






Continual Semantic Segmentation with Automatic Memory Sample Selection
一、问题?
1、在许多场景中,静态模型不能总是满足现实世界的需求,因为不断变化的环境要求模型不断更新以处理新数据,有时是新类。由于新阶段无法访问之前的类,因此在对新类进行训练后,模型会忘记之前的类的信息。这种现象,即灾难性遗忘,一直是该领域的一个长期问题。此外,这个问题在密集的预测任务中尤其严重,比如语义分割。
2、本文所解决的问题:如何选择最好的样本进行重放?
选择最常见、多样性最低的样本进行replay,认为最具代表性的样本会提高replay的有效性。然而,最常见的样本可能并不总是后期被遗忘的样本。有论文建议同时保存靠近配送中心的低多样性样本和靠近分类边界的高多样性样本。然而,由于记忆长度是有限的,如何找到两种样本的最优配额以最大程度地促进重放效果成为挑战。此外,现有的方法大多是基于单一因素设计的,而选择性能可能受到多个因素的影响,且关系复杂。例如,除了多样性,记忆样本的选择也应该是依赖于类的,因为硬类需要更多的样本来重放,以缓解更严重的灾难性遗忘问题。
3、为了帮助智能体做出更明智的决策,我们结合样本多样性和类性能特征构建了一个新颖而全面的状态。在状态计算过程中,需要测量样本间的相似度
二、创新点
1、我们将CSS的样本选择表述为马尔可夫决策过程,并引入了一种新颖有效的自动范例,用于CSS中的样本重放。
为了帮助智能体做出更明智的决策,我们结合样本多样性和类性能特征构建了一个新颖而全面的状态。在状态计算过程中,需要测量样本间的相似度。
我们发现,通过计算原型距离的朴素相似度测量在分割中是无效的,因为原型丢失了对像素级预测很重要的局部结构细节。因此,我们提出了一种在多结构图空间中测量的新的相似度,以获得更有信息量的状态。
2、我们为CSS设计了一种有效的RL(reinforcement learning)范式,具有包含多个可以指导选择决策的因素的新颖状态表示,以及用于选择样本并提高其重放有效性的双阶段动作空间。
3、大量的实验证明,我们的样本重放自动范例可以有效地缓解灾难性遗忘问题,实现了最先进的(SOTA)性能。
三、方法细节
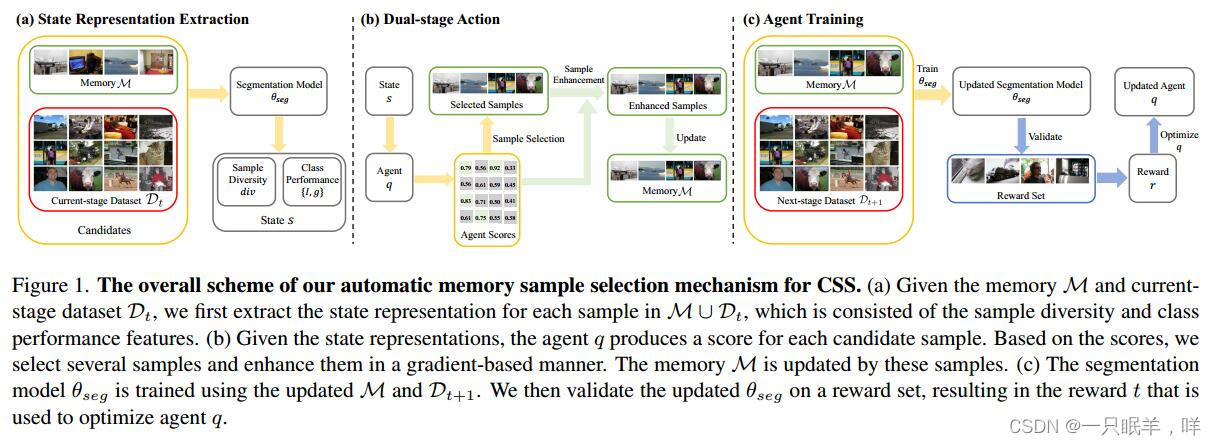
如图1所示,在本工作中,我们在一个强化学习(RL)框架下解决了上述问题,agent q对每个状态s打分,并根据分数做出动作a。利用任务特定的状态表示,一种新的选择增强双阶段动作空间和奖励驱动优化,我们可以优化智能体学习有效的选择策略。
1.马尔可夫决策过程(a Markov Decision Process)
1、状态表示
我们提出将样本多样性和类别表现两种线索结合起来构建状态。样本多样性div衡量其新颖性,可以反映潜在的重放效果。
给定一个图像,在其中的所有C类上,我们计算它们的多样性{divc}C,c=1,准确度 {Ic}C,c=1 and 健忘 {gc}C,c=1,产生了三组特征。然后,我们计算三组在不同类别上的平均值,并将它们连接起来,得到图像的状态表示。
2、多结构空间相似性度量
在以往的工作中,相似度主要在原型级空间[38]或像素级空间[45]中测量。
前者将样本压缩为单个原型特征,然后计算特征距离;这种方法计算效率高,但忽略了空间信息和结构细节,从而导致误差。例如,两张局部结构或物体姿态完全不同的图像可能具有相似的原型特征,因为原型是通过所有像素的平均特征计算的,隐藏了局部细节之间的差异。由于缺乏局部细节而导致的这种错误不利于分割任务,其中局部结构信息对于进行像素级预测[56]非常重要。因此,在CSS中使用原型级相似性构造的状态会导致性能较差。像素级的算法保留了局部信息,但是像素级的距离计算需要的计算成本是不可接受的,可能会导致过拟合。
因此,为了获得信息量更大的相似性,需要一个新的表示空间,既要保留空间信息和结构信息,又要压缩计算成本。在此基础上,我们提出了一种新的方法,首先将每个样本映射到一个多结构图空间中,然后基于图匹配测量样本间的相似度。图的每个顶点代表一个语义结构,边缘代表空间和语义相关性,因此可以利用综合信息来度量细粒度的相似性。
多结构图:
首先,将类c的图生成M个超像素区域,s {rm}M,m=1 (r1 ∪r2 ∪...∪rM = R)。Fi和Fj之间的L2距离作为语义距离 ;超像素ri和rj的两个质心坐标之间的欧氏距离作为空间距离,反映了它们的相对位置。然后,将语义距离和空间距离归一化[0, 1] 。最后,得到距离Di,j = 语义距离+空间距离
图间相似度:
在将图像映射到图空间后,我们使用匹配算法来度量相似度。对于两个图Gi和Gj,采用Sinkhorn算法[15]进行对齐,其中通过求解最优运输问题得到运输成本tc。tc越高,两个图的相似度越低。

表示计算:
计算c类图像之间的平均相似度:
健忘gc作为不同类的相似度计算:
2.具有样本选择和增强的双阶段作用
1、在得到每个样本的状态信息i后,我们使用agent network q,以i作为输入,生成分数q(i)。得分越高,说明样本越适合重放。因此,我们将agent得分作为重放有效性指标,并利用它为RL机制驱动一个新的行动空间,该机制有两个阶段:样本选择和样本增强。
具体来说,我们首先选取agent得分最高的L个记忆样本;
通过最大化agent得分的基于梯度的方式实现增强。具体而言,我们将状态s x视为在分割网络参数θseg下,由输入图像x与M、Dt计算出的特征;我们对x进行梯度更新,使agent得分q(s x)向更大的方向移动,反映更好的重放效果。
简单来说是对选择的图片进行不同的增强,以此更新agent得分。















 417
417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









