







上一章讨论了文档标准化加载,现在转向文档的细分,这虽简单却对后续工作有重大影响。
一、为什么要进行文档分割
- 模型大小和内存限制:大型GPT模型参数众多,需大量计算和内存,而硬件设备如GPU或TPU有内存限制,文档分割有助于在这些限制内工作。
- 计算效率:长文本序列需更多资源,分块可提高计算效率。
- 序列长度限制:GPT模型有最大序列长度限制(如2048个token),超长文档需分割。
- 更好的泛化:多块训练增强模型对不同文本样式和结构的泛化。
- 数据增强:分割可增加训练样本,如将长文档分成多个独立样本。
注意事项:分割可能导致上下文信息丢失,特别是在分割点附近,需权衡分割方法。
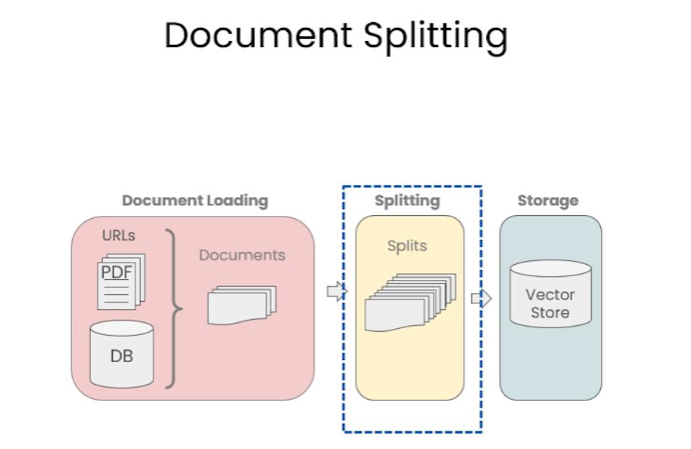
图 4.3.1 文档分割的意义
单一字符分割易失语义,应分至完整语义段落或单元以保准确性。
二、文档分割方式
Langchain 中文本分割器都根据 chunk_size (块大小)和 chunk_overlap (块与块之间的重叠大小)进行分割。

图 4.3.2 文档分割示例
- chunk_size 指每个块包含的字符或 Token (如单词、句子等)的数量
- chunk_overlap 指两个块之间共享的字符数量,用于保持上下文的连贯性,避免分割丢失上下文信息

图 4.3.3 文档分割工具
Langchain提供多种文档分割方式,区别在怎么确定块与块之间的边界、块由哪些字符/token组成、以及如何测量块大小
三、基于字符分割
文本分割方法与任务类型紧密相关,尤其在拆分代码时。我们引入了语言文本分割器,含多种编程语言分隔符,需考虑不同语言差异
我们将从基于字符的分割开始探索,借助 LangChain 提供的 RecursiveCharacterTextSplitter 和 CharacterTextSplitter 工具来实现此目标。
CharacterTextSplitter 是字符文本分割,分隔符的参数是单个的字符串;RecursiveCharacterTextSplitter 是递归字符文本分割,将按不同的字符递归地分割(按照这个优先级[“\n\n”, “\n”, " ", “”]),这样就能尽量把所有和语义相关的内容尽可能长时间地保留在同一位置。因此,RecursiveCharacterTextSplitter 比 CharacterTextSplitter 对文档切割得更加碎片化
RecursiveCharacterTextSplitter 需要关注的是如下4个参数:
- separators - 分隔符字符串数组
- chunk_size - 每个文档的字符数量限制
- chunk_overlap - 两
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2189
2189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









