







参考该文章
一.综述
1.医学成像的特点
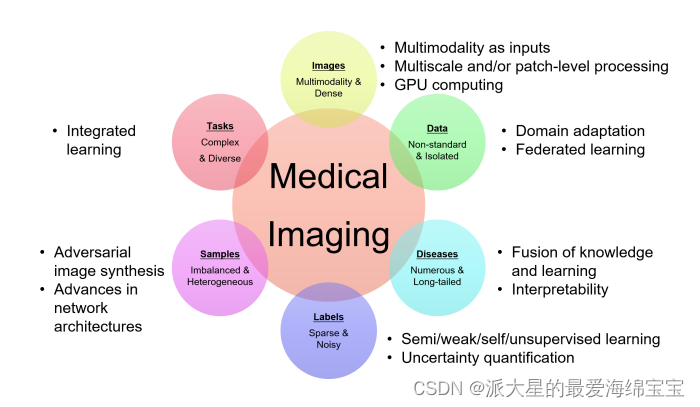
1.图像:多模态、像素分辨率高
现有的:x射线、CT、MRI、超声和数字病理
新的:spectral CT
随着技术发展的越来越好,像素、体素分辨率和信息密度增加
2.数据:孤立且获取方式没有标准
病人隐私、数据管理、数据在不同医院或中心,导致没有一个真正的集中开源医疗大数据
没有标准的获取协议,设备、扫描设置的不同
3.疾病:疾病模式多,且发病率呈长尾分布
常见的疾病,数量少但是数据多
罕见的疾病,数量多但是数据少
4.标签:标签稀疏且有噪声
不同任务需要不同形式的标签,导致了标签的稀疏
不同的经验、条件,用户之间和用户内部的标签很不一致,导致了标签的噪声
图像标签的黄金标准的建立仍是一个有待解决的问题
5.样本:样本种类多、不平衡
已标记的图像中国,不同样本的外观是不同的,其概率分布是多模态的
正样本和负样本的比例不平均
6.任务:图像处理和分析的任务复杂多样
现有一系列技术:重建、增强、restoration、分类、检测、分割和registration。将技术与多种图像模式和多种疾病结合,使得任务复杂多样
2.临床需要和应用
医学成像是医学诊断和治理过程中的重要部分。1990年CT只需要50-100片,如今需要1000-2500片;放大一张与前列腺相关的图像40倍,需要至少10GB;每年世界上医学成像研究成数十亿次,且还在增加。人的主观性、医生之间的巨大差异和疲劳等因素,人对图像的判读是有限的。时间不变的情况下,放射科医生需要审查的图像越来越多,导致了遗漏增加。较长的周转时间,以及缺乏数值结果或量化。
可开发的自动化工具:病理发现的检测、疾病程度的量化、病例特征的描述(例如分为良性和恶性)、广泛定义为决策支持的各种软件工具。也可拓展为characterization of three-dimensional and time-varying events
3.关键技术和深度学习
医学图像重建:目的是通过医学成像设备CT或MRI扫描仪获取的信号形成图像(视觉表示)。从低剂量和/或快速获取的高质量图像重建具有重要的临床意义。
医学图像增强:目的是调整图像的强度,使合成的图像更适合显示或进一步的分析。增强方法包括去噪、超分辨率(super-resolution)、MR偏置校正(MR bias field correction)、图像协调(image harmonization)(super-resolution)。近几年来大量研究了模态转换和模态合成等图像增强步骤。
医学图像分割:目的是为像素分配标签,使具有相同标签的像素组成被分割的对象。在临床量化、治疗和手术中有许多应用。
医学图像配准 registration:目的是将一个或多个图像的空间坐标对齐到一个公共坐标系中。广泛应用于种群分析、纵向分析、多模态融合、借助标签转移的图像分割。
计算机辅助检测(CADe)与诊断(CADx):CADe目的是定位或找到一个包含所感兴趣对象(通常是一个损伤)的边界框。CADx目的是进一步将局部病变分为良性/恶性或多种病变类型之一。
其他技术:关键点检测(landmark detection)、图像或视图识别、自动报告生成等。
以上技术在数学上可以看作是通过函数逼近法(function approximation methods)去逼近一个映射F,y=F(x)。以图像(一张或多张)为输入x,输出一个特定的y。
y的定义依据技术,技术又取决于应用程序或任务的不同。在图像增强中,y是一个质量增强的图像,通常与输入图像x的大小一样;在图像分割中,y是一个标签掩码;在图像配准中,y是一个deformation field;在CADe中,y是一个边界框。
有很多方法近似F,例如深度学习DL(机器学习ML的一个分支)是函数逼近的最强大的方法之一。
例子:
给定一个数据集{(xn,yn);n=1,…,N},深度神经网络的参数为Θ(包括层数、每层的结点数、连接权重、激活函数的选择等),近似F的卷积神经网络可以写作ϕΘ^(x),表示一种模型,可以看作是一个黑盒子。Θ^是最小化损失函数L(Θ)的参数,
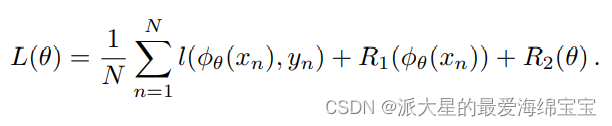
l(ϕΘ(x),y)是penalize预测损失的item-wise损失函数,R1(ϕΘ(xn))关于输出的先验belief,R2(Θ)是关于网络参数的正则项。
4.历史回顾
2012年,CNN展示在ImageNet上的优越性;2013年DL成为十大突破性技术之一。由于以上问题,医学成像界正在热议是否要应用DL,最主要的问题就是标记数据的缺失,即数据挑战。
2015-2016年,开始使用迁移学习TL。实例证明,可利用基于ImageNet的深度网络训练,对医学成像任务进行优化,有助于加快训练收敛速度,提高准确度。
2017-2018年,合成数据增强(synthetic data augmentation)作为处理有限数据集的第二种解决方法出现。典型的增强是任何网络训练的重要组成部分。实例证明,基于生成对抗网络GAN的合成增强图像可以生成放射专家无法识别的病灶图像样本,提高CNN对肝脏病灶的分类性能。
在图像分割上,关键贡献之一是U-Net架构,最初用于微观细胞分割,现用于许多医学分割任务,可有效和鲁棒的学习有效的特征。
5.新型的深度学习方法
1.网络架构
加深网络架构
深网络比浅网络的建模能力和泛化能力更好。
- 从AlexNet开始有加深趋势,如VGGNet、Inception Net和ResNet。
- 使用跳跃连接使网络更具训练性,如DenseNet、U-Net。U-Net用于分割,其他用于分类。
对抗机制和注意力机制
生成式对抗网络GAN
- 在生成模型中加一个鉴别器,鉴别器用来判断样本来自模型分布还是数据分布。生成器和鉴别器都用深度网络表示,它们的训练通过minimax优化完成。
- 应用于医学图像重建、图像质量增强和分割。
注意力机制
- 允许描述图像内容或做出整体决策时,自动发现“在哪里”和“关注什么”。
- “Squeeze-and-excitation networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition2018中,squeeze和excitation可以看作是一种通道注意力机制。
- Self-attention generative adversarial networks,” in International Conference on Machine Learning2019文中,注意力与GAN结合。
- Attention u-net: Learning where to look for the pancreas2018文中,注意力与U-Net结合。
神经结构搜索NAS与轻量化设计
NAS
旨在自动设计深度网络的体系结构,以实现针对给定任务的高性能。已成功应用于医学图像的体积分割。
轻量化设计
目标是在在手机等资源受限设备上设计计算高效的结构,同时保持精度。
2.注释有效方法(Annotation efficient approaches)
为了处理稀疏和噪声标签,一个关键的思想是利用来自现有模型和数据的特征表示能力的强大和健壮性。这些模型和数据不一定来自于同一领域或应用于同一任务。
迁移学习TL
- 目的是通过将通过解决源问题获得的知识应用到不同但相关的目标问题上。
- 一种常用的TL方法是基于ImageNet进行预训练。但是ImageNet是自然图像,它的预训练模型只适用于2D图像,特别是小样本环境。
- 3D anisotropic hybrid network: Transferring convolutional features from 2D images to 3D anisotropic volumes2018中,有效的将从2D图像中学习到的卷积特征转移到3Danisotropic volumes中。
- Med3D: Transfer learning for 3D medical image analysis中,结合了来自多个具有不同模式、目标器官和病理医学挑战的多个数据集,学习了一个3D网络,该网络为3D医学图像分析任务提供了一个有效的预训练模型。
域适应Domain adaptation
是源领域和目标领域具有相同特征空间但不同分布的一种迁移学习TL形式。
- 在Unsupervised domain adaptation in brain lesion segmentation with adversarial networks2017中,通过对抗机制学习domain-invariant特征,该机制将输入数据的域进行分类。
- 在Translating and segmenting multimodal medical volumes with cycle-and shape-consistency generative adversarial network2018中,提出利用周期cycle和形状一致的生成对抗网络对多模式医疗volumes进行合成和分割。
- 在Unsupervised cross-modality domain adaptation of convnets for biomedical image segmentations with adversarial loss2018中,提出一种用于跨模态生物医学图像分割的域自适应模块。
- 在3D U2-net: A 3D universal u-net for multi-domain medical image segmentation2019中,提出一种通用U-Net,用于处理多个领域上的多器官分割任务。
自监督学习
是无监督学习的一种形式,通过代理任务学习表示,其中数据提供监督信号,一旦学习了表示,就可以使用带注释的数据对其进行微调。
- 在Models genesis: Generic autodidactic models for 3d medical image analysis2019中,模型使用代理任务,用一个扭曲的图像作为输入来恢复原始图像。
- 在Rubik’s cube+: A self-supervised feature learning framework for 3D medical image analysis2020中,使用一个魔方代理任务。
半监督学习
使用一小部分带注释的图像训练一个模型,然后为一组带注释的大部分图像生成未标签(pseudo-labels),通过混合这两组图像学习最终的模型。
- 在Semi-supervised learning for network-based cardiac MR image segmentation2017中,使用该方法实现了心脏MR分割方法。
- 在ASDNet: Attention based semi-supervised deep networks for medical image segmentation2018中,提出了一种基于注意力的半监督深度网络用于分割。
弱监督或部分监督学习
- 在Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases2017中,从X光片中解决了一个弱监督多标签疾病分类。
- 在Weakly supervised histopathology cancer image segmentation and classification2014中,提出了使用像素级注释。
- 在Constrained-CNN losses for weakly supervised segmentation2019中,提出了使用点和涂鸦这样弱注释的弱监督方法。
- 在“Marginal loss and exclusion loss for partially supervised multi-organ segmentation2020中,使用边际损失和排除损失应用于多器官分割。
- 在f-AnoGan: Fast unsupervised anomaly detection with generative adversarial networks2019中,仅从正常图像中构建深度模型,检测测试图像中的异常区域。
无监督学习和disentanglement
无监督学习不依赖注释图像的存在。采用对抗学习策略的disentanglement网络结构促进了深度特征的统计匹配。
- 在医学成像中,无监督学习和disentanglement被应用于图像配准、运动追踪、artifact
reduction、改进分类、领域自适应和通用建模。
3.知识融入学习Embedding knowledge into learning
知识有各种来源,如成像物理、统计约束、任务细节和嵌入到DL方法的方式也不同。
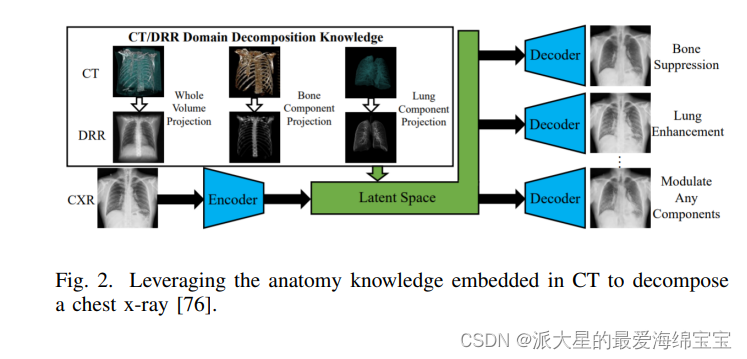
- 如图,将未配对CT中嵌入的解剖学知识解码为一个深度网络,网络将胸部x射线分解为肺、骨骼和其他结构。
4.Federated learning
这一研究方向称为联合学习(FL):解决数据隐私、数据安全和数据访问权相关的问题,可通过分布式计算和模型聚合策略学习通用的、健壮的算法模型,使数据不被转移到医院或影响实验室之外。与传统的集中式学习形成对比:所有本地数据集上传到一台服务器。
- 在Multi-institutional deep learning modeling without sharing patient data: A feasibility study on brain tumor segmentation2018中,FL首次应用到了深度学习DL模型中。
- 在Privacy-preserving federated brain tumour segmentation2019中,研究了几种实用的FL方法。
- 在Multi-site fMRI analysis using privacy-preserving federated learning and domain adaptation: Abide results2020中,FL和领域自适应被应用于训练模型。
5.可解释性Interpretability
特别是在医学诊断上,没有证据和解释,医生很难相信机器学习ML模型的预测。大多数解释方法可分为基于模型和事后可解释性,前者是关于约束模型的,后者关于提取模型已经学习到的关系的信息。
6.Uncertainty quantification
用置信测度表征模型预测,可被视为事后可解释性的方法,尽管不确定性测度通常与模型预测一起计算。
二.肝脏案例研究和进展亮点
近几年,利用医学成像对腹部和疾病进行自动检测、分类和分割取得极大进展。
大型公共数据集促进了进展,如MICCAI数据十项全能(A large annotated medical image dataset for the development and evaluation of segmentation algorithms2019)和深层损伤数据集(DeepLesion: automated mining of large-scale lesion annotations and universal lesion detection with deep learning2018)。
对于单个器官,肝脏、前列腺和脊柱可以说是分割最精确的结构,也是深度学习研究最活跃的结构。
大多研究使用U-Net对肝脏和肝脏病变进行分割,肝脏分割的Dice coefficents通常超过95%。
Universal lesion detectors(DeepLesion: automated mining of large-scale lesion annotations and universal lesion detection with deep learning2018)已被(Bounding maps for universal lesion detection2020)开发应用于包括腹部CT在内的全身CT。Universal lesion detectors可以识别、分类和测量整个腹部的淋巴结和各种肿瘤,使用公开的深层病变数据集进行训练。
腹部成像的深度学习,新进展将会是在不同的患者群体和图像采集的变化中展示普遍性。
三.讨论
未来的科技挑战
大多数挑战都是通过不断改进已知数据挑战的解决方法来解决的。整个community都在不断开发和改进基于迁移学习的解决方法和数据增强方案。随着系统开始跨数据集、医院和国家实现,出现了新的挑战,包括跨采集协议、机器和医院的系统鲁棒性和泛化。数据预处理、持续的模型学习和跨系统的微调是未来的一些新发展。
未来展望
未来,一个直接的进步是将图像与额外的临床背景结合起来,从患者记录到额外的临床描述(如血液测试、基因组学、药物、生命体征和心电图等)。这一步将提供从图像空间到患者级信息的过渡。
随着越来越多的数据可用,DL和AI将在数据中实现无监督的探索,从而推进和增强我们所知的医疗提供新的药物和治疗方法的发现。














 3760
3760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









