







前言
使用graphrag也有一段时间了,也被graphrag的index过程给绕晕过,在这里简单介绍下
微软使用datashaper(微软自家的)创建workflow来执行index的过程,即将输入文本块进行切块、向量化、实例、关系抽取等等的过程,这篇文章努力给大家讲清楚流程
官方源码链接如下:
附同系列链接:
GraphRAG:LLM之Graphrag的index过程——datashaper操作讲解(二)
大家在学习的过程中也可以结合graphrag的examples文件夹边学习边操作
不过最终还是要回归到graphrag去的,graphrag的pipeline_config创建于graphrag\index\cli.py的index_cli函数的_create_default_config,_create_default_config会跳转到graphrag\index\create_pipeline_config.py,红框位置便是整个构建索引过程分别要进行的步骤
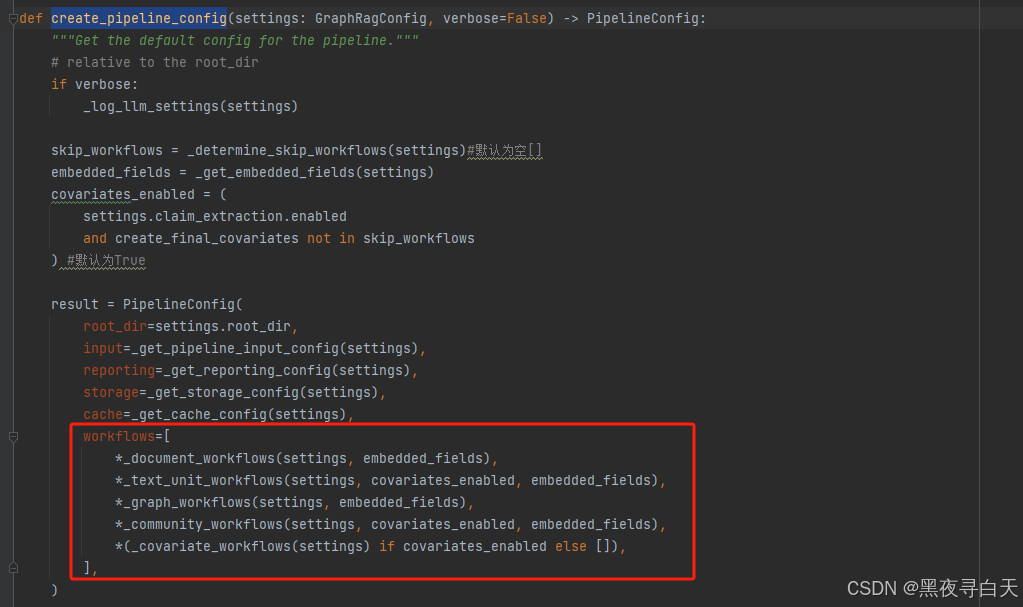
其中_document_workflows包含了create_base_documents与create_final_documents
create_base_documents
以graphrag\index\workflows\v1\create_base_documents.py具体讲解好了
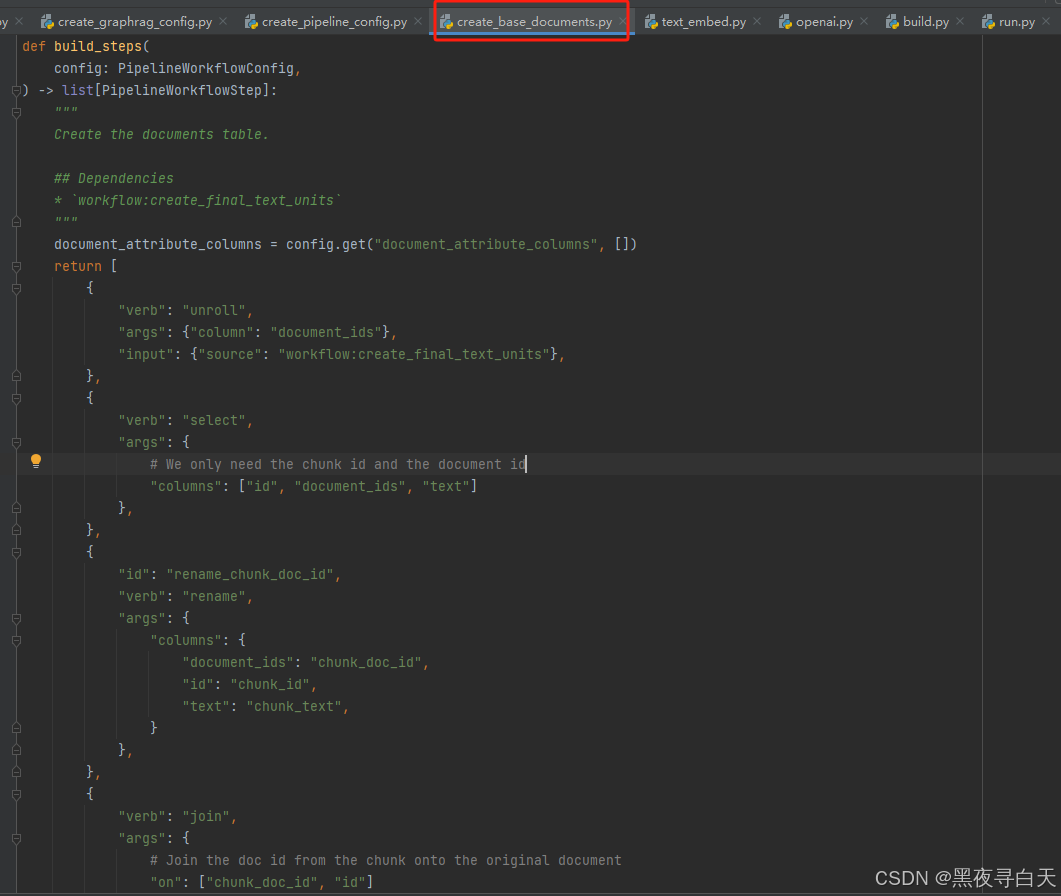
unroll
{
"verb": "unroll",
"args": {"column": "document_ids"},
"input": {"source": "workflow:create_final_text_units"},
},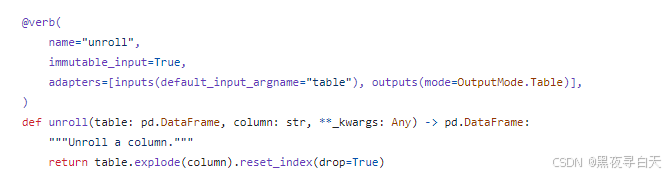
unroll函数传入的table是create_final_text_units的输出,它将table中的document_ids列展开,使得每个列表元素都成为一行,最后返回新的 DataFrame
举个例子:
import pandas as pd
data = {
'user_id': [1, 2, 3],
'document_ids': [[101, 102], [103], [104, 105, 106]]
}
df = pd.DataFrame(data)
#df输出
user_id document_ids
0 1 [101, 102]
1 2 [103]
2 3 [104, 105, 106]
# 使用 unroll 函数展开 document_ids 列
unrolled_df = unroll(df, 'document_ids')
#展开后
user_id document_ids
0 1 101
1 1 102
2 2 103
3 3 104
4 3 105
5 3 106
select
{
"verb": "select",
"args": {
# We only need the chunk id and the document id
"columns": ["id", "document_ids", "text"]
},
},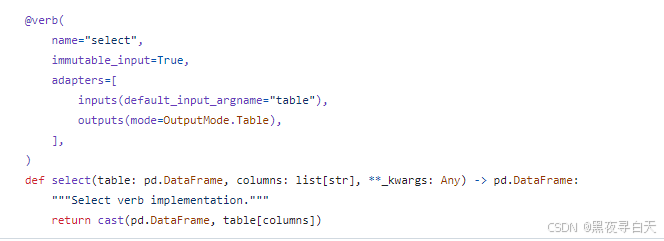
将document_ids展开后,获取指定的列,例如id,document_ids,text
rename
{
"id": "rename_chunk_doc_id",
"verb": "rename",
"args": {
"columns": {
"document_ids": "chunk_doc_id",
"id": "chunk_id",
"text": "chunk_text",
}
},
},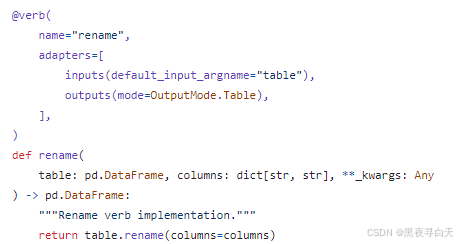
无须多言,将列名换个名字
join
{
"verb": "join",
"args": {
# Join the doc id from the chunk onto the original document
"on": ["chunk_doc_id", "id"]
},
"input": {"source": "rename_chunk_doc_id", "others": [DEFAULT_INPUT_NAME]},
},源码:
from typing import Any, cast
import pandas as pd
from pandas._typing import MergeHow, Suffixes
from .decorators import OutputMode, inputs, outputs, verb
from .types import JoinStrategy
__strategy_mapping: dict[JoinStrategy, MergeHow] = {
JoinStrategy.Inner: "inner",
JoinStrategy.LeftOuter: "left",
JoinStrategy.RightOuter: "right",
JoinStrategy.FullOuter: "outer",
JoinStrategy.Cross: "cross",
JoinStrategy.AntiJoin: "outer",
JoinStrategy.SemiJoin: "outer",
}
def __clean_result(
strategy: JoinStrategy, result: pd.DataFrame, source: pd.DataFrame
) -> pd.DataFrame:
if strategy == JoinStrategy.AntiJoin:
return cast(
pd.DataFrame, result[result["_merge"] == "left_only"][source.columns]
)
if strategy == JoinStrategy.SemiJoin:
return cast(pd.DataFrame, result[result["_merge"] == "both"][source.columns])
result = cast(
pd.DataFrame,
pd.concat(
[
result[result["_merge"] == "both"],
result[result["_merge"] == "left_only"],
result[result["_merge"] == "right_only"],
]
),
)
return result.drop("_merge", axis=1)
@verb(
name="join",
immutable_input=True,
adapters=[
inputs(default_input_argname="table", input_argnames={"other": "other"}),
outputs(mode=OutputMode.Table),
],
)
def join(
table: pd.DataFrame,
other: pd.DataFrame,
on: list[str] | None = None,
strategy: str = "inner",
**_kwargs: Any,
) -> pd.DataFrame:
"""Join verb implementation."""
join_strategy = JoinStrategy(strategy)
if on is not None and len(on) > 1:
left_column = on[0]
right_column = on[1]
output = table.merge(
other,
left_on=left_column,
right_on=right_column,
how=__strategy_mapping[join_strategy],
suffixes=cast(Suffixes, ["_1", "_2"]),
indicator=True,
)
else:
output = table.merge(
other,
on=on,
how=__strategy_mapping[join_strategy],
suffixes=cast(Suffixes, ["_1", "_2"]),
indicator=True,
)
return __clean_result(join_strategy, output, table)代码有点长,图片装下不好看了,只贴出关键函数

join函数接受两个 DataFrame 对象 table 和 other
接受一个 on 参数,它是一个列名列表,用于指定连接的键。
接受一个 strategy 参数,它是一个字符串,指定了连接策略
使用 pandas.DataFrame.merge 方法进行合并,并传入适当的参数,如 how(合并方式)、suffixes(处理重复列名的后缀)和 indicator(添加一个特殊列来指示每个行的来源
调用 __clean_result 函数来处理合并后的结果,特别是对于 AntiJoin 和 SemiJoin
JoinStrategy在types.py文件中定义

该枚举包含了不同的合并策略,如内连接(Inner)、左外连接(LeftOuter)、右外连接(RightOuter)、全外连接(FullOuter)、反连接(AntiJoin)、半连接(SemiJoin)和交叉连接(Cross)
举个例子:
import pandas as pd
df1 = pd.DataFrame({
'chunk_doc_id': [1, 2, 3],
'id': [101, 102, 103],
'value': ['A', 'B', 'C']
})
df2 = pd.DataFrame({
'chunk_doc_id': [1, 2, 4],
'id': [101, 104, 105],
'description': ['Desc1', 'Desc2', 'Desc3']
})
# 使用 join 函数进行左外连接
result = join(
table=df1,
other=df2,
on=['chunk_doc_id', 'id'],
strategy='left outer'
)
print(result)
#输出
chunk_doc_id id value description
0 1 101 A Desc1
1 2 102 B Desc2
2 3 103 C None
左外连接保留了 df1 中的所有行,即使它们在 df2 中没有匹配的行。df2 中没有匹配的行(例如 chunk_doc_id 为 4 的行,id为104 105的行)则不会出现在结果中。对于 df1 中没有在 df2 中找到匹配的行,description 列的值为 None总的来说就是对上边得到的 rename_chunk_doc_id进行一个连接操作
aggregate_override
{
"id": "docs_with_text_units",
"verb": "aggregate_override",
"args": {
"groupby": ["id"],
"aggregations": [
{
"column": "chunk_id",
"operation": "array_agg",
"to": "text_units",
}
],
},
},源码:
from functools import reduce
from typing import Any, cast
import pandas as pd
from .decorators import (
OutputMode,
inputs,
outputs,
verb,
)
from .types import FieldAggregateOperation
@verb(
name="aggregate",
immutable_input=True,
adapters=[
inputs(default_input_argname="table"),
outputs(mode=OutputMode.Table),
],
)
def aggregate(
table: pd.DataFrame,
to: str,
groupby: list[str],
column: str,
operation: FieldAggregateOperation,
**_kwargs: Any,
) -> pd.DataFrame:
"""Aggregate verb implementation."""
result = cast(
pd.DataFrame,
table.groupby(groupby).agg({column: aggregate_operation_mapping[operation]}),
)
result[to] = result[column]
result.drop(column, axis=1, inplace=True)
return result.reset_index()
aggregate_operation_mapping = {
FieldAggregateOperation.Any: "first",
FieldAggregateOperation.Count: "count",
FieldAggregateOperation.CountDistinct: "nunique",
FieldAggregateOperation.Valid: lambda series: series.dropna().count(),
FieldAggregateOperation.Invalid: lambda series: series.isna().sum(),
FieldAggregateOperation.Max: "max",
FieldAggregateOperation.Min: "min",
FieldAggregateOperation.Sum: "sum",
FieldAggregateOperation.Product: lambda series: reduce(lambda x, y: x * y, series),
FieldAggregateOperation.Mean: "mean",
FieldAggregateOperation.Median: "median",
FieldAggregateOperation.StDev: "std",
FieldAggregateOperation.StDevPopulation: "",
FieldAggregateOperation.Variance: "variance",
FieldAggregateOperation.ArrayAgg: lambda series: [e for e in series],
FieldAggregateOperation.ArrayAggDistinct: lambda series: [
e for e in series.unique()
],
}aggregate 函数,用于对 pandas DataFrame 中的数据进行分组和聚合操作。
FieldAggregateOperation 枚举,在types文件定义,它包含pandas 所有支持的聚合操作,如计数(Count)、求和(Sum)、平均值(Mean)等
在这里使用的是array_agg,即将分组内的多个值聚合成一个数组。
在aggregate 函数中:
1、使用 table.groupby(groupby) 对 DataFrame 进行分组,graphrag中的groupby是上诉表中的id列
2、使用 .agg() 方法对每个组应用聚合操作,graphrag中是对id列的每个id所对应的chunk_id进行合并操作,即执行后id列中相同的id会进行合并,相同的id可能会得到[chunk_id_1,chunk_id_2,...]
3、将聚合结果列重命名为 to 参数指定的名称,可以认为将id重新命名为text_units
4、删除原始的聚合列
5、使用 .reset_index() 重置索引,使分组列成为 DataFrame 的普通列
还是举个例子吧
import pandas as pd
df = pd.DataFrame({
'user': ['Alice', 'Alice', 'Bob', 'Bob', 'Charlie'],
'rating': [5, 4, 3, 5, 2]
})
# 使用 array_agg 聚合操作
result = df.groupby('user').agg({'rating': lambda x: [e for e in x]})
print(result)
#结果
rating
user
Alice [5, 4]
Bob [3, 5]
Charlie [2]
graphrag对aggregate进行了重载,代码位于graphrag\index\verbs\overrides中
同上:
{
"verb": "join",
"args": {
"on": ["id", "id"],
"strategy": "right outer",
},
"input": {
"source": "docs_with_text_units",
"others": [DEFAULT_INPUT_NAME],
},
},
{
"verb": "rename",
"args": {"columns": {"text": "raw_content"}},
},convert
*[
{
"verb": "convert",
"args": {
"column": column,
"to": column,
"type": "string",
},
}
for column in document_attribute_columns
],源码:
import numbers
from collections.abc import Callable
from datetime import datetime
from typing import Any, cast
import numpy as np
import pandas as pd
from pandas.api.types import is_bool_dtype, is_datetime64_any_dtype, is_numeric_dtype
from .decorators import OutputMode, inputs, outputs, verb
from .types import ParseType
def _convert_int(value: str, radix: int) -> int | float:
try:
return int(value, radix)
except ValueError:
return np.nan
def _to_int(column: pd.Series, radix: int) -> pd.DataFrame | pd.Series:
if radix is None:
if column.str.startswith("0x").any() or column.str.startswith("0X").any():
radix = 16
elif column.str.startswith("0").any():
radix = 8
else:
radix = 10
return column.apply(lambda x: _convert_int(x, radix))
def _convert_float(value: str) -> float:
try:
return float(value)
except ValueError:
return np.nan
# todo: our schema TypeHints allows strict definition of what should be allowed for a bool, so we should provide a way to inject these beyond the defaults
# see https://pandas.pydata.org/pandas-docs/stable/user_guide/io.html#boolean-values
def _convert_bool(value: str) -> bool:
return isinstance(value, str) and (value.lower() == "true")
def _convert_date_to_str(value: datetime, format_pattern: str) -> str | float:
try:
return datetime.strftime(value, format_pattern)
except Exception:
return np.nan
def _to_str(column: pd.Series, format_pattern: str) -> pd.DataFrame | pd.Series:
column_numeric: pd.Series | None = None
if is_numeric_dtype(column):
column_numeric = cast(pd.Series, pd.to_numeric(column))
if column_numeric is not None and is_numeric_dtype(column_numeric):
try:
return column.apply(lambda x: "" if x is None else str(x))
except Exception: # noqa: S110
pass
try:
datetime_column = pd.to_datetime(column)
except Exception:
datetime_column = column
if is_datetime64_any_dtype(datetime_column):
return datetime_column.apply(lambda x: _convert_date_to_str(x, format_pattern))
if isinstance(column.dtype, pd.ArrowDtype) and "timestamp" in column.dtype.name:
return column.apply(lambda x: _convert_date_to_str(x, format_pattern))
if is_bool_dtype(column):
return column.apply(lambda x: "" if pd.isna(x) else str(x).lower())
return column.apply(lambda x: "" if pd.isna(x) else str(x))
def _to_datetime(column: pd.Series) -> pd.Series:
if column.dropna().map(lambda x: isinstance(x, numbers.Number)).all():
return pd.to_datetime(column, unit="ms")
return pd.to_datetime(column)
def _to_array(column: pd.Series, delimiter: str) -> pd.Series | pd.DataFrame:
def convert_value(value: Any) -> list:
if pd.isna(value):
return []
if isinstance(value, list):
return value
if isinstance(value, str):
return value.split(delimiter)
return [value]
return column.apply(convert_value)
__type_mapping: dict[ParseType, Callable] = {
ParseType.Boolean: lambda column, **_kwargs: column.apply(
lambda x: _convert_bool(x)
),
ParseType.Date: lambda column, **_kwargs: _to_datetime(column),
ParseType.Decimal: lambda column, **_kwargs: column.apply(
lambda x: _convert_float(x)
),
ParseType.Integer: lambda column, radix, **_kwargs: _to_int(column, radix),
ParseType.String: lambda column, format_pattern, **_kwargs: _to_str(
column, format_pattern
),
ParseType.Array: lambda column, delimiter, **_kwargs: _to_array(column, delimiter),
}
@verb(
name="convert",
adapters=[
inputs(default_input_argname="table"),
outputs(mode=OutputMode.Table),
],
)
def convert(
table: pd.DataFrame,
column: str,
to: str,
type: str, # noqa: A002
radix: int | None = None,
delimiter: str | None = ",",
formatPattern: str = "%Y-%m-%d", # noqa: N803
**_kwargs: Any,
) -> pd.DataFrame:
"""Convert verb implementation."""
parse_type = ParseType(type)
table[to] = __type_mapping[parse_type](
column=table[column],
radix=radix,
format_pattern=formatPattern,
delimiter=delimiter,
)
return table
总结就是 数据类型转换,数字转字符串啥的
merge_override
{
"verb": "merge_override",
"enabled": len(document_attribute_columns) > 0,
"args": {
"columns": document_attribute_columns,
"strategy": "json",
"to": "attributes",
},
},源码:
from collections.abc import Callable
from functools import partial
from typing import Any
import pandas as pd
from pandas.api.types import is_bool
from .decorators import OutputMode, inputs, outputs, verb
from .types import MergeStrategy
@verb(
name="merge",
adapters=[
inputs(default_input_argname="table"),
outputs(mode=OutputMode.Table),
],
)
def merge(
table: pd.DataFrame,
to: str,
columns: list[str],
strategy: str,
delimiter: str = "",
preserveSource: bool = False, # noqa: N803
**_kwargs: Any,
) -> pd.DataFrame:
"""Merge verb implementation."""
merge_strategy = MergeStrategy(strategy)
table[to] = table[columns].apply(
partial(merge_strategies[merge_strategy], delim=delimiter), axis=1
)
if not preserveSource:
table.drop(columns=columns, inplace=True)
return table
merge_strategies: dict[MergeStrategy, Callable] = {
MergeStrategy.FirstOneWins: lambda values, **_kwargs: values.dropna().apply(
lambda x: _correct_type(x)
)[0],
MergeStrategy.LastOneWins: lambda values, **_kwargs: values.dropna().apply(
lambda x: _correct_type(x)
)[-1],
MergeStrategy.Concat: lambda values, delim, **_kwargs: _create_array(values, delim),
MergeStrategy.CreateArray: lambda values, **_kwargs: _create_array(values, ","),
}
def _correct_type(value: Any) -> str | int | Any:
if is_bool(value):
return str(value).lower()
try:
return int(value) if value.is_integer() else value
except AttributeError:
return value
def _create_array(column: pd.Series, delim: str) -> str:
col: pd.DataFrame | pd.Series = column.dropna().apply(lambda x: _correct_type(x))
return delim.join(col.astype(str)) 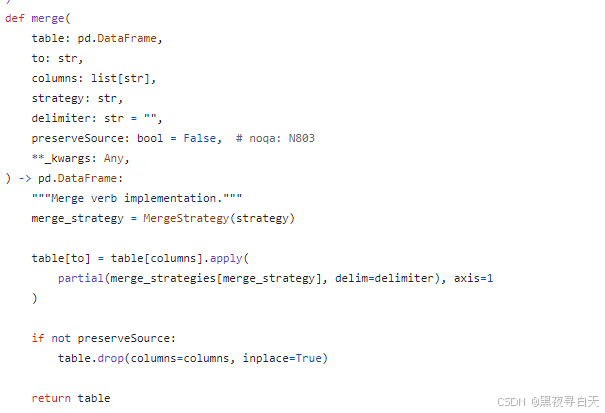
merge_strategies的合并策略有:
FirstOneWins: 返回第一个非空值。LastOneWins: 返回最后一个非空值。Concat: 将所有非空值拼接成一个字符串,使用delimiter作为分隔符。CreateArray: 将所有非空值转换为一个数组。
总结就是 我们可以额外定义一些要传的值,这些会以json格式被合并到表的attributes列中,例如我们想额外传张三的年龄,工作地址,有没有脱发啥的属性啥的
graphrag对merge进行了重载,代码位于graphrag\index\verbs\merge中
create_final_documents
text_embed(graphrag自定义函数)
{
"verb": "rename",
"args": {"columns": {"text_units": "text_unit_ids"}},
"input": {"source": "workflow:create_base_documents"},
},
{
"verb": "text_embed",
"enabled": not skip_raw_content_embedding,
"args": {
"column": "raw_content",
"to": "raw_content_embedding",
**document_raw_content_embed_config,
},
},简单的讲就是将文本块进行向量化,在graphrag中是执行自定义的 text_embed函数,将raw_content列中的文本块向量化之后存入raw_content_embedding中
源码位于graphrag\index\verbs\text\embed\text_embed.py
@verb(name="text_embed")
async def text_embed(
input: VerbInput,
callbacks: VerbCallbacks,
cache: PipelineCache,
column: str,
strategy: dict,
**kwargs,
) -> TableContainer:
# plan = kwargs['stats'].workflows.
vector_store_config = strategy.get("vector_store") #默认为None
if vector_store_config:
embedding_name = kwargs.get("embedding_name", "default")
collection_name = _get_collection_name(vector_store_config, embedding_name)
vector_store: BaseVectorStore = _create_vector_store(
vector_store_config, collection_name
)
vector_store_workflow_config = vector_store_config.get(
embedding_name, vector_store_config
)
return await _text_embed_with_vector_store(
input,
callbacks,
cache,
column,
strategy,
vector_store,
vector_store_workflow_config,
vector_store_config.get("store_in_table", False),
kwargs.get("to", f"{column}_embedding"),
)
return await _text_embed_in_memory(
input,
callbacks,
cache,
column,
strategy,
kwargs.get("to", f"{column}_embedding"),
)如果vector_store_config不为空,则会连接graphrag的向量数据库lancedb,lancedb如何操作,之后我会写出来的,连接到数据库之后就是创建表然后还是向量化并存储
由于vector_store_config默认为None,一般是执行_text_embed_in_memory函数,我们关注input、column、以及strategy
column是input表中的某一列名称,在文本块向量化中column =='raw_content',之所以这么说是因为实例、实例的声明等等的向量化也是在这个函数执行的
strategy 可以通过在setting.yaml 和graphrag\config\create_graphrag_config.py的create_graphrag_config函数修改
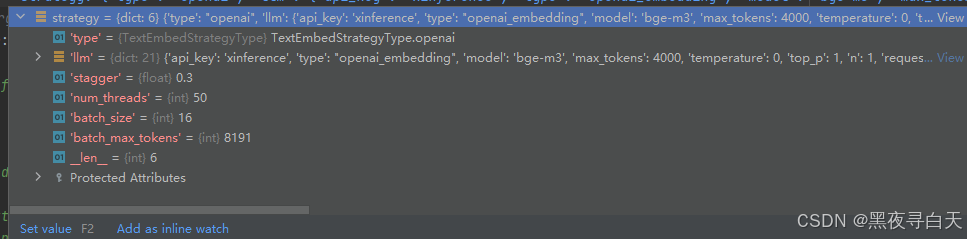
在_text_embed_in_memory函数中主要用到type属性
async def _text_embed_in_memory(
input: VerbInput,
callbacks: VerbCallbacks,
cache: PipelineCache,
column: str,
strategy: dict,
to: str,
):
input_table = input.get_input()
output_df = cast(pd.DataFrame, input_table)
strategy_type = strategy["type"]
strategy_exec = load_strategy(strategy_type)
strategy_args = {**strategy}
#input_table = input.get_input()
texts: list[str] = input_table[column].to_numpy().tolist()
result = await strategy_exec(texts, callbacks, cache, strategy_args)
output_df[to] = result.embeddings
return TableContainer(table=output_df)_text_embed_in_memory函数先将input输入表转成pd的df格式,然后将strategy的type取出来,strategy_type类型如下,默认是openai
class TextEmbedStrategyType(str, Enum):
"""TextEmbedStrategyType class definition."""
openai = "openai"
mock = "mock"
def __repr__(self):
"""Get a string representation."""
return f'"{self.value}"'将格式传入之后会返回对应的策略执行函数
def load_strategy(strategy: TextEmbedStrategyType) -> TextEmbeddingStrategy:
"""Load strategy method definition."""
match strategy:
case TextEmbedStrategyType.openai:
from .strategies.openai import run as run_openai
return run_openai
case TextEmbedStrategyType.mock:
from .strategies.mock import run as run_mock
return run_mock
case _:
msg = f"Unknown strategy: {strategy}"
raise ValueError(msg)给大家看一下run_openai的代码,它是我们将文本块转成向量的代码
async def run(
input: list[str],
callbacks: VerbCallbacks,
cache: PipelineCache,
args: dict[str, Any],
) -> TextEmbeddingResult:
"""Run the Claim extraction chain."""
if is_null(input):
return TextEmbeddingResult(embeddings=None)
llm_config = args.get("llm", {})
batch_size = args.get("batch_size", 16)
batch_max_tokens = args.get("batch_max_tokens", 8191)
oai_config = OpenAIConfiguration(llm_config)
splitter = _get_splitter(oai_config, batch_max_tokens)
llm = _get_llm(oai_config, callbacks, cache)
semaphore: asyncio.Semaphore = asyncio.Semaphore(args.get("num_threads", 4))
print('123')
# Break up the input texts. The sizes here indicate how many snippets are in each input text
texts, input_sizes = _prepare_embed_texts(input, splitter)
text_batches = _create_text_batches(
texts,
batch_size,
batch_max_tokens,
splitter,
)
log.info(
"embedding %d inputs via %d snippets using %d batches. max_batch_size=%d, max_tokens=%d",
len(input),
len(texts),
len(text_batches),
batch_size,
batch_max_tokens,
)
ticker = progress_ticker(callbacks.progress, len(text_batches))
# Embed each chunk of snippets
embeddings = await _execute(llm, text_batches, ticker, semaphore)
embeddings = _reconstitute_embeddings(embeddings, input_sizes)
return TextEmbeddingResult(embeddings=embeddings)大致就先讲到这里,后续会在这里补上或者另外写文章补上
大家看到这里,其实就应该明白graphrag-index的运行机理了,其他的都差不多
码字不易~
欢迎大家点赞或收藏~
大家的点赞或收藏可以鼓励作者加快更新哟~

















 1749
1749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









