







nnunet代码使用
上一篇博文中,我在第三方的超算平台上配置了nnunet包,上手简单,但调参非常有限,也不能使用自己的模型。
本文我将在实验室的服务器配置nnunet代码包(也是怕以后用不了第三方的平台了),可以直接阅读和修改源码,我认为是非常有必要的。
1.服务器环境
import torch
print(torch.__version__) # torch版本查询
print(torch.version.cuda) # cuda版本查询
print(torch.backends.cudnn.version()) # cudnn版本查询
print(torch.cuda.get_device_name(0)) #设备名
打印结果:1.7.1 9.2 7603
GeForce RTX 2080 Ti
2.下载nnunet
两种方法获取nnunet代码包
-
在github官网下载nnunet代码包,本地解压缩得到nnUNet-master文件夹。
-
使用
git clone https://github.com/MIC-DKFZ/nnUNet.git命令
下载完成后,命令行进入对应文件夹
cd nnUNet
pip install -e . # 安装依赖包,注意这里有个.
安装成功后,显示以下内容

3.添加路径
提前准备三个文件夹,分别存放数据集、预处理数据和训练结果
- nnUNet_raw_data_base
- nnUNet_raw_data
- Task040_KiTS
- nnUNet_raw_data
- nnUNet_preprocessed
- nnUNet_trained_models
提前准备好数据集,放在nnUNet_raw_data_base/nnUNet_raw_data下面
三个文件夹的路径一定要记清楚,nnunet的数据都在三个文件夹里面了
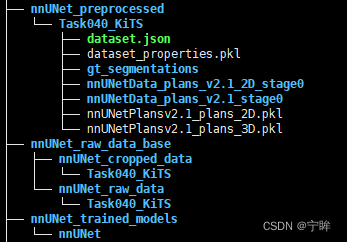
4.数据准备
原始数据如下图所示,使用nnunet要求结构化的数据集,下面进行一个简单处理
下面是我根据nnunet中的dataset_conversion/Task040_KiTS.py修改的代码
import os
import json
import shutil
def save_json(obj, file, indent=4, sort_keys=True):
with open(file, 'w') as f:
json.dump(obj, f, sort_keys=sort_keys, indent=indent)
def maybe_mkdir_p(directory):
directory = os.path.abspath(directory)
splits = directory.split("/")[1:]
for i in range(0, len(splits)):
if not os.path.isdir(os.path.join("/", *splits[:i+1])):
try:
os.mkdir(os.path.join("/", *splits[:i+1]))
except FileExistsError:
# this can sometimes happen when two jobs try to create the same directory at the same time,
# especially on network drives.
print("WARNING: Folder %s already existed and does not need to be created" % directory)
def subdirs(folder, join=True, prefix=None, suffix=None, sort=True):
if join:
l = os.path.join
else:
l = lambda x, y: y
res = [l(folder, i) for i in os.listdir(folder) if os.path.isdir(os.path.join(folder, i))
and (prefix is None or i.startswith(prefix))
and (suffix is None or i.endswith(suffix))]
if sort:
res.sort()
return res
base = "../../../data/KiTS19/origin" # 原始文件路径
out = "../../../nnUNet_raw_data_base/nnUNet_raw_data/Task040_KiTS" # 结构化数据集目录
cases = subdirs(base, join=False)
maybe_mkdir_p(out)
maybe_mkdir_p(os.path.join(out, "imagesTr"))
maybe_mkdir_p(os.path.join(out, "imagesTs"))
maybe_mkdir_p(os.path.join(out, "labelsTr"))
for c in cases:
case_id = int(c.split("_")[-1])
if case_id < 210:
shutil.copy(os.path.join(base, c, "imaging.nii.gz"), os.path.join(out, "imagesTr", c + "_0000.nii.gz"))
shutil.copy(os.path.join(base, c, "segmentation.nii.gz"), os.path.join(out, "labelsTr", c + ".nii.gz"))
else:
shutil.copy(os.path.join(base, c, "imaging.nii.gz"), os.path.join(out, "imagesTs", c + "_0000.nii.gz"))
json_dict = {}
json_dict['name'] = "KiTS"
json_dict['description'] = "kidney and kidney tumor segmentation"
json_dict['tensorImageSize'] = "4D"
json_dict['reference'] = "KiTS data for nnunet"
json_dict['licence'] = ""
json_dict['release'] = "0.0"
json_dict['modality'] = {
"0": "CT",
}
json_dict['labels'] = {
"0": "background",
"1": "Kidney",
"2": "Tumor"
}
json_dict['numTraining'] = len(cases)
json_dict['numTest'] = 0
json_dict['training'] = [{'image': "./imagesTr/%s.nii.gz" % i, "label": "./labelsTr/%s.nii.gz" % i} for i in cases]
这里只是对数据集进行一个拷贝和重命名,不对原始数据进行修改。
运行代码后,整理好的数据集结构如下:
nnUNet_raw_data_base/nnUNet_raw_data/Task040_KiTS
├── dataset.json
├── imagesTr
│ ├── case_00000_0000.nii.gz
│ ├── case_00001_0000.nii.gz
│ ├── ...
├── imagesTs
│ ├── case_00210_0000.nii.gz
│ ├── case_00211_0000.nii.gz
│ ├── ...
├── labelsTr
│ ├── case_00000.nii.gz
│ ├── case_00001.nii.gz
│ ├── ...
dataset.json文件保存了训练集图像、训练集标签、测试集图像信息
{
"description": "kidney and kidney tumor segmentation",
"labels": {
"0": "background",
"1": "Kidney",
"2": "Tumor"
},
"licence": "",
"modality": {
"0": "CT"
},
"name": "KiTS",
"numTest": 0,
"numTraining": 210,
"reference": "KiTS data for nnunet",
"release": "0.0",
"tensorImageSize": "4D",
"test": [],
"training": [
{
"image": "./imagesTr/case_00000.nii.gz",
"label": "./labelsTr/case_00000.nii.gz"
},
{
"image": "./imagesTr/case_00001.nii.gz",
"label": "./labelsTr/case_00001.nii.gz"
},
......
]
}
5.设置环境变量
以下两种方式都可
1.修改主目录中的 .bashrc 文件,通过文本编辑器或者vim修改
-
vim ~/.bashrc
-
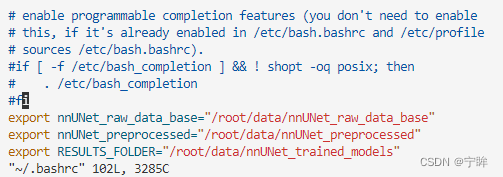
将以下代码添加到 .bashrc 文件的底部
export nnUNet_raw_data_base="/media/fabian/nnUNet_raw_data_base"
export nnUNet_preprocessed="/media/fabian/nnUNet_preprocessed"
export RESULTS_FOLDER="/media/fabian/nnUNet_trained_models"
---------------------------------------------------------------
这里是你自己的路径,就是上一步创建的三个文件夹的路径
2.临时设置环境变量
直接在终端输入三行代码,但每次关闭终端,变量会丢失,需要重新设置
export nnUNet_raw_data_base="/media/fabian/nnUNet_raw_data_base"
export nnUNet_preprocessed="/media/fabian/nnUNet_preprocessed"
export RESULTS_FOLDER="/media/fabian/nnUNet_trained_models"
---------------------------------------------------------------
这里是你自己的路径,就是上一步创建的三个文件夹的路径
可以使用screen,创建一个nnunet界面,每次在nnunet界面执行操作,也可以后台运行,这样变量就不会丢失了
上一篇博文我用的第一种方法,在实验室的服务器上我用的第二种方法
成功设置后,键入echo $RESULTS_FOLDER 等验证路径
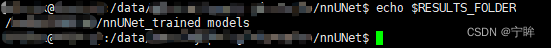
到这一步,nnunet代码包就成功安装了
6.数据预处理
这里需要注意!!
nnunet在使用过程中最常出现的错误就是No module named 'nnunet',可以在.py文件顶部添加以下代码
import sys
sys.path.append("/***/nnUNet/") # nnunet代码包所在目录的绝对路径
数据预处理
cd nnUNet/nnunet/experiment_planning
python nnUNet_plan_and_preprocess.py -t 40 --verify_dataset_integrity
40是任务ID,verify_dataset_integrity是对结构化数据集做一个校验,第一次进行预处理的时候最好还是加上。
运行结束后,预处理完成的数据在nnUNet_preprocessed文件夹下
7.模型训练
edit_plan.py修改模型训练参数,根据需求修改,也可以不修改使用默认参数
import pickle
def write_pickle(obj, file, mode='wb'):
with open(file, mode) as f:
pickle.dump(obj, f)
path = "../../nnUNet_preprocessed/Task040_KiTS/nnUNetPlansv2.1_plans_3D.pkl"
with open(path,'rb') as f:
plans = pickle.load(f)
# print(plans)
print(plans['plans_per_stage'][0])
plans['plans_per_stage'][0]['batch_size'] = 3
plans['plans_per_stage'][0]['patch_size'] = np.array((80, 160,160))
print(plans['plans_per_stage'])
write_pickle(plans,path)
修改后
{'batch_size': 3, 'num_pool_per_axis': [4, 5, 5],
'patch_size': array([ 80, 160, 160]),
'median_patient_size_in_voxels': array([128, 247, 247]),
'current_spacing': array([3.22000003, 1.62 , 1.62 ]),
'original_spacing': array([3.22000003, 1.62 , 1.62 ]),
'do_dummy_2D_data_aug': False,
'pool_op_kernel_sizes': [[2, 2, 2], [2, 2, 2], [2, 2, 2], [2, 2, 2], [1, 2, 2]], 'conv_kernel_sizes': [[3, 3, 3], [3, 3, 3], [3, 3, 3], [3, 3, 3], [3, 3, 3], [3, 3, 3]]}
参考官方教程中的edit_plans_files.md文件
开始训练
cd nnunet/run
python run_training.py 3d_fullres nnUNetTrainerV2 40 2
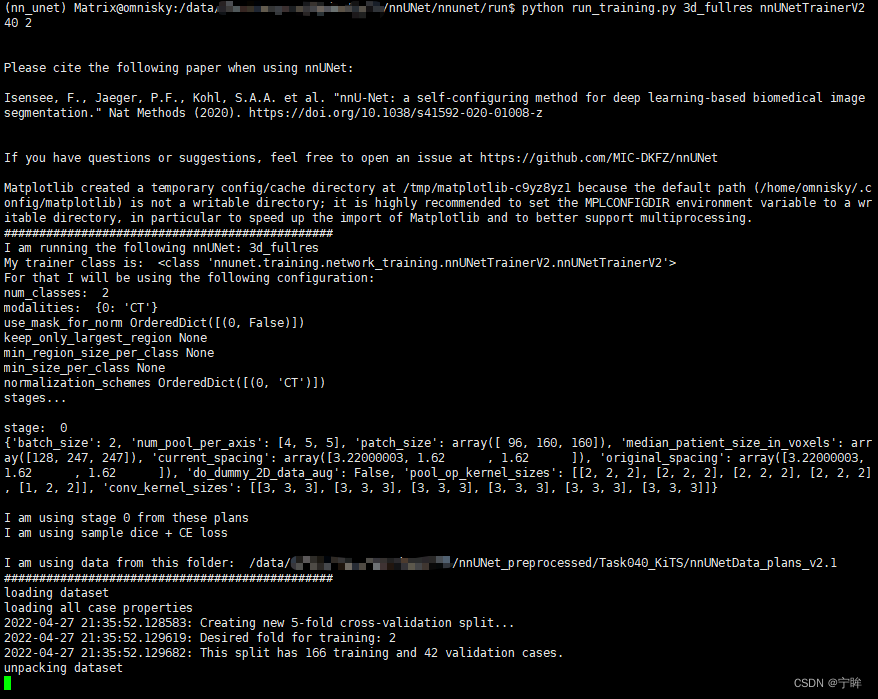
训练开始后,训练日志和训练结果记录在nnUNet_trained_models/nnUNet/3d_fullres/Task040_KiTS文件夹下
Task040_KiTS/
|-- nnUNetTrainerV2__nnUNetPlansv2.1
| |-- fold_2
| | |-- debug.json
| | |-- model_best.model
| | |-- model_best.model.pkl
| | |-- model_latest.model
| | |-- model_latest.model.pkl
| | |-- progress.png
| | `-- training_log_2022_***.txt
| `-- plans.pkl
GPU使用情况
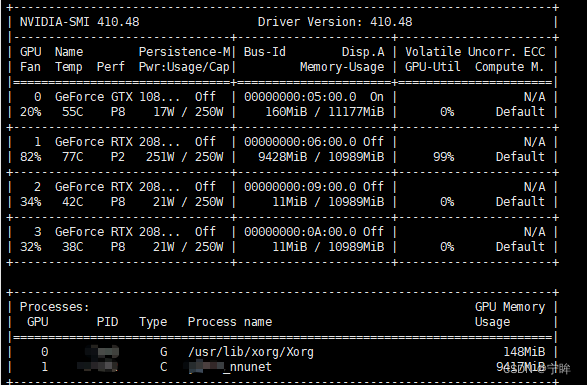
后面就可以根据
nnunet的源码快乐(jian ao)地调参了
部分训练结果
2022-04-28 14:53:37.460869:
epoch: 0
2022-04-28 15:02:25.109707: train loss : -0.0032
2022-04-28 15:02:53.418191: validation loss: -0.2166
2022-04-28 15:02:53.418688: Average global foreground Dice: [0.6796, 0.0004]
2022-04-28 15:02:53.418786: (interpret this as an estimate for the Dice of the different classes. This is not exact.)
2022-04-28 15:02:53.769954: lr: 0.009991
2022-04-28 15:02:53.770110: This epoch took 556.309131 s
2022-04-28 15:02:53.770175:
epoch: 1
2022-04-28 15:11:17.143859: train loss : -0.3128
2022-04-28 15:11:45.544097: validation loss: -0.3496
2022-04-28 15:11:45.544600: Average global foreground Dice: [0.8451, 0.0796]
2022-04-28 15:11:45.544683: (interpret this as an estimate for the Dice of the different classes. This is not exact.)
2022-04-28 15:11:46.046975: lr: 0.009982
2022-04-28 15:11:46.091851: saving checkpoint...
2022-04-28 15:11:46.413020: done, saving took 0.37 seconds
2022-04-28 15:11:46.423257: This epoch took 532.653022 s
2022-04-28 15:11:46.423343:
epoch: 2
2022-04-28 15:20:09.563497: train loss : -0.3793
2022-04-28 15:20:37.972648: validation loss: -0.3408
2022-04-28 15:20:37.973259: Average global foreground Dice: [0.8319, 0.1356]
2022-04-28 15:20:37.973370: (interpret this as an estimate for the Dice of the different classes. This is not exact.)
2022-04-28 15:20:38.510876: lr: 0.009973
2022-04-28 15:20:38.559580: saving checkpoint...
2022-04-28 15:20:40.122515: done, saving took 1.61 seconds
2022-04-28 15:20:40.138686: This epoch took 533.715276 s
......
对比上一篇博文,每个epoch的训练时间大概是948s,训练时间反而减少了许多。2080Ti不可能比A100计算速度更快,看了两个
debug.json文件之后,我发现"num_batches_per_epoch"都是250,而每个循环输入的图像数量为batch_size x num_batches_per_epoch,这样看来A100每个循环输入3000张图像,2080Ti每个循环输入750张图像,因此2080Ti每个循环更快。
参考
debug.json,可以在源码中对照修改,目前还在学习中。
















 978
978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











