










Rethinking Channel Dimensions for Efficient Model Design论文解读
论文地址:https://arxiv.org/pdf/2007.00992.pdf
代码地址:https://github.com/clovaai/rexnet
一个轻量级模型的精度进一步受到了设计惯例的限制:通道维度的阶段配置,它看起来像一个网络阶段的分段线性函数。在本文的研究中,我们研究了一种有效的通道尺寸配置。为此,我们通过分析输出特征的秩,实证研究了如何正确设计单个层。然后,我们通过搜索在计算成本限制下有关信道配置的网络体系结构来研究模型的通道配置。
通过实验观察并学习到:
-
an inverted bottleneck is needed to design with the expansion ratio of 6 or smaller values at the first 1×1 convolution
在倒残差结构中,最前面的1x1卷积层的扩展比例应该小于或等于6. -
each inverted bottleneck with a depthwise convolution in a lightweight model needs a higher channel dimension ratio
每一个拥有深度可分离卷积的倒残差结需要更高的通道尺寸比例。 -
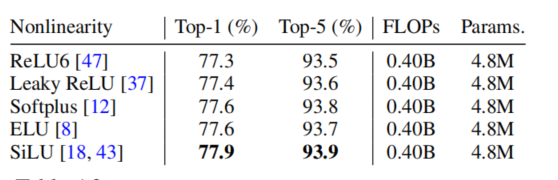
a complicated nonlinearity such as ELU and SiLU needs to be placed after 1×1 convolutions or 3×3 convolutions
在1×1卷积或3×3卷积后,需要放置卷积如ELU和SiLU这样复杂的非线性函数。 -
linear parameterizations by the block indexenjoy higher accuracies while maintaining similar computational costs.
线性地增加块的通道数可以提高精度并保持相似的计算成本。 -
The models have highly reduced the input-side channels and therefore, most of the weight parameters are placed at the output-side resulting in the loss of accuracy.
前面的尺寸小,将后面的尺寸放大会导致精度的损失。

根据上述实验,对MobileNet V1和V2进行改进:

Every inverted bottleneck block that expands the channel dimensions (except for the downsampling blocks) has a skip connection
ReXNet (x1.0)是对V2进行的改进,其中每个扩展通道的倒残差块都加入了残差连接。ReXNet (plain)是对V1进行的改进。SE是在该部分加入SE模块。

除此之外,还对非线性函数进行了对比。
代码:
ReXNet (x1.0):
import torch
import torch.nn as nn
from math import ceil
USE_MEMORY_EFFICIENT_SiLU = True
if USE_MEMORY_EFFICIENT_SiLU:
@torch.jit.script
def silu_fwd(x):
return x.mul(torch.sigmoid(x))
@torch.jit.script
def silu_bwd(x, grad_output):
x_sigmoid = torch.sigmoid(x)
return grad_output * (x_sigmoid * (1. + x * (1. - x_sigmoid)))
class SiLUJitImplementation(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
ctx.save_for_backward(x)
return silu_fwd(x)
@staticmethod
def backward(ctx, grad_output):
x = ctx.saved_tensors[0]
return silu_bwd(x, grad_output)
def silu(x, inplace=False):
return SiLUJitImplementation.apply(x)
else:
def silu(x, inplace=False):
return x.mul_(x.sigmoid()) if inplace else x.mul(x.sigmoid())
class SiLU(nn.Module):
def __init__(self, inplace=True):
super(SiLU, self).__init__()
self.inplace = inplace
def forward(self, x):
return silu(x, self.inplace)
def ConvBNAct(out, in_channels, channels, kernel=1, stride=1, pad=0,
num_group=1, active=True, relu6=False):
out.append(nn.Conv2d(in_channels, channels, kernel,
stride, pad, groups=num_group, bias=False))
out.append(nn.BatchNorm2d(channels))
if active:
out.append(nn.ReLU6(inplace=True) if relu6 else nn.ReLU(inplace=True))
def ConvBNSiLU(out, in_channels, channels, kernel=1, stride=1, pad=0, num_group=1):
out.append(nn.Conv2d(in_channels, channels, kernel,
stride, pad, groups=num_group, bias=False))
out.append(nn.BatchNorm2d(channels))
out.append(SiLU(inplace=True))
class SE(nn.Module):
def __init__(self, in_channels, channels, se_ratio=12):
super(SE, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Conv2d(in_channels, channels // se_ratio, kernel_size=1, padding=0),
nn.BatchNorm2d(channels // se_ratio),
nn.ReLU(inplace=True),
nn.Conv2d(channels // se_ratio, channels, kernel_size=1, padding=0),
nn.Sigmoid()
)
def forward(self, x):
y = self.avg_pool(x)
y = self.fc(y)
return x * y
class LinearBottleneck(nn.Module):
def __init__(self, in_channels, channels, t, stride, use_se=True, se_ratio=12,
**kwargs):
super(LinearBottleneck, self).__init__(**kwargs)
self.use_shortcut = stride == 1 and in_channels <= channels
self.in_channels = in_channels
self.out_channels = channels
out = []
if t != 1:
dw_channels = in_channels * t
ConvBNSiLU(out, in_channels=in_channels, channels=dw_channels)
else:
dw_channels = in_channels
ConvBNAct(out, in_channels=dw_channels, channels=dw_channels, kernel=3, stride=stride, pad=1,
num_group=dw_channels, active=False)
if use_se:
out.append(SE(dw_channels, dw_channels, se_ratio))
out.append(nn.ReLU6())
ConvBNAct(out, in_channels=dw_channels, channels=channels, active=False, relu6=True)
self.out = nn.Sequential(*out)
def forward(self, x):
out = self.out(x)
if self.use_shortcut:
out[:, 0:self.in_channels] += x
return out
class ReXNetV1(nn.Module):
def __init__(self, input_ch=16, final_ch=180, width_mult=1.0, depth_mult=1.0, classes=1000,
use_se=True,
se_ratio=12,
dropout_ratio=0.2,
bn_momentum=0.9):
super(ReXNetV1, self).__init__()
layers = [1, 2, 2, 3, 3, 5]
strides = [1, 2, 2, 2, 1, 2]
use_ses = [False, False, True, True, True, True]
#layers = [ceil(0 * depth_mult) for element in layers]
strides = sum([[element] + [1] * (layers[idx] - 1)
for idx, element in enumerate(strides)], [])
if use_se:
use_ses = sum([[element] * layers[idx] for idx, element in enumerate(use_ses)], [])
else:
use_ses = [False] * sum(layers[:])
ts = [1] * layers[0] + [6] * sum(layers[1:])
self.depth = sum(layers[:]) * 3
stem_channel = 32 / width_mult if width_mult < 1.0 else 32
inplanes = input_ch / width_mult if width_mult < 1.0 else input_ch
features = []
in_channels_group = []
channels_group = []
# The following channel configuration is a simple instance to make each layer become an expand layer.
for i in range(self.depth // 3):
if i == 0:
in_channels_group.append(int(round(stem_channel * width_mult)))
channels_group.append(int(round(inplanes * width_mult)))
else:
in_channels_group.append(int(round(inplanes * width_mult)))
inplanes += final_ch / (self.depth // 3 * 1.0)
channels_group.append(int(round(inplanes * width_mult)))
ConvBNSiLU(features, 3, int(round(stem_channel * width_mult)), kernel=3, stride=2, pad=1)
k = 0
for block_idx, (in_c, c, t, s, se) in enumerate(zip(in_channels_group, channels_group, ts, strides, use_ses)):
features.append(LinearBottleneck(in_channels=in_c,
channels=c,
t=t,
stride=s,
use_se=se, se_ratio=se_ratio))
k = c
pen_channels = int(1280 * width_mult)
ConvBNSiLU(features, k, pen_channels)
features.append(nn.AdaptiveAvgPool2d(1))
self.features = nn.Sequential(*features)
self.output = nn.Sequential(
nn.Dropout(dropout_ratio),
nn.Conv2d(pen_channels, classes, 1, bias=True))
O=0
def extract_features(self, x):
return self.features[:-1](x)
def forward(self, x):
x = self.features(x)
x = self.output(x).flatten(1)
return x
if __name__ == '__main__':
model = ReXNetV1(width_mult=1.0)
out = model(torch.randn(2, 3, 224, 224))
loss = out.sum()
loss.backward()
print('Checked a single forward/backward iteration')
ReXNet lite:
import torch
import torch.nn as nn
from math import ceil
def _make_divisible(channel_size, divisor=None, min_value=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if not divisor:
return channel_size
if min_value is None:
min_value = divisor
new_channel_size = max(min_value, int(channel_size + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_channel_size < 0.9 * channel_size:
new_channel_size += divisor
return new_channel_size
def _add_conv(out, in_channels, channels, kernel=1, stride=1, pad=0,
num_group=1, active=True, relu6=True, bn_momentum=0.1, bn_eps=1e-5):
out.append(nn.Conv2d(in_channels, channels, kernel, stride, pad, groups=num_group, bias=False))
out.append(nn.BatchNorm2d(channels, momentum=bn_momentum, eps=bn_eps))
if active:
out.append(nn.ReLU6(inplace=True) if relu6 else nn.ReLU(inplace=True))
class LinearBottleneck(nn.Module):
def __init__(self, in_channels, channels, t, kernel_size=3, stride=1,
bn_momentum=0.1, bn_eps=1e-5,
**kwargs):
super(LinearBottleneck, self).__init__(**kwargs)
self.conv_shortcut = None
self.use_shortcut = stride == 1 and in_channels <= channels
self.in_channels = in_channels
self.out_channels = channels
out = []
if t != 1:
dw_channels = in_channels * t
_add_conv(out, in_channels=in_channels, channels=dw_channels, bn_momentum=bn_momentum,
bn_eps=bn_eps)
else:
dw_channels = in_channels
_add_conv(out, in_channels=dw_channels, channels=dw_channels * 1, kernel=kernel_size, stride=stride,
pad=(kernel_size // 2),
num_group=dw_channels, bn_momentum=bn_momentum, bn_eps=bn_eps)
_add_conv(out, in_channels=dw_channels, channels=channels, active=False, bn_momentum=bn_momentum,
bn_eps=bn_eps)
self.out = nn.Sequential(*out)
def forward(self, x):
out = self.out(x)
if self.use_shortcut:
out[:, 0:self.in_channels] += x
return out
class ReXNetV1_lite(nn.Module):
def __init__(self, fix_head_stem=False, divisible_value=8,
input_ch=16, final_ch=164, multiplier=1.0, classes=1000,
dropout_ratio=0.2,
bn_momentum=0.1,
bn_eps=1e-5, kernel_conf='333333'):
super(ReXNetV1_lite, self).__init__()
layers = [1, 2, 2, 3, 3, 5]
strides = [1, 2, 2, 2, 1, 2]
kernel_sizes = [int(element) for element in kernel_conf]
strides = sum([[element] + [1] * (layers[idx] - 1) for idx, element in enumerate(strides)], [])
ts = [1] * layers[0] + [6] * sum(layers[1:])
kernel_sizes = sum([[element] * layers[idx] for idx, element in enumerate(kernel_sizes)], [])
self.num_convblocks = sum(layers[:])
features = []
inplanes = input_ch / multiplier if multiplier < 1.0 else input_ch
first_channel = 32 / multiplier if multiplier < 1.0 or fix_head_stem else 32
first_channel = _make_divisible(int(round(first_channel * multiplier)), divisible_value)
in_channels_group = []
channels_group = []
_add_conv(features, 3, first_channel, kernel=3, stride=2, pad=1,
bn_momentum=bn_momentum, bn_eps=bn_eps)
for i in range(self.num_convblocks):
inplanes_divisible = _make_divisible(int(round(inplanes * multiplier)), divisible_value)
if i == 0:
in_channels_group.append(first_channel)
channels_group.append(inplanes_divisible)
else:
in_channels_group.append(inplanes_divisible)
inplanes += final_ch / (self.num_convblocks - 1 * 1.0)
inplanes_divisible = _make_divisible(int(round(inplanes * multiplier)), divisible_value)
channels_group.append(inplanes_divisible)
for block_idx, (in_c, c, t, k, s) in enumerate(
zip(in_channels_group, channels_group, ts, kernel_sizes, strides)):
features.append(LinearBottleneck(in_channels=in_c,
channels=c,
t=t,
kernel_size=k,
stride=s,
bn_momentum=bn_momentum,
bn_eps=bn_eps))
pen_channels = int(1280 * multiplier) if multiplier > 1 and not fix_head_stem else 1280
_add_conv(features, c, pen_channels, bn_momentum=bn_momentum, bn_eps=bn_eps)
self.features = nn.Sequential(*features)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.output = nn.Sequential(
nn.Conv2d(pen_channels, 1024, 1, bias=True),
nn.BatchNorm2d(1024, momentum=bn_momentum, eps=bn_eps),
nn.ReLU6(inplace=True),
nn.Dropout(dropout_ratio),
nn.Conv2d(1024, classes, 1, bias=True))
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = self.output(x).flatten(1)
return x
if __name__ == '__main__':
model = ReXNetV1_lite(multiplier=1.0)
out = model(torch.randn(2, 3, 224, 224))
loss = out.sum()
loss.backward()
print('Checked a single forward/backward iteration')
















 675
675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









