






倾向得分匹配法是通过对样本建模(logit模型)得到倾向性得分,通过倾向性得分为试验组在对照组中找到最接近的样本,从而进行研究的。
倾向得分匹配在真实世界临床研究用途越来越广泛,它是一种事后推动组间比较均衡化的方法。但是对样本量要求会高一点,如果样本太小,会导致处理组许多样本在控制组中找不到能匹配的样本,因此,对于样本量充足的研究,可以考虑一下PSM法来控制混杂偏倚。
接下来通过一份是实操数据集为大家详细介绍PSM法控制混杂的全套分析流程,从基线表——PSM——PSM后的回归分析,通通一文搞定!
一、实操案例介绍
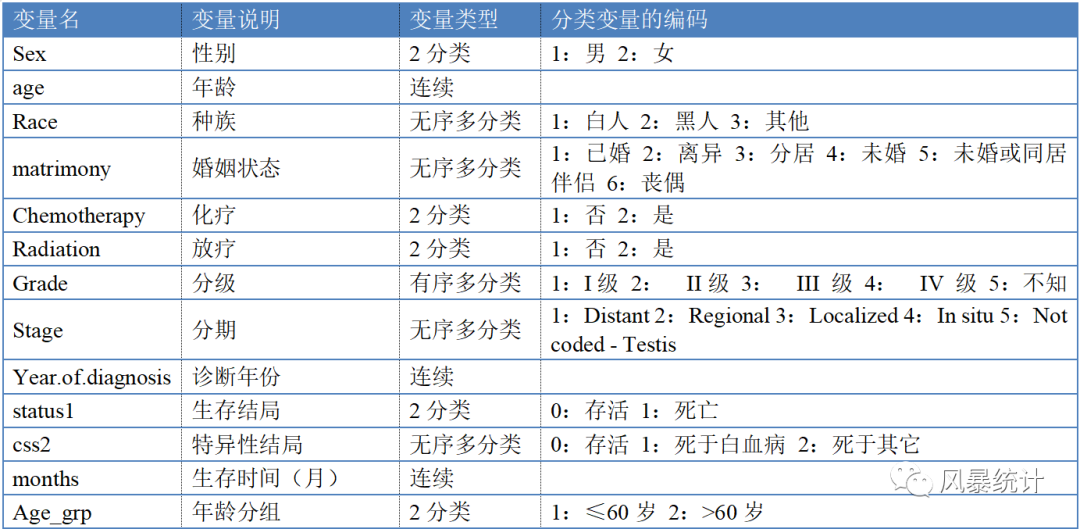
数据集来源于seer公共数据库的一份白血病数据,相关变量及对应编码如下。(如需获取实操数据,可在“医学论文与统计分析”公众号后台回复“seer白血病”)
二、R语言实操
1.安装加载R包
本次实操,我们需要先对数据进行倾向性得分匹配,再对匹配后的数据开展生存分析,分析主要用到以下R包,其中“MatchIt”包用于倾向性得分匹配,“survival”和"survminer"是生存分析中的常用包,“autoReg”是一款功能清大的包,各种回归分析不在话下,建议诸位同学可以自行探索一下。(如需获得本次实操代码,可在“医学论文与统计分析”公众号后台回复“seer白血病”)
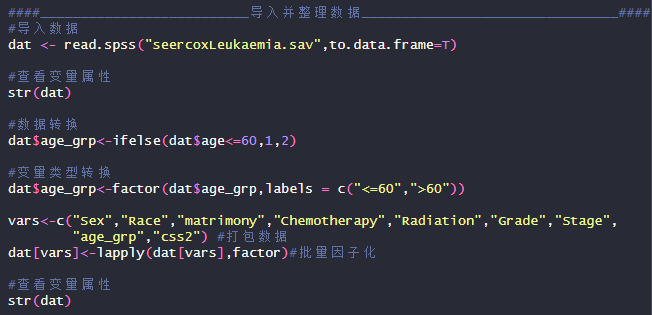
2.导入并整理数据
导入数据后,对数据的处理主要包括数据的重编码,数值型数据在R语言分析中会更加灵活;定量数据转分类以及变量类型转换。
3.基线差异性分析
这里用到了tableone,这个包可分组给出变量的均值(标准差)/频数(频率)以及组间比较的结果,比较遗憾的是并不显示统计量。

代码解读:“vars”设定要描述统计的变量,”strata”指定分组变量,”data”设定数据集,”factorVars”指定分类变量。
4.倾向性得分匹配
首先,根据研究需要选择需要匹配的变量,其中~之前的变量(如chemotherapy)是分组变量,也是我们要研究的关键变量,~之后的变量则是其他混杂变量。
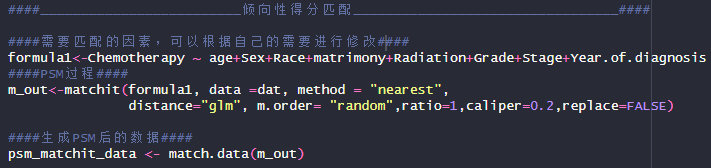
代码解读:matchit(formula, data = NULL, method = “nearest”,distance = “glm”, m.order = NULL, ratio = 1,caliper = NULL, replace = FALSE)中,“method”指匹配使用的方法,这里用到了“nearest"是最近邻匹配,也是此R包的默认选项,其他常用的匹配方法还有”exact“精确匹配,”full“完全匹配等。”distance“指用于计算倾向性评分的方法,默认值是“glm”也就是logistic回归法。”m.order"是匹配发生的顺序,这里选择“random”随机,这种情况下可能出现同样代码每次运行出现不同匹配结果的情况,默认为“largest”。“ratio"限制匹配比例,等于1为1:1匹配,数据差距悬殊时,也可以1:2或者1:3、1:4。"caliper”也就是卡钳值,默认为NULL,卡钳值越小,匹配越严格,匹配上的概率也有越小,但是卡钳值过大,同样不利于控制混杂,因此在实际操作中通常设为0.01-0.1,“replace”指对于允许匹配的方法,是否通过替换进行匹配,默认为F。
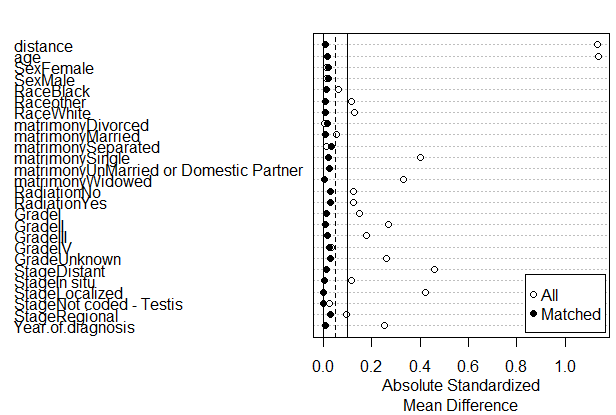
5.匹配后数据描述及均衡性比较
①SMD版

结果如下:
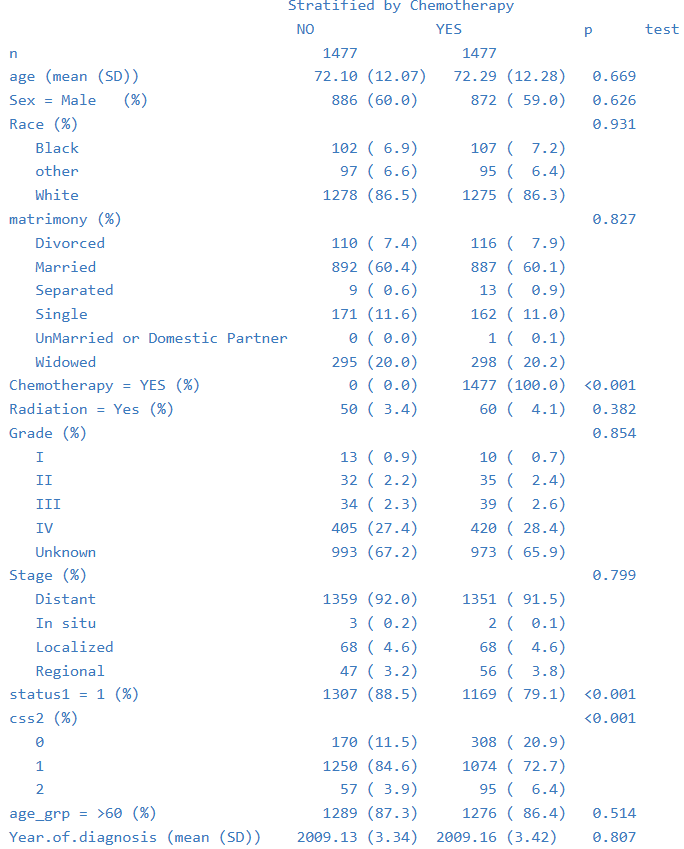
②P值版
这里同样用到了tableone包,代码比较简洁,好操作。

结果如下:
6.绘制KM曲线
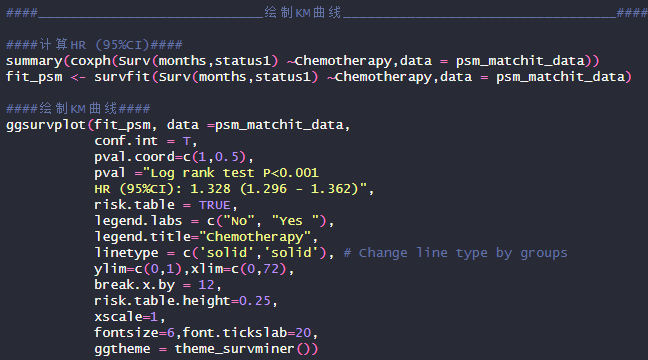
代码解读:”conf.int“为T,则显示置信区间,”pval “可以自定义在绘图上显示的文字,”risk.table“规定了风险表是否显示,T为显示,“legend.lab”与”legend.title"定义了图例的名字与分类名字,“linetype”定义线型大小,“xlim”与“ylim”定义了x轴与y轴的区间范围,“break.x.by”定义x轴最小单位,“ggtheme”定义了绘图主题。
结果如下:
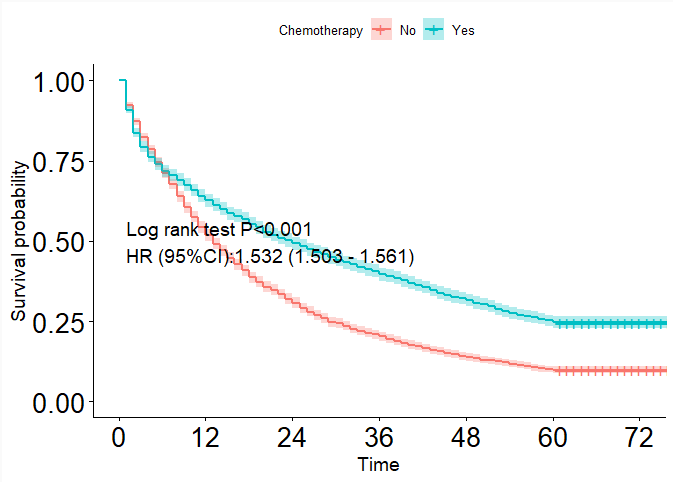
那么匹配后,当数据已经均衡可比了,我们应该怎么去分析呢?
倾向得分匹配后,出现了两种现象:第一,样本量减少了;第二,匹配带来了数据的聚集性,造成数据不独立。
这里针对“生存事件资料”,提出几种解决数据不独立、样本量减少的办法。生存事件资料倾向得分匹配后,可开展分层Cox回归、稳健Cox回归、Cox 脆弱模型(Frailty model)回归。
接下来,从普通cox回归到多种形式的cox回归都为大家介绍一下!
7.多因素cox分析
这里用到了survival包与autoReg包。survival包中的coxph函数比较好理解surv(生存时间,生存状态)~混杂因素,data=数据集)。autoReg包是一款功能强大的R包,可以一步到位实现批量单因素,多因素以及逐步回归法。

代码解读:autoReg函数可以自动根据设定的阈值控制变量进入多因素回归模型,如果不限制阈值,全部变量进入多因素回归,可将阈值设置为1,如threshold=1;加上“final= TRUE”表示增加逐步向后回归的结果。
8.匹配后cox回归分析——分层分析、脆弱模型、最佳稳健法
在Cox回归应用上,其实,最推荐的应该是稳健法Cox回归方法,下面汇总了各类方法的代码,大家可以都了解一下与普通cox回归代码略有不同。
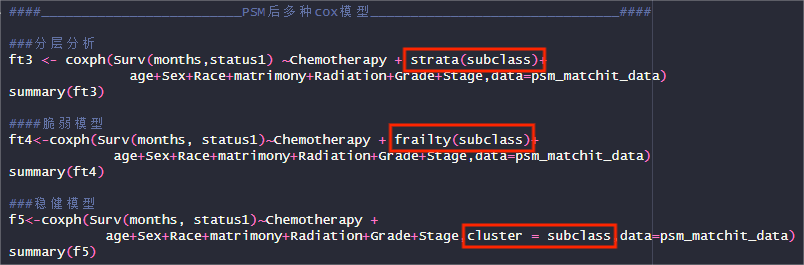
好的,以上就是我们本次代码复现的全部内容,包括基线表,KM曲线,PSM,匹配后的回归分析,足够一篇文章的主要统计内容,大家感兴趣的话,不妨试一试!
相关数据与代码已经放在“医学论文与统计分析”公众号后台,回复“seer白血病”即可获取。
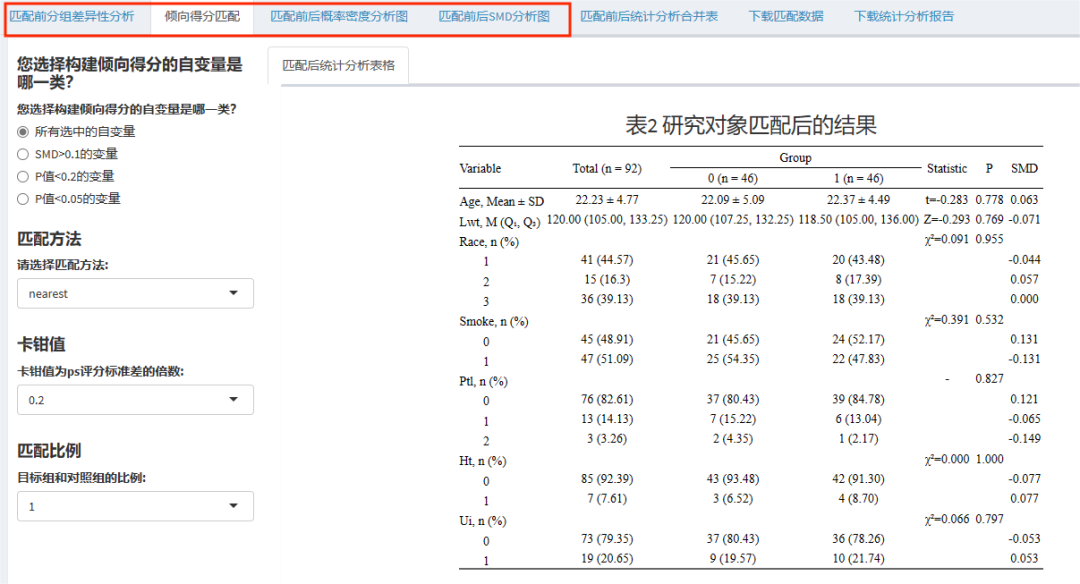
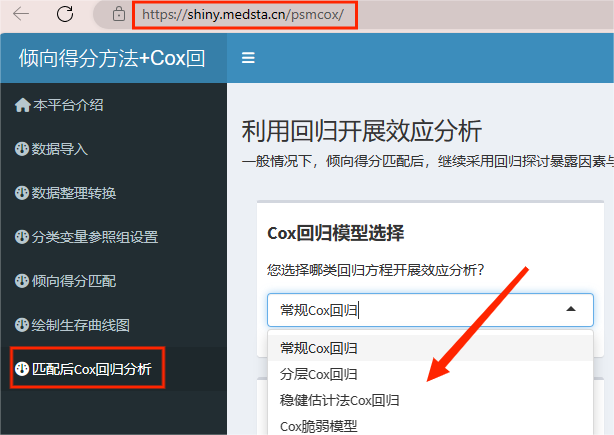
三、风暴统计平台一站式分析
以上统计方法在“风暴统计”平台均可实现,包括:
倾向性得分匹配
匹配前后SMD分析图
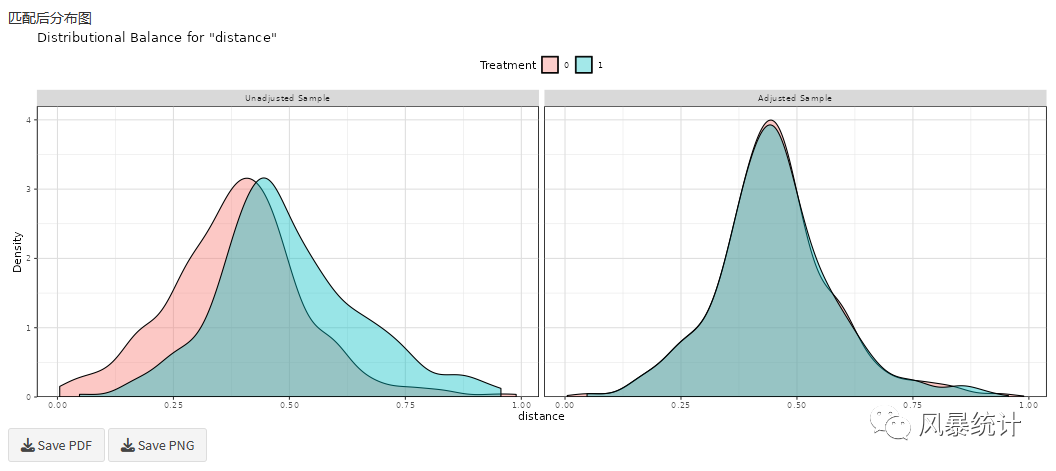
匹配前后概率密度分析图
绘制KM曲线
匹配前后差异性比较
匹配后的多种形式回归分析
一应俱全!真正实现菜单式操作,有兴趣不妨点击下方链接查看详细操作流程,快来试试吧!
以上就是本篇文章的全部内容啦!感兴趣的话,不妨来试试吧!
本公众提供各种科研服务了!
一、课程培训 2022年以来,我们召集了一批富有经验的高校专业队伍,着手举行短期统计课程培训班,包括R语言、meta分析、临床预测模型、真实世界临床研究、问卷与量表分析、医学统计与SPSS、临床试验数据分析、重复测量资料分析、nhanes、孟德尔随机化等10余门课。如果您有需求,不妨点击查看: |

















 1496
1496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









