







1.任务介绍
任务来源: DQN: Deep Q Learning |自动驾驶入门(?) |算法与实现
任务原始代码: self-driving car
在上一篇使用了DQN算法完成自动驾驶小车绕圈任务之后,学习了DDPG算法,并将DDPG算法用在该任务上。
最终效果:这个gif是没有加速过的,DQN的是两倍速的效果
整体来说,无论是连续性还是转弯的流畅性来说,以及小车能够跑的距离,DDPG的效果要远远优于DQN,但是要比DQN难调试的多。
2.调试记录
主要问题:在DDPG代码调试过程中,一个非常大非常主要的问题就是前期训练若干次之后,action总会持续输出设定的边界极限值,这个问题查阅相关资料,几乎每个人在调试DDPG算法的时候都会遇到,调试大部分时间都在解决该问题
注意:由于每个尝试阶段使用的奖励函数的基础值不一致,有基础值100的,也有基础值1的,所以average_score不具备参考意义,average_distance更具备参考价值
2.1 actor_loss增加梯度惩罚项
记录:deepseek给到的方法,尝试了之后有效,可以解决持续输出极限值的问题;对应的梯度惩罚项系数也尝试了多种组合,但整体训练效果都很不稳定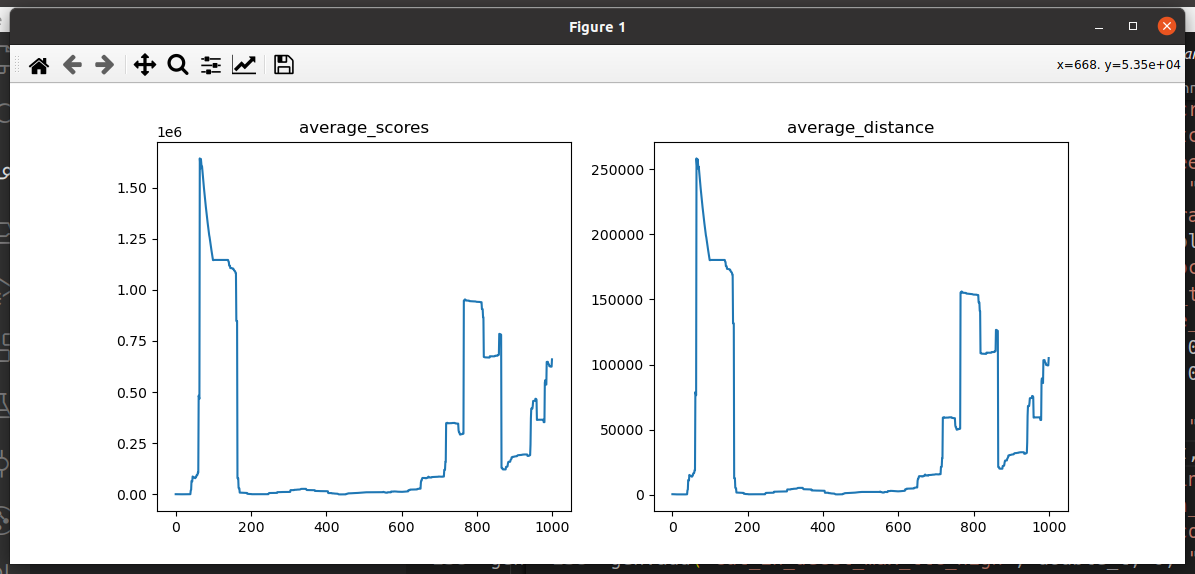
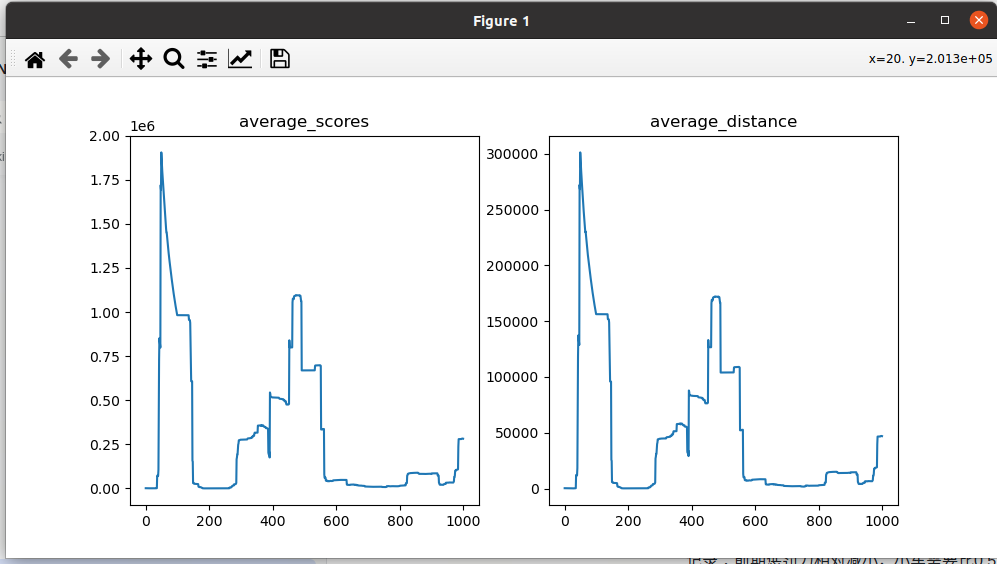
分析可能是后期actor_loss已经太大了,梯度惩罚项失效了已经,而后面失效的时候,action输出的也是极限值
尝试代码:
class DDPGAgent:
def learn(self):
...
# Actor更新 TODO: 为什么用梯度上升?
# 通过最大化Q值间接优化策略
actor_actions = self.actor.forward(states, False, 0.0, self.memory.mem_cntr) # a = μ(s|θ^μ)
q_values = self.critic(states, actor_actions) # Q(s, a|θ^Q)
actor_loss = -q_values.mean() # L = -E[Q]
# 梯度惩罚方法,解决action输出极限值
grad_penalty = (actor_actions ** 2).mean()
actor_loss = actor_loss + 0.4 * grad_penalty
...
2.2 actor梯度下降使用非常严格的梯度剪裁
记录:该方法也可以解决action输出极限值的情况,不过score波动特别大,还需要适配调整;其实发现这么做不是非常合理,因为这个梯度剪裁都已经达到0.000000005的非常小的值了
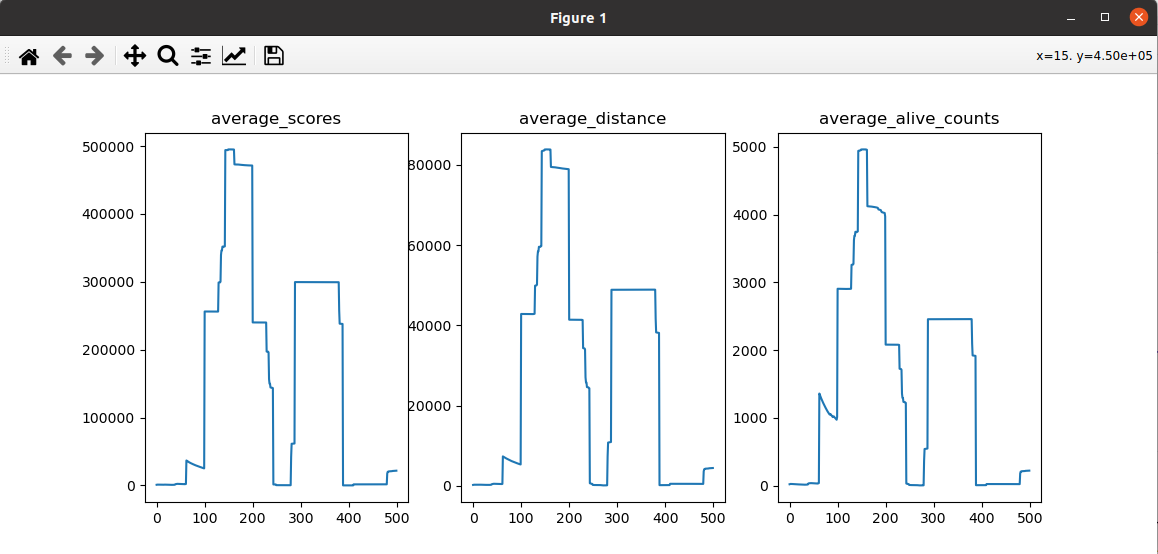
尝试代码:
class DDPGAgent:
def learn(self):
...
self.actor_optimizer.zero_grad()
actor_loss.backward() # 自动微分反向传播
# 严格的梯度裁剪方法,解决action输出极限值
torch.nn.utils.clip_grad_norm_(self.actor.parameters(), 0.000000005)
self.actor_optimizer.step()
...
2.3 actor_loss乘以一个小于1的系数
思考:既然actor_loss加上梯度惩罚项有用,可以改善持续输出极限值的问题,那么直接对actor_loss乘以一个小于1的系数(大概1e-10),缩小前期actor_loss的值,减缓前期梯度更新的幅度,理论上应该也可以解决问题
记录:该方法也可以解决action输出极限值的情况,到后面车速感觉特别快,应该考虑action 0和action 1的惩罚系数要各自分开算;这个方法其实也不是非常合理,系数已经达到了1e-10,后面没有基于此方法做优化
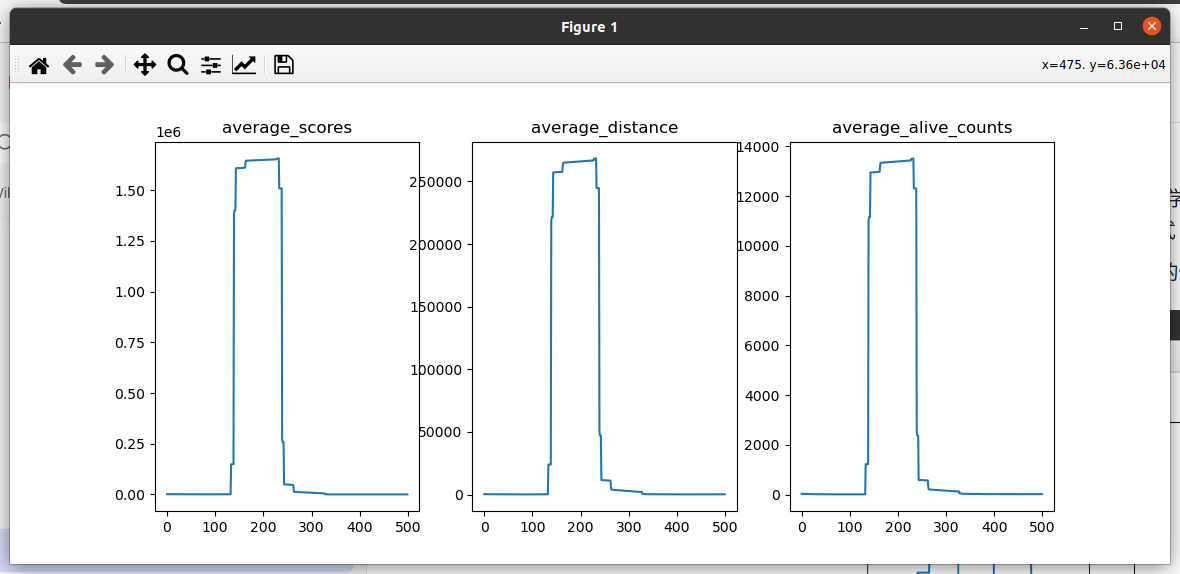
尝试代码:
class DDPGAgent:
def learn(self):
...
# Actor更新 TODO: 为什么用梯度上升?
# 通过最大化Q值间接优化策略
actor_actions = self.actor.forward(states, False, 0.0, self.memory.mem_cntr) # a = μ(s|θ^μ)
q_values = self.critic(states, actor_actions) # Q(s, a|θ^Q)
actor_loss = -q_values.mean() # L = -E[Q]
# actor_loss系数惩罚方法,解决action输出极限值
grad_penalty = 1e-10
actor_loss = actor_loss * grad_penalty
...
2.4 actor网络优化
记录:通过查阅资料,建议更改actor网络的结构,在尝试增加、减小模型层数以及神经元个数之后都没有效果;
2.5 奖励函数优化(稳定有效)
记录:主要是将奖励函数的输出值限定在[-1,1]之间,并且在奖励函数中考虑过大转向的惩罚,以及速度较低的惩罚,还有碰撞的惩罚,这个做法可以稳定解决action输出极限值的问题;
但其实奖励函数这么设置还是不很稳定,奖励函数中没有明确的方向引导,导致小车有的时候会反向跑圈 - -!
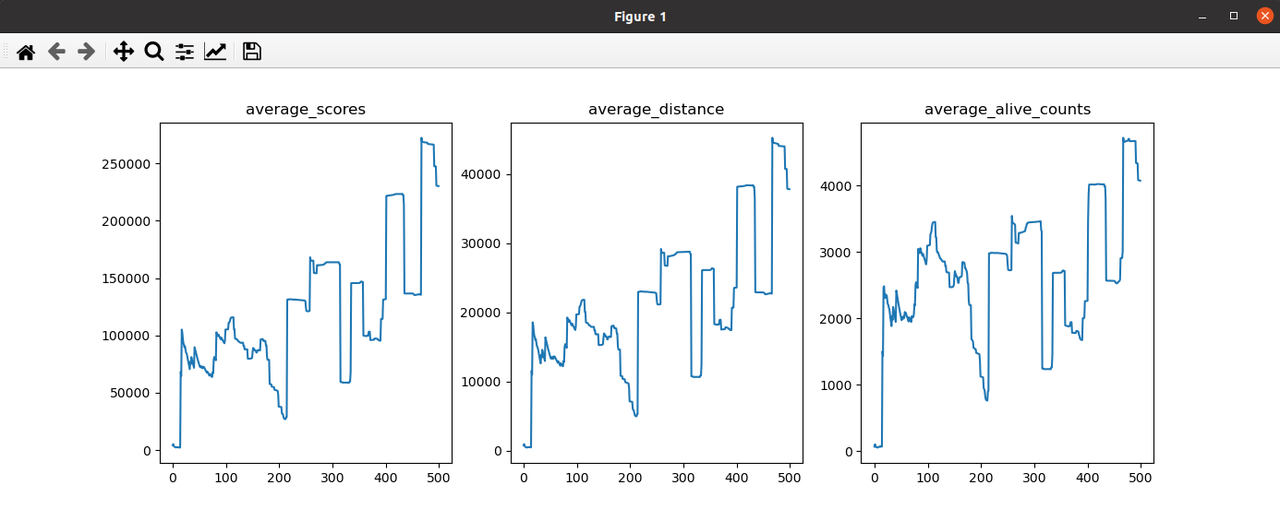
现阶段问题:小车整体的score依然会在某个点之后断崖式下降;通过记录的log发现,小车的alive_count只有在episode 26的时候是非常大的,能够到到286W左右,但是在此之后剩下的所有episode中,alive_count基本都维持在10左右
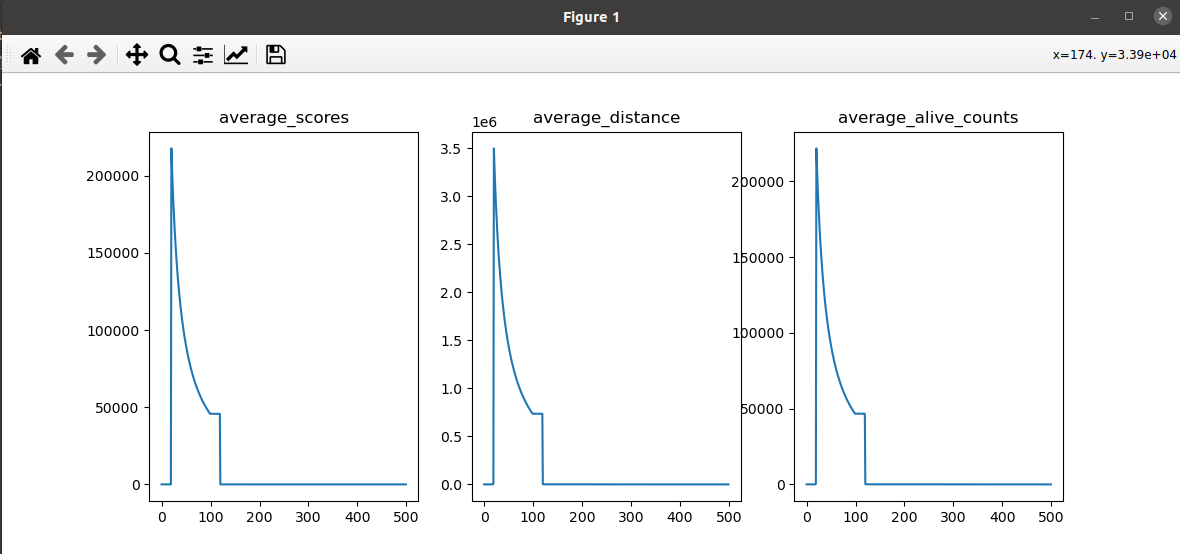
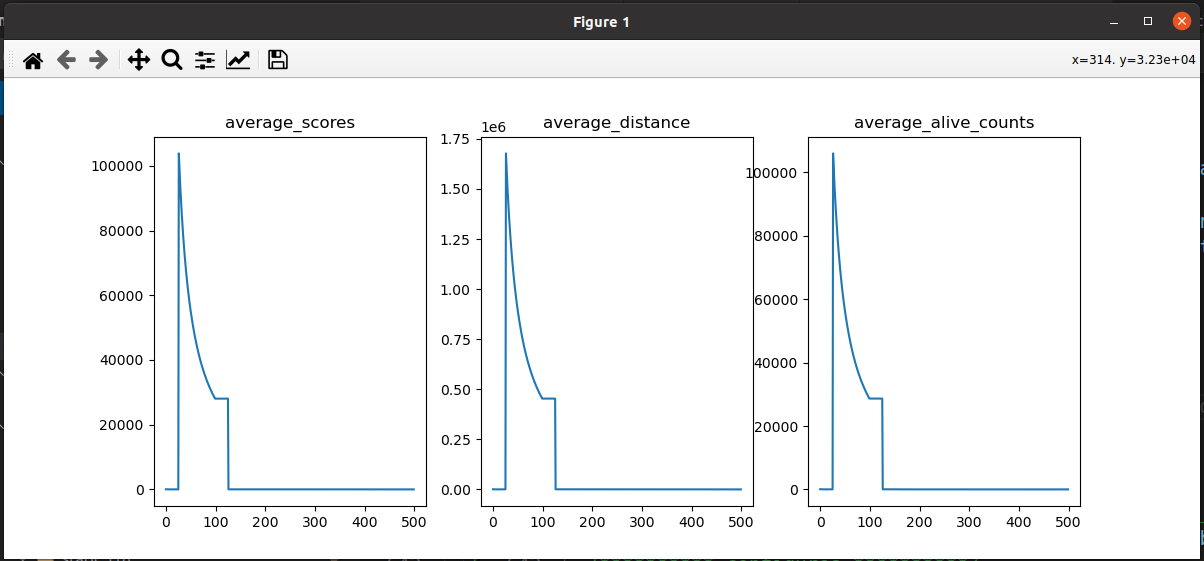
尝试代码:
class Car:
def get_reward_optimized333(self, action, done):
# 居中性奖励
lateral_reward = max((self.current_lateral_min_dist / 60 - 0.4) * 2, 0.0)
# action输出转角奖励
steer_reward = 0.0
if abs(action[0].item()) >= 2.5:
steer_reward = -0.2 * abs(action[0].item()) + 0.5
# 速度奖励
speed_reward = 0.0
if self.speed < 12.0:
speed_reward = 0.05 * self.speed - 0.6
else:
speed_reward = (self.speed - 12.0) * 0.04
# elif self.speed >= 16.0:
# speed_reward = -0.15 * self.speed + 2.4
# 速度基础
speed_base_reward = self.speed / 15.0
# 转角连续性
angle_discount = 1.0
if len(self.angle_memory) >= 5:
self.angle_memory = self.angle_memory[1:]
self.angle_memory.append(action[0].item())
aaa = [0] * 4
if len(self.angle_memory) >= 5:
for i in range(1, 5):
aaa[i - 1] = self.angle_memory[i] - self.angle_memory[i - 1]
bbb = [0] * 3
for j in range(1, 4):
bbb[j - 1] = 1 if aaa[j - 1] * aaa[j] < 0 else 0
if sum(bbb) >= 3 and lateral_reward > 0.0:
angle_discount = 0.8
total_reward = lateral_reward * angle_discount * speed_base_reward + speed_reward + steer_reward
# total_reward = lateral_reward * angle_discount * speed_base_reward + steer_reward
# print("total_reward: ", total_reward)
total_reward = max(-1.0, min(total_reward, 1.0))
# return total_reward
return total_reward if ~done else -1.0
2.6 增大buffer_size=1000W
记录:为了解决小车整体的score依然会在某个点之后断崖式下降的问题,通过提供一些log细节给到deepseek,deepseek觉得可能是buffer_size只有100W导致的,训练后期,小车的mem_cntr已经达到280W了,所以前期的经验可能已经被遗忘,建议尝试先用增大buffer_size方法试一下; 这个做法验证是有效的,episode: 17 的时候已经训练超过72小时了,但最终小车在mem_cntr > 10000000的时候,依然是会断崖式下降
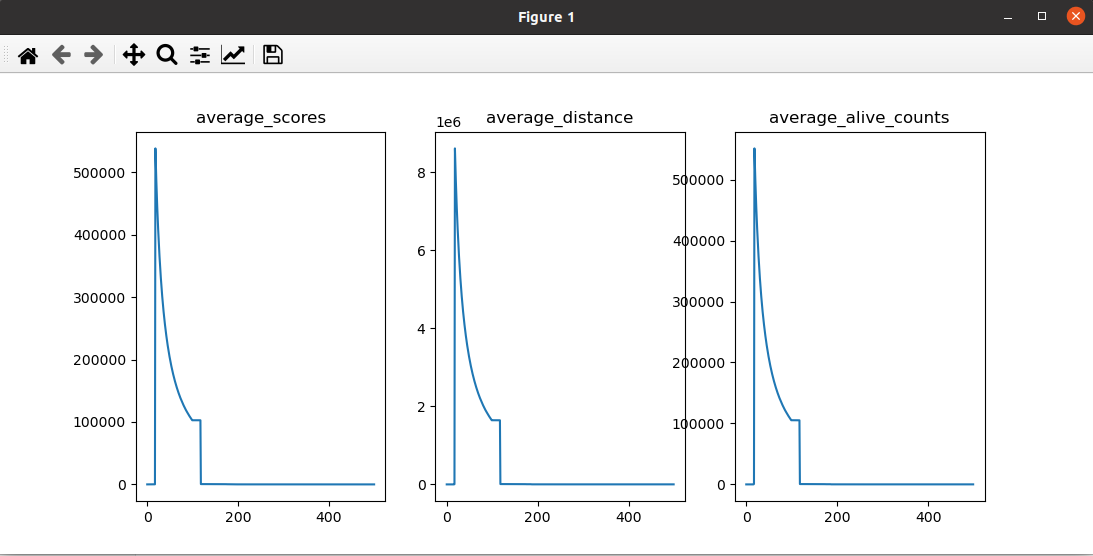
2.7 减小buffer_size=10W,加速数据周转
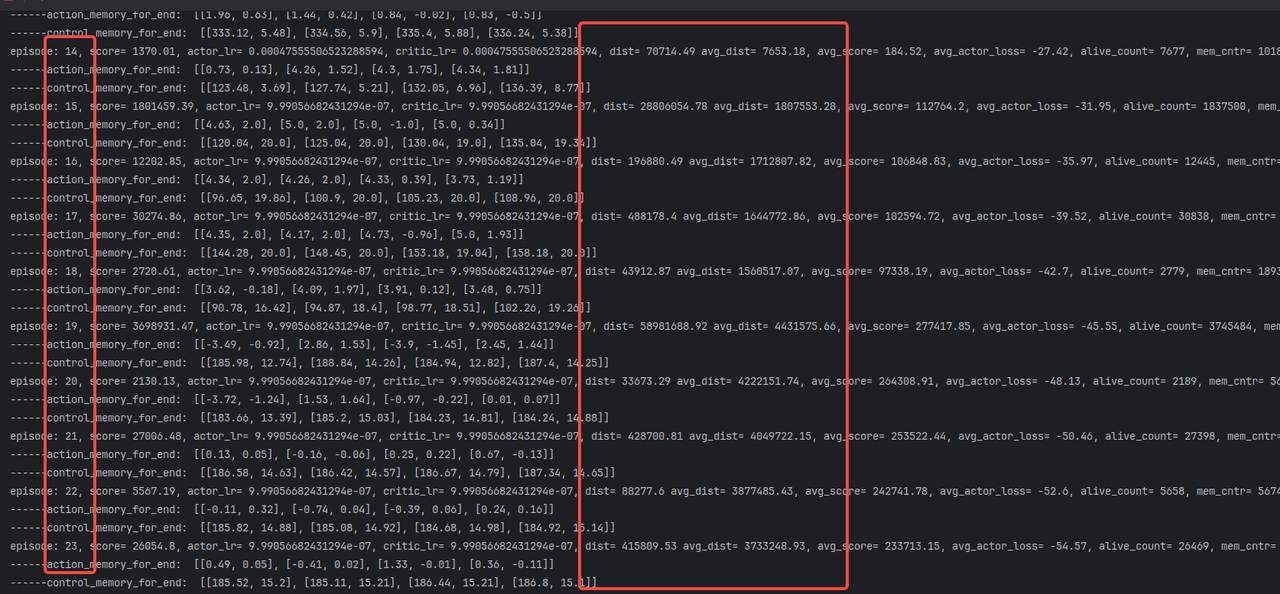
记录:加速数据周转的方法,也明显有效可以解决小车整体的score依然会在某个点之后断崖式下降的问题,且表现要比增大buffer_size=1000W的效果好; episode: 23训练大概100个小时的时候电脑自己关机了。。。。。下面是期间截图的一些log
3.相比DQN代码主要改进点
3.1 Actor网络更新
class Actor(nn.Module):
def __init__(self, input_dims, action_dim, max_action):
super(Actor, self).__init__()
self.max_action = max_action
self.fc1 = nn.Linear(input_dims[0], 256)
self.fc2 = nn.Linear(256, 256)
self.fc3 = nn.Linear(256, action_dim)
# 初始化最后一层权重为小范围随机值
torch.nn.init.uniform_(self.fc3.weight, -3e-3, 3e-3)
torch.nn.init.constant_(self.fc3.bias, 0.0)
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def forward(self, state, add_noise, noise, mem_cntr):
x = F.relu(self.fc1(state))
x = F.relu(self.fc2(x))
x = torch.tanh(self.fc3(x)).to(self.device)
if add_noise:
x += torch.tensor(noise).to(self.device)
x = torch.clip(x, torch.tensor([-1.0, -1.0]).to(self.device), torch.tensor([1.0, 1.0]).to(self.device))
steer = x[:, 0] * self.max_action[0]
speed = x[:, 1] * self.max_action[1]
action = torch.stack([steer, speed], dim=1)
return action
3.2 增加Critic网络
class Critic(nn.Module):
def __init__(self, input_dims, action_dim):
super(Critic, self).__init__()
self.fc1 = nn.Linear(input_dims[0] + action_dim, 256)
self.fc2 = nn.Linear(256, 256)
self.fc3 = nn.Linear(256, 1)
def forward(self, state, action):
x = torch.cat([state, action], dim=1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
q_value = self.fc3(x)
return q_value
3.3 增加ReplayBuffer类用于管理历史经验
class ReplayBuffer:
def __init__(self, max_mem_size, batch_size, input_dims, action_dim, device):
self.mem_size = max_mem_size
self.batch_size = batch_size
self.mem_cntr = 0
self.device = device
self.state_memory = np.zeros((self.mem_size, *input_dims), dtype=np.float32)
# TODO: dtype还需验证
self.action_memory = np.zeros((self.mem_size, action_dim), dtype=np.float32)
self.reward_memory = np.zeros(self.mem_size, dtype=np.float32)
self.next_state_memory = np.zeros((self.mem_size, *input_dims), dtype=np.float32)
self.terminal_memory = np.zeros(self.mem_size, dtype=bool)
def store(self, state, action, reward, next_state, done):
index = self.mem_cntr % self.mem_size
self.state_memory[index] = state
self.action_memory[index] = action
self.reward_memory[index] = reward
self.next_state_memory[index] = next_state
self.terminal_memory[index] = done
self.mem_cntr += 1
def sample(self):
max_mem = min(self.mem_cntr, self.mem_size)
batch = np.random.choice(max_mem, self.batch_size, replace=False)
states = torch.FloatTensor(self.state_memory[batch]).to(self.device)
actions = torch.FloatTensor(self.action_memory[batch]).to(self.device)
rewards = torch.FloatTensor(self.reward_memory[batch]).unsqueeze(1).to(self.device)
next_states = torch.FloatTensor(self.next_state_memory[batch]).to(self.device)
dones = torch.FloatTensor(self.terminal_memory[batch]).unsqueeze(1).to(self.device)
return states, actions, rewards, next_states, dones
3.4 增加用于探索的OU噪声
class OUNoise:
def __init__(self, action_dim, mu=0.0, theta=0.2, sigma=0.05):
self.action_dim = action_dim
self.mu = mu
self.theta = theta
self.sigma = sigma
self.state = 0
self.reset()
def reset(self):
self.state = np.ones(self.action_dim) * self.mu
def sample(self):
dx = self.theta * (self.mu - self.state)
dx += self.sigma * np.random.randn(self.action_dim)
self.state += dx
return self.state
3.5 Agent替换为DDPGAgent
1.__init__函数初始化四个网络,actor、critic以及它们的目标网络,增加了OU噪声;
def __init__(self, gamma, tau, input_dims, action_dim, lr,
max_action, batch_size=256, buffer_size=1e6):
self.gamma = gamma
self.tau = tau
self.max_action = max_action
self.batch_size = batch_size
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 初始化网络
self.actor = Actor(input_dims, action_dim, max_action).to(self.device)
self.actor_target = Actor(input_dims, action_dim, max_action).to(self.device)
self.actor_target.load_state_dict(self.actor.state_dict())
self.critic = Critic(input_dims, action_dim).to(self.device)
self.critic_target = Critic(input_dims, action_dim).to(self.device)
self.critic_target.load_state_dict(self.critic.state_dict())
# 优化器 TODO: 为什么lr设置的不一样?
self.actor_optimizer = optim.Adam(self.actor.parameters(), lr=lr)
self.critic_optimizer = optim.Adam(self.critic.parameters(), lr=lr)
self.lr_min = 1e-6
self.actor_loss_value = 0.0
self.actor_lr_scheduler = optim.lr_scheduler.ExponentialLR(
self.actor_optimizer,
gamma=0.995 # 每episode学习率衰减0.5%
)
self.critic_lr_scheduler = optim.lr_scheduler.ExponentialLR(
self.critic_optimizer,
gamma=0.995 # 每episode学习率衰减0.5%
)
# 经验回放
self.memory = ReplayBuffer(buffer_size, batch_size, input_dims, action_dim, self.device)
self.action_memory_for_end = []
self.control_memory_for_end = []
# OU噪声
self.noise = OUNoise(action_dim)
2.learn函数实现;
def learn(self):
if self.memory.mem_cntr < self.batch_size:
return
# 从经验池采样
states, actions, rewards, next_states, dones = self.memory.sample()
# Critic更新
with torch.no_grad(): # 使用 torch.no_grad() 禁用梯度计算
next_actions = self.actor_target.forward(next_states, False, 0.0, self.memory.mem_cntr)
target_q = self.critic_target(next_states, next_actions)
target_q = rewards + (1 - dones) * self.gamma * target_q
current_q = self.critic(states, actions)
# 这是为了稳定训练,类似于DQN中的目标网络机制
critic_loss = F.mse_loss(current_q, target_q) # 缩小预测与目标的差距
self.critic_optimizer.zero_grad()
critic_loss.backward()
torch.nn.utils.clip_grad_norm_(self.critic.parameters(), 1.0) # 添加梯度裁剪
self.critic_optimizer.step()
# Actor更新 TODO: 为什么用梯度上升?
# 通过最大化Q值间接优化策略
actor_actions = self.actor.forward(states, False, 0.0, self.memory.mem_cntr) # a = μ(s|θ^μ)
q_values = self.critic(states, actor_actions) # Q(s, a|θ^Q)
actor_loss = -q_values.mean() # L = -E[Q]
self.actor_loss_value = actor_loss.item()
self.actor_optimizer.zero_grad()
actor_loss.backward() # 自动微分反向传播
self.actor_optimizer.step()
# 学习率调整必须在参数更新之后
if self.memory.mem_cntr % 1000 == 0:
if self.actor_lr_scheduler.get_last_lr()[0] > self.lr_min:
self.actor_lr_scheduler.step() # 调整学习率
if self.critic_lr_scheduler.get_last_lr()[0] > self.lr_min:
self.critic_lr_scheduler.step() # 调整学习率
# 软更新目标网络
self.soft_update(self.actor_target, self.actor)
self.soft_update(self.critic_target, self.critic)
3.6 奖励函数优化
class Car:
def get_reward_optimized333(self, action, done):
# 居中性奖励
lateral_reward = max((self.current_lateral_min_dist / 60 - 0.4) * 2, 0.0)
# action输出转角奖励,大转向惩罚
steer_reward = 0.0
if abs(action[0].item()) >= 2.5:
steer_reward = -0.2 * abs(action[0].item()) + 0.5
# 速度奖励,低速惩罚
speed_reward = 0.0
if self.speed < 12.0:
speed_reward = 0.05 * self.speed - 0.6
else:
speed_reward = (self.speed - 12.0) * 0.04
# 速度基础
speed_base_reward = self.speed / 15.0
# 转角连续性
angle_discount = 1.0
if len(self.angle_memory) >= 5:
self.angle_memory = self.angle_memory[1:]
self.angle_memory.append(action[0].item())
aaa = [0] * 4
if len(self.angle_memory) >= 5:
for i in range(1, 5):
aaa[i - 1] = self.angle_memory[i] - self.angle_memory[i - 1]
bbb = [0] * 3
for j in range(1, 4):
bbb[j - 1] = 1 if aaa[j - 1] * aaa[j] < 0 else 0
if sum(bbb) >= 3 and lateral_reward > 0.0:
angle_discount = 0.8
total_reward = lateral_reward * angle_discount * speed_base_reward + speed_reward + steer_reward
total_reward = max(-1.0, min(total_reward, 1.0))
return total_reward if ~done else -1.0
4.任务思考
1.DDPG的learn代码中,critic在计算loss的时候,为什么使用target_q和current_q的mse_loss作为loss,而actor在计算loss的时候,采用的是critic网络在states和由states经过actor网络输出的action作为输入,经过critic网络输出的q值,取mean和负号之后的结果作为loss?
对于Critic的损失函数,用户提到用的是目标Q值和当前Q值的均方误差(MSE)。这里的目标Q值应该来自目标网络,这是为了稳定训练,类似于DQN中的目标网络机制。具体来说,Critic网络需要学习如何准确估计当前状态和动作的Q值,而目标Q值可能是通过贝尔曼方程计算得到的,即奖励加上折扣后的下一个状态的Q值。使用MSE损失可以让Critic网络的预测值逼近这个目标值,从而学习到正确的Q值。
然后看Actor的损失函数。Actor的目标是选择一个动作,使得Critic给出的Q值最大化。因此,Actor的损失函数应该是负的Q值的均值,因为梯度下降时会最小化这个损失,相当于最大化Q值。也就是说,Actor通过调整策略(生成动作的参数),使得Critic认为这个动作的Q值很高,从而优化策略。
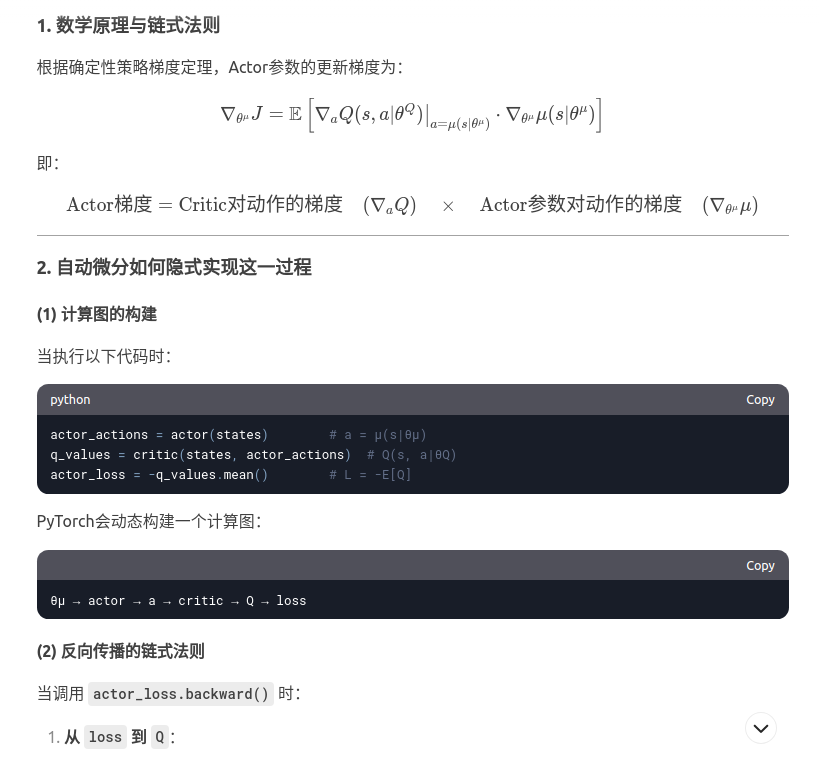
2.自动微分的基本概念:

3.单步reward奖励设置在[0,1]之间和设置在[-1,1]之间,训练效果上会引起很大差异吗?
这个问题来源,是之前在尝试优化奖励函数的时候,单步reward奖励设置在[0,1],发下小车车速越跑越慢的很严重,下面是deepseek的答复。
对于[0,1]的奖励,Critic的Q值估计可能整体较高,而Actor可能在选择动作时没有足够的动力去探索更优的行为,导致保守。相反,在[-1,1]的奖励中,负奖励可以作为惩罚,激励Agent避免不良状态,从而更积极优化策略。
4.DDPG为何没有采用合并损失的方法?(这个问题来源于后续的PPO算法)
算法设计的差异:DDPG基于确定性策略梯度,而PPO是基于随机策略的。确定性策略梯度需要Critic提供准确的Q值梯度,分开更新可以确保Critic先收敛,再指导Actor的更新,这样可能更稳定。
目标网络的使用:DDPG通过目标网络来稳定训练,分开更新允许Critic和Actor的目标网络参数逐步更新,减少即时更新的干扰。如果合并损失,可能需要调整目标网络的更新机制,增加了复杂性。
梯度来源不同:在DDPG中,Actor的更新直接依赖于Critic对动作的梯度,即∇aQ(s,a),而Critic的更新是基于TD误差。这两个梯度来源不同,分开处理可以更明确地控制各自的优化目标。
实践经验:DDPG的设计在实验中被证明有效,分开更新并没有导致严重的梯度不一致问题,可能是因为目标网络和经验回放的缓冲机制缓解了这一问题。
5.完整代码
调试过程中的一些代码保留着,以提些许思考,尤其是奖励函数的版本,感兴趣可以替换get_reward_optimized333之外的奖励函数复现试试action持续输出极限值的问题
from typing import AsyncGenerator
import pygame
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import math
import time
WIDTH = 1920
HEIGHT = 1080
CAR_SIZE_X = 60
CAR_SIZE_Y = 60
BORDER_COLOR = (255, 255, 255, 255) # Color To Crash on Hit
current_generation = 0 # Generation counter
class Actor(nn.Module):
def __init__(self, input_dims, action_dim, max_action):
super(Actor, self).__init__()
self.max_action = max_action
self.fc1 = nn.Linear(input_dims[0], 256)
self.fc2 = nn.Linear(256, 256)
self.fc3 = nn.Linear(256, action_dim)
# 没用
# for layer in [self.fc1, self.fc2]:
# torch.nn.init.xavier_uniform_(layer.weight)
# torch.nn.init.constant_(layer.bias, 0.1)
# 初始化最后一层权重为小范围随机值
torch.nn.init.uniform_(self.fc3.weight, -3e-3, 3e-3)
torch.nn.init.constant_(self.fc3.bias, 0.0)
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def forward(self, state, add_noise, noise, mem_cntr):
x = F.relu(self.fc1(state))
x = F.relu(self.fc2(x))
x = torch.tanh(self.fc3(x)).to(self.device)
if add_noise:
x += torch.tensor(noise).to(self.device)
x = torch.clip(x, torch.tensor([-1.0, -1.0]).to(self.device), torch.tensor([1.0, 1.0]).to(self.device))
steer = x[:, 0] * self.max_action[0]
# speed = (x[:, 1] + 1.0) * self.max_action[1] / 2
speed = x[:, 1] * self.max_action[1]
action = torch.stack([steer, speed], dim=1)
# action = torch.tanh(self.fc3(x)).to(self.device) * torch.tensor(self.max_action).to(self.device)
return action
class Critic(nn.Module):
def __init__(self, input_dims, action_dim):
super(Critic, self).__init__()
self.fc1 = nn.Linear(input_dims[0] + action_dim, 256)
self.fc2 = nn.Linear(256, 256)
self.fc3 = nn.Linear(256, 1)
def forward(self, state, action):
x = torch.cat([state, action], dim=1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
q_value = self.fc3(x)
return q_value
class ReplayBuffer:
def __init__(self, max_mem_size, batch_size, input_dims, action_dim, device):
self.mem_size = max_mem_size
self.batch_size = batch_size
self.mem_cntr = 0
self.device = device
self.state_memory = np.zeros((self.mem_size, *input_dims), dtype=np.float32)
self.action_memory = np.zeros((self.mem_size, action_dim), dtype=np.float32)
self.reward_memory = np.zeros(self.mem_size, dtype=np.float32)
self.next_state_memory = np.zeros((self.mem_size, *input_dims), dtype=np.float32)
self.terminal_memory = np.zeros(self.mem_size, dtype=bool)
def store(self, state, action, reward, next_state, done):
index = self.mem_cntr % self.mem_size
self.state_memory[index] = state
self.action_memory[index] = action
self.reward_memory[index] = reward
self.next_state_memory[index] = next_state
self.terminal_memory[index] = done
self.mem_cntr += 1
def sample(self):
max_mem = min(self.mem_cntr, self.mem_size)
batch = np.random.choice(max_mem, self.batch_size, replace=False)
states = torch.FloatTensor(self.state_memory[batch]).to(self.device)
actions = torch.FloatTensor(self.action_memory[batch]).to(self.device)
rewards = torch.FloatTensor(self.reward_memory[batch]).unsqueeze(1).to(self.device)
next_states = torch.FloatTensor(self.next_state_memory[batch]).to(self.device)
dones = torch.FloatTensor(self.terminal_memory[batch]).unsqueeze(1).to(self.device)
return states, actions, rewards, next_states, dones
class OUNoise:
def __init__(self, action_dim, mu=0.0, theta=0.2, sigma=0.05):
self.action_dim = action_dim
self.mu = mu
self.theta = theta
self.sigma = sigma
self.state = 0
self.reset()
def reset(self):
self.state = np.ones(self.action_dim) * self.mu
def sample(self):
dx = self.theta * (self.mu - self.state)
dx += self.sigma * np.random.randn(self.action_dim)
self.state += dx
return self.state
class DDPGAgent:
def __init__(self, gamma, tau, input_dims, action_dim, lr,
max_action, batch_size=256, buffer_size=1e6):
self.gamma = gamma
self.tau = tau
self.max_action = max_action
self.batch_size = batch_size
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 初始化网络
self.actor = Actor(input_dims, action_dim, max_action).to(self.device)
self.actor_target = Actor(input_dims, action_dim, max_action).to(self.device)
self.actor_target.load_state_dict(self.actor.state_dict())
self.critic = Critic(input_dims, action_dim).to(self.device)
self.critic_target = Critic(input_dims, action_dim).to(self.device)
self.critic_target.load_state_dict(self.critic.state_dict())
# 优化器 TODO: 为什么lr设置的不一样?
self.actor_optimizer = optim.Adam(self.actor.parameters(), lr=lr)
self.critic_optimizer = optim.Adam(self.critic.parameters(), lr=lr)
self.lr_min = 1e-6
self.actor_loss_value = 0.0
self.actor_lr_scheduler = optim.lr_scheduler.ExponentialLR(
self.actor_optimizer,
gamma=0.995 # 每episode学习率衰减0.5%
)
self.critic_lr_scheduler = optim.lr_scheduler.ExponentialLR(
self.critic_optimizer,
gamma=0.995 # 每episode学习率衰减0.5%
)
# 经验回放
self.memory = ReplayBuffer(buffer_size, batch_size, input_dims, action_dim, self.device)
self.action_memory_for_end = []
self.control_memory_for_end = []
# OU噪声
self.noise = OUNoise(action_dim)
def select_action(self, state, episode, add_noise=True):
state = torch.FloatTensor(state).unsqueeze(0).to(self.device)
action = self.actor.forward(state, add_noise, self.noise.sample(), self.memory.mem_cntr).cpu().data.numpy().flatten()
return np.clip(action, -1.0 * torch.tensor(self.max_action), self.max_action)
def soft_update(self, target, source):
for target_param, param in zip(target.parameters(), source.parameters()):
target_param.data.copy_(self.tau * param.data + (1.0 - self.tau) * target_param.data)
def learn(self):
if self.memory.mem_cntr < self.batch_size:
return
# 从经验池采样
states, actions, rewards, next_states, dones = self.memory.sample()
# Critic更新
with torch.no_grad(): # 使用 torch.no_grad() 禁用梯度计算
next_actions = self.actor_target.forward(next_states, False, 0.0, self.memory.mem_cntr)
target_q = self.critic_target(next_states, next_actions)
target_q = rewards + (1 - dones) * self.gamma * target_q
current_q = self.critic(states, actions)
# 这是为了稳定训练,类似于DQN中的目标网络机制
critic_loss = F.mse_loss(current_q, target_q) # 缩小预测与目标的差距
# 在Critic损失中添加正则项---没用
# q_reg = 0.001 * torch.mean(current_q ** 2) # 抑制Q值过大
# critic_loss = F.mse_loss(current_q, target_q) + q_reg
# print("current_q: ", current_q)
# print("critic_loss: ", critic_loss.item())
self.critic_optimizer.zero_grad()
critic_loss.backward()
torch.nn.utils.clip_grad_norm_(self.critic.parameters(), 1.0) # 添加梯度裁剪
# torch.nn.utils.clip_grad_norm_(self.critic.parameters(), 0.00000005) # 添加梯度裁剪
self.critic_optimizer.step()
# Actor更新 TODO: 为什么用梯度上升?
# 通过最大化Q值间接优化策略
actor_actions = self.actor.forward(states, False, 0.0, self.memory.mem_cntr) # a = μ(s|θ^μ)
q_values = self.critic(states, actor_actions) # Q(s, a|θ^Q)
actor_loss = -q_values.mean() # L = -E[Q]
# 梯度惩罚方法,解决action输出极限值
# grad_penalty = (actor_actions ** 2).mean()
# actor_loss = actor_loss + 0.4 * grad_penalty
# actor_loss系数惩罚方法,解决action输出极限值
# grad_penalty = 1e-10
# actor_loss = actor_loss * grad_penalty
# 下面是当时的一些调试代码,没有删掉
# **限制动作幅度**:惩罚项直接对动作的平方进行惩罚,鼓励Actor输出较小的动作值,避免极端值。
# if self.memory.mem_cntr % 2000 == 0:
# self.steer_penalty_coeff = max(self.steer_penalty_coeff - 0.0004, 0.1)
# self.speed_penalty_coeff = max(self.speed_penalty_coeff - 0.0004, 0.05)
# grad_penalty = self.steer_penalty_coeff * (actor_actions[0] ** 2).mean() + \
# self.speed_penalty_coeff * (actor_actions[1] ** 2).mean()
# actor_loss = -self.critic(states, actor_actions).mean() + grad_penalty
# grad_penalty_1 = grad_penalty_0
# action1_mean = torch.sqrt(actor_actions[:, 1] ** 2).mean()
# if action1_mean.item() < 10.0:
# grad_penalty_1 = 0.05 * action1_mean.item() + 0.5
# elif action1_mean.item() >= 15.0:
# # grad_penalty_1 = -0.1 * action1_mean.item() + 2.5
# grad_penalty_1 = 0.001
# print("111: ", action1_mean, grad_penalty_1)
#
# if self.memory.mem_cntr % 2000 == 0:
# # self.steer_penalty_coeff = max(self.steer_penalty_coeff - 0.0004, 0.1)
# self.speed_penalty_coeff = max(self.speed_penalty_coeff - 0.001, 0.05)
# grad_penalty = self.steer_penalty_coeff * (actor_actions[:, 0] ** 2).mean() + \
# self.speed_penalty_coeff * (actor_actions[:, 1] ** 2).mean()
#
# actor_loss_org = -self.critic(states, actor_actions).mean()
# # print("*****: ", actor_loss_org * grad_penalty_0 * grad_penalty_1)
# # print("-----: ", actor_loss_org + grad_penalty)
# actor_loss = max(actor_loss_org * grad_penalty_0 * grad_penalty_1, actor_loss_org + grad_penalty)
# actor_loss = actor_loss_org + (actor_actions ** 2).mean()
# actor_loss = actor_loss_org * (1 / grad_penalty_0) * (1 / grad_penalty_1)
# actor_loss = actor_loss_org * grad_penalty_0 * grad_penalty_1
self.actor_loss_value = actor_loss.item()
# print("+++++: ", actor_loss.item(), actor_loss_org.item())
# print("+++++: ", actor_loss.item())
self.actor_optimizer.zero_grad()
actor_loss.backward() # 自动微分反向传播
# 严格的梯度裁剪方法,解决action输出极限值
# torch.nn.utils.clip_grad_norm_(self.actor.parameters(), 0.000000005)
self.actor_optimizer.step()
# 学习率调整必须在参数更新之后
if self.memory.mem_cntr % 1000 == 0:
if self.actor_lr_scheduler.get_last_lr()[0] > self.lr_min:
self.actor_lr_scheduler.step() # 调整学习率
# print("lr updated!, actor current lr = {}".format(self.actor_lr_scheduler.get_last_lr()[0]))
if self.critic_lr_scheduler.get_last_lr()[0] > self.lr_min:
self.critic_lr_scheduler.step() # 调整学习率
# print("lr updated!, critic current lr = {}".format(self.critic_lr_scheduler.get_last_lr()[0]))
# print("actor_loss: {}, mem_cntr: {}".format(actor_loss.item(), self.memory.mem_cntr))
# 软更新目标网络
self.soft_update(self.actor_target, self.actor)
self.soft_update(self.critic_target, self.critic)
class Car:
def __init__(self, boundary_x, boundary_y, num_radar):
# Load Car Sprite and Rotate
self.sprite = pygame.image.load('car.png').convert() # Convert Speeds Up A Lot
self.sprite = pygame.transform.scale(self.sprite, (CAR_SIZE_X, CAR_SIZE_Y))
self.rotated_sprite = self.sprite
# self.position = [690, 740] # Starting Position
self.position = [830, 920] # Starting Position
self.angle = 0
self.angle_memory = []
self.speed = 0
self.speed_memory = []
self.speed_set = False # Flag For Default Speed Later on
self.center = [self.position[0] + CAR_SIZE_X / 2, self.position[1] + CAR_SIZE_Y / 2] # Calculate Center
self.radars = [[(0, 0), 60]] * num_radar # List For Sensors / Radars
self.drawing_radars = [] # Radars To Be Drawn
self.current_lateral_min_dist = 60
self.alive = True # Boolean To Check If Car is Crashed
self.distance = 0 # Distance Driven
self.time = 0 # Time Passed
self.width = 0
self.height = 0
self.boundary_x = boundary_x
self.boundary_y = boundary_y
def draw(self, screen):
screen.blit(self.rotated_sprite, self.position) # Draw Sprite
self.draw_radar(screen) # OPTIONAL FOR SENSORS
def draw_radar(self, screen):
# Optionally Draw All Sensors / Radars
for radar in self.radars:
position = radar[0]
pygame.draw.line(screen, (0, 255, 0), self.center, position, 1)
pygame.draw.circle(screen, (0, 255, 0), position, 5)
def check_collision(self, game_map):
self.alive = True
for point in self.corners:
# If Any Corner Touches Border Color -> Crash
# Assumes Rectangle
if game_map.get_at((int(point[0]), int(point[1]))) == BORDER_COLOR:
self.alive = False
break
def check_radar(self, degree, game_map):
length = 0
x = int(self.center[0] + math.cos(math.radians(360 - (self.angle + degree))) * length)
y = int(self.center[1] + math.sin(math.radians(360 - (self.angle + degree))) * length)
# While We Don't Hit BORDER_COLOR AND length < 300 (just a max) -> go further and further
while not game_map.get_at((x, y)) == BORDER_COLOR and length < 300:
length = length + 1
x = int(self.center[0] + math.cos(math.radians(360 - (self.angle + degree))) * length)
y = int(self.center[1] + math.sin(math.radians(360 - (self.angle + degree))) * length)
# Calculate Distance To Border And Append To Radars List TODO: update dist calculate
dist = int(math.sqrt(math.pow(x - self.center[0], 2) + math.pow(y - self.center[1], 2)))
self.radars.append([(x, y), dist])
def update(self, game_map):
# Set The Speed To 20 For The First Time
# Only When Having 4 Output Nodes With Speed Up and Down
if not self.speed_set:
self.speed = 10
self.speed_set = True
self.width, self.height = game_map.get_size()
# Get Rotated Sprite And Move Into The Right X-Direction
# Don't Let The Car Go Closer Than 20px To The Edge
self.rotated_sprite = self.rotate_center(self.sprite, self.angle)
self.position[0] += math.cos(math.radians(360 - self.angle)) * self.speed
self.position[0] = max(self.position[0], 20)
self.position[0] = min(self.position[0], WIDTH - 120)
# Increase Distance and Time
self.distance += self.speed
self.time += 1
# Same For Y-Position
self.position[1] += math.sin(math.radians(360 - self.angle)) * self.speed
self.position[1] = max(self.position[1], 20)
self.position[1] = min(self.position[1], WIDTH - 120)
# Calculate New Center
self.center = [int(self.position[0]) + CAR_SIZE_X / 2, int(self.position[1]) + CAR_SIZE_Y / 2]
# print("center: {}".format(self.center))
# Calculate Four Corners
# Length Is Half The Side
length = 0.5 * CAR_SIZE_X
left_top = [self.center[0] + math.cos(math.radians(360 - (self.angle + 30))) * length,
self.center[1] + math.sin(math.radians(360 - (self.angle + 30))) * length]
right_top = [self.center[0] + math.cos(math.radians(360 - (self.angle + 150))) * length,
self.center[1] + math.sin(math.radians(360 - (self.angle + 150))) * length]
left_bottom = [self.center[0] + math.cos(math.radians(360 - (self.angle + 210))) * length,
self.center[1] + math.sin(math.radians(360 - (self.angle + 210))) * length]
right_bottom = [self.center[0] + math.cos(math.radians(360 - (self.angle + 330))) * length,
self.center[1] + math.sin(math.radians(360 - (self.angle + 330))) * length]
self.corners = [left_top, right_top, left_bottom, right_bottom]
# Check Collisions And Clear Radars
self.check_collision(game_map)
self.radars.clear()
# From -90 To 120 With Step-Size 45 Check Radar
for d in range(-120, 126, 15): # -90,-45,0,45,90z
self.check_radar(d, game_map)
def get_data(self):
# Get Distances To Border
return_values = [0] * len(self.radars)
self.current_lateral_min_dist = 60
for i, radar in enumerate(self.radars):
return_values[i] = radar[1] / 300.0
if radar[1] < self.current_lateral_min_dist:
self.current_lateral_min_dist = radar[1]
angle_rad = np.deg2rad(self.angle)
return_values = return_values + [self.current_lateral_min_dist / 30,
np.clip(self.speed / 20.0, 0.0, 1.0),
np.sin(angle_rad), np.cos(angle_rad)]
return return_values
def is_alive(self):
# Basic Alive Function
return self.alive
# TODO: DDPG奖励函数需要重新设计
def get_reward_optimized(self):
# 居中性
lateral_reward = 1.0
# print(self.current_lateral_min_dist)
if self.current_lateral_min_dist / 60 > 0.5:
lateral_reward = self.current_lateral_min_dist / 60
elif self.current_lateral_min_dist / 60 < 0.4:
lateral_reward = -0.5
else:
lateral_reward = 0.0
# 速度基础
speed_base_reward = self.speed / 15.0
# 速度连续性
# if len(self.speed_memory) >= 4:
# self.speed_memory = self.speed_memory[1:]
# self.speed_memory.append(self.speed)
# speed_up_discount = 1.0
# if self.speed_memory[-1] - self.speed_memory[0] >= 3 and lateral_reward > 0.0:
# speed_up_discount = -0.5
# elif self.speed_memory[-1] - self.speed_memory[0] >= 2 and lateral_reward > 0.0:
# speed_up_discount = 0.7
# 转角连续性
angle_discount = 1.0
if len(self.angle_memory) >= 5:
self.angle_memory = self.angle_memory[1:]
self.angle_memory.append(self.angle)
aaa = [0] * 4
if len(self.angle_memory) >= 5:
for i in range(1, 5):
aaa[i-1] = self.angle_memory[i] - self.angle_memory[i-1]
bbb = [0] * 3
for j in range(1, 4):
bbb[j-1] = 1 if aaa[j-1] * aaa[j] < 0 else 0
if sum(bbb) >= 3 and lateral_reward > 0.0:
angle_discount = 0.8
# print(lateral_reward, speed_up_discount, angle_discount, " ====== ", self.speed_memory)
return lateral_reward * speed_base_reward * angle_discount
# return lateral_reward * speed_base_reward * angle_discount
def get_reward_optimized111(self):
# 1. 居中性奖励(平滑指数衰减)
lateral_norm = self.current_lateral_min_dist / 60
lateral_reward = math.exp(-2 * (1 - lateral_norm) ** 2) # 高斯型奖励
# 2. 速度奖励(安全范围内奖励)
safe_speed = 8 # 设定安全速度阈值
speed_reward = np.clip(self.speed / safe_speed, 0, 1) # 线性奖励
# 3. 方向稳定性奖励(惩罚剧烈转向)
angle_change = np.abs(self.angle - np.mean(self.angle_memory[-5:]))
steering_penalty = -0.1 * np.tanh(angle_change / 10) # 平滑惩罚
# 4. 生存时间奖励
survival_reward = 0.01 # 每帧存活奖励
return 100 * (lateral_reward * speed_reward + steering_penalty + survival_reward)
def get_reward_optimized222(self, action):
# 居中性
# lateral_reward = 1.0
# print(self.current_lateral_min_dist)
# if self.current_lateral_min_dist / 60 > 0.5:
# lateral_reward = self.current_lateral_min_dist / 60
# elif self.current_lateral_min_dist / 60 < 0.4:
# lateral_reward = -0.5
# else:
# lateral_reward = 0.0
lateral_reward = (self.current_lateral_min_dist / 60 - 0.5) * 2
# print("lateral_reward: ", lateral_reward)
# 速度基础
speed_base_reward = self.speed / 15.0
# 转角连续性
angle_discount = 1.0
if len(self.angle_memory) >= 5:
self.angle_memory = self.angle_memory[1:]
self.angle_memory.append(self.angle)
aaa = [0] * 4
if len(self.angle_memory) >= 5:
for i in range(1, 5):
aaa[i-1] = self.angle_memory[i] - self.angle_memory[i-1]
bbb = [0] * 3
for j in range(1, 4):
bbb[j-1] = 1 if aaa[j-1] * aaa[j] < 0 else 0
if sum(bbb) >= 3 and lateral_reward > 0.0:
angle_discount = 0.8
# steer_penalty = 0.0
# if abs(action[0].item()) >= 2.5:
# steer_penalty = -0.36 * abs(action[0].item()) + 0.8
steer_penalty = 0.0
if abs(action[0].item()) >= 2.5:
steer_penalty = -0.2 * abs(action[0].item()) + 0.5
speed_penalty = 1.0
if self.speed < 10.0:
speed_penalty = 0.1 * self.speed - 1.0
elif self.speed >= 15.0:
speed_penalty = -0.1 * self.speed + 1.5
total_reward = 1.0 * lateral_reward + 0.5 * speed_penalty + 1.5 * steer_penalty
# print(lateral_reward, speed_up_discount, angle_discount, " ====== ", self.speed_memory)
# return 100 * lateral_reward * speed_base_reward * angle_discount
# return (lateral_reward * speed_base_reward * angle_discount) if self.speed > 1.0 else -1.0
# print("speed_penalty: {}, steer_penalty: {}, speed: {}, steer: {}".format(speed_penalty, steer_penalty,
# self.speed, action[0].item()))
# return lateral_reward * speed_base_reward * angle_discount + speed_penalty + steer_penalty
return total_reward
def get_reward_optimized333(self, action, done):
# 居中性奖励
lateral_reward = max((self.current_lateral_min_dist / 60 - 0.4) * 2, 0.0)
# action输出转角奖励
steer_reward = 0.0
if abs(action[0].item()) >= 2.5:
steer_reward = -0.2 * abs(action[0].item()) + 0.5
# 速度奖励
speed_reward = 0.0
if self.speed < 12.0:
speed_reward = 0.05 * self.speed - 0.6
else:
speed_reward = (self.speed - 12.0) * 0.04
# elif self.speed >= 16.0:
# speed_reward = -0.15 * self.speed + 2.4
# 速度基础
speed_base_reward = self.speed / 15.0
# 转角连续性
angle_discount = 1.0
if len(self.angle_memory) >= 5:
self.angle_memory = self.angle_memory[1:]
self.angle_memory.append(action[0].item())
aaa = [0] * 4
if len(self.angle_memory) >= 5:
for i in range(1, 5):
aaa[i - 1] = self.angle_memory[i] - self.angle_memory[i - 1]
bbb = [0] * 3
for j in range(1, 4):
bbb[j - 1] = 1 if aaa[j - 1] * aaa[j] < 0 else 0
if sum(bbb) >= 3 and lateral_reward > 0.0:
angle_discount = 0.8
total_reward = lateral_reward * angle_discount * speed_base_reward + speed_reward + steer_reward
# total_reward = lateral_reward * angle_discount * speed_base_reward + steer_reward
# print("total_reward: ", total_reward)
total_reward = max(-1.0, min(total_reward, 1.0))
# return total_reward
return total_reward if ~done else -1.0
def rotate_center(self, image, angle):
# Rotate The Rectangle
rectangle = image.get_rect()
rotated_image = pygame.transform.rotate(image, angle)
rotated_rectangle = rectangle.copy()
rotated_rectangle.center = rotated_image.get_rect().center
rotated_image = rotated_image.subsurface(rotated_rectangle).copy()
return rotated_image
def train():
pygame.init()
screen = pygame.display.set_mode((WIDTH, HEIGHT))
game_map = pygame.image.load('map.png').convert() # Convert Speeds Up A Lot
clock = pygame.time.Clock()
num_radar = 17
action_max_limit = [5.0, 2.0]
agent = DDPGAgent(gamma=0.99, tau=0.05, input_dims=[num_radar + 4], action_dim=2, max_action=action_max_limit,
batch_size=128, buffer_size=100000, lr=0.0005)
scores = []
average_scores = []
distance = []
average_distance = []
alive_counts = []
average_alive_counts = []
actor_loss_values = []
average_actor_loss = []
n_games = 500
for i in range(n_games):
car = Car([], [], num_radar)
done = False
score = 0
observation = car.get_data()
alive_count = 0
start_time = time.time()
while not done:
action = agent.select_action(observation, i)
if len(agent.action_memory_for_end) >= 4:
agent.action_memory_for_end = agent.action_memory_for_end[1:]
agent.action_memory_for_end.append([round(action[0].item(), 2), round(action[1].item(), 2)])
car.angle += action[0].item()
car.angle = car.angle % 360
car.speed = min(max(car.speed + action[1].item(), 0.0), 20.0)
# car.angle += action[0].item()
# car.angle = car.angle % 360
# car.speed = action[1].item()
if len(agent.control_memory_for_end) >= 4:
agent.control_memory_for_end = agent.control_memory_for_end[1:]
agent.control_memory_for_end.append([round(car.angle, 2), round(car.speed, 2)])
screen.blit(game_map, (0, 0))
car.update(game_map)
car.draw(screen)
pygame.display.flip()
clock.tick(60)
done = not car.is_alive()
observation_, reward = car.get_data(), car.get_reward_optimized333(action, done)
# observation_, reward, done = car.get_data(), car.get_reward_optimized333(action), not car.is_alive()
score += reward
# agent.store_transition(observation, action, reward, observation_, done)
agent.memory.store(observation, action, reward, observation_, done)
agent.learn()
observation = observation_
alive_count += 1
end_time = time.time()
duration = end_time - start_time
# 记录平均score
scores.append(score)
avg_score = np.mean(scores[-100:])
average_scores.append(avg_score)
# 记录平均distance
distance.append(car.distance)
avg_distance = np.mean(distance[-100:])
average_distance.append(avg_distance)
# 记录平均alive_counts
alive_counts.append(alive_count)
avg_alive_count = np.mean(alive_counts[-100:])
average_alive_counts.append(avg_alive_count)
# 记录平均actor_loss
actor_loss_values.append(agent.actor_loss_value)
avg_actor_loss = np.mean(actor_loss_values[-100:])
average_actor_loss.append(avg_actor_loss)
# 打印当前学习率(调试用)
current_actor_lr = agent.actor_lr_scheduler.get_last_lr()[0]
current_critic_lr = agent.critic_lr_scheduler.get_last_lr()[0]
print(
f'episode: {i}, duration= {round(duration, 2)}, score= {round(score, 2)}, actor_lr= {current_actor_lr},'
f' critic_lr= {current_critic_lr}, dist= {round(car.distance, 2)}'
f' avg_dist= {round(avg_distance, 2)}, avg_score= {round(avg_score, 2)},'
f' avg_actor_loss= {round(avg_actor_loss, 2)}, alive_count= {alive_count},'
f' mem_cntr= {agent.memory.mem_cntr}')
print("------action_memory_for_end: ", agent.action_memory_for_end)
print("------control_memory_for_end: ", agent.control_memory_for_end)
plt.subplot(1, 3, 1)
plt.plot([i for i in range(0, n_games)], average_scores)
plt.title("average_scores")
plt.subplot(1, 3, 2)
plt.plot([i for i in range(0, n_games)], average_distance)
plt.title("average_distance")
plt.subplot(1, 3, 3)
plt.plot([i for i in range(0, n_games)], average_alive_counts)
plt.title("average_alive_counts")
plt.show()
if __name__ == '__main__':
train()
6.参考
DDPG或TD3算法训练时总是输出边界值问题记录
强化学习过程中为什么action最后总会收敛到设定的行为空间的边界处?
深度强化学习调参技巧:以D3QN、TD3、PPO、SAC算法为例(有空再添加图片)

















 1005
1005

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









