






3月24日晚间,DeepSeek上线了小版本更新后的DeepSeek-V3模型。新模型的版本号为DeepSeek-V3-0324,官方也发布了通知。

据各大测评来看,在性能上,编程能力的优化成了最大亮点,新版本DeepSeek-V3生成前端代码的能力大大提升。
老郑比较好奇的是,在统计分析中,代码生成能力怎么样,和RI比呢?来测试一下!
我分别用DeepSeek-V3-0324和DeepSeek-R1版本,给我写一段logistic回归多模型策略的R语言函数,我提供了示例数据以及供它参考的多模型策略word表格,看看两个版本生成的R语言函数哪个更准确,更加方便!
1
DeepSeek-V3-0324
DeepSeek官网进入后,关闭深度思考,即可体验DeepSeek-V3-0324。输入指令,上传示例数据和参考表格。
以下是DeepSeek-V3-0324版本给我的R语言函数!
library(tidyverse)
library(broom)
library(flextable)
library(officer)
library(gtsummary)
perform_enhanced_logistic_analysis <- function(data, outcome_var, exposure_var,
adj_vars_model2, adj_vars_model3,
output_file = "logistic_results.docx")
{
# 数据预处理
data <- data %>%
mutate(across(where(is.character), as.factor)) %>%
mutate(across(where(is.factor), ~fct_explicit_na(.x, na_level = "Missing")))
# 确保结果变量是因子且正确编码
data[[outcome_var]] <- as.factor(data[[outcome_var]])
if (!all(levels(data[[outcome_var]]) %in% c("0", "1"))) {
data[[outcome_var]] <- factor(data[[outcome_var]], levels = c(0, 1))
}
# 模型1: 粗模型(仅暴露变量)
formula1 <- as.formula(paste(outcome_var, "~", exposure_var))
model1 <- glm(formula1, data = data, family = binomial())
# 模型2: 调整模型(X1,X2,X3)
formula2 <- as.formula(paste(outcome_var, "~", exposure_var, "+",
paste(adj_vars_model2, collapse = "+")))
model2 <- glm(formula2, data = data, family = binomial())
# 模型3: 完全调整模型(所有协变量)
formula3 <- as.formula(paste(outcome_var, "~", exposure_var, "+",
paste(adj_vars_model3, collapse = "+")))
model3 <- glm(formula3, data = data, family = binomial())
# 提取模型结果的函数
extract_model_results <- function(model, var_name) {
tidy_results <- broom::tidy(model, conf.int = TRUE, exponentiate = TRUE)
var_results <- tidy_results %>% filter(term == var_name)
if (nrow(var_results) == 1) {
return(list(
OR = sprintf("%.2f", var_results$estimate),
CI = sprintf("%.2f (%.2f-%.2f)",
var_results$estimate,
var_results$conf.low,
var_results$conf.high),
P = ifelse(var_results$p.value < 0.001, "<0.001",
sprintf("%.3f", var_results$p.value))
))
} else {
return(list(OR = NA, CI = NA, P = NA))
}
}
# 获取每个模型的结果
res1 <- extract_model_results(model1, exposure_var)
res2 <- extract_model_results(model2, exposure_var)
res3 <- extract_model_results(model3, exposure_var)
# 创建结果数据框
result_df <- tibble(
Variables = exposure_var,
Model1_OR = res1$OR,
Model1_CI = res1$CI,
Model1_P = res1$P,
Model2_OR = res2$OR,
Model2_CI = res2$CI,
Model2_P = res2$P,
Model3_OR = res3$OR,
Model3_CI = res3$CI,
Model3_P = res3$P
)
# 创建专业表格
ft <- flextable(result_df) %>%
set_header_labels(
Variables = "Variables",
Model1_OR = "OR", Model1_CI = "95% CI", Model1_P = "P*",
Model2_OR = "OR", Model2_CI = "95% CI", Model2_P = "P*",
Model3_OR = "OR", Model3_CI = "95% CI", Model3_P = "P*"
) %>%
add_header_row(
values = c("", "Model 1", "Model 2", "Model 3"),
colwidths = c(1, 3, 3, 3)
) %>%
theme_booktabs() %>%
align(align = "center", part = "all") %>%
fontsize(size = 10, part = "all") %>%
bold(part = "header") %>%
autofit()
# 创建Word文档
doc <- read_docx() %>%
body_add_par("Logistic回归多模型策略", style = "heading 1") %>%
body_add_flextable(ft) %>%
body_add_par("OR: Odds Ratio; CI: Confidence Interval", style = "Normal") %>%
body_add_par("Model 1: Crude model (unadjusted)", style = "Normal") %>%
body_add_par(paste("Model 2: Adjusted for", paste(adj_vars_model2, collapse = ", ")),
style = "Normal") %>%
body_add_par(paste("Model 3: Fully adjusted for",
paste(adj_vars_model3, collapse = ", ")),
style = "Normal")
# 保存文档
print(doc, target = output_file)
# 返回结果
return(list(
models = list(model1 = model1, model2 = model2, model3 = model3),
results = result_df,
table = ft
))
}
# 使用示例
# 读取数据
data <- read.csv("示例数据.csv")
# 定义变量
outcome_var <- "outcome"
exposure_var <- "V_D"
adj_vars_model2 <- c("X1", "X2", "X3")
adj_vars_model3 <- c("X1", "X2", "X3", "X4", "X5", "X6", "X7", "X8", "X9", "X10", "X11")
# 执行分析并生成Word文档
results <- perform_enhanced_logistic_analysis(
data = data,
outcome_var = outcome_var,
exposure_var = exposure_var,
adj_vars_model2 = adj_vars_model2,
adj_vars_model3 = adj_vars_model3,
output_file = "logistic_regression_results.docx"
)复制到R语言中,直接跑出了word文档,结果如下:
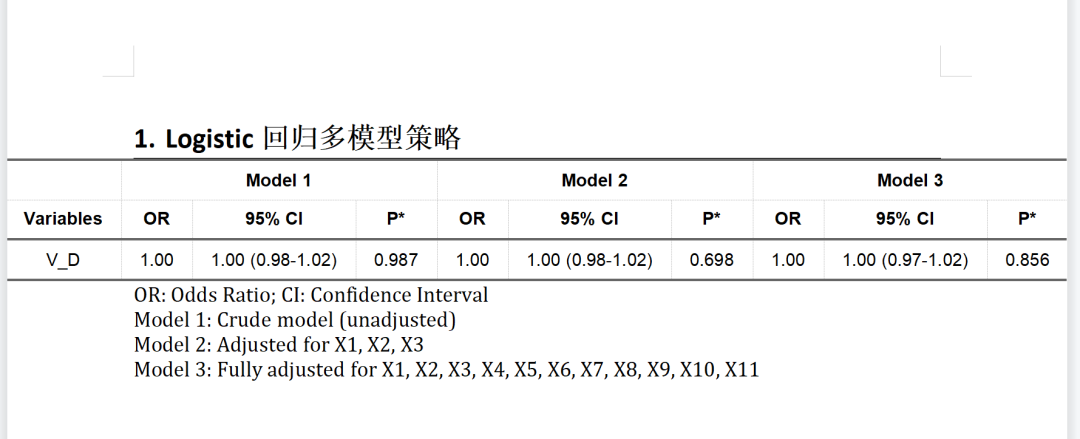
2
DeepSeek-R1
同样的指令和材料输入到DeepSeek-R1版本。
也给了我一段R语言函数
library(tidyverse)
library(flextable)
library(officer)
create_logistic_models <- function(data, outcome_var) {
# 数据预处理
df <- data %>%
mutate(across(c(X5, X6, X7, X8, X9, X10, X11), as.factor))
# 定义模型公式
formula_m1 <- as.formula(paste(outcome_var, "~ V_D"))
formula_m2 <- as.formula(paste(outcome_var, "~ V_D + X1 + X2 + X3"))
formula_m3 <- as.formula(paste(outcome_var, "~ V_D + X5 + X6 + X7 + X8 + X9 + X10 + X11 + X1 + X2 + X3 + X4"))
# 拟合模型
m1 <- glm(formula_m1, family = binomial(), data = df)
m2 <- glm(formula_m2, family = binomial(), data = df)
m3 <- glm(formula_m3, family = binomial(), data = df)
# 结果提取函数
extract_results <- function(model) {
coefs <- coef(summary(model))[-1, ] # 排除截距
or <- exp(coefs[, "Estimate"])
ci <- exp(confint(model)[-1, ])
p_value <- coefs[, "Pr(>|z|)"]
data.frame(
OR = sprintf("%.2f", or),
CI = sprintf("(%.2f-%.2f)", ci[,1], ci[,2]),
P = ifelse(p_value < 0.001, "<0.001", sprintf("%.3f", p_value))
}
# 提取各模型结果
res_m1 <- extract_results(m1)["V_D", ]
res_m2 <- extract_results(m2)["V_D", ]
res_m3 <- extract_results(m3)["V_D", ]
# 构建结果表格
result_table <- data.frame(
Variables = "V_D",
Model1 = paste(res_m1$OR, res_m1$CI, res_m1$P, sep = "\n"),
Model2 = paste(res_m2$OR, res_m2$CI, res_m2$P, sep = "\n"),
Model3 = paste(res_m3$OR, res_m3$CI, res_m3$P, sep = "\n")
)
# 创建Word表格
ft <- flextable(result_table) %>%
set_header_labels(Variables = "Variables",
Model1 = "Model1\nOR (95%CI) P",
Model2 = "Model2\nOR (95%CI) P",
Model3 = "Model3\nOR (95%CI) P") %>%
theme_booktabs() %>%
autofit()
# 添加表格注释
ft <- add_footer_lines(ft, values = c(
"OR: Odds Ratio, CI: Confidence Interval",
"Model1: Crude model",
"Model2: Adjusted for X1, X2, X3",
"Model3: Adjusted for X5-X11 and X1-X4"))
# 输出Word文档
save_as_docx(ft, path = "Logistic_Models_Table.docx")
return(ft)
}
# 使用示例
data <- read.csv("示例数据.csv")
create_logistic_models(data, "outcome")但是他报错了。

于是我又追问。
DeepSeek-R1重新提供了一段代码,我跑出了想要的结果,但可能追问时没有说清楚,所以没有导出至word。
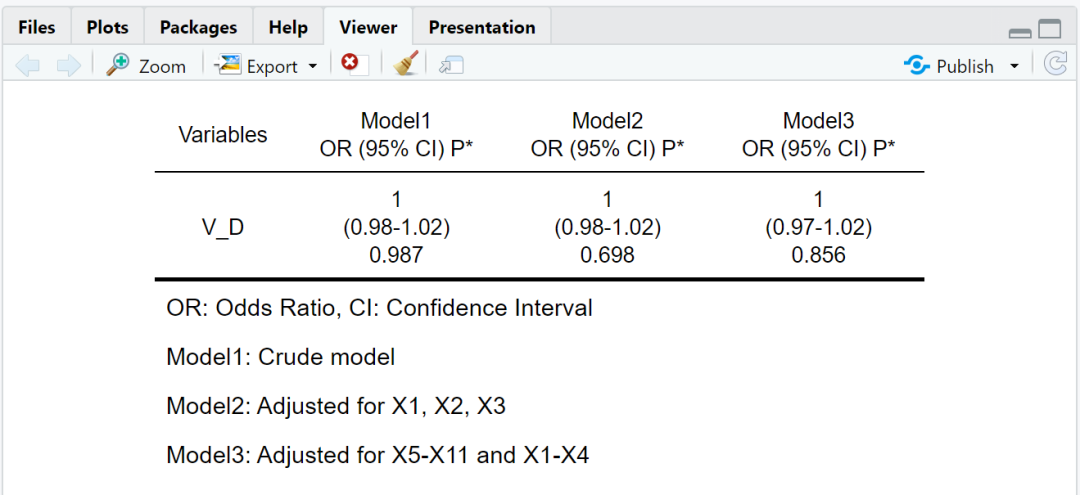
3
Zstats风暴统计
输出的结果是否正确呢?我们来Zstats风暴统计平台核实一下。
(1)复制以下链接到浏览器打开2025版Zstats风暴统计平台,Logistic回归控制混杂偏倚界面。
logistic回归控制混杂:http://zstats.medsta.cn/logisticcon/
(2)导入示例数据
(3)选入相应的变量,点击分析即可
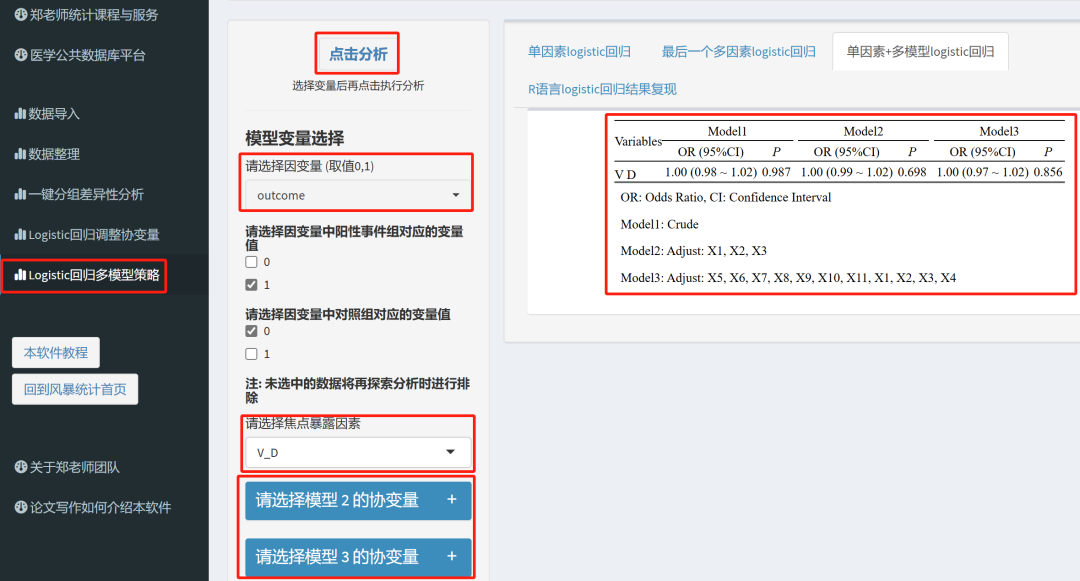
多模型策略三线表已经给出!
首先,可以看到,结果上,无论是DeepSeek-V3-0324还是DeepSeek-R1,都没有问题;
其次,就体验感而言,貌似V3更胜一筹,但这也是我一次的体验,哈哈哈,大家可以也试试;
还有就是,追问V3不会轻易卡顿,R1虽然没有以前那样只能问一次,但是我再想追问时已经服务器繁忙了!
真是太智能了,这段函数自己写可能要花个一周时间,借助DeepSeek半小时搞定!


郑重声明
Zstats-AI 平台
√浙中医大统计老师郑卫军主持
√ 基于R语言软件开发
√ 免费使用,无需注册直接使用
√ 一键生成发表级图表
www.medsta.cn/software
(电脑端浏览器打开)
有人问,郑老师,免费你怎么赚钱?郑老师不是有培训课程嘛?我就打打培训广告,你们这个总没有意见吧?



















 6636
6636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









