







【本文的阅读时间约15分钟,希望大家耐心观看】
这是机器学习方法系列科普文章,由浙中大公卫徐老师撰写,往期推文可以看集合。
在众多机器学习模型中,决策树是最为简单直观的一种算法。它就像我们平常做决定时的过程,逐步排除可能的选项,最终得出结论。
今天这篇文章中,我们将结合图例讲解讲解决策树的结构、数学原理、具体构建和优化过程,让大家在理解时不至于太抽象,同时我们也会提供构建决策树预测模型的数据和代码,感兴趣的不妨尝试一下。
什么是决策树?
决策树(Decision Tree)是一类经典的机器学习监督模型,被广泛用于分类和回归问题,也是一些机器学习集成模型,例如随机森林、XGBoost模型的基本结构单元。
顾名思义,决策树模型名称的由来就是因为其和一颗树一样,从底部的根向上生长,每个分支代表一个规则,每片叶子表示一个最终结果。
此外,决策树模型是树状结构模型的总称,根据分支的样本集合纯度度量指标的不同分为不同算法,其中具有标志性的是ID3、C4.5和CART。
决策树的结构如下所示:
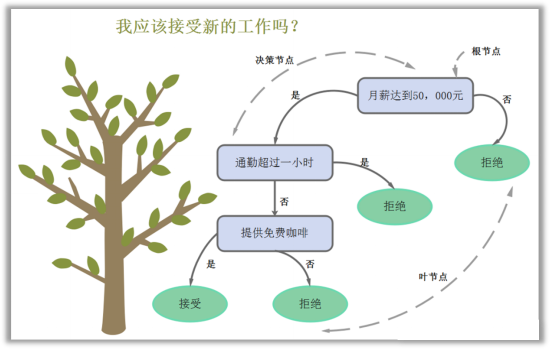
从上图中,我们可以看到决策树的构成包括:
根节点:是树的起点,代表整个数据集;
决策节点/内部节点:图1中的灰篮色框,每个灰蓝色框代表一条决策规则,根据这个规则将数据分成不同部分;
例如根据规则“月薪是否达到50000”将数据分成“达到”和“没有达到”两部分。
叶节点:图1中的绿色框,代表决策结果;
那么思考一个问题:图1中3条决策规则的顺序对于决策树来说要怎么确定呢?
这就要从决策树背后的数学原理来理解了。
决策树背后的数学原理
对这部分看着头大的读者可以跳过,只要记住:决策树是通过能够度量样本子集同质程度的指标来确定决策规则的顺序的,根据度量指标的不同对应不同决策树算法。
想理解深一点的读者不妨继续往下看,公式并不多。
决策树每个决策节点的划分都会产生两个或多个数据子集,我们必然是希望同一个子集中的数据“纯度”或者说同质度越高越好,不同子集间的区分度越高越好。
例如对于猫和狗的数据分类,我们用“叫声是否为汪汪汪”这一决策规则就能把两者完全区分开来,这样的决策规则我们希望离根节点越近越好。
度量样本集“纯度”的指标主要包括基于信息熵的信息增益和信息增益率,以及基尼指数,基于这三种“纯度”指标的决策树算法分别为ID3、C4.5和CART。
信息增益(information gain)
ID3算法是根据基于信息熵(information entropy)的信息增益来度量数据子集的“纯度”的。
假设数据集的结局变量Y有J个类别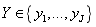 ,对于每个决策节点,数据集/数据子集D中每各个类别的占比为
,对于每个决策节点,数据集/数据子集D中每各个类别的占比为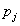
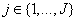 ,那么D的信息熵为:
,那么D的信息熵为:
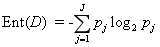
Ent(D)的值越小代表该节点中D的纯度越高。
例如D中只有一个类别的数据,那么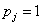 ,
,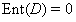 。
。
假设该节点的决策规则r有K个可能取值,那么数据集将被划分为子集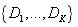 ,划分后所有数据子集信息熵的加权和则为:
,划分后所有数据子集信息熵的加权和则为:
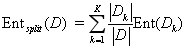 ,
,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1049
1049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









