







详情请点击下方:
优惠了!第2期GBD公共数据库挖掘1对1指导班,快速撰写SCI
GBD数据库本身就是一个可用于研究全球疾病负担的数据库,数据全面、分析简单,无论是统计小白还是科研医生都能用这个数据库进行探索。但要想在众多文章中脱颖而出,不妨添加一些“套路”。
今天就用一篇一区top文章为大家讲清楚,如何用层次聚类对GBD数据库进行聚类分析。
简单来说,聚类分析就像是把一堆不同的水果(如苹果、香蕉、橙子)根据它们的特征(如颜色、大小、形状)分成几类。

聚类分析的本质,就是对变量进行分类,研究者依据自身对变量和理论的了解,将具有相同性质的变量分为一类。如果你也想在挖掘GBD数据库时尝试这个分析套路,欢迎联系郑老师的统计团队!专业的统计师指导,不管是聚类分析还是预测模型,都可以带你尝试!如果你对GBD数据库挖掘感兴趣,扫描下方二维码来聊聊吧!

接下来我们将以一篇GBD聚类文章为例,为大家解读如何用聚类分析对不同地区的数据进行分类。
2024年3月12日,英国伦敦国王学院的作者在《Science of The Total Environment》(医学一区top,IF=8.2)中发表的题为:“Effect of ambient ozone pollution on disease burden globally: A systematic analysis for the global burden of disease study 2019”的研究论文,旨在探究GBD环境臭氧污染对于全球疾病负担的影响。

本文有两大亮点:第一点为在数据分析时使用了分层聚类分析的方法;第二点为文章方向为臭氧对所有疾病的疾病负担。
接下来本文将从这两点进行简单介绍。
何为分层聚类分析?
当我们在网上搜“聚类分析”时,跳出来的第一句话就是“聚类分析是一种无监督学习的方法,旨在将数据集中的样本划分为具有相似特征的不同组”。
问题来了,什么是无监督式学习?和监督式学习有什么区别?
简单来讲,有监督学习就像老师教孩子识别苹果和香蕉,给出明确的“这是苹果”、“那是香蕉”的指示,孩子学会了根据这些标签来分类。
而无监督学习则是一群孩子在沙滩上玩耍,没有大人告诉他们怎么玩,他们自己分群、堆沙堡或挖沙子,形成了自然的群体和活动模式。
如果公式的角度,我们可以从最简单的线性回归来理解:
Y=aX+b
公式中的Y为响应变量向量,X为自变量向量,a为系数,b为截距。将所有数据都告知,得出最后的Y,这就是一个简单的有监督式学习的公式。
而无监督式学习呢,就是没有Y这个响应变量,只有自变量X。而是通过自变量X之间的一些数据特性进行聚类,降维,关联规则学习。
我们今天要说的层次聚类(Hierarchical Clustering)就是聚类分析中的一种。层次聚类目的是把每个数据点作为一个独立的簇开始,然后逐步合并最相似的簇,直到所有的数据点被合并到一个簇中或达到了预定的簇。
举个例子,在200个水果中有苹果,葡萄,龙眼,橙子,西瓜找出类似的。那聚类会更具形状,大小,颜色来把这些水果分组。如果目标是分成3组,那可能开始时200个水果会按各自的大小,颜色聚集到同一个簇中,最终可能以葡萄和龙眼组,苹果和橙子组,西瓜组分成3个大组。
文章内容
接下来将对文章内容进行简单介绍。
暴露于环境臭氧污染会造成健康损失甚至死亡,两者都是世界范围内疾病负担的主要危险因素。因此本文的研究团队基于GBD 2019的数据,综合综合评价臭氧污染相关疾病负担。
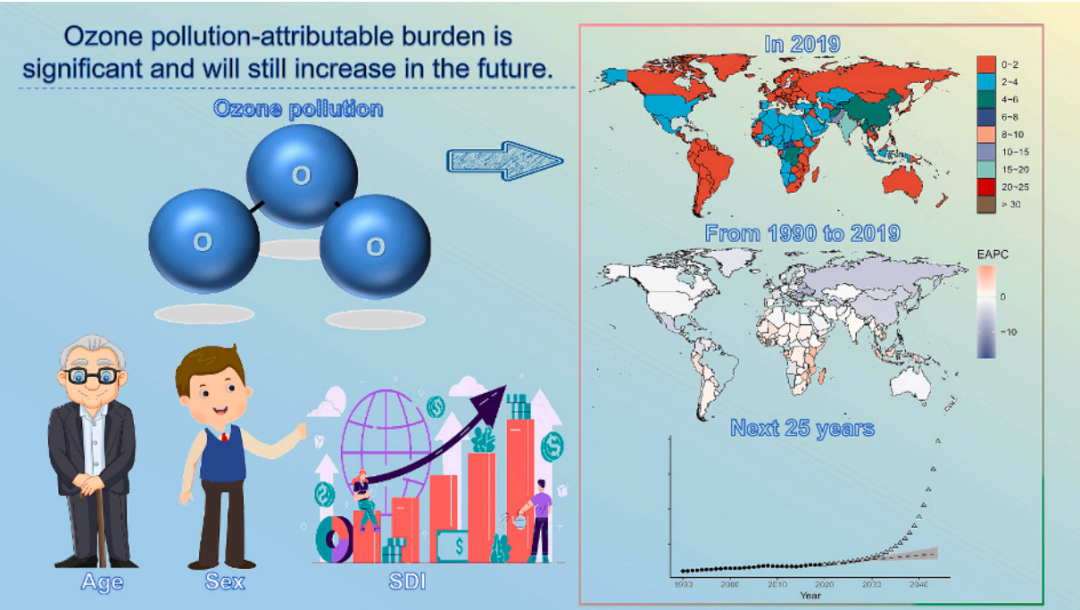
初步分析表明,2019年,臭氧污染导致全球365,222人死亡,6,210,145人死亡,占全球死亡人数的0.65%,占全球DALYs的0.24%。
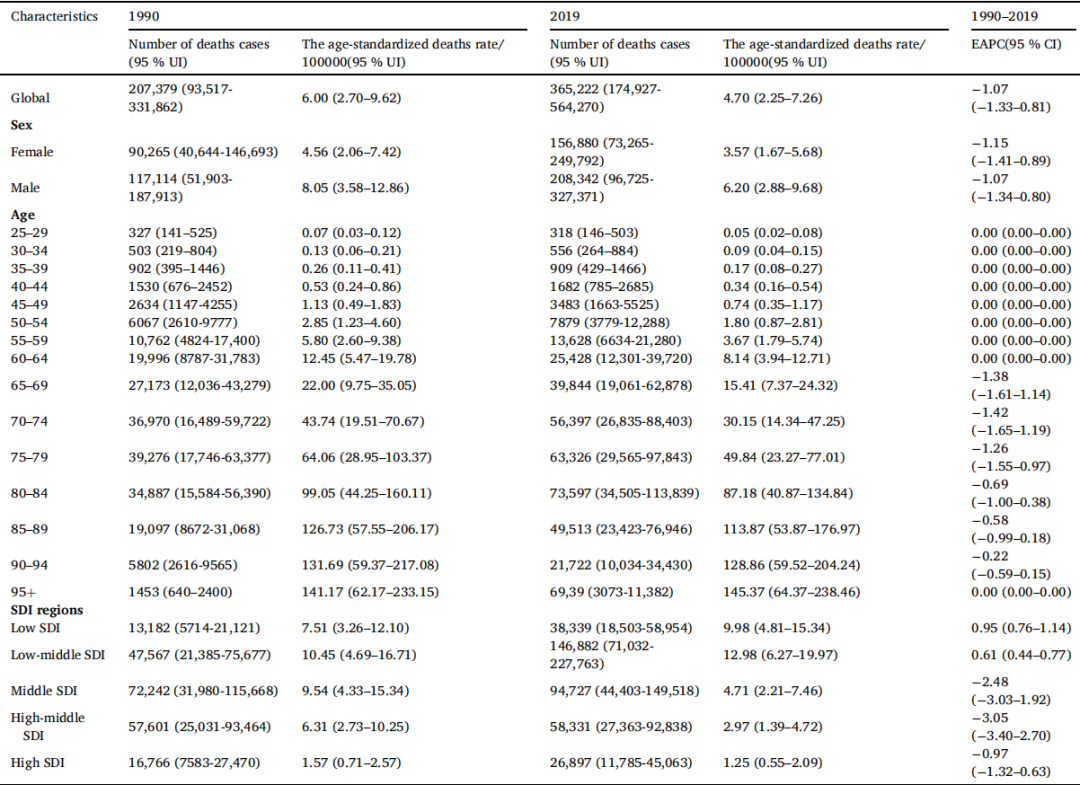
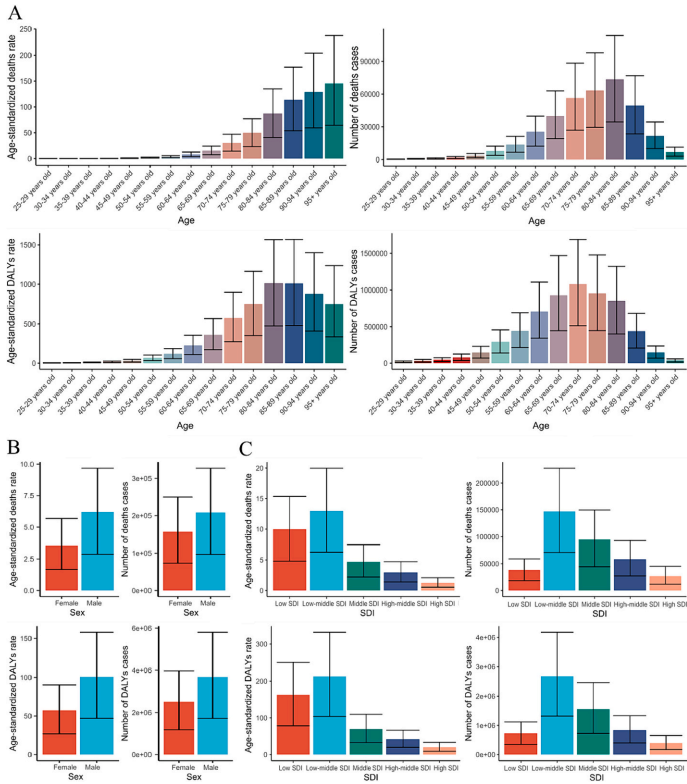
研究团队发现,疾病负担随着年龄的增长而持续增加,其中男性为高危人群,中低社会人口指数(SDI)区域为高危区。
由于臭氧污染的疾病负担在GBD区域和各国之间差别很大,因此研究团队使用聚类分析评价全球疾病负担研究(GBD)地区相关疾病负担的变化规律。
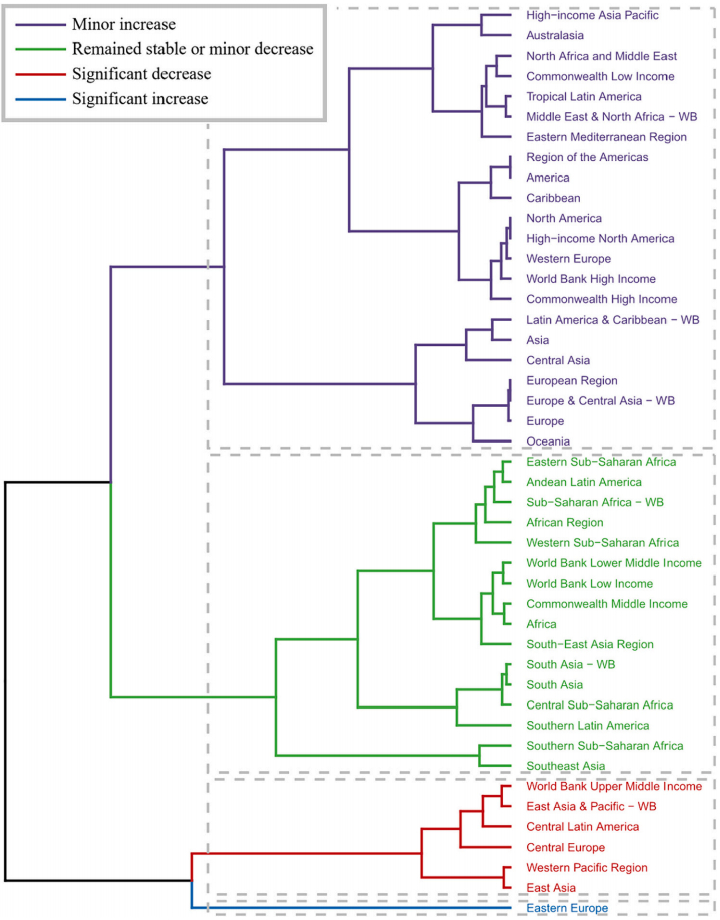
结果发现,2019年,与1990年相比,死亡人数和残疾病例数分别增长了76.11%和56.37%。
最后,使用率年龄-时期-队列(APC)模型和贝叶斯年龄-时期-队列(BAPC)模型预测未来25年的疾病负担。结果显示,从2020年到2044年,男女死亡病例数和残疾调整生命年病例数仍将增加。
综上所述,如今环境臭氧污染已经威胁到全球公众的健康。应考虑全球具体情况,制定更积极有效的战略措施。
总之,将分层聚类方法应用于GBD数据库的分析中,不仅可以细化数据的分层结构,丰富研究成果的多样性,增强数据可视化的效果,从而使研究报告更加具有创新性和说服力。

详情请点击下方:















 552
552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









