







这是官网tutorial的第二个学习笔记,下面是之前的几个学习笔记
Layernorm
LayerNorm(层归一化)是一种用于提升深度学习模型性能的技术,尤其适用于序列模型或小批量数据的神经网络。通过减去输入向量的均值并除以标准差,将数据归一化为零均值和单位方差,再应用可学习的线性变换(包括权重和偏置),从而加速模型训练并提高模型性能。其数学表达式为
y = x − E [ x ] Var ( x ) + ϵ ∗ w + b y = \frac{ x - \text{E}[x] }{ \sqrt{\text{Var}(x) + \epsilon} } * w + b y=Var(x)+ϵx−E[x]∗w+b
前向过程
@triton.jit
def _layer_norm_fwd_fused(
X, # pointer to the input
Y, # pointer to the output
W, # pointer to the weights
B, # pointer to the biases
Mean, # pointer to the mean
Rstd, # pointer to the 1/std
stride, # how much to increase the pointer when moving by 1 row
N, # number of columns in X
eps, # epsilon to avoid division by zero
BLOCK_SIZE: tl.constexpr,
):
# Map the program id to the row of X and Y it should compute.
row = tl.program_id(0)
Y += row * stride
X += row * stride
# Compute mean
mean = 0
_mean = tl.zeros([BLOCK_SIZE], dtype=tl.float32)
for off in range(0, N, BLOCK_SIZE):
cols = off + tl.arange(0, BLOCK_SIZE)
a = tl.load(X + cols, mask=cols < N, other=0.).to(tl.float32)
_mean += a
mean = tl.sum(_mean, axis=0) / N
# Compute variance
_var = tl.zeros([BLOCK_SIZE], dtype=tl.float32)
for off in range(0, N, BLOCK_SIZE):
cols = off + tl.arange(0, BLOCK_SIZE)
x = tl.load(X + cols, mask=cols < N, other=0.).to(tl.float32)
x = tl.where(cols < N, x - mean, 0.)
_var += x * x
var = tl.sum(_var, axis=0) / N
rstd = 1 / tl.sqrt(var + eps)
# Write mean / rstd
tl.store(Mean + row, mean)
tl.store(Rstd + row, rstd)
# Normalize and apply linear transformation
for off in range(0, N, BLOCK_SIZE):
cols = off + tl.arange(0, BLOCK_SIZE)
mask = cols < N
w = tl.load(W + cols, mask=mask)
b = tl.load(B + cols, mask=mask)
x = tl.load(X + cols, mask=mask, other=0.).to(tl.float32)
x_hat = (x - mean) * rstd
y = x_hat * w + b
# Write output
tl.store(Y + cols, y, mask=mask)
反向过程
层归一化操作符的反向传播过程比前向传播更为复杂。设 x ^ \hat{x} x^为线性变换前的归一化输入,即 x − E [ x ] Var ( x ) + ϵ \frac{x - \text{E}[x]}{\sqrt{\text{Var}(x) + \epsilon}} Var(x)+ϵx−E[x],则(x)的向量-雅可比乘积(VJP) ∇ x \nabla_x ∇x表示如下:
∇ x = 1 σ ( ∇ y ⊙ w − ( 1 N x ^ ⋅ ( ∇ y ⊙ w ) ) ⏟ c 1 ⊙ x ^ − 1 N ∇ y ⋅ w ⏟ c 2 ) \nabla_{x} = \frac{1}{\sigma} \left( \nabla_{y} \odot w - \underbrace{\left( \frac{1}{N} \hat{x} \cdot ( \nabla_{y} \odot w ) \right)}_{c_1} \odot \hat{x} - \underbrace{\frac{1}{N} \nabla_{y} \cdot w }_{c_2} \right) ∇x=σ1 ∇y⊙w−c1 (N1x^⋅(∇y⊙w))⊙x^−c2 N1∇y⋅w
其中, ⊙ \odot ⊙ 表示元素级乘法, ⋅ \cdot ⋅ 表示点积, σ \sigma σ 是标准差。 c 1 c_1 c1 和 c 2 c_2 c2 是中间常数,用于提高以下实现的可读性。
对于权重 w w w 和偏置 b b b,其向量-雅可比乘积(VJP) ∇ w \nabla_{w} ∇w 和 ∇ b \nabla_b ∇b 更为直接:
∇ w = ∇ y ⊙ x ^ 和 ∇ b = ∇ y \nabla_{w} = \nabla_{y} \odot \hat{x} \quad \text{和} \quad \nabla_{b} = \nabla_{y} ∇w=∇y⊙x^和∇b=∇y
由于相同的权重 w w w 和偏置 b b b 在同一批次的所有行中使用,因此它们的梯度需要相加。为了高效地执行此步骤,我们采用了并行归约策略:每个内核实例将某些行的局部 ∇ w \nabla_{w} ∇w 和 $ \nabla_{b}$ 累加到其中一个独立缓冲区中。这些缓冲区驻留在 L2 缓存中,然后由另一个函数进一步归约以计算实际的 ∇ w \nabla_{w} ∇w 和 ∇ b \nabla_{b} ∇b。
假设输入行数 M = 4 且 GROUP_SIZE_M = 2,以下是 ∇ w \nabla_{w} ∇w(为简洁起见,省略了 ∇ b \nabla_{b} ∇b的并行归约策略示意图:
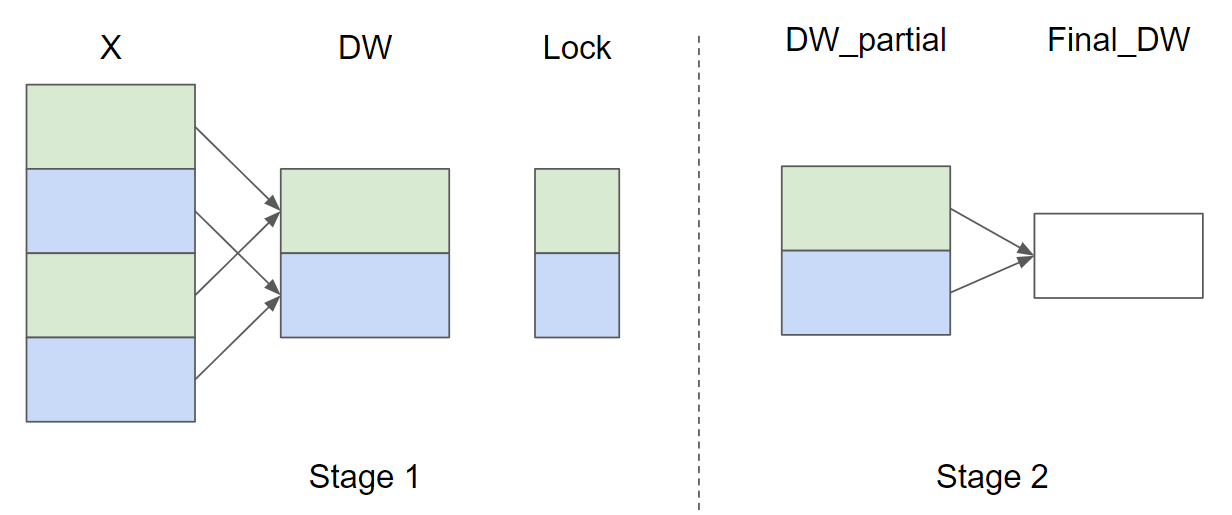
在第 1 阶段,具有相同颜色的 X 行共享同一个缓冲区,因此使用锁来确保一次只有一个内核实例写入缓冲区。在第 2 阶段,缓冲区被进一步归约以计算最终的
∇
w
\nabla_{w}
∇w 和
∇
b
\nabla_{b}
∇b 。在以下实现中,第 1 阶段由函数 _layer_norm_bwd_dx_fused 实现,第 2 阶段由函数 _layer_norm_bwd_dwdb 实现。我们先来看几个函数。
tl.atomic_cas
tl.atomic_cas 是 Triton 中用于执行原子比较和交换操作的函数,它在内存位置 pointer 处执行操作,比较该位置的值与 cmp,如果相等则将该位置的值替换为 val。以下是其用法:
语法
tl.atomic_cas(pointer, cmp, val, sem=None, scope=None)
参数
pointer:要操作的内存位置。cmp:期望在pointer处找到的值。val:若比较成功,则写入到pointer处的值。sem(可选):指定操作的内存语义,可取值为 “acquire”、“release”、“acq_rel”、“relaxed”,默认为 “acq_rel”。scope(可选):定义观察原子操作同步效果的线程范围,可取值为 “gpu”、“cta”(线程块)、“sys”,默认为 “gpu”。
返回值
返回原子操作前 pointer 处存储的数据。
使用场景
在并行计算中,tl.atomic_cas 可用于实现锁机制,确保同一时间只有一个线程可以访问特定资源,防止数据竞争。例如,在累加部分和时,通过 tl.atomic_cas 控制对共享缓冲区的访问。
示例
假设要对某个计数器进行线程安全的递增操作:
import triton
import triton.language as tl
@triton.jit
def _increment_counterKernel(COUNTER, N):
pid = tl.program_id(0)
if pid >= N:
return
while tl.atomic_cas(COUNTER, 0, 1) == 1:
pass
# Critical section
tl.store(COUNTER, tl.load(COUNTER) + 1)
tl.atomic_xchg(COUNTER, 0) # Release the lock
# Usage
counter = torch.zeros(1, dtype=torch.int32, device='cuda')
N = 10
_increment_counterKernel[(N,)](counter, N)
在上述代码中,tl.atomic_cas 用于在进入临界区前获取锁,确保同一时间只有一个线程可以执行递增操作。
tl.atomic_xchg
tl.atomic_xchg 是 Triton 中用于执行原子交换操作的函数。它将指定内存位置的值替换为一个新的值,并返回该内存位置的旧值。这个操作是原子性的,意味着它作为一个不可分割的整体执行,没有其他线程可以在此操作完成之前对其进行干扰。
语法
tl.atomic_xchg(pointer, value, sem=None, scope=None)
参数
pointer:指向要更新的内存位置的指针。value:要写入到内存位置的新值。sem(可选):指定操作的内存语义,可取值为 “acquire”、“release”、“acq_rel”、“relaxed”,默认为 “acq_rel”。scope(可选):定义观察原子操作同步效果的线程范围,可取值为 “gpu”、“cta”(线程块)、“sys”,默认为 “gpu”。
返回值
返回 pointer 指向的内存位置的旧值。
使用场景
tl.atomic_xchg 通常用于实现锁机制或更新共享变量时保证操作的原子性。例如,它可以用来实现简单的自旋锁,或者在多线程环境下安全地更新计数器。
示例
以下是一个简单的示例,展示如何使用 tl.atomic_xchg 来实现一个简单的计数器:
import triton
import triton.language as tl
@triton.jit
def _increment_counter_kernel(COUNTER, N):
pid = tl.program_id(0)
if pid >= N:
return
# 使用原子交换操作来确保线程安全地更新计数器
old_value = tl.atomic_xchg(COUNTER, tl.load(COUNTER) + 1)
# 执行其他操作
# ...
# 使用示例
counter = torch.zeros(1, dtype=torch.int32, device='cuda')
N = 10
_increment_counter_kernel[(N,)](counter, N)
注意:上述代码中的计数器更新操作并不是线程安全的,因为 tl.load(COUNTER) + 1 和 tl.atomic_xchg 分成的两步操作之间存在竞态条件。正确的做法是将计数器的值更新逻辑封装在单个原子操作中,或者使用锁来保护共享资源的访问。这里主要展示tl.atomic_xchg的用法,实际使用时需要更严谨的同步逻辑。
tl.debug_barrier
在 Triton 中,tl.debug_barrier() 是一个用于调试的同步原语,它确保在同一个程序块(program block)中的所有线程都到达该屏障点后,才会继续执行后续代码。这种同步机制在调试和优化并行程序时非常有用,因为它可以帮助开发者确保不同线程之间的执行顺序,从而更容易发现和修复潜在的线程同步问题。
使用方法
tl.debug_barrier() 的使用非常简单,只需在需要同步的点调用该函数即可。尽管它主要用于调试目的,但在某些情况下也可以用于确保多线程程序的正确性。
参数说明
tl.debug_barrier() 函数没有参数。
返回值
tl.debug_barrier() 没有返回值。
使用场景
- 调试和验证代码:在开发和调试过程中,
tl.debug_barrier()可以帮助开发者验证不同线程之间的执行顺序,从而确保程序的逻辑正确。 - 同步多线程:在某些情况下,程序逻辑需要所有线程在某个点完成各自的任务后再继续执行。在这种情况下,
tl.debug_barrier()可以用来同步这些线程。
示例
假设我们有一个内核函数,其中包含多个线程,我们希望确保某些操作在所有线程都完成某个阶段后再继续执行。使用 tl.debug_barrier() 可以轻松实现这一需求:
import triton
import triton.language as tl
@triton.jit
def _debug_kernel(X, N):
pid = tl.program_id(0)
if pid >= N:
return
# 第一个阶段:执行一些操作
a = tl.load(X + pid)
a += 1
# 使用 debug_barrier 确保所有线程完成第一个阶段
tl.debug_barrier()
# 第二个阶段:执行另一些操作
a *= 2
tl.store(X + pid, a)
# 使用示例
x = torch.arange(10, device='cuda')
N = 10
_debug_kernel[(N,)](x, N)
print(x)
在这个示例中,所有线程在完成第一个阶段(对 a 加 1)后,都会到达 tl.debug_barrier() 设置的屏障点。只有当所有线程都到达这个点后,才会继续执行第二个阶段(对 a 乘以 2)。这种同步机制对于确保程序的正确性和调试非常有用。
尽管 tl.debug_barrier() 可以用于调试和同步多线程程序,但它也有一些限制。由于它是一个重操作(heavy operation),在性能敏感的代码中应该谨慎使用,避免对性能造成负面影响。
反向传播第一阶段
@triton.jit
def _layer_norm_bwd_dx_fused(DX, # pointer to the input gradient
DY, # pointer to the output gradient
DW, # pointer to the partial sum of weights gradient
DB, # pointer to the partial sum of biases gradient
X, # pointer to the input
W, # pointer to the weights
Mean, # pointer to the mean
Rstd, # pointer to the 1/std
Lock, # pointer to the lock
stride, # how much to increase the pointer when moving by 1 row
N, # number of columns in X
GROUP_SIZE_M: tl.constexpr, BLOCK_SIZE_N: tl.constexpr):
# Map the program id to the elements of X, DX, and DY it should compute.
row = tl.program_id(0)
cols = tl.arange(0, BLOCK_SIZE_N)
mask = cols < N
X += row * stride
DY += row * stride
DX += row * stride
# Offset locks and weights/biases gradient pointer for parallel reduction
lock_id = row % GROUP_SIZE_M
Lock += lock_id
Count = Lock + GROUP_SIZE_M
DW = DW + lock_id * N + cols
DB = DB + lock_id * N + cols
# Load data to SRAM
x = tl.load(X + cols, mask=mask, other=0).to(tl.float32)
dy = tl.load(DY + cols, mask=mask, other=0).to(tl.float32)
w = tl.load(W + cols, mask=mask).to(tl.float32)
mean = tl.load(Mean + row)
rstd = tl.load(Rstd + row)
# Compute dx
xhat = (x - mean) * rstd
wdy = w * dy
xhat = tl.where(mask, xhat, 0.)
wdy = tl.where(mask, wdy, 0.)
c1 = tl.sum(xhat * wdy, axis=0) / N
c2 = tl.sum(wdy, axis=0) / N
dx = (wdy - (xhat * c1 + c2)) * rstd
# Write dx
tl.store(DX + cols, dx, mask=mask)
# Accumulate partial sums for dw/db
partial_dw = (dy * xhat).to(w.dtype)
partial_db = (dy).to(w.dtype)
while tl.atomic_cas(Lock, 0, 1) == 1:
pass
count = tl.load(Count)
# First store doesn't accumulate
if count == 0:
tl.atomic_xchg(Count, 1)
else:
partial_dw += tl.load(DW, mask=mask)
partial_db += tl.load(DB, mask=mask)
tl.store(DW, partial_dw, mask=mask)
tl.store(DB, partial_db, mask=mask)
# need a barrier to ensure all threads finished before
# releasing the lock
tl.debug_barrier()
# Release the lock
tl.atomic_xchg(Lock, 0)
反向传播第二阶段
@triton.jit
def _layer_norm_bwd_dwdb(DW, # pointer to the partial sum of weights gradient
DB, # pointer to the partial sum of biases gradient
FINAL_DW, # pointer to the weights gradient
FINAL_DB, # pointer to the biases gradient
M, # GROUP_SIZE_M
N, # number of columns
BLOCK_SIZE_M: tl.constexpr, BLOCK_SIZE_N: tl.constexpr):
# Map the program id to the elements of DW and DB it should compute.
pid = tl.program_id(0)
cols = pid * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)
dw = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)
db = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)
# Iterate through the rows of DW and DB to sum the partial sums.
for i in range(0, M, BLOCK_SIZE_M):
rows = i + tl.arange(0, BLOCK_SIZE_M)
mask = (rows[:, None] < M) & (cols[None, :] < N)
offs = rows[:, None] * N + cols[None, :]
dw += tl.load(DW + offs, mask=mask, other=0.)
db += tl.load(DB + offs, mask=mask, other=0.)
# Write the final sum to the output.
sum_dw = tl.sum(dw, axis=0)
sum_db = tl.sum(db, axis=0)
tl.store(FINAL_DW + cols, sum_dw, mask=cols < N)
tl.store(FINAL_DB + cols, sum_db, mask=cols < N)
封装pytorch
- pytorch中torch.autograd.Function可以被继承用于封装自定义的操作,具体可以看这篇博文或者官方文档 pytorch 自动微分以及自定义 torch.autograd.Function 教程-CSDN博客
class LayerNorm(torch.autograd.Function):
@staticmethod
def forward(ctx, x, normalized_shape, weight, bias, eps):
# allocate output
y = torch.empty_like(x)
# reshape input data into 2D tensor
x_arg = x.reshape(-1, x.shape[-1])
M, N = x_arg.shape
mean = torch.empty((M, ), dtype=torch.float32, device=x.device)
rstd = torch.empty((M, ), dtype=torch.float32, device=x.device)
# Less than 64KB per feature: enqueue fused kernel
MAX_FUSED_SIZE = 65536 // x.element_size()
BLOCK_SIZE = min(MAX_FUSED_SIZE, triton.next_power_of_2(N))
if N > BLOCK_SIZE:
raise RuntimeError("This layer norm doesn't support feature dim >= 64KB.")
# heuristics for number of warps
num_warps = min(max(BLOCK_SIZE // 256, 1), 8)
# enqueue kernel
_layer_norm_fwd_fused[(M, )]( #
x_arg, y, weight, bias, mean, rstd, #
x_arg.stride(0), N, eps, #
BLOCK_SIZE=BLOCK_SIZE, num_warps=num_warps, num_ctas=1)
ctx.save_for_backward(x, weight, bias, mean, rstd)
ctx.BLOCK_SIZE = BLOCK_SIZE
ctx.num_warps = num_warps
ctx.eps = eps
return y
@staticmethod
def backward(ctx, dy):
x, w, b, m, v = ctx.saved_tensors
# heuristics for amount of parallel reduction stream for DW/DB
N = w.shape[0]
GROUP_SIZE_M = 64
if N <= 8192: GROUP_SIZE_M = 96
if N <= 4096: GROUP_SIZE_M = 128
if N <= 1024: GROUP_SIZE_M = 256
# allocate output
locks = torch.zeros(2 * GROUP_SIZE_M, dtype=torch.int32, device=w.device)
_dw = torch.zeros((GROUP_SIZE_M, N), dtype=x.dtype, device=w.device)
_db = torch.zeros((GROUP_SIZE_M, N), dtype=x.dtype, device=w.device)
dw = torch.empty((N, ), dtype=w.dtype, device=w.device)
db = torch.empty((N, ), dtype=w.dtype, device=w.device)
dx = torch.empty_like(dy)
# enqueue kernel using forward pass heuristics
# also compute partial sums for DW and DB
x_arg = x.reshape(-1, x.shape[-1])
M, N = x_arg.shape
_layer_norm_bwd_dx_fused[(M, )]( #
dx, dy, _dw, _db, x, w, m, v, locks, #
x_arg.stride(0), N, #
BLOCK_SIZE_N=ctx.BLOCK_SIZE, #
GROUP_SIZE_M=GROUP_SIZE_M, #
num_warps=ctx.num_warps)
grid = lambda meta: (triton.cdiv(N, meta['BLOCK_SIZE_N']), )
# accumulate partial sums in separate kernel
_layer_norm_bwd_dwdb[grid](
_dw, _db, dw, db, min(GROUP_SIZE_M, M), N, #
BLOCK_SIZE_M=32, #
BLOCK_SIZE_N=128, num_ctas=1)
return dx, None, dw, db, None
layer_norm = LayerNorm.apply
测试layernorm
def test_layer_norm(M, N, dtype, eps=1e-5, device=DEVICE):
# create data
x_shape = (M, N)
w_shape = (x_shape[-1], )
weight = torch.rand(w_shape, dtype=dtype, device=device, requires_grad=True)
bias = torch.rand(w_shape, dtype=dtype, device=device, requires_grad=True)
x = -2.3 + 0.5 * torch.randn(x_shape, dtype=dtype, device=device)
dy = .1 * torch.randn_like(x)
x.requires_grad_(True)
# forward pass
y_tri = layer_norm(x, w_shape, weight, bias, eps)
y_ref = torch.nn.functional.layer_norm(x, w_shape, weight, bias, eps).to(dtype)
# backward pass (triton)
y_tri.backward(dy, retain_graph=True)
dx_tri, dw_tri, db_tri = [_.grad.clone() for _ in [x, weight, bias]]
x.grad, weight.grad, bias.grad = None, None, None
# backward pass (torch)
y_ref.backward(dy, retain_graph=True)
dx_ref, dw_ref, db_ref = [_.grad.clone() for _ in [x, weight, bias]]
# compare
assert torch.allclose(y_tri, y_ref, atol=1e-2, rtol=0)
assert torch.allclose(dx_tri, dx_ref, atol=1e-2, rtol=0)
assert torch.allclose(db_tri, db_ref, atol=1e-2, rtol=0)
assert torch.allclose(dw_tri, dw_ref, atol=1e-2, rtol=0)
@triton.testing.perf_report(
triton.testing.Benchmark(
x_names=['N'],
x_vals=[512 * i for i in range(2, 32)],
line_arg='provider',
line_vals=['triton', 'torch'] + (['apex'] if HAS_APEX else []),
line_names=['Triton', 'Torch'] + (['Apex'] if HAS_APEX else []),
styles=[('blue', '-'), ('green', '-'), ('orange', '-')],
ylabel='GB/s',
plot_name='layer-norm-backward',
args={'M': 4096, 'dtype': torch.float16, 'mode': 'backward'},
))
def bench_layer_norm(M, N, dtype, provider, mode='backward', eps=1e-5, device=DEVICE):
# create data
x_shape = (M, N)
w_shape = (x_shape[-1], )
weight = torch.rand(w_shape, dtype=dtype, device=device, requires_grad=True)
bias = torch.rand(w_shape, dtype=dtype, device=device, requires_grad=True)
x = -2.3 + 0.5 * torch.randn(x_shape, dtype=dtype, device=device)
dy = .1 * torch.randn_like(x)
x.requires_grad_(True)
quantiles = [0.5, 0.2, 0.8]
def y_fwd():
if provider == "triton":
return layer_norm(x, w_shape, weight, bias, eps) # noqa: F811, E704
if provider == "torch":
return torch.nn.functional.layer_norm(x, w_shape, weight, bias, eps) # noqa: F811, E704
if provider == "apex":
apex_layer_norm = (apex.normalization.FusedLayerNorm(w_shape).to(x.device).to(x.dtype))
return apex_layer_norm(x) # noqa: F811, E704
# forward pass
if mode == 'forward':
gbps = lambda ms: 2 * x.numel() * x.element_size() * 1e-9 / (ms * 1e-3)
ms, min_ms, max_ms = triton.testing.do_bench(y_fwd, quantiles=quantiles, rep=500)
# backward pass
if mode == 'backward':
y = y_fwd()
gbps = lambda ms: 3 * x.numel() * x.element_size() * 1e-9 / (ms * 1e-3) # noqa: F811, E704
ms, min_ms, max_ms = triton.testing.do_bench(lambda: y.backward(dy, retain_graph=True), quantiles=quantiles,
grad_to_none=[x], rep=500)
return gbps(ms), gbps(max_ms), gbps(min_ms)
test_layer_norm(1151, 8192, torch.float16)
bench_layer_norm.run(save_path='.', print_data=True)
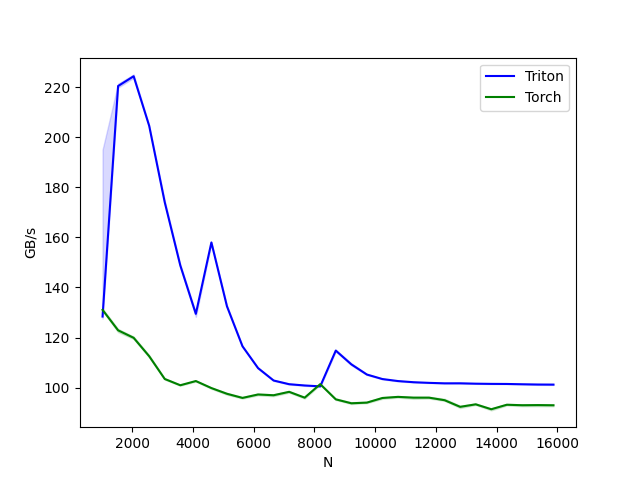
测试结果
- 由于机器性能差异,可能和官网有所出入


















 361
361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











