







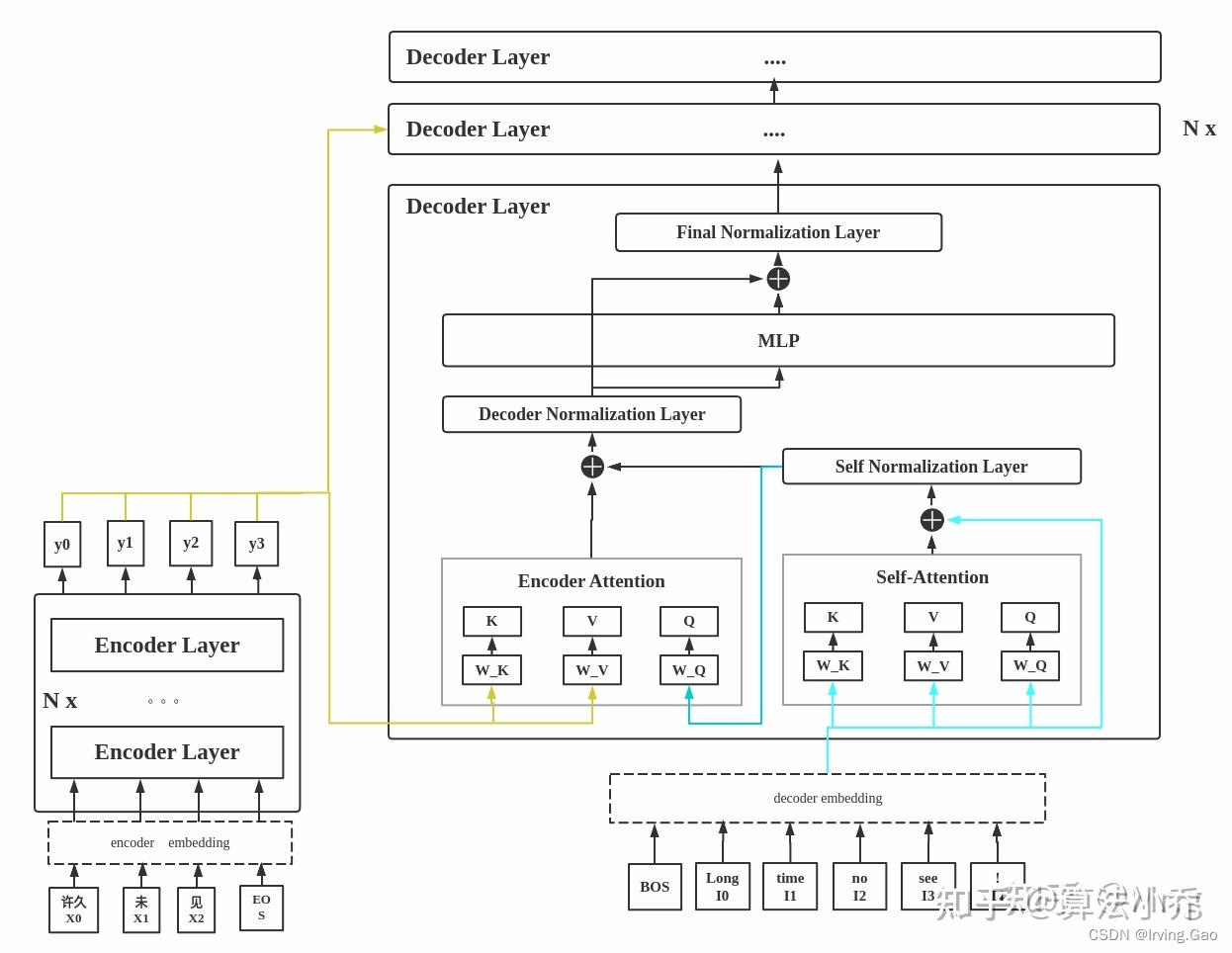
Decoder整体结构详解图
出自知乎文章:Transformer之Decoder的QKV来源
图画的很清晰,Decoder分为两个部分,Self Attention和Encoder Attention:
Self Attention:输入的QKV都是经过embedding后的 想要输出的 query;Encoder Attention:输入的Q是 目标语言的 经过Self Attention后的向量embedding;输入的K和V分别是Encoder输出的需要 被参考语言的 向量embedding。















 1821
1821











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









