







control包含text,image和trajectory
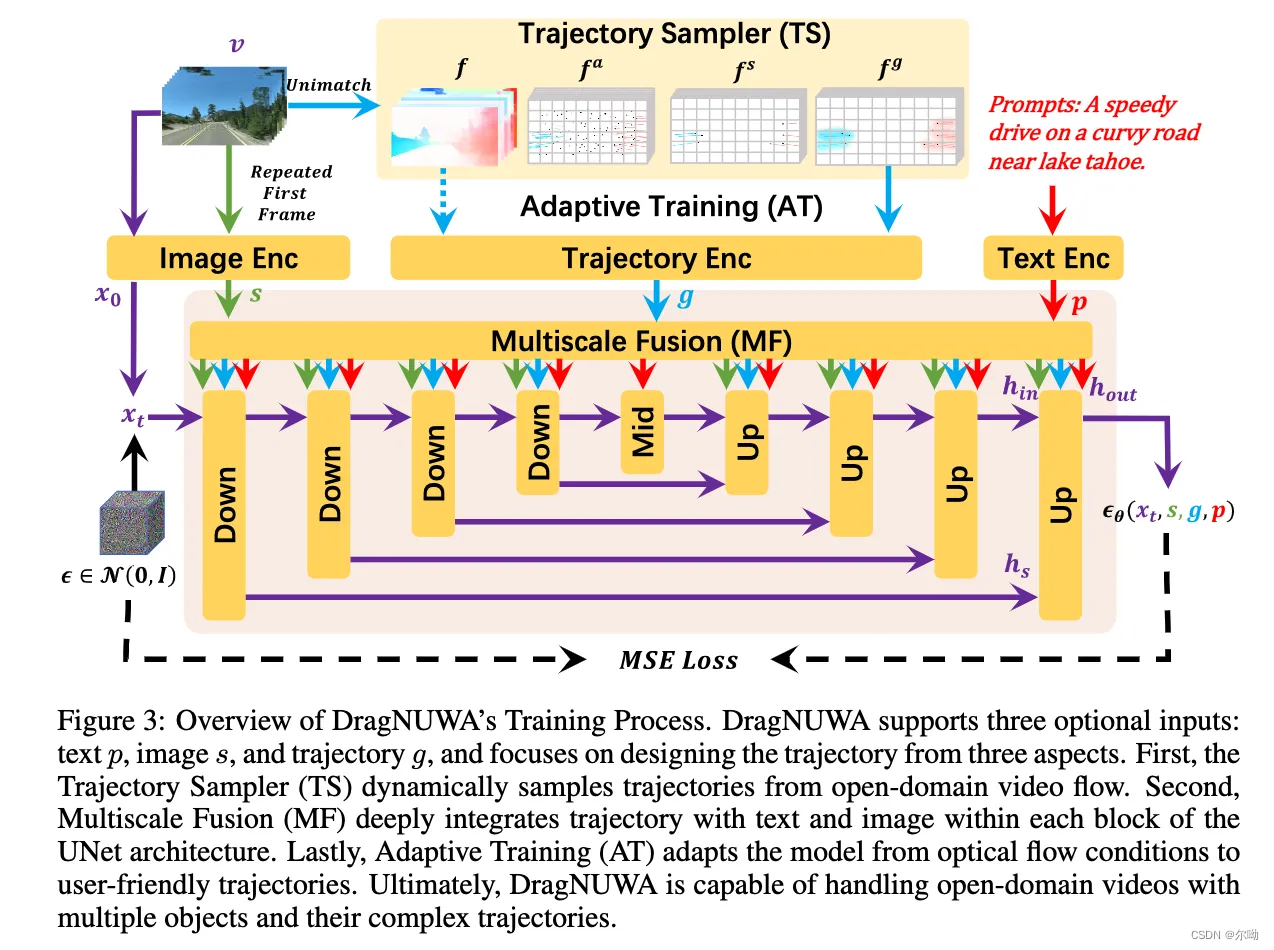
- 训练
a. trajectory sampler:
ⅰ. 直接使用key point tracking model来提取trajectory的方案有两个问题,一个是现有的模型训练数据的domain和视频训练数据不一致,而且user在使用的过程中提供的不一定是关键点的trajectory;
ⅱ. 使用TS来直接从视频光流当中采样trajectory,对于一个视频 v ∈ R L × C × H × W v\in \mathbb{R}^{L\times C \times H\times W} v∈RL×C×H×W,首先使用unimatch来提取密集的光流 f ∈ R ( L − 1 ) × C × H × W f\in\mathbb{R}^{(L-1)\times C\times H\times W} f∈R(L−1)×C×H×W,对于第一帧和第二帧之间的光流表示为 f 0 ∈ R C × H × W f_0\in \mathbb{R}^{C\times H\times W} f0∈RC×H×W,一种直接的方法就是根据光流的密度对 f 0 f_0 f0进行采样,但是存在motion幅度大的区域会采样过多,motion幅度小的区域采样不足的情况,所以本文使用了锚点,间隔 λ \lambda λ并加入随机的扰动 δ \delta δ,范围是 − λ 2 → λ 2 -\frac{\lambda}{2}\rightarrow \frac{\lambda}{2} −2λ→2λ,此时基于anchor可以在 f 0 f_0 f0采样得到一系列光流 f 0 , i , j a = { 0 e l s e f 0 , i , j ( i + δ ) % λ = 0 & ( j + δ ) % λ = 0 f^a_{0,i,j}=\begin{cases} 0&{else} \\ {f_{0,i,j}}&{(i+\delta)\%\lambda=0 \&(j+\delta)\%\lambda=0}\end{cases} f0,i,ja={0f0,i,jelse(i+δ)%λ=0&(j+δ)%λ=0,之后再得到的光流中根据多项式分布随机采样 n ∼ U [ 1 , N ] n \sim U[1,N] n∼U[1,N]个trajectory,这样得到了sparse的 f 0 s f_0^s f0s,之后根据 f 0 s f_0^s f0s iteratively得到对应的trajectory,得到trajectory f s f^s fs之后,因为是稀疏的,所以还对其进行了gaussian filter得到 f g ∈ R ( L − 1 ) × C × H × W f^g\in\mathbb{R}^{(L-1)\times C\times H\times W} fg∈R(L−1)×C×H×W
b. multiscale fusion
ⅰ. video encode使用SDXL的image autoencoder, v ∈ R L × C × H × W → x 0 ∈ R L × c × h × w v\in \mathbb{R}^{L\times C \times H\times W}\rightarrow x_0\in \mathbb{R}^{L\times c \times h\times w} v∈RL×C×H×W→x0∈RL×c×h×w
ⅱ. text使用CLIP来进行embedding p ∈ R l p × c p p\in \mathbb{R}^{l_p\times c_p} p∈Rlp×cp
ⅲ. image control使用视频的第一帧,第一帧复制L次,L是视频的帧数,复制之后每帧独立的使用SDXL的image encoder和几个conv层来进行encode,得到 s ∈ R L × c s × h × w s\in \mathbb{R}^{L\times c_s \times h\times w} s∈RL×cs×h×w
ⅳ. trajectory的encode:TS步骤得到 f g ∈ R ( L − 1 ) × C × H × W f^g\in\mathbb{R}^{(L-1)\times C\times H\times W} fg∈R(L−1)×C×H×W,第一帧拼接上全0的一个frame,之后经过一系列的conv层,得到 g ∈ R L × c g × h × w g\in \mathbb{R}^{L\times c_g \times h\times w} g∈RL×cg×h×w
ⅴ. 在得到image,trajectory,text的control之后经过fusion层,以适应不同的分辨率输入,trajectory g和image s分别downsample到不同的scale,在第l层 g ( l ) , s ( l ) , m ( l ) g^{(l)},s^{(l)},m^{(l)} g(l),s(l),m(l),首先通过zero-initialization的conv转换到scale w g ( l ) , w s ( l ) , w m ( l ) w_g^{(l)},w_s^{(l)},w_m^{(l)} wg(l),ws(l),wm(l)和shift b g ( l ) , b s ( l ) , b m ( l ) b_g^{(l)},b_s^{(l)},b_m^{(l)} bg(l),bs(l),bm(l),其中m是指示当前帧是否作为条件的binary mask,之后scale w和shift b通过linear projection fuse到hidden state h中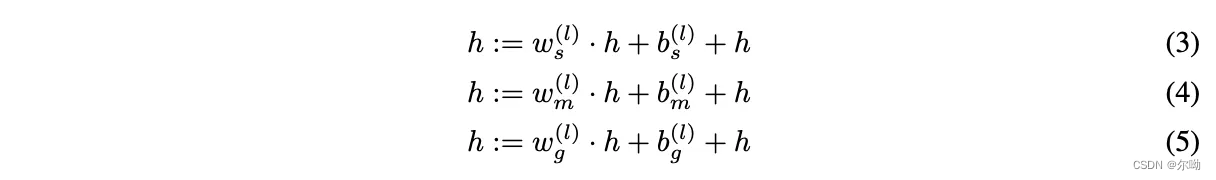
ⅵ. text通过cross attention来完成inject,作为k和v,hidden state作为q;
ⅶ. 为了支持不同的条件组合,在训练的过程中会随机的丢掉一些条件;
c. adaptive training
ⅰ. 在stage1,使用text p+dense optical flow f+repeated first frame s作为条件
ⅱ. 在stage2,使用的是采样之后的trajectory















 596
596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









