







机器学习--模型评估与旋转与对手写体Mnist
一、模型评估与旋转
1、查准率
查全率与查准率是信息检索领域内的概念,二者是反映检索效果的重要指标。根据查准率和查全率可绘制系统的PR曲线,可根据曲线判断系统的优劣。
查准率(精度)是衡量某一检索系统的信号噪声比的一种指标,即检出的相关文献量与检出的文献总量的百分比。
普遍表示为:查准率=(检索出的相关信息量/检索出的信息总量)x100%。使用专指性较强的检索语言(如上位类、上位主题词)能提高查准率,但查全率下降。
python代码:
随机交叉验证和分层交叉验证效果对比。
使用cross_vla_score函数,进行三折对比
from sklearn.model_selection import cross_val_score
cross_val_score(sgd_clf, X_train, y_train_5, cv=3, scoring="accuracy")

分层采样
from sklearn.model_selection import StratifiedKFold
from sklearn.base import clone
skfolds = StratifiedKFold(n_splits=3, random_state=42)
for train_index, test_index in skfolds.split(X_train, y_train_5):
clone_clf = clone(sgd_clf)
X_train_folds = X_train[train_index]
y_train_folds = (y_train_5[train_index])
X_test_fold = X_train[test_index]
y_test_fold = (y_train_5[test_index])
clone_clf.fit(X_train_folds, y_train_folds)
y_pred = clone_clf.predict(X_test_fold)
n_correct = sum(y_pred == y_test_fold)
print(n_correct / len(y_pred))
 通过两种方法,可以看到两种交叉验证的准确率都达到了95%上下。
通过两种方法,可以看到两种交叉验证的准确率都达到了95%上下。
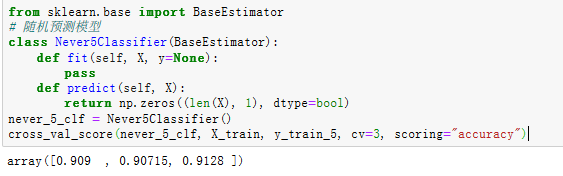
接下来让我们来看一个蠢笨的分类器,将所有图片都预测为‘非5’
from sklearn.base import BaseEstimator
class Never5Classifier(BaseEstimator):
def fit(self, X, y=None):
pass
def predict(self, X):
return np.zeros((len(X), 1), dtype=bool)
never_5_clf = Never5Classifier()
cross_val_score(never_5_clf, X_train, y_train_5, cv=3, scoring="accuracy")
2、查全率
查全率(召回率),是衡量某一检索系统从文献集合中检出相关文献成功度的一项指标,即检出的相关文献量与检索系统中相关文献总量的百分比。普遍表示为:查全率=(检索出的相关信息量/系统中的相关信息总量)x100%。使用泛指性较强的检索语言(如上位类、上位主题词)能提高查全率,但查准率下降。
3、混淆矩阵
评估分类器性能的更好的方法是混淆矩阵。总体思路就是统计A类别实例被分成B类别的次数。例如,要想知道分类器将数字3和数字5混淆多少次,只需要通过混淆矩阵的第5行第3列来查看。
要计算混淆矩阵,需要一组预测才能将其与实际目标进行比较。当然可以通过测试集来进行预测,但是现在我们不动它(测试集最好保留到项目的最后,准备启动分类器时再使用)。最为代替,可以使用cross_val_predict()函数:
cross_val_predict 和 cross_val_score 不同的是,前者返回预测值,并且是每一次训练的时候,用模型没有见过的数据来预测
from sklearn.model_selection import cross_val_predict
y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3)
from sklearn.metrics import confusion_matrix
confusion_matrix(y_train_5, y_train_pred)
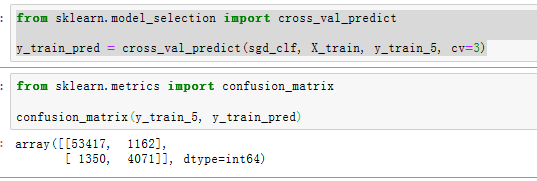
上面的结果表明:第一行所有’非5’(负类)的图片中,有53417被正确分类(真负类),1162,错误分类成了5(假负类);第二行表示所有’5’(正类)的图片中,有1350错误分类成了非5(假正类),有4071被正确分类成5(真正类).
一个完美的分类器只有真正类和真负类,所以其混淆矩阵只会在其对角线(左上到右下)上有非零值
4、F1-Score
F1分数(F1-score)是分类问题的一个衡量指标。一些多分类问题的机器学习竞赛,常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,最小为0。
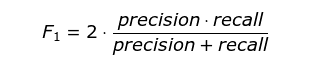
此外还有F2分数和F0.5分数。F1分数认为召回率和精确率同等重要,F2分数认为召回率的重要程度是精确率的2倍,而F0.5分数认为召回率的重要程度是精确率的一半。计算公式为:
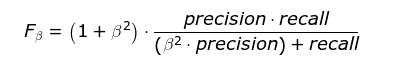
G分数是另一种统一精确率和的召回率系统性能评估标准,G分数被定义为召回率和精确率的几何平均数。

下面,我们可以将精度和召回率组合成单一的指标,称为F1分数。
𝐹1=21𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛+1𝑅𝑒𝑐𝑎𝑙𝑙=2∗𝑃𝑟𝑒∗𝑅𝑒𝑐𝑃𝑟𝑒+𝑅𝑒𝑐=𝑇𝑃𝑇𝑃+𝐹𝑁+𝐹𝑃2
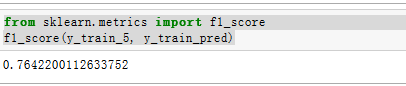
要计算F1分数,只需要调用f1_score()即可
from sklearn.metrics import f1_score
f1_score(y_train_5, y_train_pred)
F1分数对那些具有相近的精度和召回率的分类器更为有利。这不一定一直符合预期,因为在某些情况下,我们更关心精度,而另一些情况下,我们可能真正关系的是召回率。
5、ROC
在信号检测理论中,接收者操作特征曲线(receiver operating characteristic curve,或者叫ROC曲线)是坐标图式的分析工具,用于 (1) 选择最佳的信号侦测模型、舍弃次佳的模型。 (2) 在同一模型中设定最佳阈值。在做决策时,ROC分析能不受成本/效益的影响,给出客观中立的建议。
ROC曲线首先是由二战中的电子工程师和雷达工程师发明的,用来侦测战场上的敌军载具(飞机、船舰),也就是信号检测理论。之后很快就被引入了心理学来进行信号的知觉检测。数十年来,ROC分析被用于医学、无线电、生物学、犯罪心理学领域中,而且最近在机器学习(machine learning)和数据挖掘(data mining)领域也得到了很好的发展。
分类模型(又称分类器,或诊断)将实例映射到特定类。ROC分析的是二元分类模型,也就是输出结果只有两种类别的模型,例如:(阳性/阴性) (有病/没病) (垃圾邮件/非垃圾邮件) (敌军/非敌军)。
当讯号侦测(或变量测量)的结果是连续值时,类与类的边界必须用阈值来界定。举例来说,用血压值来检测一个人是否有高血压,测出的血压值是连续的实数(从0~200都有可能),以收缩压140/舒张压90为阈值,阈值以上便诊断为有高血压,阈值未满者诊断为无高血压。
二元分类模型的个案预测有四种结局:真阳性(TP):诊断为有,实际上也有高血压。
伪阳性(FP):诊断为有,实际却没有高血压。
真阴性(TN):诊断为没有,实际上也没有高血压。
伪阴性(FN):诊断为没有,实际却有高血压。这四种结局可以画成2 × 2的混淆矩阵.

from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)
def plot_precision_recall_vs_threshold(precisions, recalls, thresholds):
plt.plot(thresholds, precisions[:-1], "b--", label="Precision", linewidth=2)
plt.plot(thresholds, recalls[:-1], "g-", label="Recall", linewidth=2)
plt.xlabel("Threshold", fontsize=16)
plt.title("精度和召回率VS决策阈值", fontsize=16)
plt.legend(loc="upper left", fontsize=16)
plt.ylim([0, 1])
plt.figure(figsize=(8, 4))
plot_precision_recall_vs_threshold(precisions, recalls, thresholds)
plt.xlim([-700000, 700000])
plt.show()

可以看见,随着阈值提高,召回率下降了,也就是说,有真例被判负了,精度上升,也就是说,有部分原本被误判的负例,被丢出去了。
你可以会好奇,为什么精度曲线会比召回率曲线要崎岖一些,原因在于,随着阈值提高,精度也有可能会下降 4/5 => 3/4(虽然总体上升)。另一方面,阈值上升,召回率只会下降。
现在就可以轻松通过选择阈值来实现最佳的精度/召回率权衡了。还有一种找到最好的精度/召回率权衡的方法是直接绘制精度和召回率的函数图。
def plot_precision_vs_recall(precisions, recalls):
plt.plot(recalls, precisions, "b-", linewidth=2)
plt.xlabel("Recall", fontsize=16)
plt.title("精度VS召回率", fontsize=16)
plt.ylabel("Precision", fontsize=16)
plt.axis([0, 1, 0, 1])
plt.figure(figsize=(8, 6))
plot_precision_vs_recall(precisions, recalls)
plt.show()
 可以看见,从80%的召回率往右,精度开始急剧下降。我们可能会尽量在这个陡降之前选择一个精度/召回率权衡–比如召回率60%以上。当然,如何选择取决于你的项目。
可以看见,从80%的召回率往右,精度开始急剧下降。我们可能会尽量在这个陡降之前选择一个精度/召回率权衡–比如召回率60%以上。当然,如何选择取决于你的项目。
二、对手写体Mnist
导入要用到的库
from sklearn.datasets import fetch_openml
import numpy as np
import os
np.random.seed(42)
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
使用sklearn的函数来获取MNIST数据集
def sort_by_target(mnist):
reorder_train=np.array(sorted([(target,i) for i, target in enumerate(mnist.target[:60000])]))[:,1]
reorder_test=np.array(sorted([(target,i) for i, target in enumerate(mnist.target[60000:])]))[:,1]
mnist.data[:60000]=mnist.data[reorder_train]
mnist.target[:60000]=mnist.target[reorder_train]
mnist.data[60000:]=mnist.data[reorder_test+60000]
mnist.target[60000:]=mnist.target[reorder_test+60000]
mnist=fetch_openml('mnist_784',version=1,cache=True)
mnist.target=mnist.target.astype(np.int8)
sort_by_target(mnist)
1、对数据进行排序
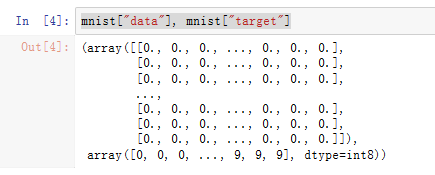
mnist["data"], mnist["target"]
2、查看MNIST数据集的特征
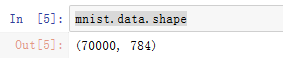
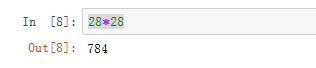
mnist.data.shape
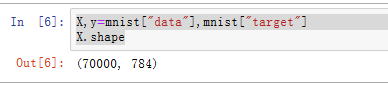
X,y=mnist["data"],mnist["target"]
X.shape
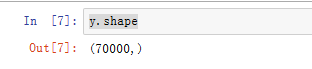
y.shape
28*28
3、展示图片
def plot_digit(data):
image = data.reshape(28, 28)
plt.imshow(image, cmap = mpl.cm.binary,
interpolation="nearest")
plt.axis("off")
some_digit = X[36000]
plot_digit(X[36000].reshape(28,28))
 展示10x10的图片集合
展示10x10的图片集合
def plot_digits(instances,images_per_row=10,**options):
size=28
# 每一行有一个
image_pre_row=min(len(instances),images_per_row)
images=[instances.reshape(size,size) for instances in instances]
# 有几行
n_rows=(len(instances)-1) // image_pre_row+1
row_images=[]
n_empty=n_rows*image_pre_row-len(instances)
images.append(np.zeros((size,size*n_empty)))
for row in range(n_rows):
# 每一次添加一行
rimages=images[row*image_pre_row:(row+1)*image_pre_row]
# 对添加的每一行的额图片左右连接
row_images.append(np.concatenate(rimages,axis=1))
# 对添加的每一列图片 上下连接
image=np.concatenate(row_images,axis=0)
plt.imshow(image,cmap=mpl.cm.binary,**options)
plt.axis("off")
plt.figure(figsize=(9,9))
example_images=np.r_[X[:12000:600],X[13000:30600:600],X[30600:60000:590]]
plot_digits(example_images,images_per_row=10)
plt.show()

















 816
816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









