







细心的小伙伴会注意到,计算分位数的时候,R和SPSS有时候跑出来的结果不一样。
对此我们手搓了一个数据集,内有一列名为ID,值为1到1200的数据。

在R语言中,用我们常见的quantile函数看看情况。结果如下:
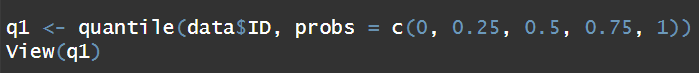

把这个数据集导出来放到SPSS里面跑四分位数结果如下:
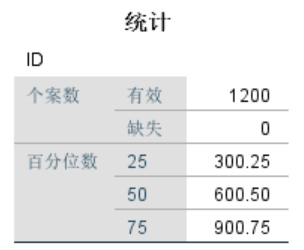
我们可以看到,SPSS与R语言分析结果是存在着区别的!
其实在于,中位数、分位数的算法好好多种!
很难相信看似简单的分位数计算quantile函数,居然有九种type(1-3用于分类变量,4-9用于连续变量),逐渐变成了陌生的样子。
首先我们得知道分位数是什么:
分位数计算公式 q = (1 - λ) x[j] + λ x[j+1] 是一种插值方法,用于估计数据集中特定概率水平 p 的分位数。这个公式是通过对相邻的顺序统计量进行加权平均来计算分位数的。
q:是我们要估计的分位数。
λ:是一个插值权重,它的值介于0和1之间。这个权重决定了在相邻的两个顺序统计量 x[j] 和 x[j+1] 之间如何进行插值。
x[j]:这是数据集中第 j 大的顺序统计量,也就是排在第 j 位的数值。
x[j+1]:这是数据集中第 j+1 大的顺序统计量,也就是排在第 j+1 位的数值。
具体来说,如果 λ 接近0,那么 q 将更接近于 x[j];如果 λ 接近1,那么 q 将更接近于 x[j+1]。当 λ 正好为0.5时,q 将是 x[j] 和 x[j+1] 的算术平均值。
通过查阅分位数计算文献《Sample Quantiles in Statistical Packages》,可知R默认使用type7,SPSS默认使用type6(官方没有文档解释,结果来看实际上是type6),SAS提供了type1-4及6的选项,通过参数可以设置,另外也支持自己编写其他方式并提供了函数参数。
其中,R语言的Quantile函数格式如下:

那么type6和type7的区别其实核心问题就在于λ这一插值权重。
原文中对于权重的计算有着以下的描述:n is the sample size, the value of γ is a function of j = floor(np + m) and g = np + m - j, and m is a constant determined by the sample quantile type.这里我们可知m 是一个常数,其值取决于所选择的样本分位数类型。不同的分位数类型(如前文提到的类型 1 到类型 9)会有不同的 m 值,这个值会影响 j 和 g 的计算,进而影响 γ 的值。
对于type6来说,常数m:m = p,插值点:p[k] = k / (n + 1)
这种方法计算的是每个顺序统计量的期望值在经验分布函数中的位置。也就是说,p[k]是经验分布函数F(x[k])的期望值。这种方法倾向于给出比方法7稍微更偏左的分布。
对于type7来说,常数m:m = 1 - p,插值点:p[k] = (k - 1) / (n - 1)
这种方法计算的是每个顺序统计量在经验分布函数中的众数位置。也就是说,p[k]是经验分布函数F(x[k])的众数。这种方法倾向于给出比方法6稍微更偏右的分布。
通过查阅分位数计算文献《Sample Quantiles in Statistical Packages》,可知R默认使用type7,SPSS默认使用type6(官方没有文档解释,结果来看实际上是type6),SAS提供了type1-4及6的选项,通过参数可以设置,另外也支持自己编写其他方式并提供了函数参数。这一文献与R Documentation以及SAS Blogs可以相互印证。
相关文献截图:
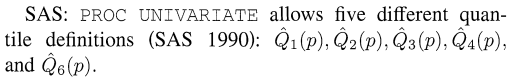
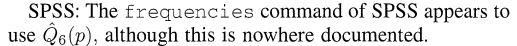
R Documentation:

SAS Blogs:

本文分享到这里了,由郑老师研究生撰写
我们开展统计服务了
我们是郑老师统计工作室,成立了临床研究统计服务团队,针对以下类型的数据开展分析服务,并提供规范的统计报告(中文或英文)。
①研究者发起的临床试验整体设计与分析
②医院真实世界数据与预测模型
③公共数据库挖掘,SEER、NHANES、老年健康数据库、GBD数据库
④孟德尔随机化数据分析
联系李老师咨询(微信号sas555777)
















 156
156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









