






import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
iris=load_iris()
X=iris.data
y=iris.target
X.shape
#调用PCA
pca=PCA(n_components=2)
pca=pca.fit(X)
X_dr=pca.transform(X)
#X_dr=PCA(2).fit_transform(X)另外一种方式




#如何实现把三种类型的鸢尾花显示在二维坐标上呢
plt.figure()
plt.scatter(X_dr[y==0,0],X_dr[y==0,1],color="red",label=iris.target_names[0])
plt.scatter(X_dr[y==1,0],X_dr[y==1,1],color="blue",label=iris.target_names[1])
plt.scatter(X_dr[y==2,0],X_dr[y==2,1],color="orange",label=iris.target_names[2])
plt.legend()
plt.show()







‘’‘现在我们了解了,V(k,n)是新特征空间,是我们要将原始数据进行映射的那些新特征向量组成的矩阵。我们用它来
计算新的特征矩阵,但我们希望获取的毕竟是X_dr,为什么我们要把V(k,n)这个矩阵保存在n_components这个属
性当中来让大家调取查看呢?
我们之前谈到过PCA与特征选择的区别,即特征选择后的特征矩阵是可解读的,而PCA降维后的特征矩阵式不可解
读的:PCA是将已存在的特征进行压缩,降维完毕后的特征不是原本的特征矩阵中的任何一个特征,而是通过某些
方式组合起来的新特征。通常来说,在新的特征矩阵生成之前,我们无法知晓PCA都建立了怎样的新特征向量,新
特征矩阵生成之后也不具有可读性,我们无法判断新特征矩阵的特征是从原数据中的什么特征组合而来,新特征虽
然带有原始数据的信息,却已经不是原数据上代表着的含义了。
但是其实,在矩阵分解时,PCA是有目标的:在原有特征的基础上,找出能够让信息尽量聚集的新特征向量。在
sklearn使用的PCA和SVD联合的降维方法中,这些新特征向量组成的新特征空间其实就是V(k,n)。当V(k,n)是数字
时,我们无法判断V(k,n)和原有的特征究竟有着怎样千丝万缕的数学联系。但是,如果原特征矩阵是图像,V(k,n)这
个空间矩阵也可以被可视化的话,我们就可以通过两张图来比较,就可以看出新特征空间究竟从原始数据里提取了
什么重要的信息’’’









可以明显看出,这两组数据可视化后,由降维后再通过inverse_transform转换回原维度的数据画出的图像和原数
据画的图像大致相似,但原数据的图像明显更加清晰。这说明,inverse_transform并没有实现数据的完全逆转。
这是因为,在降维的时候,部分信息已经被舍弃了,X_dr中往往不会包含原数据100%的信息,所以在逆转的时
候,即便维度升高,原数据中已经被舍弃的信息也不可能再回来了。所以,降维不是完全可逆的。
Inverse_transform的功能,是基于X_dr中的数据进行升维,将数据重新映射到原数据所在的特征空间中,而并非
恢复所有原有的数据。但同时,我们也可以看出,降维到300以后的数据,的确保留了原数据的大部分信息,所以
图像看起来,才会和原数据高度相似,只是稍稍模糊罢了
也就是说没有逆转,只是将数据映射到了原特征空间,失去的信息量无法补回
'''降维的目的之一就是希望抛弃掉对模型带来负面影响的特征,而我们相信,带有效信息的特征的方差应该是远大于
噪音的,所以相比噪音,有效的特征所带的信息应该不会在PCA过程中被大量抛弃。inverse_transform能够在不
恢复原始数据的情况下,将降维后的数据返回到原本的高维空间,即是说能够实现”保证维度,但去掉方差很小特
征所带的信息“。利用inverse_transform的这个性质,我们能够实现噪音过滤'''
from sklearn.datasets import load_digits
digits=load_digits()
digits.data
fig,axes=plt.subplots(4,10
,figsize=(16,8)
,subplot_kw={"xticks":[],"yticks":[]}
)
for i ,ax in enumerate(axes.flat):
ax.imshow(digits.images[i,:,:])






#PCA实现对手写数字的降维
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
digits=pd.read_csv(r"C:\Users\MI\Desktop\菜菜sklearn\菜菜的完整版课程\课件\04主成分分析PCA与奇异值分解SVD\digit recognizor.csv")





#查看0-200的学习曲线
scores=[]
for i in range(1,100,10):
X_dr=PCA(i).fit_transform(X)
rcf=RandomForestClassifier(n_estimators=10,random_state=20)
sc=cross_val_score(rcf,X_dr,y,cv=5).mean()
scores.append(sc)
plt.figure(figsize=(20,5))
plt.plot(range(1,100,10),scores)
plt.show()

#查看0-200的学习曲线
scores=[]
for i in range(10,25):
X_dr=PCA(i).fit_transform(X)
rcf=RandomForestClassifier(n_estimators=10,random_state=20)
sc=cross_val_score(rcf,X_dr,y,cv=5).mean()
scores.append(sc)
plt.figure(figsize=(20,5))
plt.plot(range(10,25),scores)
plt.show()

##找到最佳维度查看效果,并调整n_estimatiors
X_dr=PCA(24).fit_transform(X)
cross_val_score(RandomForestClassifier(n_estimators=10,random_state=0),X_dr,y,cv=10).mean()

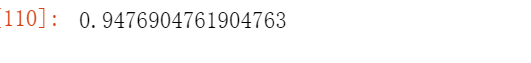
#换模型,knn()不填默认是5
#画出knn的学习曲线
from sklearn.neighbors import KNeighborsClassifier as KNN
scores=[]
for i in range(10):
X_dr=PCA(24).fit_transform(X)
sc=cross_val_score(KNN(i+1),X_dr,y,cv=5).mean()
scores.append(sc)
plt.figure(figsize=(20.5))
plt.plot(range(10)+1,scores)
plt.show()

%%timeit
#查看下面代码的运行时间
cross_val_score(KNN(4),X_dr,y,cv=5).mean()

原本785列的特征被我们缩减到23列之后,用KNN跑出了目前位置这个数据集上最好的结果。再进行更
细致的调整,我们也许可以将KNN的效果调整到98%以上。PCA为我们提供了无限的可能,终于不用再因为数据量
太庞大而被迫选择更加复杂的模型了















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









