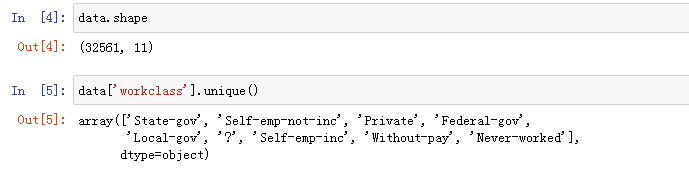
可以看到,workclass这一列有问号,问号通常表示缺失值
将问号替换成np.nan,方便使用dropna

去掉缺失值所在的行

可以看到,workclass这一列,已经没有nan了,于此同时,记录也损失了两千多行
b 从清洗后的数据中获得特征值和目标值

c 将特征分成两部分,即字符串特征和数字特征

d 将字符串特征转换为one-hot编码
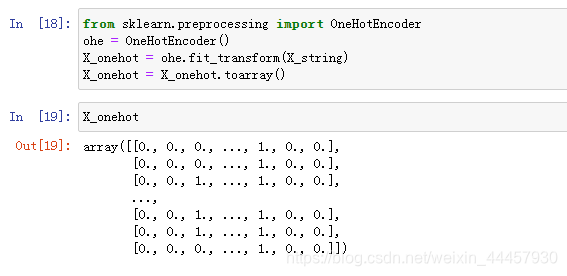
e 将one-hot编码后的特征与数字特征水平拼接

f 标准化
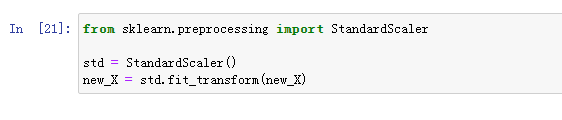
(3)PCA降维,保留95%的信息

(4)将新数据划分为训练集和测试集

(5)KNN预测

(6)交叉验证与网格化搜索
因为30162的算术平方根为173,因此k最大只能为173,为了方便,让k最大取170
由于太参数网格化搜索太花时间,因此建议到服务器上运行。
(7)最佳参数及其对应的模型

(8)代码整合
上面的交叉验证时,分的是二折,这里使用4折
import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import StandardScaler
"""导入数据"""
data = pd.read_csv('F:/拜师培训/4168_Sklearn_v2/V2-sklearn第二节资料/day02代码/knn/salary.txt')
"""数据处理"""
# 将不影响结果的数据去掉
data.drop(labels=['final_weight','education','capital_gain','capital_loss'],
axis = 1, inplace=True)
# 将问号替换掉
data.replace('?', np.nan, inplace=True)
# 去掉 nan 所在的行
data.dropna(axis=0, inplace=True)
# 从清洗后的数据中获得特征值和目标值
X = data.iloc[:, 0:-1]
y = data['salary']
# 将字符串所在的字段进行one-hot编码
# 将需要编码的字段名放到一个列表中
cols = ['workclass', 'marital_status', 'occupation',
'relationship', 'race', 'sex','native_country']
# 将所有的字符串字段整理成一个DataFrame,即字符串特征
X_string = X[cols]
# 将所有的数值字段整合成一个DataFrame,即数字特征
X_number = X[[col_num for col_num in X.columns if col_num not in cols]]
# 将特征为字符串的字段转化成one-hot编码
ohe = OneHotEncoder()
X_onehot = ohe.fit_transform(X_string)
X_onehot = X_onehot.toarray()
# 将one-hot编码后的特征,与数字特征水平连接
new_X = np.hstack((X_onehot, X_number)) # 两重括号
'''标准化'''
std = StandardScaler()
new_X = std.fit_transform(new_X)
'''PCA降维'''
pca = PCA(n_components=0.95)
new_data = pca.fit_transform(new_X)
'''将新数据划分为训练集和测试集'''
X_train, X_test, y_train, y_test = train_test_split(new_data, y)
'''KNN训练及预测'''
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
score = knn.score(X_test, y_test)
print('k=5时的预测结果:')
print(score)
'''交叉验证与网格化搜索'''
para = {"n_neighbors": [1, 3, 5, 7, 10, 20, 50, 100, 150, 170],
'p':[1, 2],
'weights':['distance', 'uniform']}
gc = GridSearchCV(knn, param_grid=para, cv=4)
gc.fit(X_train, y_train)
print()
print()
print('最好的模型:')
print(gc.best_estimator_)
print('最好的模型对应的参数:')
print(gc.best_params_)
print('最好的模型在训练集上的准确率:')
print(gc.best_score_)
print('最好的模型在测试集上的准确率:')
print(gc.score(X_test, y_test))
输出
k=5时的预测结果:
0.8195199575653096
最好的模型:
KNeighborsClassifier(n_neighbors=20)
最好的模型对应的参数:
{'n_neighbors': 20, 'p': 2, 'weights': 'uniform'}
最好的模型在训练集上的准确率:
0.8232614801836379
最好的模型在测试集上的准确率:
0.8244264686381116
(9)总结
可以看到,本案例中KNN的准确率并不是很高,但本例的综合性很强,将缺失值处理、字符串转one-hot编码、数据标准化、PCA降维、数据集划分、KNN、交叉验证与网格化搜索都串起来了。

















 1372
1372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









