







- 问题引入:
- 现在有很多方法综合使用多种损失,包括perceptual loss, adversarial loss和ditortion loss(L1, L2),但是最佳的损失组合方式如何得到还是一个问题;
- 本文提出一个方法,对图像中的每个区域使用最佳的objectives,分为两个模型;
- 一个是predictive model输入LR得到optimal objective map,一个是generative model使用optimal objective map得到SR输出;
- 方法:
- predictive model: T ^ B = C ψ ( x ) \widehat{T}_B = C_{\psi}(x) T B=Cψ(x),输入LR x x x输出optimal objective map T ^ B \widehat{T}_B T B
- generative model: y ^ T ^ B = G θ ( x ∣ T ^ B ) \widehat{y}_{\widehat{T}_B} = G_\theta(x|\widehat{T}_B) y T B=Gθ(x∣T B)
- 对于perception-oriented SR,损失函数是下面七项的加权和,其中
L
r
e
c
L_{rec}
Lrec是重建损失,
L
p
e
r
l
L_{per_l}
Lperl表示的是VGG不同层取出来的feature的perceptual loss
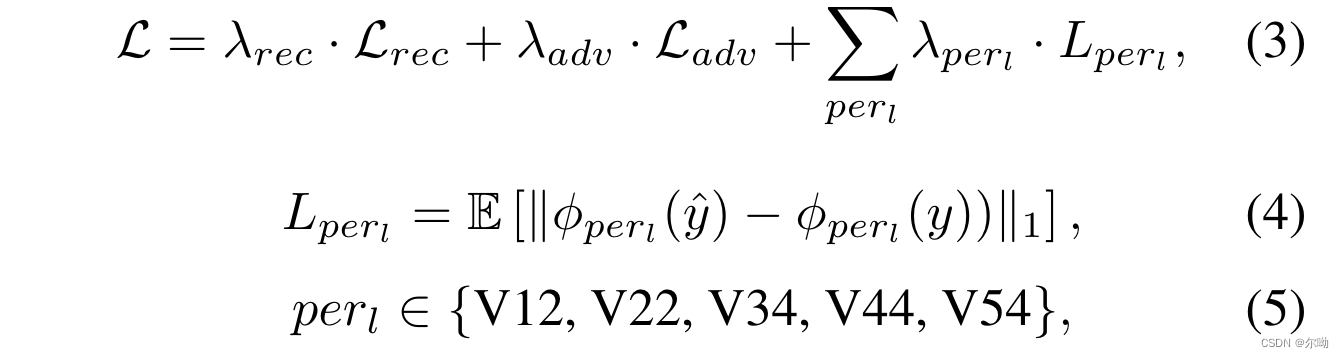
- objective space: 因为损失是七项损失的加权和,所以目标空间可以用一个七维向量来表示 λ i ∈ R 7 \lambda_i\in \mathbb{R}^7 λi∈R7;
- 文中设置了两组参数空间
A
A
A和
B
B
B
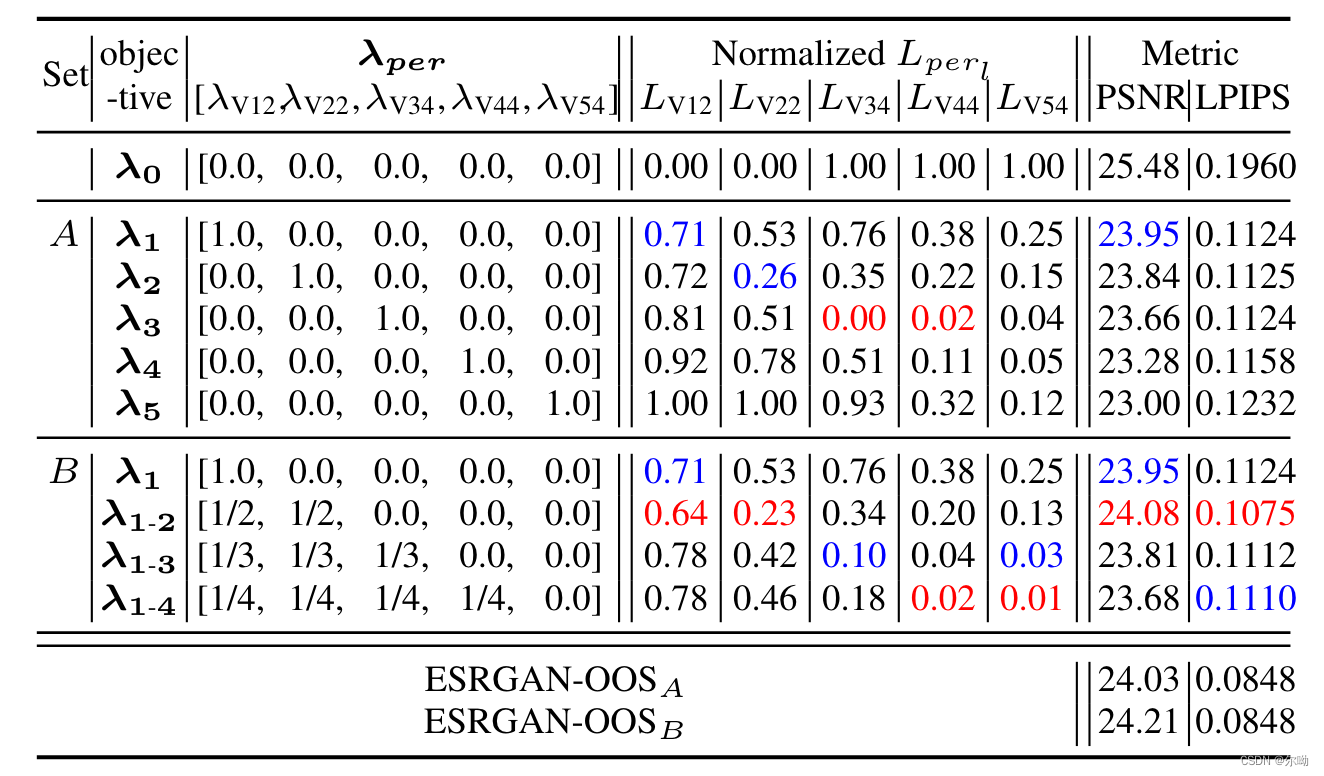
- 之后对于每一个像素位置,选择其中LPIPS最小的时候对应的
λ
\lambda
λ得到map
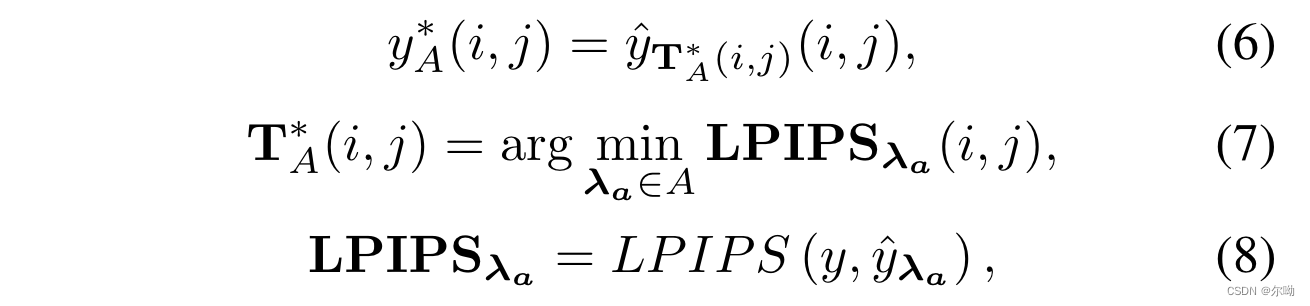















 799
799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









