






传统的机器翻译(seq2seq)任务使用encoder-decoder架构,演化成了现在基于attention的transformer架构
传统的实现方式:
encoder: 输入sequence,输出一个context vector
encoder decoder都使用RNN(LSTM)实现

如果源语言输入序列比较长,这种结构会导致固定长度的context vector,可能无法存储全部的语义信息,而注意力机制的提出则解决了这个问题
传统RNN+Attention:

很像现在的attention结构,α为注意力系数,使用“对齐模式”进行计算,对输入的隐层状态进行加权


现代Attention: 输入 一列vectors 输出 一列考虑了上下文信息的vectors
attention层仅进行上下文信息融合
基于现代attention的transformer架构:
encoder: N to N
decoder: 输出向量一个一个往外蹦
使用masked attention了解模型自己已输出的结果(倒嚼)
使用cross attention连接encoder输出的N vectors和masked attention输出,
Q来自output, K , V来自encoder的N vectors
cross attention: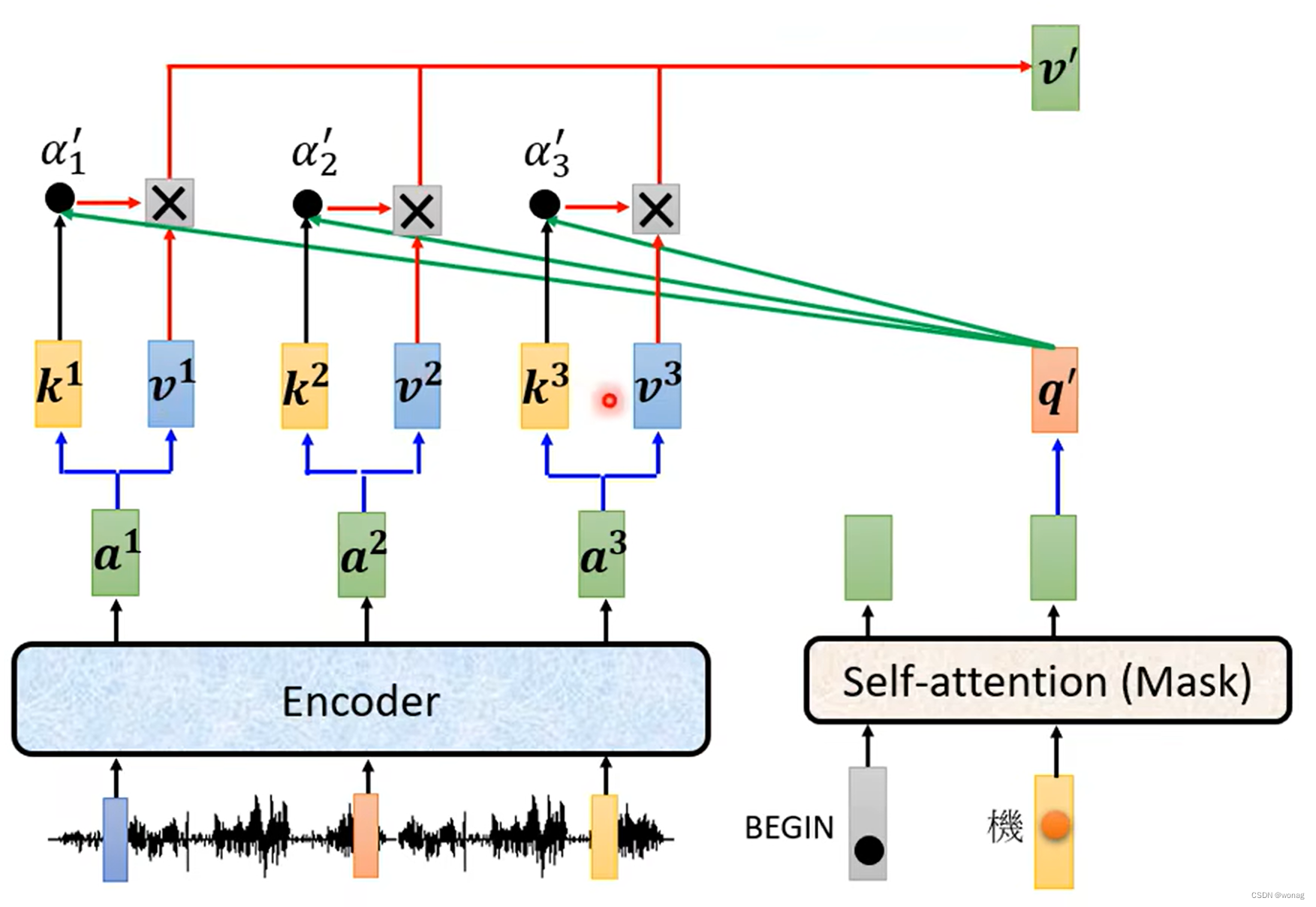















 1088
1088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









