







2025年3月21日,医学顶刊《BMJ》(医学一区top,IF=93.6)发表了一篇方法学文章,题为:“How to use directed acyclic graphs: guide for clinical researchers”,介绍了如何构建、解释和展示有向无环图作为临床研究的一部分,以及它们如何帮助传达研究的优势或局限性。
前面我们已经介绍过这篇文章,今天我们整理了整篇的实用指南!
顶刊BMJ杂志最新发布:临床研究者如何使用有向无环图(DAG)?干货满满!
一、引言:DAGs为何重要?
有向无环图(Directed Acyclic Graphs, DAGs)是一种在因果推断领域中广泛应用的工具,尤其在临床研究中近年来备受重视。它通过图形化的方式,帮助研究者清晰地表达变量之间的因果关系假设,从而优化研究设计和数据分析过程。这篇文章旨在为临床研究者提供一份系统且实用的指南,帮助他们在研究设计、数据分析和结果解释中有效运用DAGs。
DAGs的核心价值在于,它迫使研究者明确提出关于变量之间因果结构的假设。通过节点(代表变量,如暴露、结局或协变量)和箭头(表示因果方向),DAGs构建出无环的因果路径,能够帮助研究者识别混杂因子(confounders)、中介变量(mediators)、选择偏倚(selection bias)以及其他潜在的偏倚来源。
这种显性化的假设表达,不仅提高了研究的透明度,还为选择适当的统计调整方法提供了理论依据。例如,在研究重度饮酒是否导致死亡时,社会经济地位可能同时影响饮酒行为和死亡风险,如果不加以控制,就可能导致结果偏倚。DAGs通过可视化这些关系,帮助研究者设计更严谨的分析策略,避免因混杂或选择偏倚导致的错误结论。
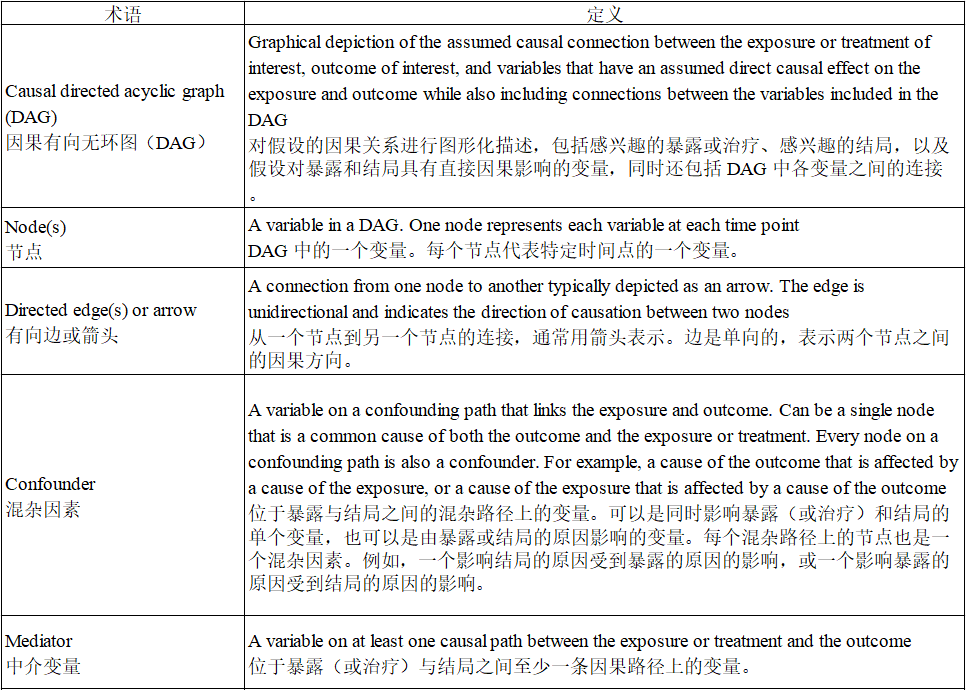
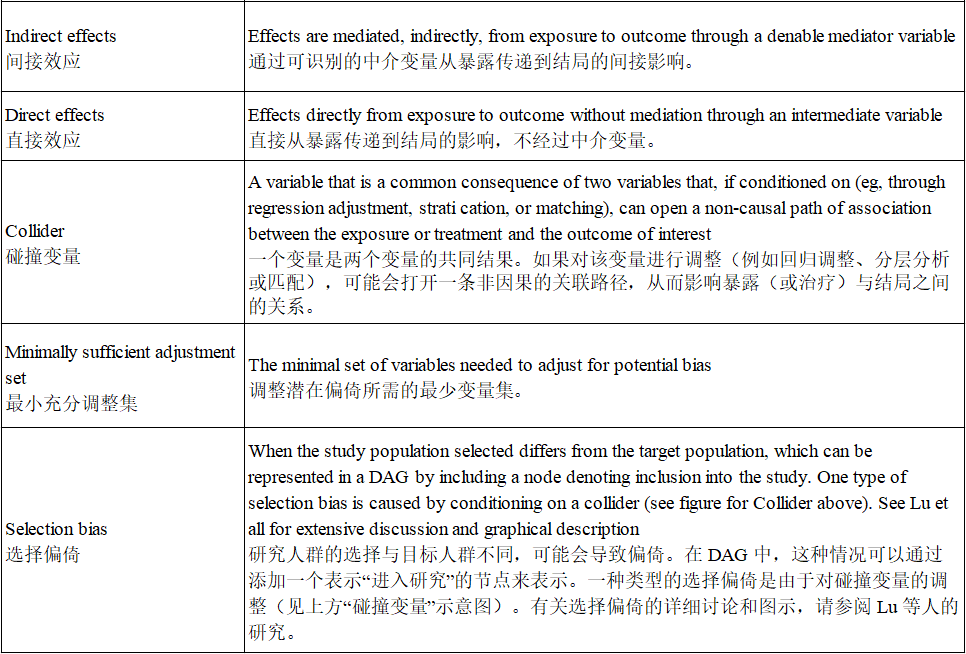
因果有向无环图(DAGs)是一种用于展示变量之间假设因果结构的图示。这些图可以用来说明可能的原因(例如,一种行为或医学干预,在本文中称为“暴露”)与可能的结果(例如,疾病的发生或未发生,在本文中称为“结局”)之间的假设联系。
尽管因果图已经被使用了很长时间,但 DAG 在流行病学研究中的历史相对较短,然而,它已广泛应用于研究暴露与结局关联背后的因果结构。DAG 可用于多种目的,例如帮助识别混杂因素、评估潜在的选择偏倚,以及理解测量误差和缺失数据可能对效应估计的影响。
二、DAGs的定义
DAG建立在图论基础上,由几个基本元素组成。
有向无环图的定义
DAGs核心要素:

节点(Nodes):每个节点代表研究中的一个变量,可以是暴露(如重度饮酒)、结局(如死亡),或者任何协变量(如社会经济地位、饮食质量)。若变量随时间变化,每个时间点的测量值需用独立的节点表示。例如,基线饮酒量和随访时的饮酒量应为两个节点。
有向边(Directed Edges)或箭头:箭头连接两个节点,表示变量之间的因果关系具有单向性。箭尾指向箭头的方向表明因果效应,例如,“社会经济地位→重度饮酒”表示社会经济地位影响饮酒行为。箭头的存在并不意味着效应大小或形式,而是表明至少对某些个体存在因果关系。
无环性(Acyclic):DAGs不允许路径形成闭环,即不存在从一个节点出发、通过箭头回到自身的循环路径。这是因为因果关系隐含时间顺序,箭尾的变量必须在时间上先于箭头的变量。例如,“死亡→社会经济地位”是不可能的,因为死亡无法反过来影响过去的社会经济状况。
以研究重度饮酒与死亡的关系为例,一个简单的DAG可能包含“重度饮酒”、“死亡”和“社会经济地位”三个节点,箭头从社会经济地位分别指向重度饮酒和死亡,表示它作为混杂因子的作用。这种结构化的表达方式为后续分析奠定了基础。
因果关系的表达:
DAGs通过箭头的连接方式表达变量之间的因果效应,主要分为以下三种类型:
直接效应(Direct Effects):一个变量直接影响另一个变量。例如,在图1A中,社会经济地位直接指向死亡,表示其对死亡有直接的因果效应。箭头的存在意味着至少对部分个体存在效应,但不指定效应的大小(如正向或负向)、方向或数学形式(如线性、二次关系)。
间接效应(Indirect Effects):因果效应通过中介变量传递。例如,在图1B中,社会经济地位通过“久坐工作”间接影响死亡,形成路径“社会经济地位→久坐工作→死亡”。这种间接效应通常涉及多个变量之间的链式关系。
总效应(Total Effects):直接效应与所有间接效应的总和。例如,社会经济地位对死亡的总效应包括其直接效应(社会经济地位→死亡)和通过久坐工作的间接效应(社会经济地位→久坐工作→死亡)。
DAGs的无环特性避免了时间悖论。例如,若允许“死亡→社会经济地位”的箭头,则意味着未来事件影响了过去,这在因果逻辑中不可行。如果研究涉及时间维度,可以通过多个节点表示不同时间点的变量,例如基线社会经济地位和随访时的社会经济地位。
可以用一个简化的例子来说明,该例子调查了大量饮酒对全因死亡率结果的影响。
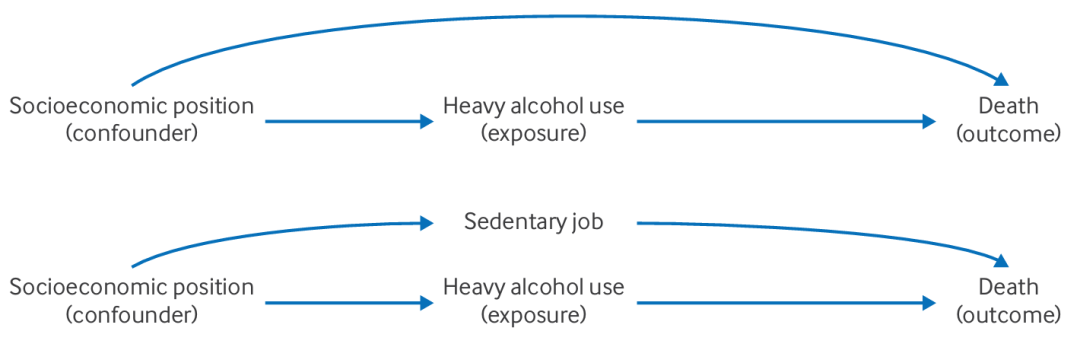
在有向无环图(DAG)中展示混杂的示例:以重度饮酒为暴露,死亡为结局,社会经济地位为混杂因素。
图1上:简单混杂,社会经济地位被视为混杂因素,直接影响重度饮酒和死亡。它是暴露和结局的共同原因,形成一条混杂路径(confounding path)。例如,低社会经济地位可能增加饮酒风险,同时也提高死亡率。如果不调整社会经济地位,饮酒与死亡的关联可能被夸大或掩盖。
图1下:复杂混杂,久坐工作被视为混杂因素,因为它位于暴露与结局之间的一条混杂路径上。社会经济地位通过“久坐工作”间接影响死亡。久坐工作本身也成为混杂路径上的节点,因为它既受社会经济地位影响(低社会经济地位者更可能从事久坐工作),又影响死亡(久坐增加健康风险),同时与重度饮酒相关(久坐者可能更易饮酒)。这种多层关系增加了识别混杂的复杂性。
这些图表明,混杂因子可能以简单或复杂的方式影响因果关系估计。研究者需要根据具体的研究问题判断每个变量的角色(如暴露、结局或混杂因子),并确保DAG反映合理的因果假设。
三、有向无环图在临床研究中的应用
有向无环图(DAG)之所以有用,是因为它们迫使研究者明确假设变量之间关联背后的因果结构。因此,DAG能够识别出哪些变量应该被调整,同样重要的是,也能识别出根据研究者的假设哪些变量不应该被调整。
在下文中,我们将描述研究者如何利用DAG来识别和描述分析中不同潜在变量的作用:暴露、结果、混杂因素、最小充分调整集、中介变量、选择、碰撞变量以及效应修饰因子。
有向无环图的应用
1.识别混杂因子与最小充分调整集
混杂因素是位于混杂路径上的变量,这条路径包括图中暴露的共同原因和结局节点。
这条路径可能就像DAG中直接指向暴露和结果的箭头节点一样简单(即,图1A中社会经济地位是暴露和结果的混杂因素和直接共同原因)。
混杂因素也可能是路径上的一个节点,该节点包含导致暴露和结果的共同原因。例如,在图1B中,社会经济地位是一个混杂因素,尽管它通过久坐不动的工作节点间接导致死亡。
此外,久坐不动的工作是一种混杂因素,因为它处于导致结果的共同原因路径上,并且通过其直接原因——社会经济地位——与暴露有关。这些混淆路径有时被称为后门路径,尽管并非所有后门路径都是混淆路径。
混杂因素引起了它们所引起的节点之间的关联,当目标是估计一个节点对另一个节点的因果关系时,这可能会导致偏差。例如,在图1中,社会经济地位是酗酒与死亡之间关联的混杂因素。这种混淆意味着酗酒与死亡之间的粗略关联(例如,不考虑社会经济地位的混淆)将是对酗酒与死亡因果关系的有偏差估计。
最小充分调整集是一组测量变量,调整后它足以消除由于混杂引起的偏差,只留下从暴露到结果的因果路径(即,从暴露到结果的所有路径都是由指向同一方向的箭头形成的)这个集合被认为是最小的,因为从中去除任何变量都会导致残留混淆。
即使没有测量相关变量,也可以找到最低限度的充分调整集。例如,图3,它在图1中添加了一个未测量的饮食质量变量,研究重度饮酒与死亡的关系,社会经济地位和饮食质量均为混杂因子,最小充分调整集为同时调整社会经济地位和饮食质量。如果饮食质量未测量,则需要通过敏感性分析评估残余混杂的影响。
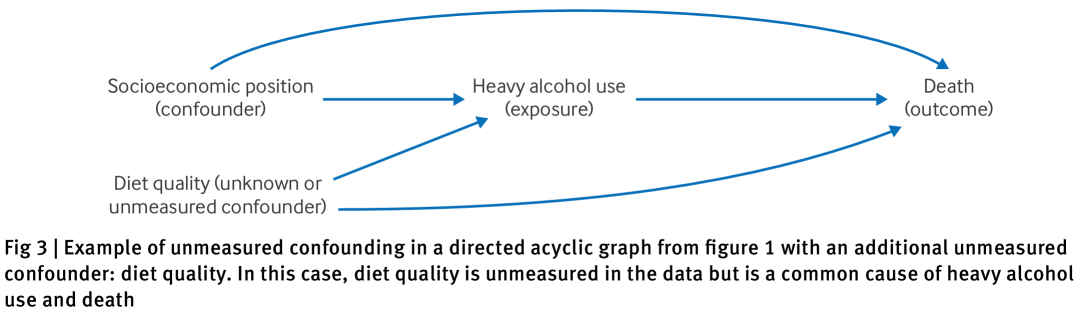
这些示例说明了如何利用有向无环图(DAG)帮助明确因果假设,并协助识别可能的调整集以减轻偏差。
重要的是,可能不存在仅包含已测量变量的最小充分调整集。例如,在图1B中,存在两个最小充分调整集,每个调整集仅包含一个变量:(1)社会经济地位和(2)久坐工作。因此,即使暴露与结果之间的真实共同原因(在此为社会经济地位)未被测量,仍然可以通过调整久坐工作来消除混杂偏差。
然而,在图3中,只有一个最小充分调整集,包含社会经济地位和饮食质量——没有其他替代集可以绕过对这些变量进行条件控制的需求。检测这些可能缺少必要变量或未测量变量的情况,有助于研究人员评估其结果中可能存在的偏差,设计敏感性分析,并考虑替代估计方法(例如,工具变量或负对照)。
2. 识别中介变量
中介变量位于暴露与结局之间的因果路径上,传递间接效应。对中介变量进行调整可能会导致对暴露总体效应的估计出现偏差,因为它会阻断中介(间接)效应。
例如,在图4中,大量饮酒不仅会影响死亡率,还会影响快餐消费,而快餐消费又反过来影响死亡率。因此,大量饮酒的总效应部分是由于其直接效应(由从大量饮酒到死亡的箭头表示),部分是由于间接效应,即从大量饮酒到快餐消费再到死亡的路径(由从大量饮酒到吸烟再到死亡的箭头表示)。由此可以得出结论,如果目标是估计大量饮酒对死亡率的总效应,那么对快餐消费进行调整可能会导致偏差。此外,对中介变量进行调整还可能导致碰撞偏差(见下文)。若目标是仅估计直接效应,则需要调整中介变量以隔离直接路径。
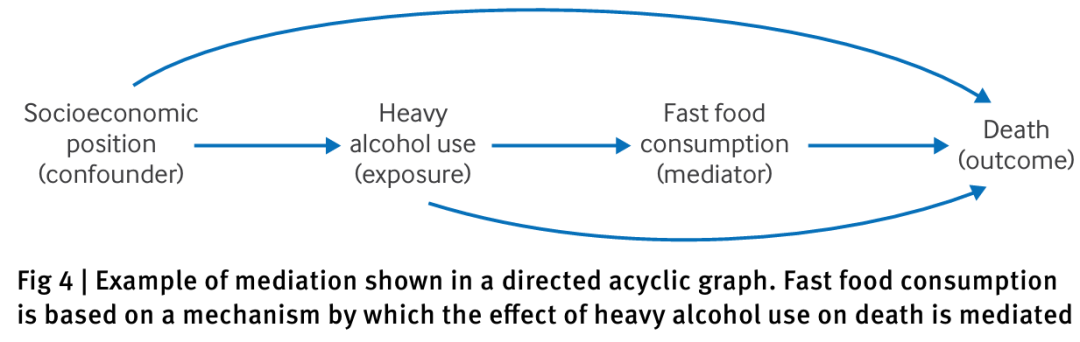
3.识别碰撞变量和选择偏差
当从目标人群中选取样本时,如果样本中估计的因果效应与目标人群中的真实因果效应不同,就可能发生选择偏差。
选择偏差的潜在来源包括:
进入研究的选择(即不同组之间不同的资格标准)
进入研究后数据缺失(可能由于失访或未回答问卷部分)
有意的分析分层或限制(例如,用于估计亚组特定效应)。
一种特殊的选择偏差形式与由两个其他节点导致的节点相关(即有两个或更多箭头指向它),这种节点被称为碰撞变量。
如果对暴露-结果关联进行调整时涉及这样的变量,可能会引发虚假关联,这被称为碰撞偏差。
重要的是,DAG可以帮助识别碰撞变量,这些变量通常不应被调整,并且在无法避免对碰撞变量进行调整时(例如,在选择样本时),还可以帮助识别能够减轻碰撞偏差的变量。
图5中的例子说明了大量饮酒对全因死亡率的影响,但该研究仅限于65岁及以上的老年人。为此,增加了一个选择节点以及一个表示年龄的节点(年龄是一个混杂因素)。许多因素会影响这项研究的选择;例如,要活到65岁,参与者需要保持健康的生活方式,并且根据定义不能在此前死亡。此外,那些大量饮酒的人可能更不容易进入研究样本。
这些变量将影响参与者是否被选中,这表明存在从年龄、大量饮酒和死亡指向选择的箭头。因此,进入研究的选择是暴露-结果关联的一个碰撞变量,导致对暴露对结果的因果效应的估计出现偏差。
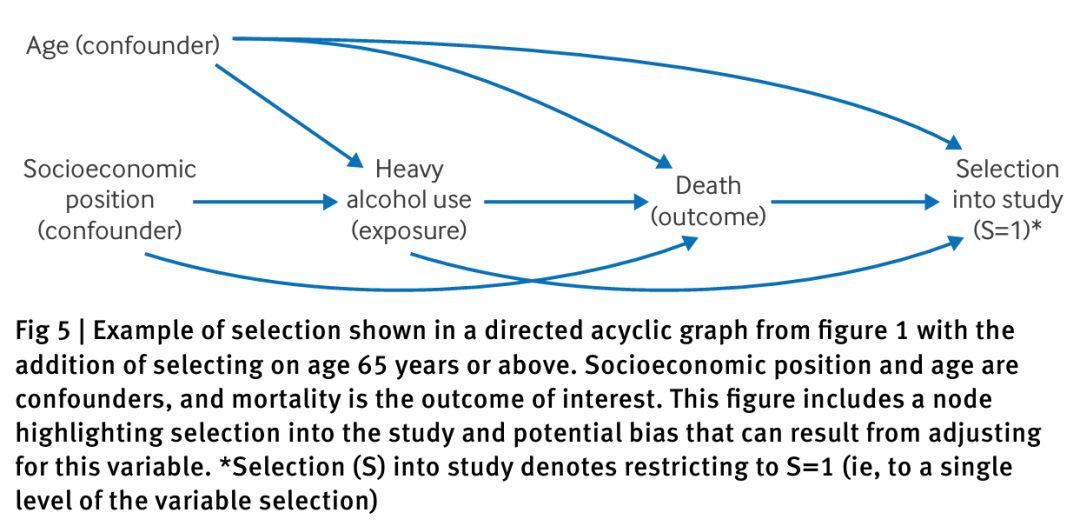
有向无环图(DAG)还有许多其他用途。例如,这些图可以描述关于测量误差及其原因的假设,从而帮助理解信息偏差并识别缓解策略。它们还可以扩展用于概念化潜在的效应修饰因子。此外,DAG可以应用于时间变化的暴露、结果和协变量,并描述它们可能复杂的机制,例如过去和当前的吸烟行为。
利用DAG来理解时间变化变量的影响,包括在估计多时间点暴露效应时,识别需要调整的时间变化混杂因素。例如,在研究大量饮酒对死亡的影响时,使用基线和后续时间点的大量饮酒数据,以及两个时间点的吸烟数据,可以帮助理解看似循环或表观双向因果结构的关系。箭头连接需反映时间顺序,如“T0饮酒→T1饮酒→死亡”,并识别时间依赖的混杂调整变量(如T0吸烟影响T1饮酒和死亡)。这种设计确保因果顺序清晰,避免时间悖论。
四、在临床研究中实施有向无环图
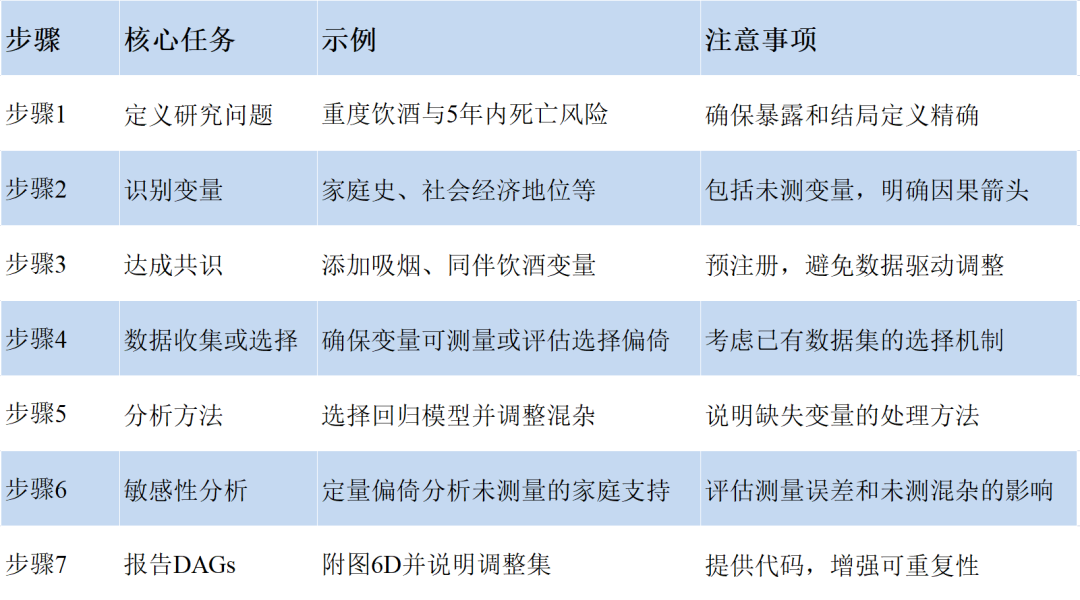
研究者提出一个包含七个步骤的指南,用于绘制和使用这些图表以改进研究设计和数据分析。这些步骤为DAG及其可用的算法方法提供了入门指导。实施这些步骤并不需要软件,但某些工具可以帮助构建DAG,从而进一步简化这一过程。针对每个建议的步骤,我们将通过示例描述如何构建DAG。
有向无环图七步指南
以下逐一详细说明,并结合示例加以阐释:
步骤1:确定目标人群并定义研究问题,明确暴露(或处理)和感兴趣的结果的定义。
首先需要明确目标人群和研究问题,精确定义暴露、结局和估计目标。例如:
目标人群:英国18岁及以上的饮酒人群。
暴露:重度饮酒障碍的临床诊断。
结局:5年内的全因死亡风险。
估计目标(Estimand):平均治疗效应(Average Treatment Effect),即比较所有患病者与假设未患病时的死亡风险差异。
清晰的问题定义是DAG构建的基础。例如,若研究问题改为“饮酒量与心血管死亡的关系”,暴露和结局的定义将随之改变,影响后续变量选择。
步骤2:通过回顾文献并与领域专家讨论(包括熟悉构建有向无环图的专家),识别与感兴趣因果效应相关的所有变量。
通过文献回顾和专家讨论,识别所有可能影响暴露、结局或选择的变量。例如,在重度饮酒与死亡的研究中,可能包括:
直接相关变量:家庭饮酒史、社会经济地位、医疗可及性、实际饮酒量。
间接相关变量:饮食质量、吸烟、同伴饮酒行为。
选择节点(S):如是否进入队列研究的标准(例如,纳入条件为有医疗记录者)。
应尽可能包括未测量的变量,并用箭头表达因果机制。例如,“家庭饮酒史→重度饮酒”和“社会经济地位→医疗可及性→死亡”。
步骤3:与更多专家合作开发有向无环图,直至达成共识,并将共识DAG纳入任何预先注册中。
与领域内更多专家合作,迭代完善DAG,确保涵盖所有相关变量和因果关系。例如,初始DAG可能仅包含重度饮酒、死亡和社会经济地位,经过讨论后新增吸烟和同伴饮酒效应(见图6D)。共识DAG应纳入研究预注册(如ClinicalTrials.gov),避免数据驱动的调整,确保假设的独立性。
步骤4:基于共识有向无环图,确定需要收集数据的变量或合适的数据集;如果使用已收集的数据,则考虑哪些变量会影响样本选择。
基于共识DAG,确定需要收集的变量。例如,社会经济地位、医疗可及性和吸烟需通过问卷或数据库获取。若使用已有数据集(如美国Medicaid数据),需评估选择偏倚。例如,低收入者更可能进入Medicaid,社会经济地位应指向选择节点(S)。
步骤5:根据研究问题(步骤1)和共识有向无环图(步骤3)定义的内容,选择分析方法、结果和暴露的测量指标以及协变量。
根据DAG选择合适的统计模型和调整集。例如,若最小充分调整集包括社会经济地位和医疗可及性,可以使用多元回归模型调整这些变量。若变量缺失(如医疗可及性无数据),需说明替代方法,如倾向评分匹配或工具变量分析。
步骤6:针对无法获取或容易受到测量误差影响的变量,确定敏感性分析,以量化未测量变量或测量误差可能产生的影响。
针对未测量变量(如家庭支持)或测量误差,设计敏感性分析。例如,若重度饮酒数据来自自我报告,可能存在测量误差,可以用验证数据校正(如与客观生物标志物比较)。对于未测混杂(如家庭支持),可用定量偏倚分析(quantitative bias analysis)评估其对结果的影响范围。
步骤7:在未来的出版物中包含有向无环图,并在描述调整集和敏感性分析时引用该图。
在论文中包含DAG(主文或补充材料),详细说明调整集的选择依据,并附带可重复性代码。
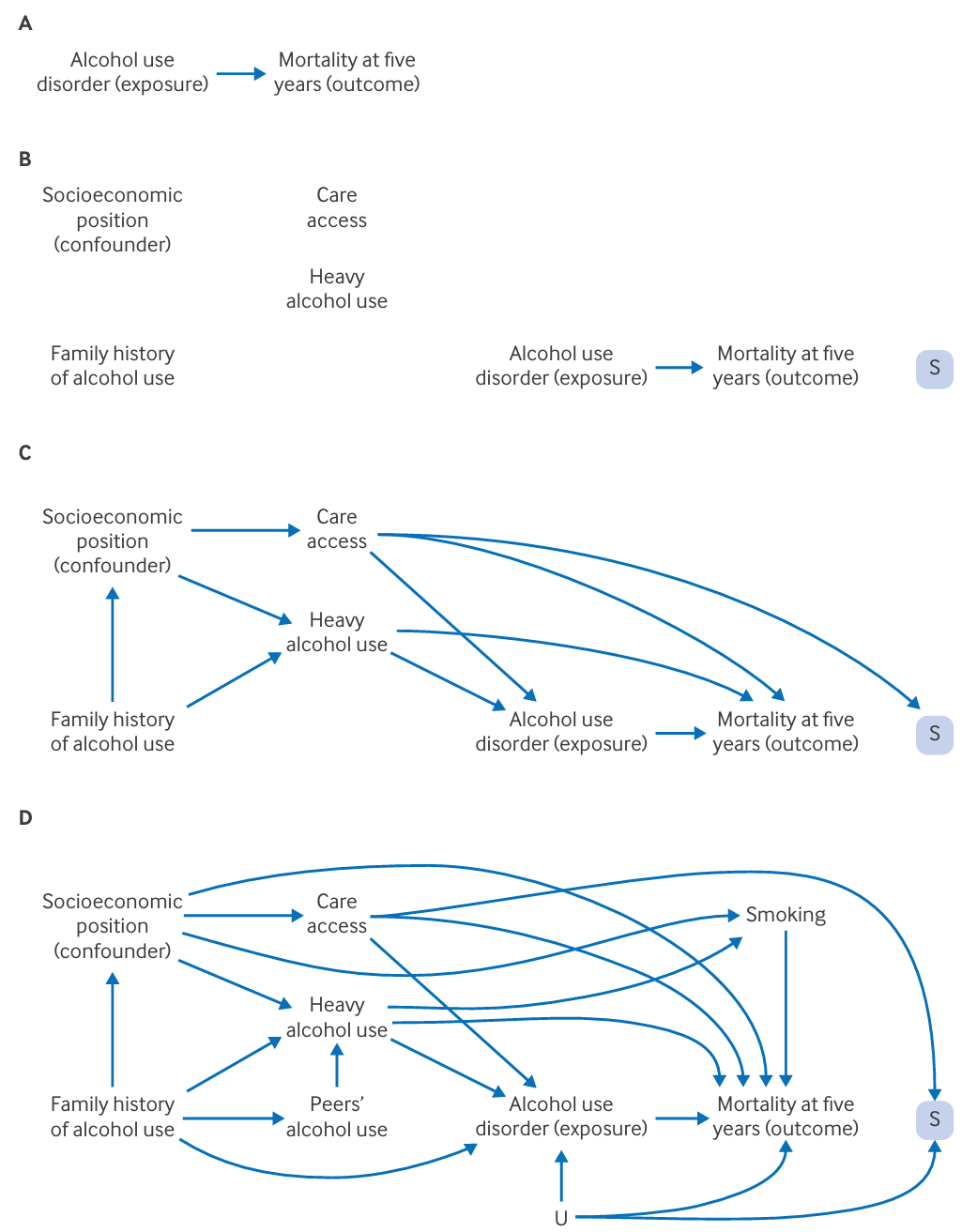
举例,有向无环图的构建过程:
(A)首先定义感兴趣的暴露(即一种原因,例如某种行为或医疗干预)和结果(即疾病的存在或不存在)。
(B)利用专家知识和以往的研究,可以构建初步图表,以确定与暴露和结果相关的变量,同时也包括其他相关变量。
(C)然后通过添加箭头明确表示这些变量之间的因果关系。
(D)通过进一步完善和达成共识,完成图表,包括变量、暴露和结果之间的所有关系。
U = 未测量且可能未知的混杂因素;S = 选择(S=1 表示被选入研究的选择,由围绕 S 节点的方框暗示)。
五、有向无环图的局限性和注意事项
尽管DAGs在因果推断中功能强大,但其局限性不容忽视:
假设依赖性:DAGs完全依赖研究者的因果假设。如果遗漏关键混杂变量(如图3中的饮食质量),调整将不足,导致残余混杂。例如,若饮食质量同时影响饮酒和死亡,却未纳入DAG,估计结果可能偏倚。
非参数性:DAGs不假设数据生成函数,无法直接评估效应的大小或形式(如线性关系还是阈值效应)。它仅提供结构化的因果框架,具体效应需通过统计模型估计。
复杂性:当变量数量过多时,DAG可能变得过于密集,难以绘制或理解。例如,若研究涉及数十个变量,手动绘制可能不切实际,需借助软件(如dagitty)或替代方法(如析取原因准则)。
在使用DAGs时,研究者应避免以下误区:
不可作为概念图或思维导图:DAGs不是展示过程的工具(如细胞内信号通路),而是专门用于因果假设的表达。
避免限制于已测变量:仅包含已测变量的DAG不足以发现未测混杂。例如,若仅绘制重度饮酒和死亡的直接箭头,可能忽略社会经济地位的混杂作用。
避免双向箭头:双向箭头(如“重度饮酒↔死亡”)违背无环性。若存在潜在混杂,应加入未测变量节点(如“遗传因素”),而不是使用双向箭头。
避免过于简化:若DAG仅包含暴露和结局的直接箭头,可能遗漏关键中介变量或碰撞体(colliders),导致分析策略错误。
六、报告有向无环图
在实证研究论文中报告DAG对读者、审稿人和编辑都非常有帮助。
它们还可以包含在研究者进行的预先注册中,这可以让读者确信,在数据和分析方案确定之前,因果结构已经经过深思熟虑。这种报告有助于避免因选择性分析或调整集而导致的偏差和虚假统计信号。
在实证研究论文中,DAG可以作为分析计划的一部分呈现。它们可以作为主要图表包含在正文中,或者更常见的是放在补充材料中,以阐明研究的假设。作者可以列出直接参与构建图表的人员名单,并附上支持图表中所展示关系的相关文献以及用于创建图表的可重复代码(如果使用了软件)。
DAG可以帮助审稿人和编辑理解一项研究,因为它们明确地展示了研究设计、数据收集和分析背后的假设。许多实证研究论文隐含地假定了某种因果结构。包含DAG可以使这种潜在的因果结构变得明确,并让读者评估这些假设的合理性。因此,在同行评审过程中,要求提交这些图表可能会对审稿人和编辑有所帮助。
之前郑老师的【“小满”临床统计学沙龙】这一期公益直播曾讲过:有向无环图(DAG)理论与实践,感兴趣的朋友可以去看直播回放,就在【医学论文与统计分析】视频号。
最后,在文末给郑老师我们团队打个一对一指导广告吧,大家不要见怪哈!
我们将提供专业的一对一微信R语言答疑指导哦

我们描述了研究人员如何使用dag来识别和描述分析中不同潜在变量的作用:暴露、结果、混杂因素、最小充分调整集、介质、选择、碰撞器和效果调节剂

















 3271
3271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









