










Smart Data Pipelines: Tools, Techniques, and Key Concepts
一、什么是数据管道?
数据管道是一系列步骤,允许数据从一个系统转移到另一个系统,特别是分析、数据科学或人工智能和机器学习系统,并在其中变得有用。在高层,数据管道的工作方式是从源中提取数据,应用转换和处理规则,然后将数据推送到目的地。
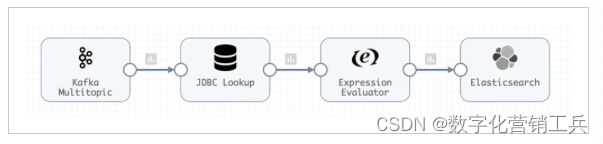
(从卡夫卡多主题到弹性搜索的数据管道)
二、数据管道的用途是什么?
有很多数据。根据目前的估计,每个人每天创建2.5万亿字节的数据,世界上有78亿人。数据管道将原始数据转换为可用于分析、应用程序、机器学习和人工智能系统的数据。它们保持数据流动,以解决问题,为决策提供信息,让我们面对现实,让我们的生活更方便。
数据管道用于:
1. 为客户360向销售和营销部门提供销售数据
2. 连接全球科学家和医生网络以加快药物发现
3. 推荐金融服务,帮助企业蓬勃发展
4. 追踪新冠肺炎病例并为社区卫生决策提供信息
5. 将各种传感器数据与人工智能相结合,实现预测性维护
有这么多工作要做,数据管道可能会很快变得非常复杂。
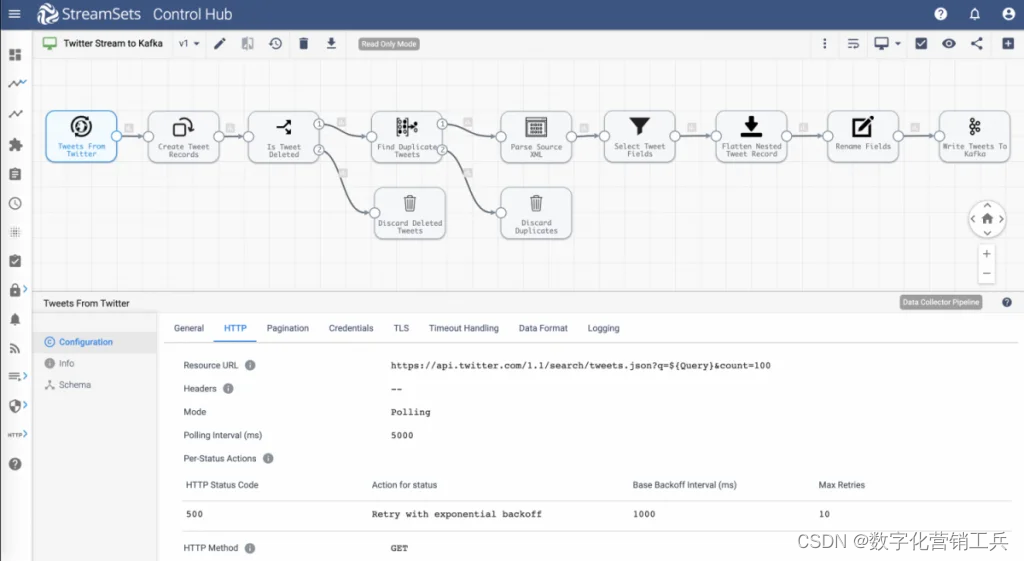
(情绪分析样本流数据摄入数据管道)
三、使用数据管道的好处
数据管道做得好对公司和组织以及他们所做的工作都有着难以置信的优势。
1. 自助服务数据
数据科学家和业务分析师可以临时创建数据管道,以解决IT瓶颈。这意味着,当人们有出色的想法时,他们可以测试它们,快速失败,更快创新。
2. 加速云迁移和采用
数据管道可以帮助您扩展云的存在,并将数据迁移到云平台(是的,这与s有关)。云计算可以帮助您以传统内部部署数据中心闻所未闻的处理速度、成本效益和超大容量为许多新用例提供支持。此外,您的团队可以利用这些云平台上发生的快速创新,如自然语言处理、情绪分析、图像处理等。
3. 实时分析和应用程序
消费者和业务应用程序中的实时或接近实时的功能给数据管道带来了压力,要求它们立即将正确的数据交付到正确的位置。流式数据管道为实时分析和应用程序提供连续数据。
四、使用数据管道面临的挑战
当您的业务依赖数据时,当数据流戛然而止时会发生什么?或者数据转向错误,永远无法到达预期目的地?或者更糟的是,数据是错误的,可能会带来灾难性后果?
1. 始终在建数据
构建和调试数据管道需要时间。您必须与模式保持一致,设置源和目的地,检查您的工作,查找错误,并来回切换,直到您最终可以投入使用,到那时业务需求可能会再次发生变化。这就是为什么这么多数据工程师有这么多积压的工作。
2. 无序数据管道
即使是对行或表的微小更改也可能意味着数小时的返工、更新管道中的每个阶段、调试,然后部署新的数据管道。数据管道通常必须离线才能进行更新或修复。计划外的更改可能会导致隐藏的损坏,需要数月的工程时间才能发现和修复。这些意想不到的、计划外的、无情的变化被称为“数据漂移”。
3. 建造它,他们就会来
数据管道是为特定的框架、处理器和平台构建的。更改其中任何一种基础设施技术以利用成本节约或其他优化可能意味着在部署前需要数周或数月的重建和测试管道。
在我们研究如何应对数据管道开发的这些挑战之前,我们需要花点时间了解数据管道是如何工作的。
五、数据管道是如何工作的?
当部署并运行数据管道时,它会从源中提取数据,应用转换和处理规则,然后将数据推送到目标。
1. 5个通用数据管道源
1)JDBC
2)Oracle CDC
3)HTTP客户端
4)HDFS
5)Apache Kafka
数据源以非常不同的方式处理数据,可能包括应用程序、消息传递系统、数据流、关系数据库和NoSQL数据库、云对象存储、数据仓库和数据湖。数据结构因来源而异。
2. 常见的数据转换
转换是对数据结构、格式或值的更改,以及对数据本身的计算和修改。管道可能嵌入了任意数量的转换,以便为使用或正确路由数据做好准备。举几个例子:
1)屏蔽PII(个人身份信息)以实现保护和法规遵从性
2)正在转换字段的数据类型
3)基于公式或表达式进行计算
4)重命名字段、列和要素
5)加入或合并数据集
6)转换数据格式(例如,JSON到Parquet)
7)动态生成Avro模式和其他模式类型
8)处理缓慢变化的尺寸
3. 5个通用数据管道目的地
1)Apache Kafka
2)JDBC
3)Snowlfake(雪花)
4) Amazon S3(亚马逊S3)
5) Databricks
目的地是指数据可以随时使用、直接投入使用或存储以供潜在使用的系统。它们包括应用程序、消息传递系统、数据流、关系数据库和NoSQL数据库、数据仓库、数据湖和云对象存储。
大多数数据管道工程工具都提供了一个连接器和集成库,这些连接器和集成是为快速管道开发而预先构建的。
六、数据管道体系结构
根据您正在收集的数据类型和使用方式,您可能需要不同类型的数据管道体系结构。许多数据工程师认为流式数据管道是首选的体系结构,但了解您可能使用的所有3种基本体系结构很重要。
1. 批处理数据管道
批处理数据管道在特定时间移动大型数据集,或响应某一行为,或在达到阈值时移动大型数据。批处理数据管道通常用于批量接收或ETL处理。批处理数据管道可以用于每周或每天将数据从CRM系统传递到数据仓库,以便在用于报告和业务智能的仪表板中使用。
2. 流数据管道
流数据管道在创建数据时不断地将数据从源流到目标。流式数据管道用于填充数据湖,或作为数据仓库集成的一部分,或发布到消息传递系统或数据流。它们还用于实时应用程序的事件处理。例如,流数据管道可以用于向欺诈检测系统提供实时数据并监控服务质量。
3. 更改数据捕获管道(CDC)
更改数据捕获管道用于刷新数据并保持多个系统同步。只共享自上次同步以来对数据的更改,而不是复制整个数据库。当两个系统使用相同的数据集运行时,这在云迁移项目中尤其有用。
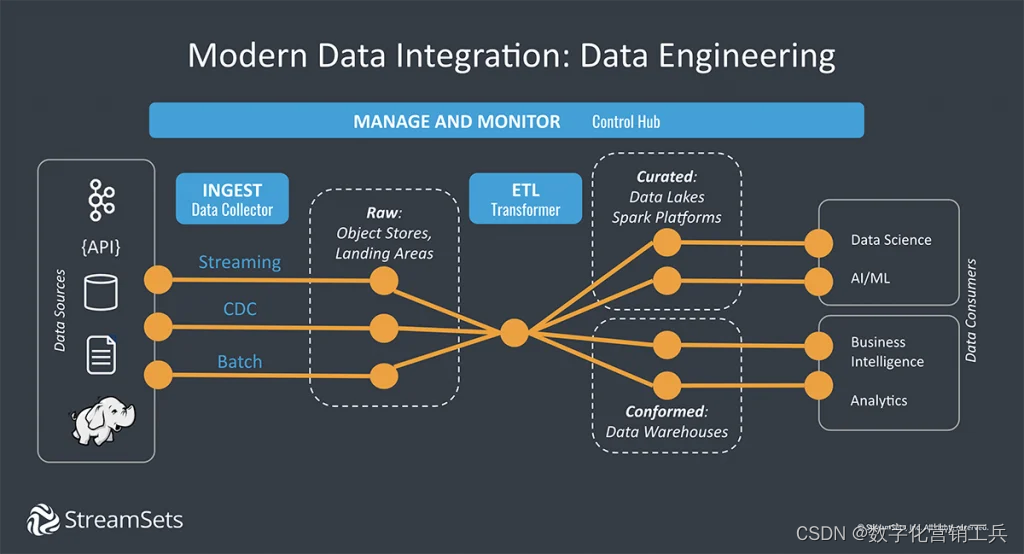
(数据工程管线图)
七、数据管道工具
在给定的时间为单个目的构建单个管道是没有问题的。找一个简单的工具来设置数据管道,或者手工编写步骤代码。但是,您如何将该过程扩展到数千个数据管道,以支持整个组织数月或数年来不断增长的数据需求?在考虑数据管道工具时,重要的是要考虑数据平台的发展方向。
1). 您是否从一个地方获取数据,然后将其放在其他地方?还是您需要对其进行转换以适应下游分析需求?
2). 您的数据环境是否稳定并完全在您的控制之下?还是它是动态的,从外部系统或应用程序中提取数据?
3). 对于短期分析项目,管道会移动数据一次吗?或者,随着时间的推移,您构建的管道是否需要操作以处理数据流?
1. 数据摄入和数据加载工具
数据接收和数据加载工具使数据管道易于设置、易于构建和易于部署,解决了“建设中”的问题,但前提是您可以依靠数据科学家稍后进行数据准备工作。这些工具只支持最基本的转换,最适合简单地复制数据。这些数据管道不是意图驱动的,而是刚性的,并嵌入了数据结构和语义的细节。当数据漂移发生时,必须重新构建和部署它们,而不是适应变化。
2. 传统数据集成平台
更复杂的数据集成或ETL软件可能为每种可能的场景提供一个解决方案,其中包括数百个连接器、集成和转换。但这些平台是为一个数据漂移罕见的时代而设计的。一有变化的迹象,这些数据管道就会破裂,需要大量返工。数字化转型的需求正在快速发展,为每一个可能的结果进行规划可能是不可能的。
3. 现代数据集成与转换平台
当今的动态基础设施和海量数据集需要为混合和多云架构构建数据集成解决方案。现代数据集成平台使您能够构建不受意外变化影响的数据管道。
这些数据管道使您能够快速移动,并相信您的数据将在几乎没有干预的情况下继续流动,而不是永远处于建设中、无序或仅限于单个平台。这些云平台允许您:
1)使用易于使用的GUI设计和部署数据管道
2)简化Snowflake和其他数据平台中复杂转换的构建和维护
3)建立尽可能多的弹性来处理更改
通过指向新平台来采用新平台(例如,将Azure与AWS一起添加),这项任务只需几分钟。
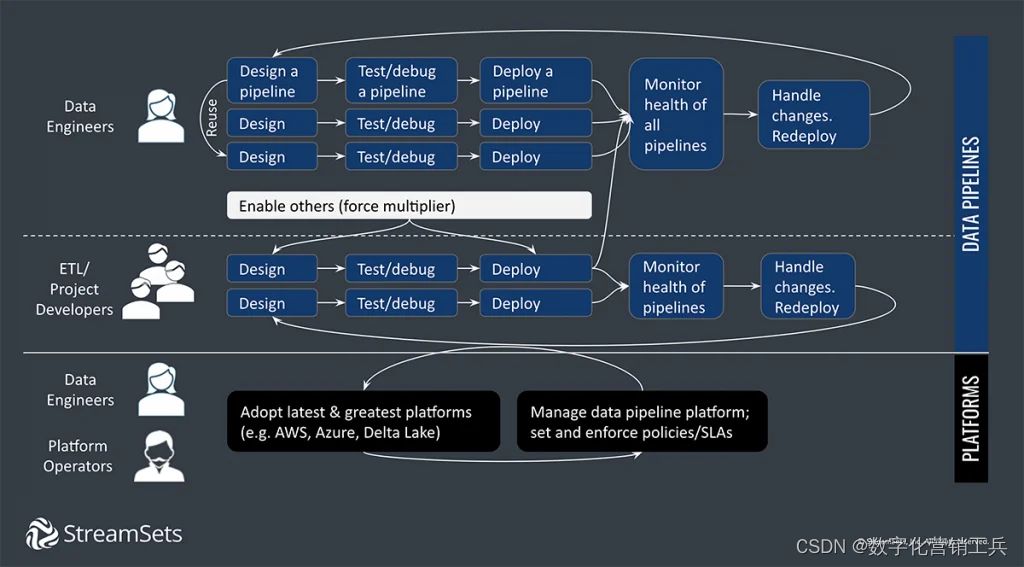
(数据工程生态系统和数据管道工作流)
八、智能数据管道示例
批处理、流式传输和CDC数据管道架构可以以一千种不同的方式应用于业务和运营需求。以下是用于接收、转换和传递数据的智能数据管道的几个示例。
1. Salesforce向亚马逊数据湖的大量摄入
这种批量接收数据管道非常适合将Salesforce联系人与AmazonS3中的一些帐户信息进行存档。Salesforce数据接收管道可能以批处理模式运行以进行定期归档,也可能实时运行以不断卸载客户数据。目的地可以是任何云存储平台。
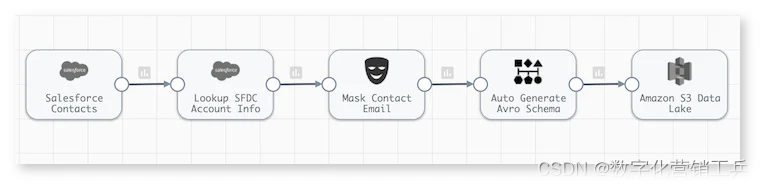 (批量摄取数据管道)
(批量摄取数据管道)
2. 使用变更数据捕获迁移到Databricks Delta Lake
许多组织正在将数据湖从内部部署转移到云,以利用现收现付的定价、更高的性能、爆发能力和新技术。此更改数据捕获管道跟踪数据源中的更改,并将其传输到目标,以在初始加载后保持系统同步。
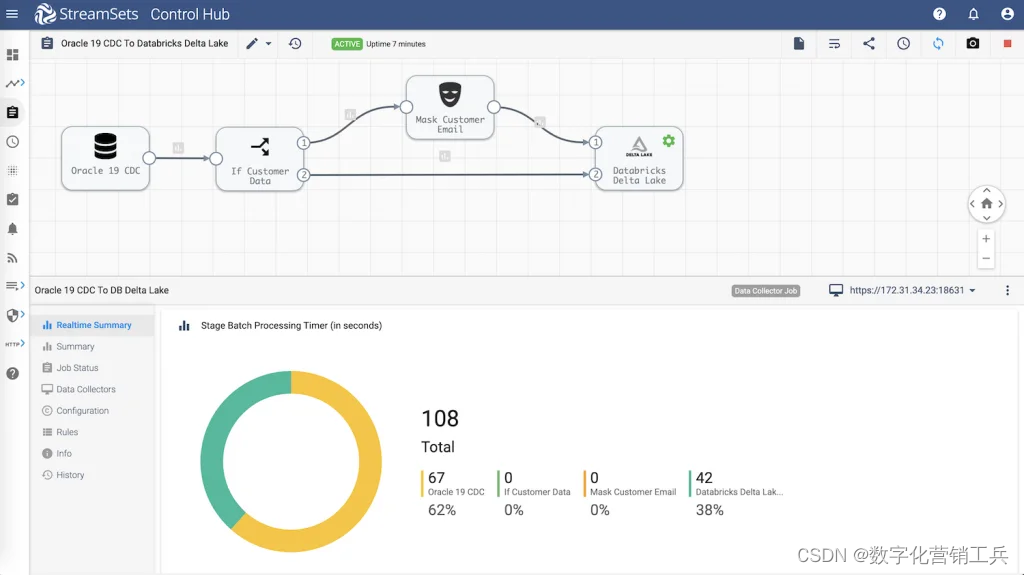
(将数据捕获更改为databricks数据管道)
3. 将多个Kafka消息流合并到AmazonS3
Apache Kafka是一个用于流分析的分布式事件流平台。这个流式数据管道处理多个上游应用程序向多个Kafka主题写入的大量数据。您可以向S3发送Kafka消息,并通过增加线程数量、转换数据并将其传递到AmazonS3数据湖来垂直扩展。
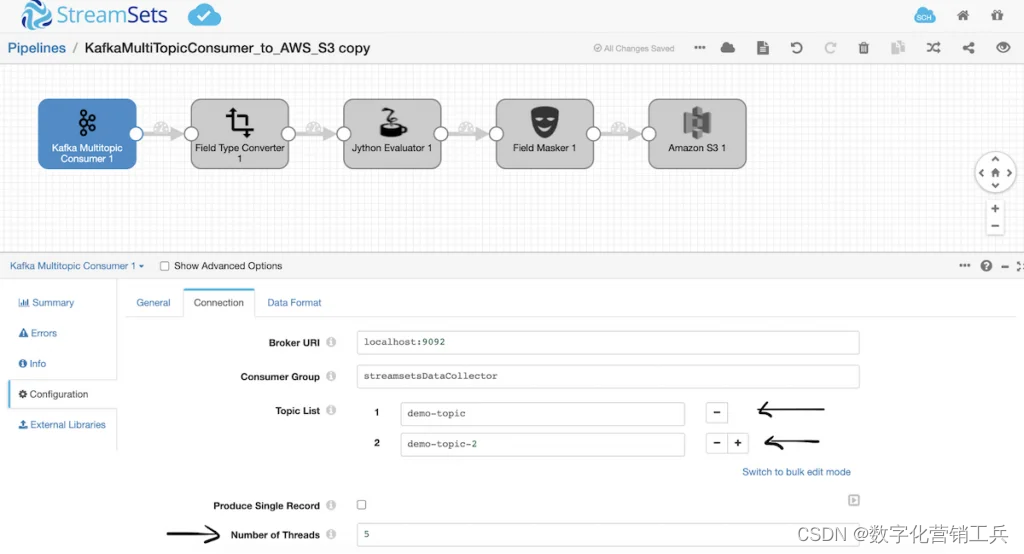
(kafka消息到S3数据管道)
4. 用于模型实验的MLflow集成管道
机器学习模型的好坏取决于数据的质量和用于训练模型的数据集的大小。实验需要数据科学家使用可信数据集的子集以快速、迭代的方式创建模型。Databricks上的MLflow集成管道允许跟踪和版本化模型训练细节,以及跟踪版本,以便数据科学家能够快速访问训练数据,并更容易地进入生产。
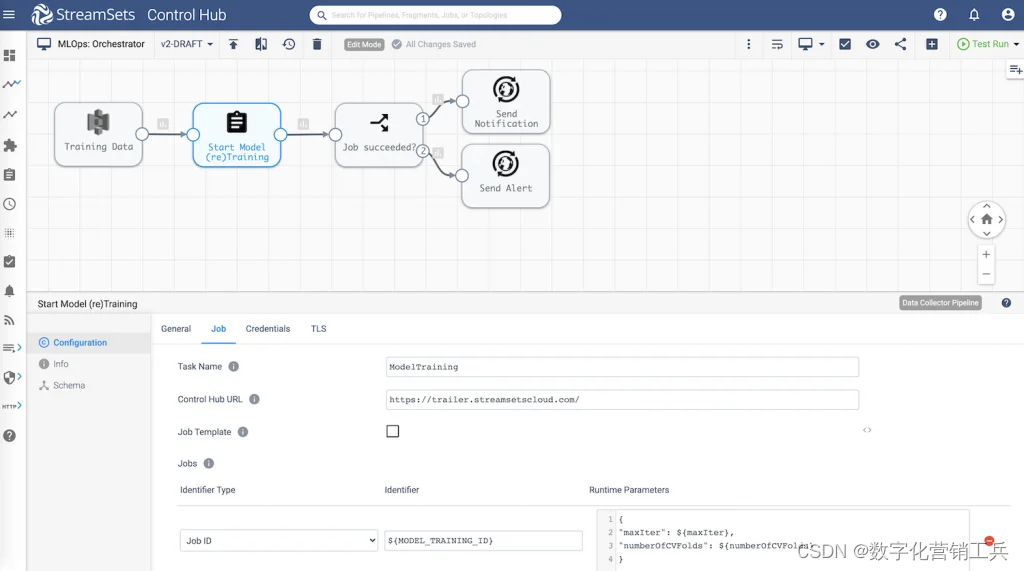
(数据块上的MLflow集成管道)
5. 多个用例和人物的数据管道
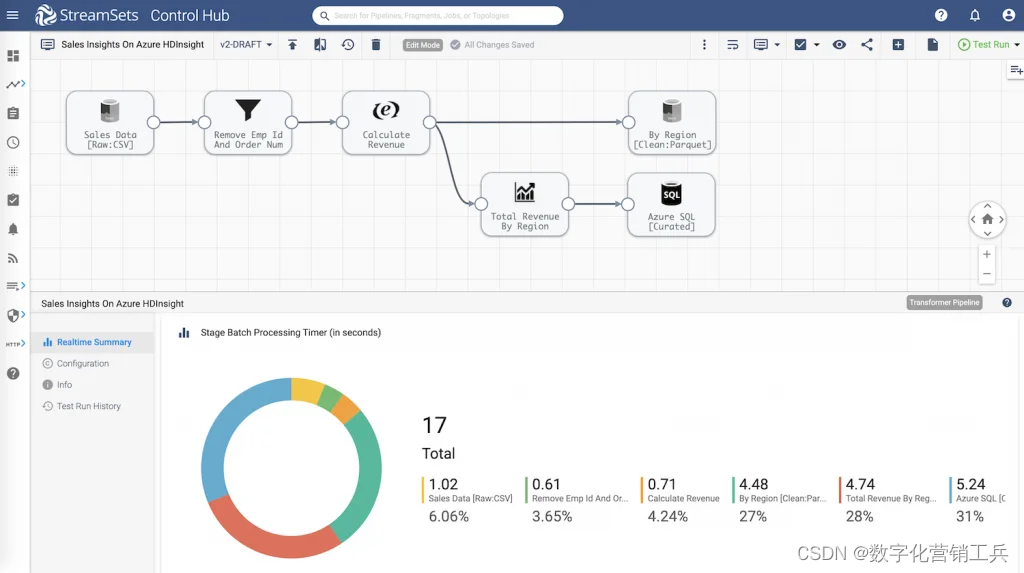
有时,您的数据必须同时做两件事。这个Spark ETL数据管道收集销售收入数据,按地区计算总额,然后以正确的格式将其发送到多个目的地,以满足单个管道中两个不同部门的业务需求。数据在Azure HDInsight上交付到Parquet中的Spark平台,并作为SQL数据交付到Microsoft Power BI。每个人都很开心。
(数据块上的MLflow集成管道)
除了上面的资源外,您还可以随时使用这些现成的部署示例数据管道来启动管道设计。只需复制并更新要运行的源和目标。
九、什么是智能数据管道?
如果汽车可以自行驾驶,当你的血压升高时,手表可以通知你的医生,为什么数据工程师仍在指定模式和重建管道?智能数据管道是一种内置智能的数据管道,用于提取细节并尽可能自动化,因此很容易在很少干预的情况下连续设置和操作。因此,智能数据管道能够快速构建和部署、容错、自适应和自愈。
2020年的全球疫情非常清楚地表明,公司必须能够迅速应对不断变化的条件。企业应该找到合适的合作方,系统全面有序建立数据管道和网络,获取企业内部和外部等生态中的有效数据。

















 290
290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









