





论文地址:https://arxiv.org/pdf/1706.03762.pdf
视频地址:https://www.bilibili.com/video/BV1pu411o7BE/?spm_id_from=333.788
2.摘要
卷积神将网络对较长的序列难以建模,因为他每次看一个比较小的窗口,如果两个像素隔得比较远,要用到很多层卷积才能把隔得很远的两个像素融合起来。但是用Transformer一层就能把整个序列看到。但是卷积有一个好处就是一个输出通道可以认为它可以识别不一样的模式,Transformer也想要这样子的多输出通道的效果,所以就提出了多头注意力。
3.模型
大多数序列转导模型都有一个编码器-解码器结构。编码器输入(X1,…Xn),得到序列Z=(Z1,…Zn),zt是xt的向量表示。解码器拿到编码器的输出Z,生成长为m的输出(y1,…ym),词是一个一个生成的,生成yt要把y1到yt-1都拿到。过去时刻的输出也会作为当前时刻的输入,这个叫做自回归。
Transformer也用了这种架构,编码器和解码器使用堆叠的自关注层和逐点的、完全连接的层。
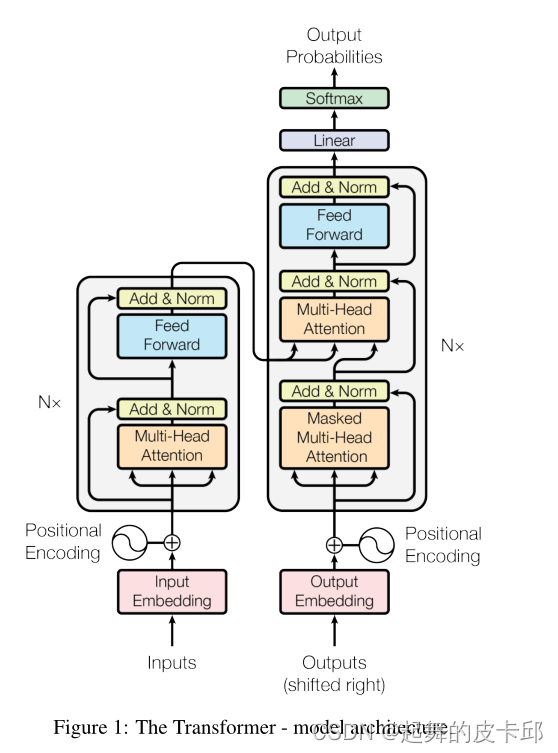
编码器:N=6,有6大层,每层有2子层。第一层是多头自注意机制,第二层是简单的,按位置完全连接的前馈神经网络(其实就是MLP)。每个子层有一个残差连接,然后使用了layer normalization。
每个子层的输出是LayerNorm(x+Sublayer(x))。残差需要输入输出相等,就把每一层输出的维度变成512。也就是在每一层都把词表示成512的长度。
LayerNorm:

batch:样本个数
feature:特征(512)
seq:样本长度
batchNorm是蓝色切法,LayerNorm是黄色切法。然后算均值和方差。
编码器最后的输出是n个长为d的向量。
解码器: 与编码器相同N=6,有6大层,每层有2个跟编码器一样的子层。但不一样的是解码器加了一个第三层,用的是一个带有掩码的多头自注意力机制(masked),来防止对后续时刻的关注,从而保障训练和预测的时候的行为是一致的。
3.2 Attention:
query,keys,values,output都是向量。output是values的加权和,每个values的权重由query与keys的关系来计算。接下来介绍3种注意力机制。

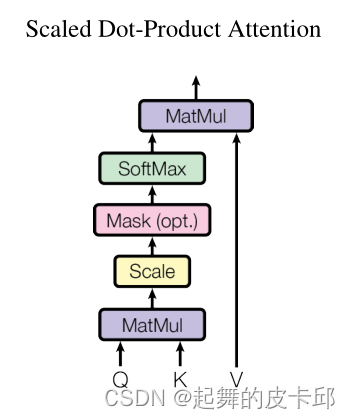
3.2.1 Scaled Dot-Product Attention
queries和keys是等长的,都等于dk。values是dv,输出也是dv。
对于每一个query和keys做内积,作为相似度,然后除以根号下的dk,通过softmax得到权重,作用于values,得到输出。

一个一个的算在实际使用中会很慢,所以将其写成矩阵
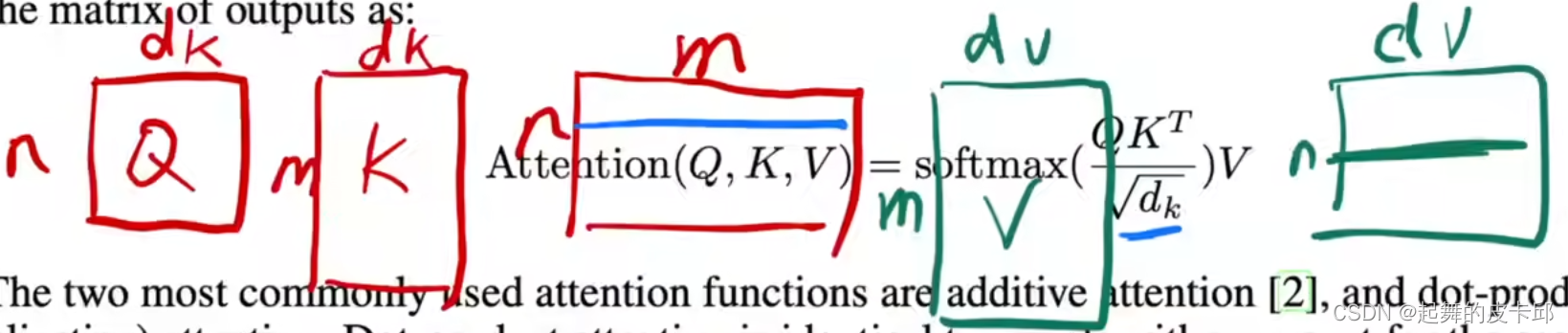
最常用的两个注意函数是加性注意和点积(乘法)注意。
scale:除根号dk。
Mask:在训练的时候,防止之后的数对当前影响,具体是给qt和kt之后的数一个很大的负数。
3.2.2 Multi-Head Attention
把整个query,key,value投影到低维,再做h次的注意力函数,然后每一个函数的输出并在一起,然后再投影回来得到最终输出。
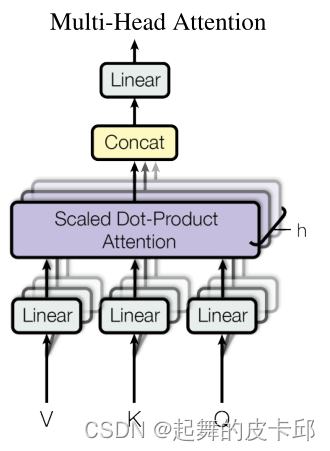
在3.2.1的方法中参数很少,但有时候我们希望有些不一样的计算像素的方法,所以用了多头的这个方法。

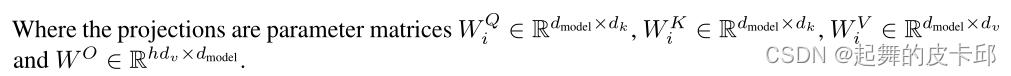 本文的h=8,并且dk = dv = dmodel/h = 64。
本文的h=8,并且dk = dv = dmodel/h = 64。
3.2.3 注意机制在模型中的使用
图一中有三个不一样的注意层。
编码器的自注意力机制:假设句子长为n,则输入是n个长为d的向量,同一个东西复制成三份,作为key,value,query。
解码器中带Masked的自注意力机制:同一个东西复制成三份,作为key,value,query。不一样的地方是在计算某个权重时,后边的权重设置成零。输出为m个长为d的向量。
解码器中的注意力机制:不再是自注意,key,value来自于编码器的输出,query来自于解码器中另一个自注意机制。其实就是把编码器的输出根据我想要的把他拎出来。
3.3 Position-wise Feed-Forward Networks
其实就是个MLP,不一样的是对每个词都作用同一个MLP。
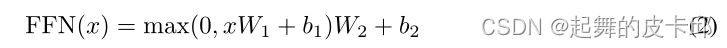
注意力层的输入是512维,W1会把他扩大四倍成2048的,因为最后有个残差链接,还得投影回去,W2就把他投影回去了。
Transformer和rnn的区别
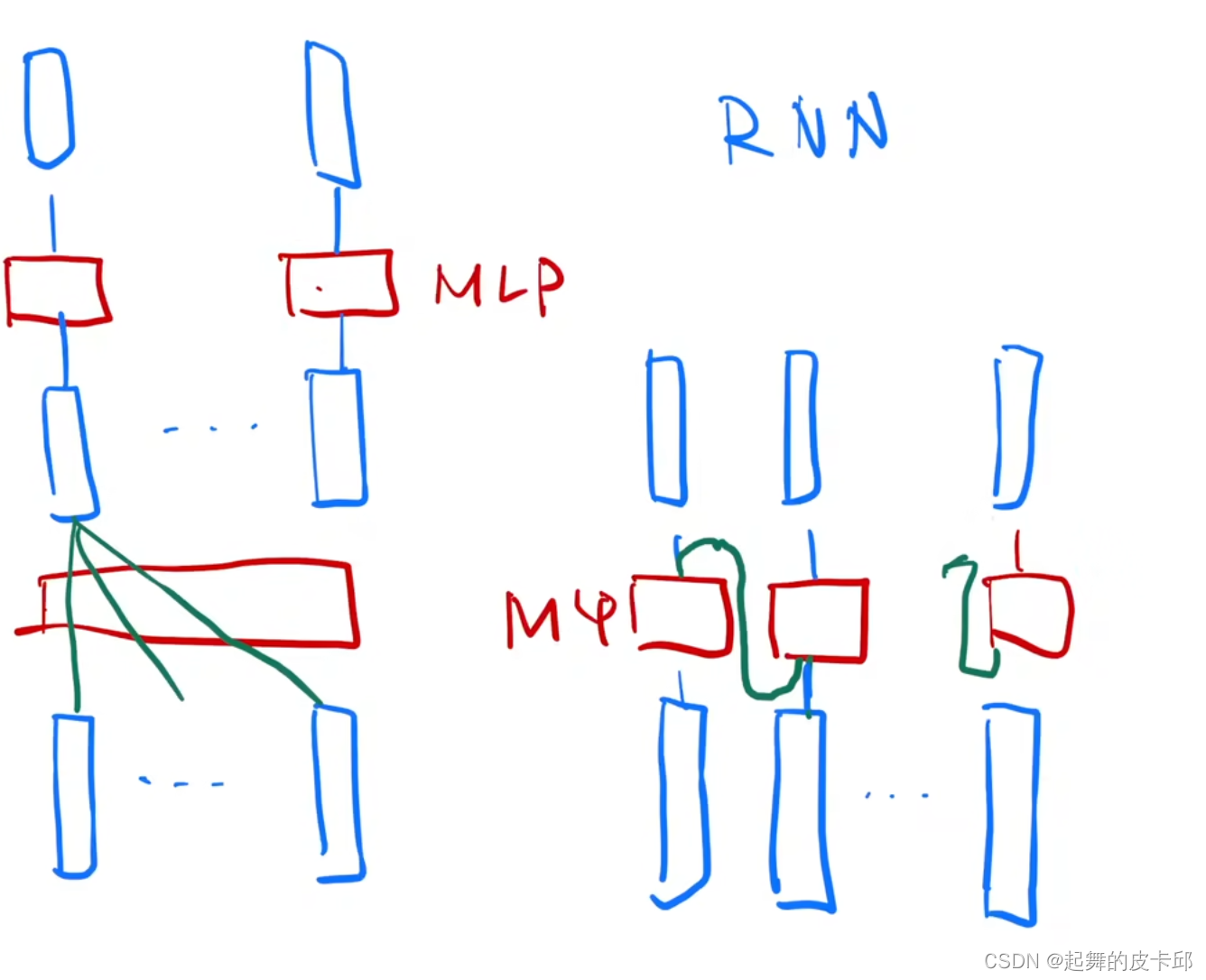
都是用一个MLP做一个语义空间的转换,不一样的是如何传递序列信息,rnn是把上一时刻的输出传入下一时刻作为输入,Transformer是通过一个attention层,全局的拉取序列信息,再用MLP做语义转换。
3.4 Embeddings and Softmax
把每个词表示成长为d的向量。编码器,解码器和softmax前边的线性层都需要embeddings,这三个是一样的权重。把权重乘了根号d,因为当维度大,学到的权重值就会变小,乘上了根号d,后边加encoding的时候在一个scale上是差不多的。
3.5 Positional Encoding
attention是不会有时序信息的,所以需要加入时序信息。
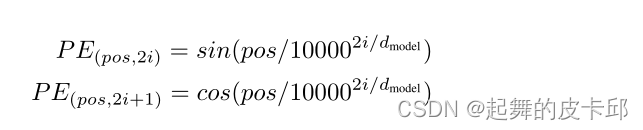
位置信息也相当于用一个向量表示出来,具体值是用上式算出来的,然后与嵌入层相加。














 441
441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









