







文章目录
矩阵分解可以用于压缩矩阵,以尽可能少的空间存储一个矩阵,同时损失尽可能少的信息。同时对数据进行降维还可以减少发生 维度灾难的发生。
维数灾难: 当数据维度提升的时候,因为空间体积提升过快,因而可用数据变得很稀疏。然而在高维空间中,所有的数据都很稀疏,从很多角度看都不相似,因而平常使用的数据组织策略变得极其低效。
在机器学习问题中,需要在高维特征空间(每个特征都能够取一系列可能值)的有限数据样本中学习一种“自然状态”(可能是无穷分布),要求有相当数量的训练数据含有一些样本组合。给定固定数量的训练样本,其预测能力随着维度的增加而减小,这就是所谓的Hughes影响或Hughes现象(以Gordon F. Hughes命名)。
------Wiki
个人理解:随着维度的升高数据之间的距离加大,这导致数据组合而成的用于最终判断的特征难以被发现
行列式与迹(Determinant and Trace)
行列式(Dterminant)
行列式可以看成将一个方阵映射成一个实数。(只有方阵才有行列式)
可以将行列式用于判断一个方阵是否可逆:
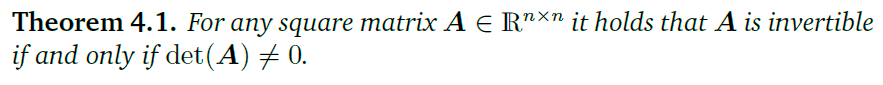
对于上/下三角矩阵的行列式的值为:
det
(
T
)
=
∏
i
=
1
n
T
i
i
\operatorname{det}(\boldsymbol{T})=\prod_{i=1}^{n} T_{i i}
det(T)=i=1∏nTii
对于n阶行列的计算,可以使用拉普拉斯展开(Laplace Expansion)


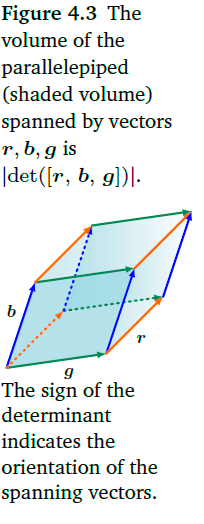
行列式的几何含义就是带有符号的多边形的体积,这个多边形是由行列式所对应的列向量通过平移之后组成的.注意到当至少其中的两个向量重合的时候,也就是这两个向量线性相关的时候,他们组成的几何体的体积为0,所以这时候他们组成的方阵的行列式为0.

行列式的一些性质:

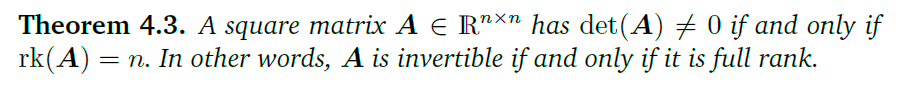
迹(Trace)
假设
f
(
x
)
=
∏
i
=
1
k
(
x
−
λ
i
)
d
i
f(x)=\prod^k_{i=1}(x-\lambda_i)^{d_i}
f(x)=∏i=1k(x−λi)di是矩阵A的特征多项式,那么A的迹为:
tr
(
A
)
=
∑
i
=
1
k
d
i
λ
i
\operatorname{tr}(\boldsymbol A)=\sum^k_{i=1}d_i\lambda_i
tr(A)=i=1∑kdiλi
对于一个方阵的迹就是它所有对角线元素的和:
t
r
(
A
)
:
=
∑
i
=
1
n
a
i
i
tr(\bold A):=\sum\limits_{i=1}^na_{ii}
tr(A):=i=1∑naii
迹的一些性质:

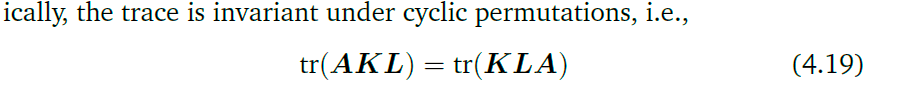
假设
B
、
A
\bold B、\bold A
B、A是向量空间U的两个基向量,所以一定存在一个向量
S
\bold S
S,使得
B
=
S
−
1
A
S
\bold B=\bold S^{-1}\bold A\bold S
B=S−1AS:
tr
(
B
)
=
tr
(
S
−
1
A
S
)
=
(
4.19
)
tr
(
A
S
S
−
1
)
=
tr
(
A
)
\operatorname{tr}(\boldsymbol{B})=\operatorname{tr}\left(\boldsymbol{S}^{-1} \boldsymbol{A} \boldsymbol{S}\right) \stackrel{(4.19)}{=} \operatorname{tr}\left(\boldsymbol{A} \boldsymbol{S} \boldsymbol{S}^{-1}\right)=\operatorname{tr}(\boldsymbol{A})
tr(B)=tr(S−1AS)=(4.19)tr(ASS−1)=tr(A)
特征多项式:

其中:
c
0
=
d
e
t
(
A
)
c
n
−
1
=
(
−
1
)
n
−
1
t
r
(
A
)
c_0=det(\bold A) \\ c_{n-1}=(-1)^{n-1}tr(\bold A)
c0=det(A)cn−1=(−1)n−1tr(A)
特征多项式可以用于求解特征值和特征向量。
特征值与特征向量
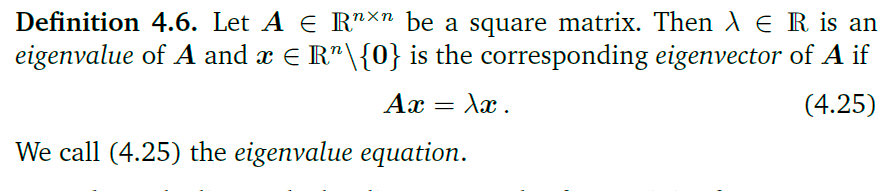

特征向量不是唯一的,与特征向量共线的所有向量都是这个矩阵的特征向量。
共线与共向:

特征值是矩阵特征多项式的一个根。
代数重度(algebraic multiplicity):该特征是特征向量的几重根。
特征空间:特征值对应的特征向量组成的向量空间就是特征空间

有疑问
特征向量所张成的空间就是特征向量通过线性映射之后得到的。而特征向量所对应的特征值的正负对应着特征向量的指向的方向

特征值的几个非常有用的性质:
1.矩阵和他的转置的特征值一样,但是特征向量不一定一样
2.观察特征方程
(
A
−
λ
I
)
x
=
0
(\bold A-\lambda\bold I)\bold x=\bold 0
(A−λI)x=0,这说明
(
A
−
λ
I
)
(\bold A-\lambda\bold I)
(A−λI)对应着核空间
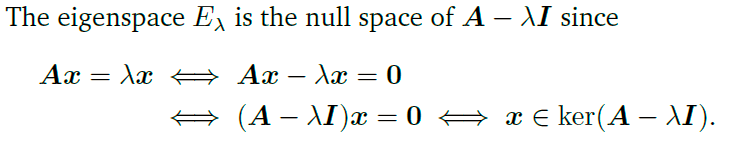
3.相似矩阵(
A
~
=
S
−
1
A
S
\widetilde A=S^{-1}AS
A
=S−1AS)的特征值保持一致,说明特征值是与基向量无关的(拥有这种性质的还有迹和行列式)
4.正定矩阵拥有正的实特征值。
几何重度(Geometric Multiplicity,特征空间的维度):
λ
\lambda
λ对应的线性无关的特征向量的个数。
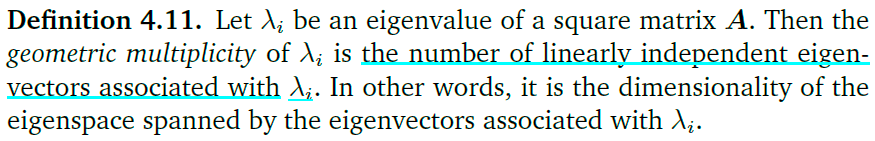
为什么?

二维空间中的几何直观理解:
对于特征方程(
A
x
=
λ
x
\bold A\bold x=\lambda\bold x
Ax=λx),等式右边是对向量x的一个变换(变换矩阵为A),右边为对x的一个伸展,二者相等,说明在经历过变换之后,x向量只是简单地发生了范数地增长,并没有离开原先地向量空间。而这个变换之后不离开原先向量空间的向量称为特征向量。特征向量组成的向量空间,称为特征空间,在特征空间中的所有向量经过变换之后也不会离开原先的张成空间。向量延展的倍数为变换矩阵的特征值

特征向量与特征值的求解过程:
由特征方程得到:
(
A
−
λ
I
)
v
=
0
(\bold A-\lambda I)\bold v=\bold 0
(A−λI)v=0当
v
⃗
\vec \bold v
v为零向量的时候,等式成立,但是我们想要一个非零向量,所以原来的式子的含义就变成,将一个向量压缩成一个零向量,这就是说在经过变换之后原先的向量发生了降维,这就是说
A
−
λ
I
\bold A-\lambda I
A−λI不是满秩的,就好像是一个三维体经过变换之后变成了二维,这时候变换之后的几何体的体积变成了0,也就是相对应的行列式变成了0,所以
∣
A
−
λ
I
∣
=
0
、
d
e
t
(
A
−
λ
I
)
=
0
|\bold A-\lambda I|=0、det(\bold A-\lambda I)=0
∣A−λI∣=0、det(A−λI)=0

下图是不同类型的线性映射时候特征值和行列式的情况:
其中
A
1
=
[
1
2
0
0
2
]
A
2
=
[
1
1
2
0
1
]
A
3
=
[
cos
(
π
6
)
−
sin
(
π
6
)
sin
(
π
6
)
cos
(
π
6
)
]
=
1
2
[
3
−
1
1
3
]
A
4
=
[
1
−
1
−
1
1
]
\bold A_1=\begin{bmatrix}\frac1 2\quad 0\\ 0 \quad 2\end{bmatrix}\\ \bold A_2=\begin{bmatrix}1 \quad\frac 12\\ 0 \quad 1\end{bmatrix}\\ \bold A_3=\begin{bmatrix}\cos(\frac\pi6)\quad -\sin(\frac\pi6)\\ \sin(\frac\pi6) \quad \cos(\frac\pi6)\end{bmatrix}=\frac12\begin{bmatrix} \sqrt 3\quad-1\\1\quad\sqrt 3\end{bmatrix}\\ \bold A_4=\begin{bmatrix}1\quad\quad -1\\ -1 \quad\quad 1\end{bmatrix}
A1=[21002]A2=[12101]A3=[cos(6π)−sin(6π)sin(6π)cos(6π)]=21[3−113]A4=[1−1−11]

为什么最后一个的行列式的值发生了变化?
每一个特征空间在变换中对应着唯一一个特征值(倍数),所以当倍数(特征值)全部都是不同的时候,说明有所有的特征向量都是线性无关的。
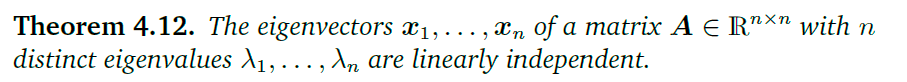
亏损矩阵
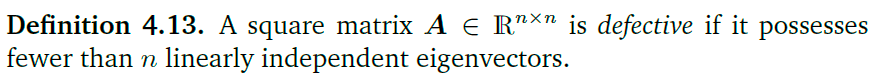
对于一个非亏损矩阵(
∈
R
n
×
n
\in \mathbb R^{n\times n}
∈Rn×n)不一定需要n个不同的特征值,但是一定需要n个特征向量组成
R
n
×
n
\mathbb R^{n\times n}
Rn×n的基。(注意到不同的向量在变换的时候延伸的倍数是可以一样的,所以会有一个特征值对应几个特征向量的情况)
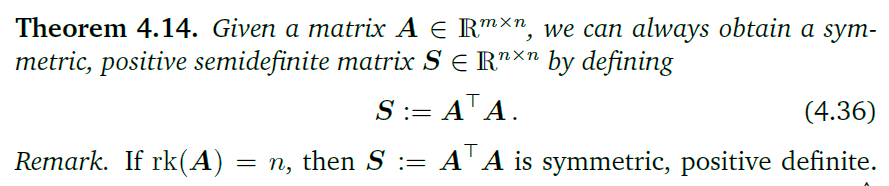
谱定律:

这说明一个对称矩阵可以进行特征分解,也就是说能够找到特征向量对应的规范正交基,使得
A
=
P
D
P
−
1
\bold A=\bold P\bold D\bold P^{-1}
A=PDP−1其中D为对角矩阵,P由特征向量组成。
行列式与迹的意义:分别与面积(体积)和周长相关


柯列斯基分解(Cholesky Decomposition)

计算方式:

这在深度学习中有很多的应用,同时还可以用于计算行列式(上下三角矩阵的行列式非常好计算)
特征分解和对角化
可对角化的条件:
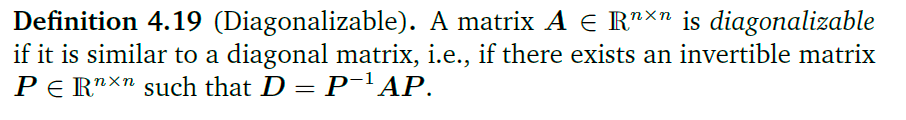

这需要P矩阵是满秩的
特征分解

这实际上就是A与D相似。P由A的特征向量组成,D由A的特征值组成(对角矩阵)
如何理解相似矩阵?
如何理解谱定理?
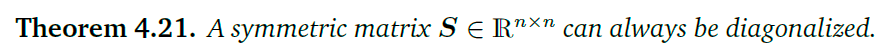

矩阵分解的几何直观理解

各部分对应的变换还是不是很清楚。
特征值分解可以这样理解,首先先进行一次基变换,将正交基变换至由特征向量组成的向量空间中,然后进行延展(这就是变换矩阵A对应在特征向量中的变换Ax= λ x \lambda x λx),最后将向量空间复原到原先的向量空间中。
对待方程
A
=
P
−
1
D
P
\bold A=\bold P^{-1}\bold D\bold P
A=P−1DP,可以这样想,单位矩阵经过A矩阵变换之后等价于
P
−
1
D
P
\bold P^{-1}\bold D\bold P
P−1DP三个矩阵变化之后的结果。
将一个矩阵分解之后,可以很方便地计算矩阵地行列式和n次方。
d
e
t
(
A
)
=
d
e
t
(
P
D
P
−
1
)
=
d
e
t
(
P
)
∗
d
e
t
(
D
)
∗
d
e
t
(
P
−
1
)
=
∏
i
d
i
i
det(\bold A)=det(\bold P\bold D\bold P^{-1})=det(\bold P)*det(\bold D)*det(\bold P^{-1})=\prod_id_{ii}
det(A)=det(PDP−1)=det(P)∗det(D)∗det(P−1)=i∏dii
奇异值分解(Singular Value Decomposition,SVD)
相对于特征值分解,奇异值分解使用范围更广,它不要求分解的矩阵是方阵。

u
i
\mathbb u_i
ui称为左奇异向量;
v
j
\mathbb v_j
vj称为右奇异向量。
Σ
\Sigma
Σ矩阵起到拓展维度的作用,所以:

SVD的几何直观解释

奇异值分解其实和特征值分解类似,只是在延伸的时候加了一些东西,这是因为矩阵为非方阵的时候,这样的变换会使向量发生维度的变化,所以 Σ \Sigma Σ矩阵在不是方阵的情况下,不仅仅使向量进行相对应的变换,还将维度进行了提升。
V T V^T VT起到旋转的作用, Σ \Sigma Σ起到拓展上域(codomain,到达域)维度的作用,最后U帮助向量升维。
上域

一个变换实例:


求解矩阵的SVD
对于一个对称正定矩阵(SPD矩阵)有:
S
=
S
T
=
P
D
P
T
S=S^T=PDP^{T}
S=ST=PDPT

所以一个SDP矩阵的SVD就是它的特征值分解。
计算一个矩阵 A ∈ R m × n \bold A\in \mathbb R^{m\times n} A∈Rm×n,等价于求解上域(codomain) R m \mathbb R^m Rm和定义域(domain) R n \mathbb R^n Rn的规范正交基
What’s the graphic intuitions?And why?
求解右奇异向量
由谱定理得知,对称矩阵的特征向量组成规范正交基,也就是说对称矩阵能够相似对角化。而我们可以通过 A A T AA^T AAT的方式得到一个半正定的对称矩阵。
A
⊤
A
=
P
D
P
⊤
=
P
[
λ
1
⋯
0
⋮
⋱
⋮
0
⋯
λ
n
]
P
⊤
\boldsymbol{A}^{\top} \boldsymbol{A}=\boldsymbol{P} \boldsymbol{D} \boldsymbol{P}^{\top}=\boldsymbol{P}\left[\begin{array}{ccc}\lambda_{1} & \cdots & 0 \\ \vdots & \ddots & \vdots \\ 0 & \cdots & \lambda_{n}\end{array}\right] \boldsymbol{P}^{\top}
A⊤A=PDP⊤=P⎣⎢⎡λ1⋮0⋯⋱⋯0⋮λn⎦⎥⎤P⊤
将SVD带入:
A
⊤
A
=
(
U
Σ
V
⊤
)
⊤
(
U
Σ
V
⊤
)
=
V
Σ
⊤
U
⊤
U
Σ
V
⊤
\boldsymbol{A}^{\top} \boldsymbol{A}=\left(\boldsymbol{U} \boldsymbol{\Sigma} \boldsymbol{V}^{\top}\right)^{\top}\left(\boldsymbol{U} \boldsymbol{\Sigma} \boldsymbol{V}^{\top}\right)=\boldsymbol{V} \boldsymbol{\Sigma}^{\top} \boldsymbol{U}^{\top} \boldsymbol{U} \boldsymbol{\Sigma} \boldsymbol{V}^{\top}
A⊤A=(UΣV⊤)⊤(UΣV⊤)=VΣ⊤U⊤UΣV⊤
由于
U
\boldsymbol U
U是正交矩阵,所以
U
U
⊤
=
I
\boldsymbol U\boldsymbol U^\top=\boldsymbol I
UU⊤=I:
A
⊤
A
=
V
Σ
⊤
Σ
V
⊤
=
V
[
σ
1
2
0
0
0
⋱
0
0
0
σ
n
2
]
V
⊤
\boldsymbol{A}^{\top} \boldsymbol{A}=\boldsymbol{V} \boldsymbol{\Sigma}^{\top} \boldsymbol{\Sigma} \boldsymbol{V}^{\top}=\boldsymbol{V}\left[\begin{array}{ccc}\sigma_{1}^{2} & 0 & 0 \\ 0 & \ddots & 0 \\ 0 & 0 & \sigma_{n}^{2}\end{array}\right] \boldsymbol{V}^{\top}
A⊤A=VΣ⊤ΣV⊤=V⎣⎡σ12000⋱000σn2⎦⎤V⊤
由此可以得出,A的SVD的奇异值就是
A
A
⊤
AA^\top
AA⊤的特征值的开根号的结果。其特征矩阵就是右奇异矩阵。
对于左奇异矩阵采取相似的方式:
A
A
⊤
=
(
U
Σ
V
⊤
)
(
U
Σ
V
⊤
)
⊤
=
U
Σ
V
⊤
V
Σ
⊤
U
⊤
=
U
[
σ
1
2
0
0
0
⋱
0
0
0
σ
m
2
]
U
⊤
.
\begin{aligned} \boldsymbol{A} \boldsymbol{A}^{\top} &=\left(\boldsymbol{U} \boldsymbol{\Sigma} \boldsymbol{V}^{\top}\right)\left(\boldsymbol{U} \boldsymbol{\Sigma} \boldsymbol{V}^{\top}\right)^{\top}=\boldsymbol{U} \boldsymbol{\Sigma} \boldsymbol{V}^{\top} \boldsymbol{V} \boldsymbol{\Sigma}^{\top} \boldsymbol{U}^{\top}\\ &=\boldsymbol{U}\left[\begin{array}{ccc} \sigma_{1}^{2} & 0 & 0 \\ 0 & \ddots & 0 \\ 0 & 0 & \sigma_{m}^{2} \end{array}\right] \boldsymbol{U}^{\top} . \end{aligned}
AA⊤=(UΣV⊤)(UΣV⊤)⊤=UΣV⊤VΣ⊤U⊤=U⎣⎡σ12000⋱000σm2⎦⎤U⊤.
现在将左右奇异矩阵联系起来:
由于
U
\boldsymbol U
U中的向量
v
i
\mathcal v_i
vi在经过A矩阵变换之后仍旧是正交向量,因为,
(
A
v
i
)
⊤
(
A
v
j
)
=
v
i
⊤
(
A
⊤
A
)
v
j
=
v
i
⊤
(
λ
j
v
j
)
=
λ
j
v
i
⊤
v
j
=
0
,
i
≠
j
\left(\boldsymbol{A} \boldsymbol{v}_{i}\right)^{\top}\left(\boldsymbol{A} \boldsymbol{v}_{j}\right)=\boldsymbol{v}_{i}^{\top}\left(\boldsymbol{A}^{\top} \boldsymbol{A}\right) \boldsymbol{v}_{j}=\boldsymbol{v}_{i}^{\top}\left(\lambda_{j} \boldsymbol{v}_{j}\right)=\lambda_{j} \boldsymbol{v}_{i}^{\top} \boldsymbol{v}_{j}=0,\quad i\ne j
(Avi)⊤(Avj)=vi⊤(A⊤A)vj=vi⊤(λjvj)=λjvi⊤vj=0,i=j
单位化右奇异向量的像域:
u
i
:
=
A
v
i
∥
A
v
i
∥
=
1
λ
i
A
v
i
=
1
σ
i
A
v
i
\boldsymbol{u}_{i}:=\frac{\boldsymbol{A} \boldsymbol{v}_{i}}{\left\|\boldsymbol{A} \boldsymbol{v}_{i}\right\|}=\frac{1}{\sqrt{\lambda_{i}}} \boldsymbol{A} \boldsymbol{v}_{i}=\frac{1}{\sigma_{i}} \boldsymbol{A} \boldsymbol{v}_{i}
ui:=∥Avi∥Avi=λi1Avi=σi1Avi
二者的关系?
由上得到奇异方程:
A
v
i
=
σ
i
u
i
,
i
=
1
,
…
,
r
\boldsymbol A\boldsymbol v_i=\sigma_i\boldsymbol u_i,\quad i=1,\dots,r
Avi=σiui,i=1,…,r
于是有:
A
V
=
Σ
U
\boldsymbol A\boldsymbol V=\Sigma\boldsymbol U
AV=ΣU
移项得:
A
=
U
Σ
V
⊤
\boldsymbol A=\boldsymbol U\Sigma\boldsymbol V^\top
A=UΣV⊤
这就是矩阵A的SVD。
矩阵逼近(Matrix Approximation)
外积:
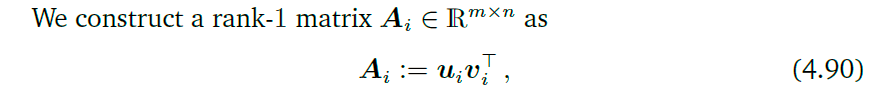
与内积不同,当两个向量相乘的时候,外积得到的是一个矩阵。有之前的SVD分解式,可以得到下式:
A
=
∑
i
=
1
r
σ
i
u
i
v
i
⊤
=
∑
i
=
1
r
σ
i
A
i
\boldsymbol{A}=\sum_{i=1}^{r} \sigma_{i} \boldsymbol{u}_{i} \boldsymbol{v}_{i}^{\top}=\sum_{i=1}^{r} \sigma_{i} \boldsymbol{A}_{i}
A=i=1∑rσiuivi⊤=i=1∑rσiAi
但是加入我们不讲所有的外积都加上的话,得到一个秩为 k ( k < r ) k(k<r) k(k<r)的矩阵,这个称为k秩逼近(rank-k approximation)
A ^ ( k ) : = ∑ i = 1 k σ i u i v i ⊤ = ∑ i = 1 k σ i A i \widehat{\boldsymbol{A}}(k):=\sum_{i=1}^{k} \sigma_{i} \boldsymbol{u}_{i} \boldsymbol{v}_{i}^{\top}=\sum_{i=1}^{k} \sigma_{i} \boldsymbol{A}_{i} A (k):=i=1∑kσiuivi⊤=i=1∑kσiAi
谱模(spectral norm)
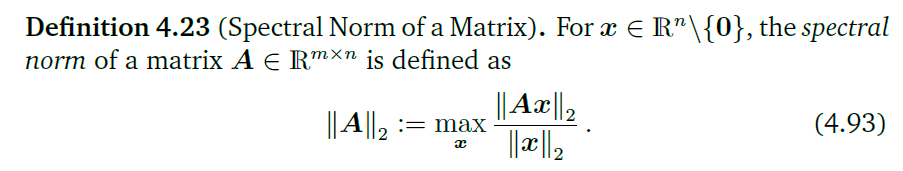
谱模表示,一个向量在经历矩阵A的变换之后最长可以变成多长(下标2代表的是欧几里得空间)。可以证明,矩阵A的谱模就是它的最大的奇异值
埃卡特-杨定理

这个定理量化了矩阵近似会造成的误差。
证明过程?
总结
















 1643
1643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









