







文章目录
C++ STL
栈
#include <stack>
using namespace std;
//定义一个栈
stack <typename> name;
//stack函数实例
stack.push(x);//将元素x加入到栈中
stack.top();//获取栈顶元素
stack.pop();//将栈顶元素弹出
stack.empty();//判断栈是否为空,返回值类型为空
stack.size();//返回栈内元素
队列
#include <queue>
using namespace std;
//队列的定义
queue< typename > name;
queue<int> Q;
//queue函数实例
Q.push(x);//将元素x入队
Q.front();//获取队首元素
Q.back();//获取队尾元素
Q.pop();//将队首元素出队
Q.empty();//判断队列是否为空
Q.size();//队列中元素的个数
优先队列(Priority_queue)
优先队列就是按照元素的优先级来确定对首部的元素的队列,它是由堆实现的,这种优先级的规则可以自定义。优先队列可以用于计算哈夫曼树最短路径权值,可以对Dijkstra算法进行优化,还可以解决一些贪心问题。
#include<cstdio>
#include<queue>
#include<string>
using namespace std;
int main() {
priority_queue<int>q;
q.push(3);//将3入队
q.empty();//检查队列是否为空
q.pop();//将优先级最高的元素出队
q.size();//队列的大小
//第一个参数是元素类型,第二个是承载底层数据结构堆的容器,第三个是参数的比较类,less<int>表示数字越大优先级越高
priority_queue<int, vector<int>, greater<int>>q_1;
}
//当想以结构体中的数据作为优先级的时候,应该堆操作符进行重载
//使用时直接将相应的结构体定义的变量直接入队即可
struct fruit {
string name;
int price;
//价格高的优先级高
//由于队列默认将优先级高的放在队首,如果将小于号重载为大于号,最后会将规则反向
friend bool operator < (fruit f1, fruit f2) {
return f1.price < f2.price;
}
};
//也可以将比较函数写在结构体外面
struct cmp{
bool operator()(fruit f1, fruit f2) {
return f1.price > f2.price;
}
};
priority_queue<fruit, vector<int>, cmp>p_2;
//当结构体数据较大应该使用引用来提高效率
/*
friend bool operator < (const fruit& f1, const fruit& f2) {
....
}
*/
pair采用方法
pair可以用于快速定义一个相当于拥有两个变量的结构体。使用pair需要添加函数头utility.当然map函数头中包含前者。
//定义一个pair变量,并初始化
pair<typename1, typename2>name(initial1, initial2);
//定义一个临时pair变量
name = make_pair(initial1, initial2);
pair函数的操作
比较两个pair函数:可以直接用比较符,规则是先比较第一个的大小,当相等时比较第二个元素的大小
常见用途:1.代替二元结构体机器构造函数。2.作为map的键值进行插入。
#include<iostream>
#include<string>
#include<map>
using namespace std;
int main(){
map<string, int>mp;//定义一个哈希表
//往哈希表中插入两个对键值
mp.insert(make_pair("hey", 5));
mp.insert(pair<string, int>("Hei", 10));
//利用迭代器遍历哈希表
for(map<string, int>::iterator it = mp.begin();it != mp.end();++it){
cout<<it->first << " " << it->second << endl;
}
return 0;
}
向量
需要包含文件头vector 和using namespace std;
定义方式:
vector<typename> vector_name;
操作:
1.获取元素的最后一个元素
vector_name.end()-1;//注意end是指向最后一个元素的下一位
vector_name.back();
vector_name.rbegine();
vector_name.at(vector_name.size()-1);
集合set
集合是一种内部有序且不含重复元素的容器。当数据加入到集合中是,会自动去重和排序,默认排序是从小到大。要使用集合需要加上set函数头,并且使用std名字空间。
定义方式:(其实容器定义的方式都大同小异)
迭代器不是指针,是类模板,表现的像指针。他只是模拟了指针的一些功能,通过重载了指针的一些操作符, − > 、 ∗ 、 + + 、 − − ->、*、++ 、-- −>、∗、++、−−等封装了指针
set<typename> name;
访问方式:(集合只能通过迭代器访问)
//定义迭代器
set<typename>::iterator it;
//除了vector和string之外,其他的STL都不支持*(it+1)的访问方式
//枚举
set<int>st;
//initialize
.......
for(set<int>::iterator it = st.begin(); it != st.end();it++){
visit(*it);
}
set常用的函数:
insert(x);//将x加入set,并实现递增排序和去重(O(logN))
find(value);//找到对应value的迭代器(O(logN))
erase(it);//删除迭代器所指的元素,可以通过find函数找到对应的迭代器
erase(value);//删除值为value的元素。时间复杂度O(logN)
erase(first, last);//删除区间元素,删除区间为[first, last)
size();//set中元素的个数O(1)
clear();//delete all elements within the set
使用unordered_set,只进行去重而不进行排序,速度比set要快很多。
字符串类型String
string类型将字符串数组的一些常用操作封装起来,使用时需要添加文件头string(注意一点string和string.h是不一样的),还需要std的名字空间。
初始化
//define & initializing
string str = "abc";
访问
//Access
//1.By subindex
str[1];
想要输入或者输出字符串,只能使用cin和cout。需要用printf输出,可以使用c_str()函数将string类型转换成字符串数组
printf("%s\n",str.c_str());
通过迭代器访问
//define. It no needs typename
string::iterator it;
for(string::iterator it = str.begin(); it != str.end();++it){
printf("%c", *it);
}
string和vector一样,能够直接通过对迭代器加减某数字实现访问。
str.begin() + 3;
函数实例
//连接两string类型
str3 = str2 + str1;
str1 += str2;
//按照字典序比较两string类型的大小
str1 >= str2;
//返回string类型的长度
str.size();
str.length();
insert()函数
str.insert(pos,string);//在str的第pos位插入stringO(N)
//str的3号位插入str2
(prototype->)insert(it,it2,it3);//串[it2, it3)插入到it对应的位置上
str.insert(str.begin() + 3, str2.begin(), str2.end());
erase()删除
//删除单个元素
erase(it);//删除元素的迭代器
erase(fist,last);//删除区间[first, last)的元素
erase(pos,length);//pos开始删除length个字符个数
clear();//清空
其他
substr(pos,len);//冲pos开始获取长度为len的子串
string::npos; //一个常数等于-1或者是unsigned_int的最大值,用于find函数失配的返回值
find(str2);//找到str2在字符串中第一次出现的位置,找不到返回string::npos.时间复杂度O(nm)
str.replace(pos, len, str2);//将str从pos位开始长度为len的子串替换成str2
str.replace(it1,it2,str2);//把迭代器范围内[it1,it2)的子串换成str2
链表
链表的概念
链表的物理地址是可以是不连续的,但是链表逻辑上是连续的。链表包含两个部分,一个用于存储数据,一个用于存储下一个节点的内存地址,以保证逻辑上的连续。
//链表的结构体定义
struct node{
typename data;//数据域
node* next;//指针域
};
链表节点的空间分配
为链表节点分配空间可以利用两种函数:malloc(C语言) 和new(C++)。但是在空间分配之后,需要队空间进行释放,否则在一些情况下就会导致内存泄漏(在一些大型程序中,可能会导致弃用的空间一直被占用,而使得无法申请新的空间)。
malloc函数
#include<stdlib.h>
typename* p = (typename*)malloc(sizeof(typename));
/*整个过程就是malloc函数申请一个于数据类型大小一致的空间,这个时
候返回的指针是void类型,然后将他强制转化成int类型,并分配给
typename指针。申请失败的时候会返回空指针
*/
//释放内存
free(p);
//本质上就是将p指针指向空地址,原先的地址占用状态被修改
new运算符(推荐使用)
//申请一个节点空间
typename* p = new typename;
//取消对该节点的占用
delete(p;
链表的基本操作
创建链表(运用for语句实现)
//传入的数组为每个节点的数据域的值
//尾插法:需要一个链表最后一个节点的指针。
node* create (int Array[]){
node *p, *pre, *head;
head = new node;//创建头节点
head->next = NULL;
pre = head;
for(int i = 0; i < 5; ++i){
//创建新结点:1.申请空间;2.完成指针域和数据域的赋值
p = new node;
p->data = Array[i];
p->next = NULL;
//更新状态指针
pre->next = p;
pre = p;
}
return head;
]
//注意一点在删除一个节点的时候需要有一个指向该节点的指针,以便后续删除该节点
静态链表
静态链表的主要原理就是Hash。它利用数组的下标作为相应节点的地址,适用于节点地址是比较小的整数。
//静态链表节点的定义方式
struct Node{
typename data;
int next;//注意这里的地址是一个整型变量
}node[size];
需要注意一点:因为静态链表是由数组实现的,所以就可能需要对其进行排序,但是如果这时候结构体类型名和结构体变量名相同(是允许的),sort函数就与出现编译错误。
(例题:A1032)
静态链表的使用步骤:
//定义静态链表
struct Node{
int address;
typename data;
int next;
XXX;//节点的某些性质
}node[MAXN];
//初始化静态链表:将性质量定义为正常情况达不到的数字
for(int i = 0; i < MAXN; ++i){
node[i].XXX = 0;
}
//标记(针对性质操作)
//可以针对性质进行统计,标记
int p = begin, count = 0;//用于开始遍历和统计
while(p != -1){
XXX = 1;
count++;
p = node[p]->next;
}
//简化操作
//由于静态链表直接采用地址映射的方式,这可能会导致地址
//不是连续的,此时应该将有效节点转移到左端,可以通过排
//序(sort函数)来实现(结合初始化的值)
搜索
深度优先搜索(DFS)
深度优先遍历会优先解决一种情况下的所有情况之后,再去解决其他的情况。如果能将一个事件的各个情况写成树形结构,就可以很容易地通过这种方法解决。
/*
有n 件物品,每件物品的重量为w[i],价值为c[i]。现在需要选出若干件物品放入一个容
量为V 的背包中,使得在选入背包的物品重量和不超过容量V 的前提下,让背包中物品的价
值之和最大,求最大价值。(l<n<20)
*/
#include <cstdio>
const int maxn = 30;
int n;//物品数量
int V;//背包容量
int maxValue = 0;//最大的价值
int w[maxn], c[maxn];//分别为单个物品的重量个价值
//参数分别为物品编号,总质量,总价值
void DFS(int index, int sumW, int sumC){
if (index == n) {//完成对所有物品的选用
if (sumW <= V && sumC > maxValue) {//检查当前方案是否满足条件
maxValue = sumC;//更新最大价值
}
return;
}
//对index号的物品,有两种结果,放入背包或是不放入背包
DFS(index + 1, sumW, sumC);//不放入背包
DFS(index + 1, sumW + w[index], sumC + c[index]);//放入背包
}
int main() {
scanf("%d%d", &n, &V);
for (int i = 0; i < n; ++i) {
scanf("%d", &w[i]);//重量
}
for (int i = 0; i < n; ++i) {
scanf("%d", &c[i]);//价值
}
DFS(0, 0, 0);//从第零件物品开始,此时的价值和重量都是0
printf("%d\n", maxValue);
return 0;
}
注意到在加入index号的物品时,总重量发生变化,这可能会导致结果不满足条件,如果能在进入递归之前能够进行检查,能够减少一些不必要的递归
//在递归之前加上判断条件
void DFS_A(int index, int sumW, int sumC) {
if(index == n)return;
DFS_A(index + 1, sumW, sumC);
//检查质量是否满足要求,以确定是否进入递归
if (sumW + w[index] <= V) {
if (sumC + c[index] > maxValue)maxValue = sumC + c[index];
DFS_A(index + 1, sumW + w[index], sumC + c[index]);
}
}
深度优先遍历的方法可以用于解决获取最优“子序列”的问题,也就是满足基本条件下的最优序列。
/*
问题描述:给定N个整数,从中选择K个数,使这K个数之和恰好等于给定的整数X,求出元素
平方和最大的结果
算法思想:利用一个数组,将已经选择的整数放入其中,当选择index号数字时,将
这个数字加入到数组中,进入递归,之后再将这个数字取出,进入不选择index号数
的递归。
*/
int n, k, x, maxSumSqu = -1, A[maxn];
vector<int>temp, ans;
void DFS_BSqu(int index, int nowK, int sum, int sumSqu) {
if (nowK == k && sum == x) {
if (sumSqu > maxSumSqu) {
maxSumSqu = sumSqu;
ans = temp;
}
return;
}
if (index == n || nowK > k || sum > x)return;
temp.push_back(A[index]);
DFS_BSqu(index + 1, nowK + 1, sum + A[index], sumSqu + A[index] * A[index]);
temp.pop_back();
DFS_BSqu(index + 1, nowK, sum, sumSqu);
}
广度优先
广度优先类似于先解决简单的问题(离起点最近)然后再一步步深入。广度优先会先遍历所有的情况,对于求最优解的情况有优势。
/*
问题描述:给定一个n*m大小的迷宫,其中*代表不可通过的墙
壁,而“.”代表平地,S表示起点,T代表终点。移动过程中,如
果当前位置是(x,y)(下标从0开始),且每次只能往前上下
左右移动,求从起点到终点的最小步数。
算法思想:可以将迷宫当作树型结构,将迷宫的起点作为树的
根节点现在问题转换成找到迷宫终点所在树的层数
*/
#include<cstdio>
#include<cstring>
#include<queue>
using namespace std;
const int maxn = 100;
struct node
{
int x, y;//记录当前的位置
int step;//步数(层数)
}S,T,Node;//分别为起点,重点,临时节点
int n, m;//分别为行,列
char maze[maxn][maxn];//迷宫信息
bool inq[maxn][maxn] = { false };//检查此位置是否遍历过
//增量数组,XY组合表示一个节点上下左右四个方向的位置
int X[4] = { 0,0,1,-1 };
int Y[4] = { 1,-1,0,0 };
//检查(x,y)这个位置是否应该入队
bool test(int x, int y) {
//超出边界
if (x >= n || x < 0 || y >= m || y < 0)return false;
//遇到墙壁
if (maze[x][y] == '*')return false;
//检查是否入队。入队则是之前访问过的位置
if (inq[x][y] == true)return false;
return true;//表示该位置有效
}
int BFS() {
queue<node>q;
q.push(S);//将起点加入到队列中
//判断当前访问的位置(出队的位置)是否为终点
while (!q.empty()) {
node top = q.front();
q.pop();
//该位置为终点,直接返回此时的深度
if (top.x == T.x && top.y == T.y) {
return top.step;
}
//检查该位置4个方向上的情况
for (int i = 0; i < 4; ++i) {
int newX = top.x + X[i];
int newY = top.y + Y[i];
if (test(newX, newY)) {
//新节点,更新相关的信息
Node.x = newX, Node.y = newY;
Node.step = Node.step + 1;
q.push(Node);
inq[newX][newY] = true;
}
}
}
return -1;
}
int main(void) {
//迷宫规格
scanf("%d%d", &n, &m);
//传入迷宫信息
for (int i = 0; i < n; ++i) {
getchar();
for (int j = 0; j < n; ++j) {
maze[i][j] = getchar();
}
maze[i][m + 1] = '\0';
}
scanf("%d%d%d%d", &S.x, &S.y, &T.x, &T.y);
S.step = 0;
printf("%d\n", BFS());
return 0;
}
值得注意的一点,当将一个元素push入队的时候,其本质就是将该元素的一个副本入队,所以,队列中的元素和原数据来源是相互独立的。
二叉树
二叉树可以通过递归的方式定义,也就是可以将二叉树的子树看作一个新的二叉树。注意一点,二叉树的左右节点是由严格区分的。
二叉树的存储和操作
//二叉树结构体的定义
struct node{
typename data;
node* lchild;
node* rchild;
};
node* root = NULL;//建树之前根节点不存在,将其设为NULL
//新建节点:申请空间,赋值,初始化,返回节点地址
node* newNode(int v){
node* Node = new node;
Node->data = v;
Node->lchild = Node->rchild = NULL;
return Node;
}
//搜索节点:检查特殊情况和满足条件的情况,然后用同样的方法检查其他的节点
void search(node* root, int x, int newdata){
if(root == NULL)return;
if(root->data == x)root->data = newdata;
search(root->lchild, x, newdata);
search(root->rchild, x, newdata);
}
//二叉树节点的插入,注意这里输入的参数是引用型的,因为要对这个树进行修改
void insert(node* &root, int x){
//查找失败,这就是要插入节点的地方
if(root == NULL){
root = newNode(x);
return;
}
if(根据条件检查检索的方向)insert(root->lchild,x);
else insert(root->rchild,x);
}
//二叉树的建立
node* Create(int data[], int n){
node* root = NULL;
for(int i = 0; i < n; ++i){
insert(root,data[i]);
}
return root;
}
二叉树的遍历
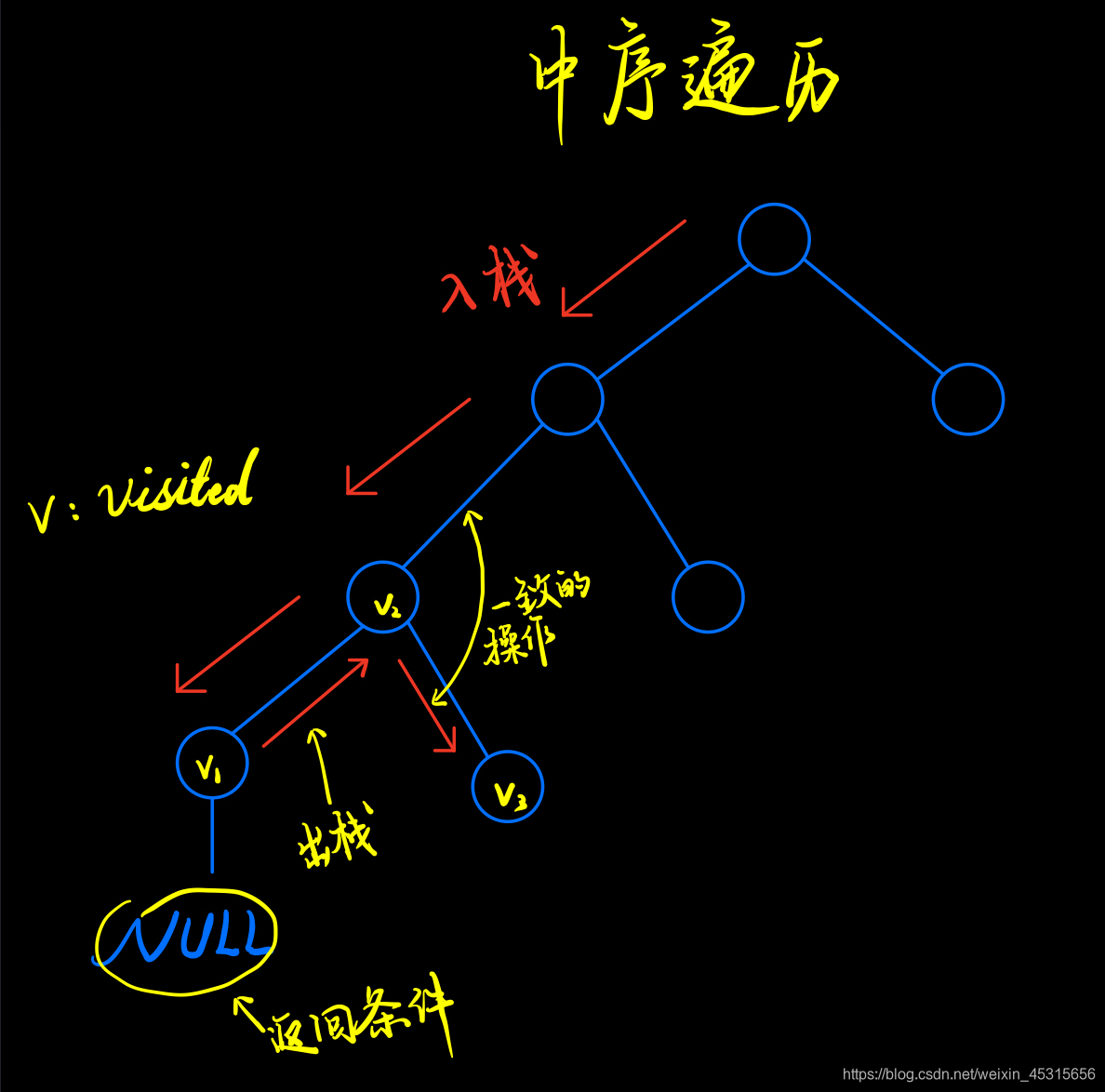
/*中序遍历(非递归):先找到最左边的节点,在寻找的过程中将途中的节点加入到栈中,当遇到根节点的时候,
取出栈顶元素(这一步相当于回溯),访问其右节点,然后继续原先的循环
*/
void InOrderWithoutRecursion2(BTNode* root)
{
//空树
if (root == NULL)
return;
//树非空
BTNode* p = root;
stack<BTNode*> s;
while (!s.empty() || p)
{
if (p)
{
s.push(p);
p = p->lchild;
}
else
{
p = s.top();
s.pop();
cout << setw(4) << p->data;
p = p->rchild;
}
}
}
/*
先序遍历(非递归):在访问头节点的同时先将右节点加入到栈中,然后再继续访问左子树。当没有左孩子的时候
访问右节点,表现为取出栈顶元素,进行访问
*/
void PreOrderWithoutRecursion(BTNode* root)
{
if(root == NULL)return;
stack<BTNode*>s;
BTNode* p = root;
s.push(root);
while(!s.empty())
{
visit(p);
if(p->rchild)s.push(p->rchild);
if(p->lchild)p = p->lchild;
else{//访问右子树
p = s.top();
s.pop();
}
}
}
/*
后序遍历(非递归):后序遍历有一个问题,需要当前访问的节点是父节点的左孩子还是右孩子,如果是左孩子,就访问
右孩子,否则访问头节点。
*/
void postOrderWithoutRecursion(BTNode* root)
{
if(root == NULL)return;
stack<BTNode*>s;
BTNode* pCur, *pLastVisit;
pCur = root;
pLastVisit = NULL;
//Find out the leftmost element of the tree.
while(pCur){
s.push(pCur);
pCur = pCur->lchild;
}
while(!s.empty())
{
pCur = s.top();
s.pop();
//访问头节点的条件:无右孩子或者是右孩子已经被访问
if(pCur->rchild == NULL || pCur->rchild == pLastVisit){
visit(pCur);
pLastVisit = pCur;
}
else{
s.push(pCur);
pCur = pCur->rchild;
//找到右子树的最左边的节点
while(pCur){
s.push(pCur);
pCur = pCur->lchild;
}
}
}
}
//递归版
void xOrder(node* root){
if(root == NULL)return;
//'* = printf("%d\n",root->data);
*//前序遍历
xOrder(root->lchild);
*//中序遍历
xOrder(root->rchild);
*//后序遍历
}
//层次遍历:每次完成一个节点的遍历,就需要检查其是否为叶子节点,否则加入到队列中
void LayerOrder(node* root){
queue<node*>q;
q.push(root);
while(!q.empty()){
node* now = q.front();
q.pop();
printf("%d",now->data);
if(now->lchild != NULL)q.push(now->lchhild);
if(now->rchild != NULL)q.push(now->rchild);
}
}
//如果还想要直到当前节点所在的层数,可以在结构体中做好标记
struct node{
int data;
int layer;
node* lchild;
node* rchild;
};
void LayerOrder(node* root){
queue<node*>1;
root->layer = 1;
q.push(root);
while(!q.empty()){
node* now = q.front();
q.pop();
printf("%d",now->data);
//更新节点信息之后,再将节点入队
if(now->lchild != NULL){
now->lchild->layer = now->layer + 1;
q.push(now->lchild);
}
if(now->rchild != NULL){
now->rchild->layer = now->layer + 1;
q.push(now->rchild);
}
}
}
树的静态实现(非二叉树)
实现静态写法是为了避免指针可能带来的错误。主要的思想就是将树的孩子节点存储在一个向量(“变长数组”)中。
struct node{
typename data;
vector<node> child;//??
}Node[maxn];
//如果不需要数据域,可以用如下方法定义
vector<int>child[maxn];//这里定义了maxn个向量
树的遍历
//先序遍历:先访问节点,之后递归地遍历其孩子节点
void PreOrder(int root){
visit(root);
for(int i = 0; i < Node[root].child.size();++i){
PreOrder(Node[root].child[i]);
}
}
//层序遍历:先访问头节点,然后将孩子节点入队,直到队列为空
void LayerOrder(int root){
queue<int>Q;
Q.push (root);
while(!Q.empty()){
int front = Q.front();
Q.pop();
visit(Q);
//下面是访问该节点所有孩子节点的方法
for(int i = 0; i < Node[front].child.size();++i){
Q.push(Node[front].child[i]);
}
}
}
二叉查找树
二叉查找树是节点按照一定规律排列的树,根节点的数据域大于或者小于左右孩子节点的数据域。同时二叉查找树还可以是一个空树。
//二叉查找树的操作
//新建一个节点:申请空间,赋值初始化,返回节点地址
node* newNode(int v){
node* Node = new node;
Node->data = v;
Node->lchild = Node ->rchild = NULL;
return Node;
}
//查找二叉查找树中数据域为x的节点
void search (node* root, int x){
//递归出口
if(root == NULL){
printf("search failed\n");
return;
}
//根据当前节点值得情况,决定递归方向
if(x == root->data)printf("%d\n",root->data);
else if(x < root->data) search(root->lchild, x);
else search(root->rchild, x);
}
//插入一个数据域为x的新节点(注意这里的root是需要引用,后续修改)
void insert (node* &root, int x){
//当查找失败的时候,这个地方即为节点插入的位置
if(root == NULL){
root = newNode(x);
return;
}
//由数据域的情况决定递归的方向
if(x == root->data)return;
else if(x < root->data)insert(root->lchild, x);
else insert(root->rchild, x);
}
//二叉查找树的建立
node* Crate(int data[], int n){
node* root = NULL;
//将数组数据找到一个合适的地方插入
for(int i = 0; i < n; ++i)insert(root,data[i]);
return root;
}
//二叉查找树的删除
//可以用根节点的前去或者后继来代替被删除的头节点
//找到极值点的过程就是不断向左或者向右的过程,直到遇到空节点
//找到以root为头节点的最大全职的节点
node* findMax(node* root){
while(root->child != NULL)root = root -> rchild;
return root;
}
//找到权值最小的节点
node* findMin(node* root){
while(root->lchild != NULL)root = root->lchild;
return root;
}
//删除节点:想用前驱后者后继节点覆盖要删除的节点,然后问题就转换成删除前驱或后继节点
//先找到想要删除的节点,然后判断节点的类型,然后再进行相应的递归操作
//删除以root为根节点的权值为x的节点
void deleteNode(node* &root, int x){
if(root == NULL)return;
//找到需要删除的节点
if(root->data == x){
//当需要删除的节点为叶节点,直接删除
if(root->lchild == NULL && root->rchild == NULL)root = NULL;
//左孩子非空,则用右孩子的极值替换该节点,然后删除该极值节点
else if(root->lchild != NULL){
node* pre = findMax(root->lchild);
root->data = pre->data;
deleteNode(root->lchild,pre->data);
}
//右孩子非空,操作同上
else{
node* next = findMin(root->rchild);
root->data = next -> data;
deleteNode(root->rchild, next->data);
}
//寻找需要删除的节点
else if(root->data > x)deleteNode(root->lshild,x);
else deleteNode(root->rchild, x);
}
}
对于删除节点的操作,可以进行优化,主要里利用极值节点坑定没有左子树或右子树的性质,将该极值节点的子树直接连接到该极值节点的父节点上即可。
加入一直删除前驱或者后继,就会导致最后树变得十分不平衡,解决这个方法可以采取交替删除前驱后继或者是记录子树高度,优先在高度更高的的子树中删除节点。
平衡二叉树
平衡二叉树是左右子树高度相差不超过1的二叉树。这样的结构可以保证在大多数操作下保持O(logn)的性能。因为当二叉树严重失衡时,二叉树退化成链表,此时操作的时间复杂度变为O(n)。在平衡二叉树中,右子树与左子树的高度之差称为该节点的平衡因子。
//节点结构体
struct node{
int v, height;//节点权值和子树高度
node* lchild, *rchild;
};
//生成一个新的节点
node* newNode(int v){
node* Node = new node;//申请节点空间
Node->v = v;//节点权值
Node->height = 1;//该节点本身的高度
Node->lchild = Node->rchild = NULL;//初始化孩子节点
}
//获取当前树的高度:从结构体变量中获取
int getHeight(node* root){
if(root == NULL)return 0;
return root->height;
}
//计算平衡因子:左子树高度减去右子树高度
int getBalanceFactor(node* root){
return getHeight(root->lchild) - getHeight(root->rchild);
}
//更新当前节点的高度:孩子节点的最大高度加上节点本身
void updateHeight(node* root){
root->height = max(getHeight(root->lchild), getHeight(root->rchild)) + 1;
}
//ALV的查找操作与二叉排序树的操作完全一致
对于ALV的插入操作,要根据树的结构做出相应的不同的操作。(BF:Balance Factor)
| 树型 | 判定条件 | 调整方法 |
|---|---|---|
| LL | BF(root) = 2;BF(root->lchild) = 1 | 对root进行右旋 |
| LR | BF(root) = 2;BF(root->lchild) = -1 | 先对root->lchild进行左旋后对root进行右旋 |
| RR | BF(root) = -2;BF(root->lchild) = -1 | 对root进行左旋 |
| RL | BF(root) = -2;BF(root->lchild) = 1 | 先对右子树进行右旋,再对root左旋 |
通过表格,可以总结:L代表根节点是正数,R代表孩子节点的负数。
下图时LL和LR型的树的调整示意图


注意到LR型是将LR先左旋转换成LL型的二叉树然后再执行右旋的,所以LR型的二叉树的调整可以由基本的左旋右旋组合而来。
//左旋:将右孩子的左孩子连接到头节点处,其原先的左孩子连接到原先的头节点的右孩子处
void L(node*& root){
node* temp = root->rchild;
root->rchild = temp->lchild;
temp->lchild = root;
//跟新调整之后的节点高度
updateHeight(root);
uodateHeight(temp);
root = temp;
}
//右旋
void R(node*& root){
node* temp = root->lchild;
root->lchild = temp->rchild;
temp->rchild = root;
updateHeight(root);
uodateHeight(temp);
root = temp;
}
//插入节点:找到插入的位置,判断插入后树的类型,然后再做相应的操作
void insert (node*&root,int v){
if(root == NULL){
root = newNode(v);
return;
}
//节点小,则在左子树中插入
if(v < root->v){
insert(root->lchild,v);
//更新节点信息,
updateHeight(root);
//L
if(getBalanceFactor(root) == 2){
//LL
if(getBalanceFactor(root->lchild)==1) R(root);
//LR
else if(getBalanceFactor(root->lchild)==-1){
L(root->lchild);
R(root);
}
}
else{
//从右子树中插入节点
insert(root->rchild,v);
updateHeight(root);
//R
if(getBalanceFactor(root) == -2){
//RR
if(getBalanceFactor(root->rchild)==-1)L(root);
//RL
else if(getBalanceFactor(root->rchild) == 1){
R(root->rchild);
L(root);
}//else if
}//if
}//else
}
//AVL树的建立
node* Create(int data[], int n){
node* root = NULL;
for(int i = 0; i < n; ++i)insert(root,data[i]);
return root;
}
并查集
在计算机科学中,并查集(英文:Disjoint-set data structure,直译为不交集数据结构)是一种数据结构,用于处理一些不交集(Disjoint sets,一系列没有重复元素的集合)的合并及查询问题。并查集支持如下操作:
查询:查询某个元素属于哪个集合,通常是返回集合内的一个“代表元素”。这个操作是为了判断两个元素是否在同一个集合之中。
合并:将两个集合合并为一个。
添加:添加一个新集合,其中有一个新元素。添加操作不如查询和合并操作重要,常常被忽略。
以下是并查集得一些基本操作。
const int N = 10;
int father[N];
//初始化
void initialSet(int father[], int N) {
for (int i = 1; i <= N; ++i) {
father[i] = i;
}
}
//查找:根节点的父节点就是其本身
int findFather(int x) {
while (x != father[x]) {
x = father[x];
}
return x;
}
//递归版本
int findFatherRe(int x) {
//递归出口
if (x == father[x])return x;
else return findFather(father[x]);
}
//并查集合并:先判断两节点是否再同一并查集中(判断根节点是否相同),然后再将其中一个根节点的父节点指向另一个根节点
//这样能能够保证并查集是个树型结构,不会出现环
void Union(int a, int b) {
int faA = findFather(a);
int faB = findFather(b);
//当二者不是统一并查集时合并
if (faA != faB){
father[faA] = father[faB];
}
}
//路径压缩:将搜索的时间复杂度由O(n)变为O(1),其实就是将所有节点的父节点全部指向根节点
int findFatherPatheShorten(int x){
int a = x;//找到根节点,同时保存初始节点
//找到根节点
while (x != father[x]) {
x = father[x];
}
//将该节点的父节点指向根节点,并保存该节点原先的父节点的信息
while (a != father[a]) {
int z = a;
a = father[a];
father[z] = x;
}
return x;
}
//递归版本
int findFatherRSRec(int v) {
if (v == father[v])return v;
else{
int F = findFather(father[v]);
father[v] = F;
return F;
}
}
堆
堆本质上就是满足父节点大于(或小于)孩子节点的二叉树。所有节点存储在一个数组当中,这样i节点的孩子节点分别为 2 ∗ i 2*i 2∗i和 2 ∗ i + 1 2*i+1 2∗i+1。
const int maxn = 100;
int heap[maxn], n = 10;
void swap(int &a, int &b) {
int temp = a;
a = b;
b = temp;
}
//向下调整O(logn):从low到high。找出该节点得该子节点中最大得节点,然后于该节点进行比较,若孩子节点较大,则与孩子节点进行交换
void downAdjust(int low, int high) {
int i = low, j = i * 2;
while (j <= high) {
//找出孩子节点中较大的
if (j + 1 <= high && heap[j + 1] > heap[j]) ++j;
//与父节点进行比较
if (heap[j] > heap[i]) {
swap(heap[j], heap[i]);
i = j;
j = i * 2;//这里只去检查被调整的元素是否满足堆的条件,因为为改动的节点应该是满足堆的要求的
}
else{
break;
}
}
}
//建堆O(n):从最后一个非叶节点往后进行循环,这是对原先数组进行了排序,以满足堆的要求
void createHeap() {
for (int i = n / 2; i >= 1; --i)downAdjust(i, n);
}
//删除堆顶元素O(logn)
void deleteTop() {
//将最后一个元素代替堆顶元素,然后减少节点数量
heap[1] = heap[n--];
downAdjust(1, n);//改动了这个节点就从这个节点进行调整
}
//向上调整:当插入一个节点的时候,这个节点被放到最后,逐个与其父节点比较,直到该节点小于父节点
void upAdjust(int low, int high){
int i = high, j = i / 2;//high就是最后一个节点,即插入的节点
//父节点在范围之内
while (j >= low) {
if (heap[j] < heap[i]) {
swap(heap[j], heap[i]);
i = j;
j = i / 2;
}
else
{
break;
}
}
}
//添加元素,借用上面的函数:加入节点,然后进行相应的调整
void insert(int x) {
heap[++n] = x;
upAdjust(1, n);
}
//堆排序:将头节点与最后一个节点进行交换,然后对堆进行调整
void heapSort() {
createHeap();
for(int i = n; i > 1; i--){
swap(heap[i], heap[1]);
downAdjust(1, i - 1);
}
}
哈夫曼树
哈夫曼树构建过程
用语言描述就是,先将队列中权值最小的两个节点合并成新的节点,加入到队列中,然后一直按照这个规律执行,直到队列中只剩下一个节点。这个时候头节点的权值就是最短路径权值
//以下是求一个实例的最短路径的权值的算法
#include<cstdio>
#include<queue>
using namespace std;
priority_queue<long long, vector<long long>, greater<long long>> q;
int main() {
int n;
long long temp, x, y, ans = 0;
scanf("&d", &n);
for (int i = 0; i < n; ++i) {
scanf("%lld", &temp);
q.push(temp);
}
while (q.size()>1)
{
//获取前两个最大节点
x = q.top();
q.pop();
y = q.top();
q.pop();
//将节点合并之后再入队
q.push(x + y);
//统计最短路径权值
ans += x + y;
}
printf("%lld", ans);
return 0;
}
哈夫曼编码是一种用于无损数据压缩的熵编码(权编码)算法,它可以根据数据的一些特点(如出现频率)来制定相应长度的编码从而达到数据压缩的目的。














 974
974











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}