







 本文介绍了潜类别分析作为一种统计技术,如何处理不可直接测量的潜在变量,如社会经济地位。通过实例,探讨了如何构建SES变量,评估模型,以及在健康生活方式与死亡率、心血管疾病研究中的应用。文章详细展示了模型选择过程和主要结果,强调了生活方式在社会经济地位影响健康中的中介作用。
本文介绍了潜类别分析作为一种统计技术,如何处理不可直接测量的潜在变量,如社会经济地位。通过实例,探讨了如何构建SES变量,评估模型,以及在健康生活方式与死亡率、心血管疾病研究中的应用。文章详细展示了模型选择过程和主要结果,强调了生活方式在社会经济地位影响健康中的中介作用。
编者
近年来,其实发表有关潜类别分析的文章越来越多,而我们要如何理解运用潜类别分析呢?在研究过程中,我们会发现有许多变量(如社会经济地位、生活压力、疾病症状类型、癌症危险行为等)是不能直接测量的。像社会经济地位这个变量,不可直接测量,由家庭收入、职业状况、教育水平、保险等变量组成,那么该如何把社会经济地位合并成一个变量进行统计分析呢?可以利用潜类别分析。今天,我们就利用一篇BMJ文章来介绍潜类别分析是什么以及如何进行潜类别分析。
本篇是潜变量分析方法系列文字第3篇
提到潜类别分析,我们首先要了解两个基本概念:外显变量和潜在变量。在潜类别分析中外显变量和潜在变量都是类别变量。像社会经济地位这个变量不可直接测量属于潜在变量,而家庭收入、职业状况、教育水平、健康保险则属于外显变量。
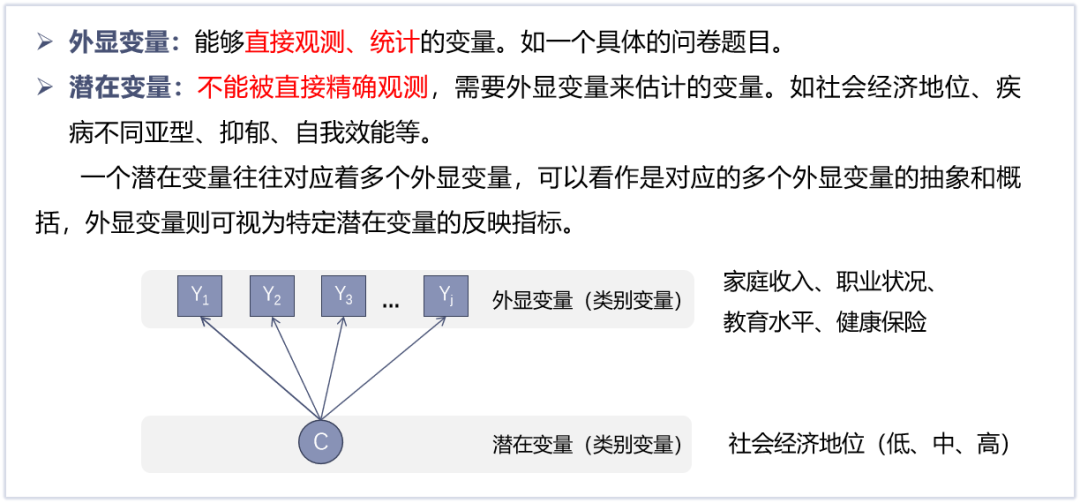
潜类别分析(Latent Class Analysis, LCA )是将潜在变量理论与分类变量相结合的一种统计分析技术,通过潜类别模型( Latent Class Model, LCM),用内在的潜在类别变量来解释外显的类别变量之间的关系,使得外显变量之间的关系经过潜在类别变量估计后,能够维持其局部独立性 。
可以将潜类别分析简单地理解为是多个分类变量生成一个新的分类变量,而这个新的分类变量将人群分为几组。

潜类别分析是基于概率模型(潜类别模型)进行分析的,那么该如何进行潜类别分析?进行潜类别分析时,我们往往不知道有几个类别,一般先假定一个类别,然后再逐步增加类别。

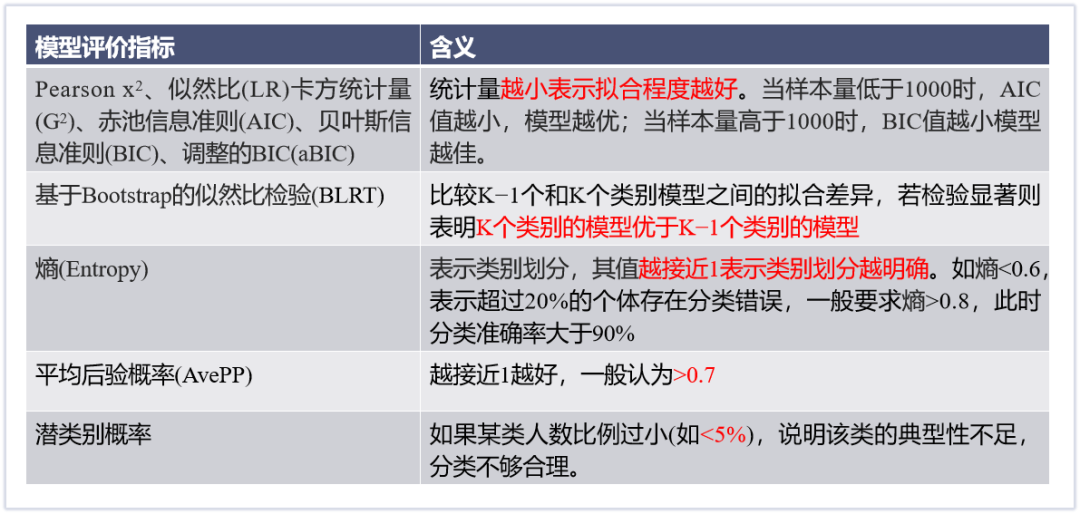
我们可以看出潜类别分析中相对重要的步骤就是对模型评价,根据拟合评价指标(AIC、BIC、G2等)进行模型比较,从而确定最佳模型。那么模型评价指标该如何判断?
本公众号回复“沙龙”即可获得代码,PPT,数据等资料 |
案例分享
2021年4月,中国华中科技大学学者在《BMJ》(一区,IF=105.7)发表题为:"
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









