







1.YOLOv1简介
yolov1全称:
You Only Look Once:Unified, Real-Time Object Detection,论文链接
有博主将其进行了翻译,论文翻译:翻译链接
YOLOv1也是目标检测网络中one steap的网络。在pascal voc2007的测试数据集的效果为63.4mAP,在448x448的图像上进行推理处理的时延为45FPS。
SSD在pascal voc2007的测试数据集的效果为74.3mAP,达到59mAP,详细见:目标检测算法——SSD,所以其实相比SSD后,yolov1的效果不算是那么好的,但是和当时的RCNN来说,其确实更快。
思想

-
将一幅图像分成SxS个网格(grid cell),如果某个object的中心 落在这个网格中,则这个网格就负责预测这个object。(paper中S设定为7)
-
每个网格要预测B个bounding box,每个bounding box除了要预测位置之外,还要附带预测一个confidence值。每个网格还要预测C个类别的分数。(paper中B设定为2,而爬山al voc数据集中有20个类别,所以C为20)
解析:
-
为了在Pascal VOC上评估YOLO,我们使用S=7,B=2。Pascal VOC有20个标注类,所以C=20。我们最终的预测是7×7×30的张量。
-
confidence 是yolov1中首次提出来的概念,置信度分数反映了该模型对那个框内是否包含目标的信心,以及它对自己的预测的准确度的估量。在形式上,我们将置信度定义为
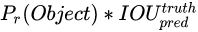 。如果该单元格中不存在目标,则置信度分数应为零。否则,我们希望置信度分数等于预测框(predict box)与真实标签框(ground truth)之间联合部分的交集(IOU)。
。如果该单元格中不存在目标,则置信度分数应为零。否则,我们希望置信度分数等于预测框(predict box)与真实标签框(ground truth)之间联合部分的交集(IOU)。 -
对于预测的bounding box的四个数值中,(x,y)坐标表示边界框的中心相对于网格单元的边界的值,而宽度和高度则是相对于整张图像来预测的。 其中(x,y)的预测值是被限定在对于的cell中的,其不会超出那个框格,所以(x,y)的数值会是0-1之间。而由于(w,h)也是相对于整个图像的预测值,所以其数值也会是0-1之间。也就是说,就是让标注的目标的中心点的那个对应网格,去预测这个目标的中心点与宽高。
-
每个网格单元还预测C个条件类别概率
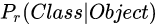 ,这些概率以包含目标的网格单元为条件。不管边界框的的数量B是多少,每个网格单元我们只预测一组类别概率。在测试时,我们把条件类概率和每个框的预测的置信度值相乘,
,这些概率以包含目标的网格单元为条件。不管边界框的的数量B是多少,每个网格单元我们只预测一组类别概率。在测试时,我们把条件类概率和每个框的预测的置信度值相乘,

它给出了每个框特定类别的置信度分数。这些分数体现了该类出现在框中的概率以及预测框拟合目标的程度。
2.YOLOv1结构
没有标注s,stride默认值为1。

经过一系列的卷积特征提取之后会通过一个展平处理通过全连接层,然后再将输出的1470维的向量通过reshape变成一个7x7x30的特征矩阵。

其中这个7x7就对应着将图像分成7x7份, 然后每一个grid cell预测的30个参数,其中的参数包含两个预测框的具体位置(4个)与置信度(1个),还有每个类别分数(20个),总共30个参数。
3.YOLOv1损失函数
yolov1中的损失包含bounding box位置回归损失、confidence置信度损失,classes分类损失,计算损失过程中主要使用误差方和来处理。

1)bounding box损失
需要注意,宽和高的损失因为对于小目标和大目标的损失不能一概而论。相同的相对位置的损失对小目标来说损失应该更大,而对大目标来说损失应该没有小目标的损失那么大,如图所示:

而为了不出现在同样的偏移情况下小目标的差值与大目标的差值相同这样的状况,作者使用了开方差来计算损失。
边界框损失就是预测边界框与真实标注边界框的损失
2)confidence损失
对于置信度的损失,就直接使用了真实值-预测值来计算。其中obj表示计算的是正样本的损失,此时C^^i = 1;而noobj表示计算的是负样本的损失,此时 C^^i = 0。
置信度损失就是是否包含了检测目标的损失。
3)classes损失
对于类别损失同样也是平方和去计算误差的。
类别损失就网格的类别与真实类别的损失。
概括:
- 损失由三部分组成,分别是:坐标预测损失、置信度预测损失、类别预测损失。
- 使用的是差方和误差。需要注意的是,w和h在进行误差计算的时候取的是它们的平方根,原因是对不同大小的bounding box预测中,相比于大bounding box预测偏一点,小box预测偏一点更不能忍受。而差方和误差函数中对同样的偏移loss是一样。 为了缓和这个问题,作者用了一个比较取巧的办法,就是将bounding box的w和h取平方根代替原本的w和h。
- 定位误差比分类误差更大,所以增加对定位误差的惩罚,使λ c o o r d =5。
- 在每个图像中,许多网格单元不包含任何目标。训练时就会把这些网格里的框的“置信度”分数推到零,这往往超过了包含目标的框的梯度。从而可能导致模型不稳定,训练早期发散。因此要减少了不包含目标的框的置信度预测的损失,使 λ n o o b j=0.5。
4.YOLOv1总结
回顾:

再理清一下yolov1的结构。首先对于一张448x448的彩色图片,yolov1将图像分割为7x7的grid cell,也就是一种有49个网格。这每个网格中,需要分别预测两个边界框的具体位置,其中分别涉及4个参数(x,y坐标相对于图像的中心点所在的网格单元边界的值;而w,h会相对于整个图像尺寸的相对值),对这两个边界框还要预测去置信度,来表示刚刚所预测到的边界框与实际边界框的iou值。而且,每个网格单元还要预测20个类别概率,以包含目标的网格单元为条件。所以每个网格单元一共涉及30个参数,所以经过卷积网络最后得到的特征矩阵也是7x7x30的大小,一一对应。
后续的操作,首先就可以根据置信度较低的边界框进行剔除,然后根据20个类别概率,对剩下的边界框进行预判。边界框的中心属于拿一个网格,而网格对应的是哪一个类别,那么这个网格所生成的边界框就对于的是哪一个类别。
我个人觉得三种损失还是比较难理解的,尤其是置信度损失,所以这里再一次的总结:
- 边界框损失就是预测边界框与真实标注边界框的损失
- 置信度损失就是是否包含了检测目标的损失
- 类别损失就网格的类别与真实类别的损失
缺点:
YOLO给边界框预测强加空间约束,因为每个网格单元只预测两个框和只能有一个类别。这个空间约束限制了我们的模型可以预测的邻近目标的数量。我们的模型难以预测群组中出现的小物体(比如鸟群)。由于我们的模型学习是从数据中预测边界框,因此它很难泛化到新的、不常见的长宽比或配置的目标。我们的模型也使用相对较粗糙的特征来预测边界框,因为输入图像在我们的架构中历经了多个下采样层。
最后,我们的训练基于一个逼近检测性能的损失函数,这个损失函数无差别地处理小边界框与大边界框的误差。大边界框的小误差通常是无关要紧的,但小边界框的小误差对IOU的影响要大得多。我们的主要错误来自于不正确的定位。
所以,对于这个主要问题的改进,从yolov2开始,又从事基于anchor的边界框来进行回归预测了。
如有错误,恳请指出。
参考论文:
https://blog.csdn.net/zhangjunp3/article/details/80421814
https://blog.csdn.net/wjinjie/article/details/107509243
https://www.bilibili.com/video/BV1yi4y1g7ro?p=1
















 689
689











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











