




 本文详细介绍了使用YOLOv3进行深度学习目标检测,特别是训练自己的图像数据集的过程。包括数据集准备、预处理、模型配置修改、训练以及目标检测的实现。通过收集不同场景的目标图片,使用labelImg工具标注,然后调整训练参数进行训练,最终得到能够检测tank和airplane的模型。
本文详细介绍了使用YOLOv3进行深度学习目标检测,特别是训练自己的图像数据集的过程。包括数据集准备、预处理、模型配置修改、训练以及目标检测的实现。通过收集不同场景的目标图片,使用labelImg工具标注,然后调整训练参数进行训练,最终得到能够检测tank和airplane的模型。
二零二零年的大年初一,给大家拜个年,祝大家鼠年吉祥,万事如意,趁着喜气,把Yolov3训练自己的数据过程,记录一下,共勉共进。
同样,无人机搭载山狗拍摄的视频,目标检测的种类是模型tank和airplane,部分效果图镇贴:

数据集准备
首先需要将自己的数据集准备好,不同场景下的目标数据尽可能的收集,以提高最终训练结果的准确度。我这边是使用相机对检测目标进行录像,然后每隔几十帧后截取图片保存。效果如图:

收集完足够图片后,通过开源的标签工具labelImg对目标进行标注,并保存xml文件,为下一步做准备。
数据集预处理
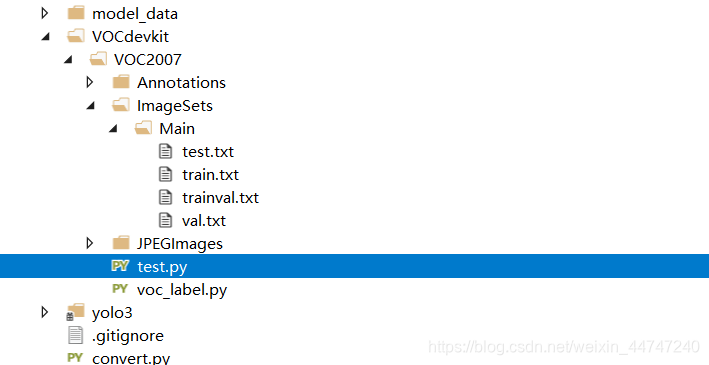
在项目下找到文件夹VOCdevkit\VOC2007,其中会包含文件夹:Annotations(用于存放xml标签数据)、Imagesets(用于存放tet文本数据)、JPEGImages(用于存放原始图片数据),接下来将目标图片集复制进JPEGImages,将标注好的xml文件复制进Annotations,运行test.py,会在Imagesets下生成test文本,看通过修改数值对训练、验证集的数量进行修改,如下图:
原demo修改
① 打开voc_annotati
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7488
7488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









