









1 要点
1.1 概述
目的:提出一个用于弱监督全幻灯片 (WSI) 分类的实例级多示例 (MIL) 框架,其动机和框架如图1:
- 结合对比学习和原型学习,以实验准确的实例和包分类;
- 提出了一个实例级弱监督对比学习算法,其通过原型学习来生成准确的实例伪标签;
- 提出了一个弱监督对比学习、原型学习,以及实例分类器训练的联合训练策略。

1.2 代码
暂无。
1.3 引用
@article{Qu:2023:110,
author = {Lin Hao Qu and Ying Fan Ma and Xiao Yuan Luo and Man Ning Wang and Zhi Jian Song},
title = {Rethinking multiple instance learning for whole slide image classification: A good instance classifier is all you need},
journal = {{IEEE TMI}},
pages = {1--10},
year = {2023}
}
2 方法
2.1 一些符号和问题声明
| 符号 | 含义 |
|---|---|
| X = { X 1 , X 2 , … , X N } X=\{X_1,X_2,\dots,X_N \} X={X1,X2,…,XN} | N N N个WSI |
| X i = { x i , j , j = 1 , 2 , … , n i } X_i=\{x_{i,j},j=1,2,\dots,n_i\} Xi={xi,j,j=1,2,…,ni} | 无交叠区块 |
| Y i ∈ { 0 , 1 } Y_i\in\{ 0,1 \} Yi∈{0,1} | 包标签 |
目标:基于标准MIL假设,预测每个包以及实例的标签。
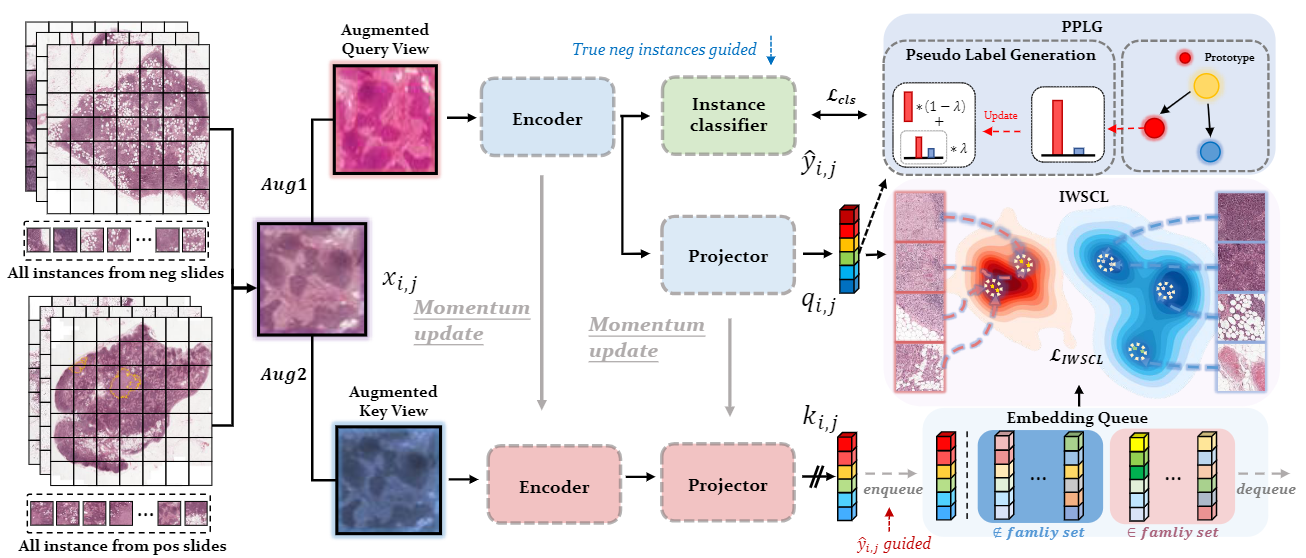
2.2 方法框架
图3展示了所提出INS框架的总体流程,其目标是使用实例集弱监督对比学习 (IWSCL) 和基于提案的伪标签生成 (PPLG) 来训练一个实例级分类器:
- 在每轮迭代中,首先随机从所有实例中选择一个实例 x i , j x_{i,j} xi,j,然后使用两种增强方法生成query视角和key视角;
- 在query视角分支中,将其输入到编码器,再分别传递给实例分类器和基于MLP (全连接) 的投影头,以分别获取预测类别 y ^ i , j ∈ R 2 \hat{y}_{i,j}\in\mathbb{R}^2 y^i,j∈R2 (一个表示正负的one-hot向量) 和特征嵌入 q i , j ∈ R d q_{i,j}\in\mathbb{R}^d qi,j∈Rd;
- 在key视角,同理获得特征嵌入 k i , j ∈ R d k_{i,j}\in\mathbb{R}^d ki,j∈Rd,其所需的编码器和投影头分别是基于动量方法对query视角下编码器和投影头的更新;
- 受MOCO和Pico方法的启发,使用一个嵌入队列来存储key视角下的特征嵌入及相应的预测类别。然后使用当前实例的 y ^ i , j , q i , j , k i j \hat{y}_{i,j},q_{i,j},k_{ij} y^i,j,qi,j,kij和来自先前迭代的嵌入队列来执行IWSCL;
- 对于 q i , j q_{i,j} qi,j,将嵌入队列中具有相同预测类别的实例嵌入拉近,其它的则拉远;在PPLG模块中,在模型训练时,保留两个代表特征向量作为正原型和负原型;
- 使用来自先前迭代的 q i , j q_{i,j} qi,j和原型向量生成伪标签 x i . j x_{i.j} xi.j;
- 使用 y ^ i , j \hat{y}_{i,j} y^i,j和 q i , j q_{i,j} qi,j,以及获得的 x i , j x_{i,j} xi,j在当前迭代结束时训练实例分类器;
- 在训练时,为了防止包级别退化,添加一个包级别约束损失。
2.3 IWSCL
对比学习中最重要的步骤是构建正负样本集,然后通过拉近正样本和推离负样本来学习其健壮性特征表示。为了在MIL设置下区分正实例和负实例,本文使用family和non-family样本集来分别表示对比学习中的正负样本集。
在MIL中,所有负包中的实例天然属于同一个样本集。这样的弱标签信息可以有效地引导实例级对比学习。具体地,在训练时使用一个大的嵌入队列来存储实例的特征嵌入 k i , j k_{i,j} ki,j和它们的预测类别 y ^ i , j \hat{y}_{i,j} y^i,j。注意对于负包中的实例,将直接分配负类,即 y ^ i , j = 0 \hat{y}_{i,j}=0 y^i,j=0。
2.3.1 Family和non-family样本选择
对于实例 x i , j x_{i,j} xi,j和其嵌入 q i , j q_{i,j} qi,j,使用实例分类器的预测类别 y ^ i , j \hat{y}_{i,j} y^i,j和嵌入队列来构建family集 F ( q i , j ) F(q_{i,j}) F(qi,j)和non-family集 F ′ ( q i , j ) F'(q_{i,j}) F′(qi,j),然后基于 q i , j q_{i,j} qi,j执行对比学习:
- F ( q i , j ) F(q_{i,j}) F(qi,j)包含两部分,第一部分包含嵌入 q i , j q_{i,j} qi,j和 k i , j k_{i,j} ki,j,第二部分包含嵌入队列中类别标签等于 y ^ i , j \hat{y}_{i,j} y^i,j的的嵌入;
- F ′ ( q i , j ) F'(q_{i,j}) F′(qi,j)包含嵌入队列中其它类别标签的嵌入。
形式上,给定一个小批次,令所有的query和key嵌入表示为
B
q
B_q
Bq和
B
k
B_k
Bk,嵌入队列表示为
Q
Q
Q。对于实例
(
x
i
,
j
,
q
i
,
j
,
y
^
i
,
j
)
(x_{i,j},q_{i,j},\hat{y}_{i,j})
(xi,j,qi,j,y^i,j),其对比嵌入池定义为:
P
(
q
i
,
j
)
=
(
B
q
∪
B
k
∪
Q
)
∖
{
q
i
,
j
}
(2)
\tag{2} P(q_{i,j})=(B_q\cup B_k\cup Q)\setminus\{ q_{i,j} \}
P(qi,j)=(Bq∪Bk∪Q)∖{qi,j}(2)在
P
(
q
i
,
j
)
P(q_{i,j})
P(qi,j)中,
F
(
q
i
,
j
)
F(q_{i,j})
F(qi,j)和
F
′
(
q
i
,
j
)
F'(q_{i,j})
F′(qi,j)被定义为:
F
(
q
i
,
j
)
=
{
m
∣
m
∈
P
(
q
i
,
j
)
,
y
^
m
=
y
^
i
,
j
}
(3)
\tag{3} F(q_{i,j})=\{ m|m\in P(q_{i,j}),\hat{y}_m=\hat{y}_{i,j} \}
F(qi,j)={m∣m∈P(qi,j),y^m=y^i,j}(3)
F
′
(
q
i
,
j
)
=
P
(
q
i
,
j
)
∖
F
(
q
i
,
j
)
(4)
\tag{4} F'(q_{i,j})=P(q_{i,j})\setminus F(q_{i,j})
F′(qi,j)=P(qi,j)∖F(qi,j)(4)
2.3.2 对比损失
基于嵌入
q
i
,
j
q_{i,j}
qi,j所构建的对比损失如下:
L
I
W
S
C
L
(
q
i
,
j
)
=
1
∣
F
(
q
i
,
j
)
∣
∑
k
+
∈
F
(
q
i
,
j
)
log
exp
(
q
i
,
j
⊤
k
+
/
τ
)
∑
k
−
∈
F
′
(
q
i
,
j
)
exp
(
q
i
,
j
⊤
k
−
/
τ
)
(5)
\tag{5} \mathcal{L}_{IWSCL}(q_{i,j})=\frac{1}{|F(q_{i,j})|}\sum_{k_+\in F(q_{i,j})}\log\frac{\exp(q_{i,j}^\top k_+/\tau)}{\sum_{k_-}\in F'(q_{i,j})\exp(q_{i,j}^\top k_-/\tau)}
LIWSCL(qi,j)=∣F(qi,j)∣1k+∈F(qi,j)∑log∑k−∈F′(qi,j)exp(qi,j⊤k−/τ)exp(qi,j⊤k+/τ)(5)其中
τ
≤
0
\tau\leq0
τ≤0是温度参数。
2.3.3 嵌入队列更新
在每次迭代结束时,当前实例的动量嵌入 k i , j k_{i,j} ki,j及其预测标签 y ^ i , j \hat{y}_{i,j} y^i,j将被添加,最先加入的嵌入及其标签则被移除。
2.4 基于提案的伪标签生成
提案学习用于给实例分配更准确的伪标签。对此,保留了两个代表特征向量,一个用于负实例,另一个则用于正实例,其记为 μ r ∈ R d , r = 0 , 1 \mu_r\in\mathbb{R}^d,r=0,1 μr∈Rd,r=0,1。伪标签的生成和原型的更新通过真负实例和实例分类器引导。
2.4.1 伪标签生成
如果当前实例
x
i
,
j
x_{i,j}
xi,j来自于正包,计算其与两个原型向量
μ
r
\mu_r
μr的内积,然后选择具有最小特征距离的伪标签作为更新方向
z
i
j
∈
R
2
z_{i_j\in\mathbb{R}^2}
zij∈R2。接下来,使用一个移动更新策略来更新实例的伪标签:
s
i
,
j
=
α
s
i
,
j
+
(
1
−
α
)
z
i
,
j
,
z
i
,
j
=
o
n
e
h
o
t
(
arg max
q
i
,
j
⊤
μ
r
)
,
(6)
\tag{6} s_{i,j}=\alpha s_{i,j}+(1-\alpha)z_{i,j},z_{i,j}=onehot(\argmax q_{i,j}^\top\mu_r),
si,j=αsi,j+(1−α)zi,j,zi,j=onehot(argmaxqi,j⊤μr),(6)其中
α
\alpha
α是用于移动更新的系数,
o
n
e
h
o
t
onehot
onehot用于将值转换为2维one-hot编码。
2.4.2 原型更新
如果当前实例
x
i
j
x_{ij}
xij来自正包,则根据其预测类别
y
^
i
,
j
\hat{y}_{i,j}
y^i,j和嵌入
q
i
,
j
q_{i,j}
qi,j来更新提案:
μ
c
=
N
o
r
m
(
β
μ
c
+
(
1
−
β
)
q
i
,
j
)
,
c
=
arg max
y
^
i
,
j
(7)
\tag{7} \mu_c=Norm(\beta\mu_c+(1-\beta)q_{i,j}),c=\argmax\hat{y}_{i,j}
μc=Norm(βμc+(1−β)qi,j),c=argmaxy^i,j(7)其中
β
\beta
β与
α
\alpha
α类似,
N
o
r
m
Norm
Norm是标准化函数。
如果当前实例
x
i
,
j
x_{i,j}
xi,j来自负包,则更新负原型为:
μ
c
=
N
o
r
m
(
β
μ
0
+
(
1
−
β
)
q
i
,
j
)
(8)
\tag{8} \mu_c=Norm(\beta\mu_0+(1-\beta)q_{i,j})
μc=Norm(βμ0+(1−β)qi,j)(8)
2.4.3 实例分类损失
训练实例分类器时,使用分类器的预测值
p
i
,
j
∈
R
2
p_{i,j}\in\mathbb{R}^2
pi,j∈R2和伪标签
s
i
,
j
s_{i,j}
si,j的交叉熵损失:
L
c
l
s
=
C
E
(
p
i
,
j
,
s
i
,
j
)
(9)
\tag{9} \mathcal{L}_{cls}=CE(p_{i,j},s_{i,j})
Lcls=CE(pi,j,si,j)(9)
2.5 包约束和总损失
2.5.1 包约束
为了充分利用包标签,我们记录每个实例的索引,并应用以下包约束损失:
L
b
c
=
C
E
(
M
L
P
(
M
e
a
n
(
q
i
,
j
,
j
=
1
,
2
,
⋅
,
n
i
)
)
,
Y
i
)
(10)
\tag{10} \mathcal{L}_{bc}=CE(MLP(Mean(q_{i,j},j=1,2,\cdot,n_i)),Y_i)
Lbc=CE(MLP(Mean(qi,j,j=1,2,⋅,ni)),Yi)(10)
2.5.2 总损失
L = L I W S C L + λ 1 L c l s + λ 2 L b c (11) \tag{11} \mathcal{L}=\mathcal{L}_{IWSCL}+\lambda_1\mathcal{L}_{cls}+\lambda_2\mathcal{L}_{bc} L=LIWSCL+λ1Lcls+λ2Lbc(11)
3 实验结果
3.1 数据集
3.1.1 仿真CIFAR-MIL数据集
CIFAR-MIL基于CIFAR-10数据集构建,该数据集包含60000张32x32的图像,累计十个类别,每个类别6000张图像。这些图像又可以划分为50000训练,10000测试。
为了模拟病理学WSI,将每个图像看作是一个实例,卡车类别的实例视作正实例,其它的作为负实例。然后,每个正包随机选择 a a a个正实例和 100 − a 100-a 100−a个负实例 (不重复),则记正实例比例为 a / 100 a/100 a/100。同理,生成包含100个实例的负包。上述过程不断重复,直到所有正实例或者负实例被使用过。CIFAR-MIL正实例的比例分别设置为5%、10%、20%、50%,以及70%。
3.1.2 Camelyon16公开数据集
该数据集是用于检测乳腺癌淋巴结转移的一个公开数据集,其中包含转移的被标记为正,其余的被标记为负。此外每一个WSI包含一个表示正负的标签,转移区域的像素级标签同样被提供。为了满足弱监督场景,训练时仅使用幻灯片级标签,测试时则使用像素标签的实例分类性能。
在训练前,每个WSI采用10x放大,且划分为512x512个不重叠区域,熵少于5的区块将作为背景被移除。如果一个区块包含25%以上的癌症区域,则标记为正。最终获得用于训练的累计186604个实例,其中243张幻灯片和111张幻灯片分别用于训练和测试。
数据集的官网:https://camelyon16.grand-challenge.org/Data/
处理好的区块:https://github.com/basveeling/pcam
3.1.3 TCGA肺癌数据集
该数据集包含1054张收集自TCGA官网的WSI,其包含两个肺癌子类型,即肺腺癌和肺鳞状细胞癌。本文的目标是加速两种类型的诊断,即将肺腺癌标记为负,余下标记为正。该数据集仅提供了幻灯片级标注,每个WSI平均大小为5000。这些WSI被随机划分为840个训练,余下210测试,其中有4张低质量WSI被抛弃。
3.1.4 Cervical癌症数据集
Cervical是一个临床诊断病理学数据集包含374张来自不同患者的宫颈癌原发病变的H&E染色WSI。每张WSI被放大5倍,并被裁剪为多个224x224的非重叠区域构成一个包。熵低于5的背景区块被舍弃:
- 原发肿瘤淋巴结转移的预测:盆腔淋巴结转移患者的WSI标记为正,累计209,余下标记为负,累计165。从中随机选择300作为训练,74作为测试;
- 患者生存概率预测:根据详细的随访记录对所有患者进行分组,使用中位数作为分界线,其中三年内没有经历癌症相关死亡的患者被标记为负,余下标记为正。从中随机选294作为训练,余下80作为测试;
- 免疫组化标记物KI-67的预测:根据KI-67免疫组织化学报告的中位数作为截止值,其中 KI-67水平低于75的标记为负,余下标记为正。从机随机选择294作为训练,余下作为测试。
3.2 度量标准和对比方法
- 度量标准:AUC和ACC;
- 对比算法:
- 基于实例的方法:MILRNN、Chi-MIL、DGMIL;
- 基于包的方法:ABMIL、Loss-ABMIL、CLAM、DSMIL、TransMIL、DTFD-MIL、TPMIL,以及WENO;
- 预处理器:SimCLR。
3.3 实现细节
- 与DSMIL一致,所有的区块均进行裁剪和背景去除操作;
- 编码器使用ResNet18;
- 实例分类器使用MLP;
- 投影头使用2层MLP,原型向量为128维;
- 不执行网络参数的预训练;
- SGD优化器,学习率为0.01、动量0.9,以及批次64;
- 嵌入队列的大小为8192;
- 为平滑训练过程,设置warm-up轮次。在warm-up之后,更新伪标签及分配真实负标签。
3.4 CIFAR-MIL实验结果

3.5 真实数据集实验结果



















 621
621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









