







 本文深入探讨了高斯混合模型(GMMs)的原理和参数学习,通过极大似然估计利用期望最大化(EM)算法进行参数更新。介绍了责任(responsibilities)的概念,并详细阐述了如何更新均值、协方差和混合权重。实例展示了GMM在数据拟合过程中的迭代变化,揭示了EM算法如何逐步优化模型以适应数据。
本文深入探讨了高斯混合模型(GMMs)的原理和参数学习,通过极大似然估计利用期望最大化(EM)算法进行参数更新。介绍了责任(responsibilities)的概念,并详细阐述了如何更新均值、协方差和混合权重。实例展示了GMM在数据拟合过程中的迭代变化,揭示了EM算法如何逐步优化模型以适应数据。
文章目录
在本章节中,我们会介绍关于密度估计的几个主要的概念,例如: 期望最大化算法(expectation maximization (EM) algorithm)。
当我们使用数据进行模型训练的时候,我们需要将数据按照一些方法表示出来,最常见的方法就是将数据点本身代表数据,如下图:
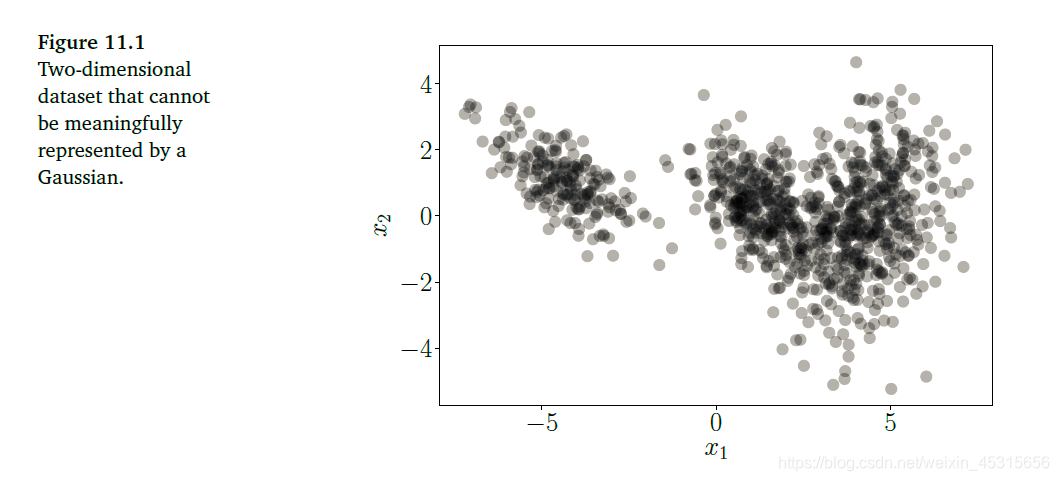
但是当数据集很大的时候,这种方法就不是很有效了(在上图这种多模型数据中的表现也不好)。在密度估计中,我们使用参数族(例如高斯分布、贝塔分布等)中的密度来表示数据。例如,我们可以找到数据集的均值和方差,然后利用高斯模型表示这些数据,我们可以认为数据集就是从这些模型中抽样出来的。
但是 ,在实践过程中,这些模型有时候不能很好地表示这些数据,也就是说这些模型的具有 有限的建模能力(have limited modeling capabilities)。所以,我们介绍一种更通用的数据模型: 混合模型(mixture model)。
混合模型可以将一个概率分布用K种不同的基本分布的 凸组合(convex combination)表示:
p ( x ) = ∑ k = 1 K π k p k ( x ) 0 ≤ π k ≤ 1 , ∑ k = 1 K π k = 1 p(x)=\sum^K_{k=1}\pi_k p_k(x)\\ 0\le \pi_k\le 1,\quad \sum^K_{k=1}\pi_k=1 p(x)=k=1∑Kπkpk(x)0≤πk≤1,k=1∑Kπk=1
其中, p k p_k pk为基本分布(高斯分布,贝塔分布等), π k \pi_k πk为 混合权重(mixture weight),混合权重能够保证混合模型的概率密度分布的总积分仍旧是1。通过将基本模型进行混合,混合模型能够很好地表示一些多模型数据(如上图中数据)。
在本章中,主要讨论 高斯混合模型(Gaussian mixture models (GMMs))。我们的目标是通过最大化模型参数的似然来训练GMMs。这里我们不会项之前那样找到一个闭型(closed-form,解析解)的极大似然估计的解,而是找到一组相互独立的联立方程(dependent simultaneous equation),解这些方程只能通过迭代的方式。
高斯混合模型(Gaussian Mixture Model)
高斯混合模型是一个密度模型,在这个模型中,我们将K个高斯分布组合起来,即
N
(
x
∣
μ
k
,
Σ
k
)
\mathcal N(x|\mu_k,\Sigma_k)
N(x∣μk,Σk):
p
(
x
∣
θ
)
=
∑
k
=
1
K
π
k
N
(
x
∣
μ
k
.
Σ
k
)
0
≤
π
k
≤
1
,
∑
k
=
1
K
π
k
=
1
p(x|\theta)= \sum^K_{k=1}\pi_k\mathcal N(x|\mu_k.\Sigma_k)\\0\le \pi_k\le1,\sum^K_{k=1}\pi_k=1
p(x∣θ)=k=1∑KπkN(x∣μk.Σk)0≤πk≤1,k=1∑Kπk=1
其中,
θ
:
=
{
μ
k
.
Σ
k
,
π
k
:
k
=
1
,
⋯
,
K
}
\theta := \{\mu_k.\Sigma_k,\pi_k:k = 1,\cdots,K\}
θ:={μk.Σk,πk:k=1,⋯,K}为模型参数的整合参数。这个混合模型能够在数据处理的时候提供更高的灵活度。下图是一个高斯混合模型的曲线图:
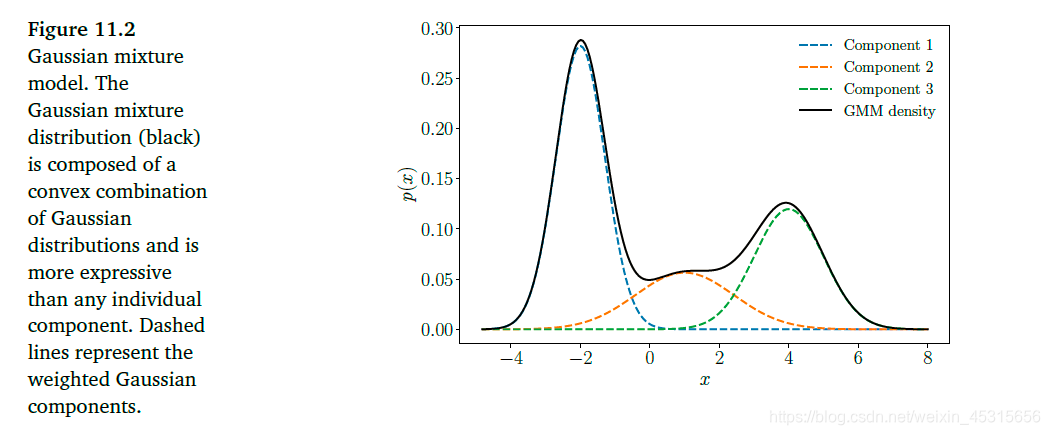
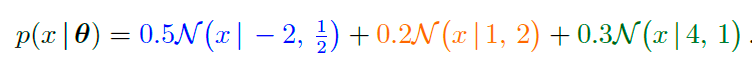
利用极大似然估计进行参数学习(Parameter Learning via Maximum Likelihood)
假设有一个从未知分布
p
(
x
)
p(x)
p(x)中抽样得到的独立同分布的数据集
X
=
{
x
1
,
⋯
,
x
N
}
\mathcal X=\{x_1,\cdots,x_N\}
X={x1,⋯,xN},我们的目标是找到能够更好地表示这个未知分布的GMM的参数
θ
\theta
θ。这里我们使用极大似然估计求解参数,由于数据都是独立同分布的,所以我们可以对似然函数进行分解:
p
(
X
∣
θ
)
=
∏
n
=
1
N
p
(
x
n
∣
θ
)
,
p
(
x
n
∣
θ
)
=
∑
k
=
1
K
π
k
N
(
x
n
∣
μ
k
,
Σ
k
)
p(\mathcal X|\theta)=\prod^N_{n=1}p(x_n|\theta),\quad p(x_n|\theta)=\sum^K_{k=1}\pi_k\mathcal N(x_n|\mu_k,\Sigma_k)
p(X∣θ)=n=1∏Np(xn∣θ),p(xn∣θ)=k=1∑KπkN(xn∣μk,Σk)
其中的每一个
p
(
x
n
∣
θ
)
p(x_n|\theta)
p(xn∣θ)都是一个高斯混合密度,所以对应的自然对数似然为:
log
p
(
X
∣
θ
)
=
∑
n
=
1
N
log
p
(
x
n
∣
θ
)
=
∑
n
=
1
N
log
∑
k
=
1
K
π
k
N
(
x
n
∣
μ
k
,
Σ
k
)
⏟
=
:
L
\log p(\mathcal X|\theta)=\sum^N_{n=1}\log p(x_n|\theta)=\underbrace{\sum^N_{n=1}\log \sum^K_{k=1}\pi_k \mathcal N(x_n|\mu_k,\Sigma_k)}_{=: \mathcal L}
logp(X∣θ)=n=1∑Nlogp(xn∣θ)==:L
n=1∑Nlogk=1∑KπkN(xn∣μk,Σk)
我们的目标就是找到能够最小化这个自然对数似然的模型参数,我们原先讨论极大似然估计的解的时候,是将这个似然函数对参数球偏导,然后将这个偏导设为0,求解出参数的值。但是在这里我们不能求出一个闭型的解。
不能求出闭型的解的原因?
原先我们讨论的是单个高斯分布,所以对应的自然对数概率分布为:
log N ( x ∣ μ , Σ ) = − D 2 log ( 2 π ) − 1 2 log det ( Σ ) − 1 2 ( x − μ ) ⊤ Σ − 1 ( x − μ ) \log \mathcal N(x|\mu,\Sigma)=-\frac D2\log (2\pi)-\frac 12\log\det(\Sigma)-\frac 12(x-\mu)^\top \Sigma^{-1}(x-\mu) logN(x∣μ,Σ)=−2Dlog(2π)−21logdet(Σ)−21(x−μ)⊤Σ−1(x−μ)
这个简单的形式能够让我们找到闭型的解,但是对于混合函数,其中的log后面的K次求和没有办法拆开,所以也就很难找到闭型的解了。
所以我们使用迭代的方式找到模型的最佳参数
θ
M
L
\theta_{ML}
θML,这个方法就是期望最大化算法(expectation maximization (EM) algorithm),EM的关键思想就是更新其中一个参数,而保持其他参数固定。
由于函数的局部最优解出的梯度都是0,所以可以将
L
\mathcal L
L对参数分别进行求偏导,然后将这些偏导设为0,这是最优化自然对数似然的必要条件:
∂
L
∂
μ
k
=
0
⊤
⟺
∑
n
=
1
N
∂
log
p
(
x
n
∣
θ
)
∂
μ
k
=
0
⊤
,
∂
L
∂
Σ
k
=
0
⟺
∑
n
=
1
N
∂
log
p
(
x
n
∣
θ
)
∂
Σ
k
=
0
∂
L
∂
π
k
=
0
⟺
∑
n
=
1
N
∂
log
p
(
x
n
∣
θ
)
∂
π
k
=
0
\begin{aligned} &\frac{\partial \mathcal{L}}{\partial \boldsymbol{\mu}_{k}}=\mathbf{0}^{\top} \Longleftrightarrow \sum_{n=1}^{N} \frac{\partial \log p\left(\boldsymbol{x}_{n} \mid \boldsymbol{\theta}\right)}{\partial \boldsymbol{\mu}_{k}}=\mathbf{0}^{\top}, \\ &\frac{\partial \mathcal{L}}{\partial \boldsymbol{\Sigma}_{k}}=\mathbf{0} \Longleftrightarrow \sum_{n=1}^{N} \frac{\partial \log p\left(\boldsymbol{x}_{n} \mid \boldsymbol{\theta}\right)}{\partial \boldsymbol{\Sigma}_{k}}=\mathbf{0} \\ &\frac{\partial \mathcal{L}}{\partial \pi_{k}}=0 \Longleftrightarrow \sum_{n=1}^{N} \frac{\partial \log p\left(\boldsymbol{x}_{n} \mid \boldsymbol{\theta}\right)}{\partial \pi_{k}}=0 \end{aligned}
∂μk∂L=0⊤⟺n=1∑N∂μk∂logp(xn∣θ)=0⊤,∂Σk∂L=0⟺n=1∑N∂Σk∂logp(xn∣θ)=0∂πk∂L=0⟺n=1∑N∂πk∂logp(xn∣θ)=0
由于
L
\mathcal L
L是一个复合函数,所以可以使用链式法则进行求偏导:
∂
log
p
(
x
n
∣
θ
)
∂
θ
=
1
p
(
x
n
∣
θ
)
∂
p
(
x
n
∣
θ
)
∂
θ
\frac{\partial\log p(x_n|\theta)}{\partial \theta}= \frac {1}{p(x_n|\theta)}\frac{\partial p(x_n|\theta)}{\partial \theta}
∂θ∂logp(xn∣θ)=p(xn∣θ)1∂θ∂p(xn∣θ)
其中:
p
(
x
n
∣
θ
)
=
∑
k
=
1
K
π
k
N
(
x
n
∣
μ
k
,
Σ
k
)
p(x_n|\theta)=\sum^K_{k=1}\pi_k\mathcal N(x_n|\mu_k,\Sigma_k)
p(xn∣θ)=∑k=1KπkN(xn∣μk,Σk);
θ
:
=
{
μ
k
.
Σ
k
,
π
k
:
k
=
1
,
⋯
,
K
}
\theta := \{\mu_k.\Sigma_k,\pi_k:k = 1,\cdots,K\}
θ:={μk.Σk,πk:k=1,⋯,K}.接下来主要介绍求解上述的几个等式。但是在求解之前我们介绍一个很重要的概念:责任(responsibilities)
责任(Responsibilities)
我们将第k个混合成分对第n个数据点的责任定义为:
r
n
k
:
=
π
k
N
(
x
n
∣
μ
k
,
Σ
k
)
∑
j
=
1
K
π
j
N
(
x
n
∣
μ
j
,
Σ
j
)
r_{nk}:=\frac{\pi_k\mathcal N(x_n|\mu_k,\Sigma_k)}{\sum^K_{j=1}\pi_j\mathcal N(x_n|\mu_j,\Sigma_j)}
rnk:=∑j=1KπjN(xn∣μj,Σj)πkN(xn∣μk,Σk)
这个第k个混合成分(Mixture Component)对数据点
x
n
x_n
xn的责任
r
n
k
r_{nk}
rnk与下面的似然函数呈比例:
p
(
x
n
∣
π
k
,
μ
k
,
Σ
k
)
=
π
k
N
(
x
n
∣
μ
k
,
Σ
k
)
p(x_n|\pi_k,\mu_k,\Sigma_k)= \pi_k\mathcal N(x_n|\mu_k,\Sigma_k)
p(xn∣πk,μk,Σk)=πkN(xn∣μk,Σk)
如果一个数据点与其中的混合成分越匹配(模型对应的部分能够很好地表示数据),那么相对应的责任也就越大。一个数据点的责任可以使用一个规范化的概率向量表示:
r
n
:
=
[
r
n
1
,
⋯
,
r
n
K
]
⊤
∈
R
K
,
∑
k
r
n
k
=
1
,
r
n
k
≥
0
r_n:=[r_{n1,\cdots,r_{nK}}]^\top\in \mathbb R^K, \sum_kr_{nk}=1,r_{nk}\ge0
rn:=[rn1,⋯,rnK]⊤∈RK,∑krnk=1,rnk≥0。(?
r
n
r_n
rn满足Boltzmann/Gibbs分布)
可以将责任理解为数据点在各个混合成分中,所占有的比例,也就是各混合成分得到这个数据点的概率(一个不是很准确的理解就是,这个数据在各个混合成分之间的分量).
接下来确定模型参数的时候,都需要依赖于这个责任,我们先改变一个参数,而保持其他的参数不变,然后计算对应的责任,之后不断将这两个步骤进行迭代,知道得到一个局部最优解。其实,正是二者与责任的高度相关性,使得最终的解没有一个闭型的解。
更新均值(Updating the Means)
定理:(GMM均值的更新)GMM的均值参数
μ
k
,
k
=
1
,
⋯
,
K
\mu_k,k=1,\cdots,K
μk,k=1,⋯,K为:
μ
k
n
e
w
=
∑
n
=
1
N
r
n
k
x
n
∑
n
=
1
N
r
n
k
\mu^{new}_{k}=\frac{\sum^N_{n=1}r_{nk}x_n}{\sum^N_{n=1}r_{nk}}
μknew=∑n=1Nrnk∑n=1Nrnkxn
由于更新一个混合模型的参数需要所有混合模型的均值、协方差矩阵和混合权重,所以我们不能一次性为所有的
μ
k
\mu_k
μk找到闭型的解。(我们需要同步更新?像梯度下降法那样?)
证明:这里对定理进行简单的证明,但是不做详细说明
结合之前的结论,我们求解似然函数对均值的偏导:
∂
p
(
x
n
∣
θ
)
∂
μ
k
=
∑
j
=
1
K
π
j
∂
N
(
x
n
∣
μ
j
,
Σ
j
)
∂
μ
k
=
π
k
∂
N
(
x
n
∣
μ
k
,
Σ
k
)
∂
μ
k
=
π
k
(
x
n
−
μ
k
)
⊤
Σ
k
−
1
N
(
x
n
∣
μ
k
,
Σ
k
)
\begin{aligned} \frac{\partial p\left(\boldsymbol{x}_{n} \mid \boldsymbol{\theta}\right)}{\partial \boldsymbol{\mu}_{k}} &=\sum_{j=1}^{K} \pi_{j} \frac{\partial \mathcal{N}\left(\boldsymbol{x}_{n} \mid \boldsymbol{\mu}_{j}, \boldsymbol{\Sigma}_{j}\right)}{\partial \boldsymbol{\mu}_{k}}=\pi_{k} \frac{\partial \mathcal{N}\left(\boldsymbol{x}_{n} \mid \boldsymbol{\mu}_{k}, \boldsymbol{\Sigma}_{k}\right)}{\partial \boldsymbol{\mu}_{k}} \\ &=\pi_{k}\left(\boldsymbol{x}_{n}-\boldsymbol{\mu}_{k}\right)^{\top} \boldsymbol{\Sigma}_{k}^{-1} \mathcal{N}\left(\boldsymbol{x}_{n} \mid \boldsymbol{\mu}_{k}, \boldsymbol{\Sigma}_{k}\right) \end{aligned}
∂μk∂p(xn∣θ)=j=1∑Kπj∂μk∂N(xn∣μj,Σj)=πk∂μk∂N(xn∣μk,Σk)=πk(xn−μk)⊤Σk−1N(xn∣μk,Σk)
将上述的似然函数带入到对代价函数的偏导中:
∂
L
∂
μ
k
=
∑
n
=
1
N
∂
log
p
(
x
n
∣
θ
)
∂
μ
k
=
∑
n
=
1
N
1
p
(
x
n
∣
θ
)
∂
p
(
x
n
∣
θ
)
∂
μ
k
=
∑
n
=
1
N
(
x
n
−
μ
k
)
⊤
Σ
k
−
1
π
k
N
(
x
n
∣
μ
k
,
Σ
k
)
∑
j
=
1
K
π
j
N
(
x
n
∣
μ
j
,
Σ
j
)
⏟
=
r
n
k
=
∑
n
=
1
N
r
n
k
(
x
n
−
μ
k
)
⊤
Σ
k
−
1
\begin{aligned} \frac{\partial \mathcal{L}}{\partial \boldsymbol{\mu}_{k}} &=\sum_{n=1}^{N} \frac{\partial \log p\left(\boldsymbol{x}_{n} \mid \boldsymbol{\theta}\right)}{\partial \boldsymbol{\mu}_{k}}=\sum_{n=1}^{N} \frac{1}{p\left(x_{n} \mid \theta\right)} \frac{\partial p\left(\boldsymbol{x}_{n} \mid \boldsymbol{\theta}\right)}{\partial \boldsymbol{\mu}_{k}} \\ &=\sum_{n=1}^{N}\left(\boldsymbol{x}_{n}-\boldsymbol{\mu}_{k}\right)^{\top} \boldsymbol{\Sigma}_{k}^{-1}\underbrace{\frac{\pi_{k} \mathcal{N}\left(\boldsymbol{x}_{n} \mid \boldsymbol{\mu}_{k}, \boldsymbol{\Sigma}_{k}\right)}{\sum_{j=1}^{K} \pi_{j} \mathcal{N}\left(x_{n} \mid \mu_{j}, \Sigma_{j}\right)}}_{=r_{nk}} = \sum^N _{n=1} r_{n k}\left(\boldsymbol{x}_{n}-\boldsymbol{\mu}_{k}\right)^{\top} \boldsymbol{\Sigma}_{k}^{-1} \end{aligned}
∂μk∂L=n=1∑N∂μk∂logp(xn∣θ)=n=1∑Np(xn∣θ)1∂μk∂p(xn∣θ)=n=1∑N(xn−μk)⊤Σk−1=rnk
∑j=1KπjN(xn∣μj,Σj)πkN(xn∣μk,Σk)=n=1∑Nrnk(xn−μk)⊤Σk−1
为了求解
μ
k
n
e
w
\mu^{new}_{k}
μknew,需要求解
∂
L
(
μ
n
e
w
k
)
∂
μ
k
=
0
⊤
\frac{\partial \mathcal L(\mu^{new_k})}{\partial \mu_k}=0^\top
∂μk∂L(μnewk)=0⊤:
∑
n
=
1
N
r
n
k
x
n
=
∑
n
=
1
N
r
n
k
μ
k
n
e
w
⇔
μ
k
n
e
w
=
1
N
k
∑
n
=
1
N
r
n
k
x
n
\sum^N_{n=1}r_{nk}x_n=\sum^N_{n=1}r_{nk}\mu_k^{new}\Leftrightarrow \mu^{new}_k=\frac{1}{N_k}\sum^N_{n=1}r_{nk}x_n
n=1∑Nrnkxn=n=1∑Nrnkμknew⇔μknew=Nk1n=1∑Nrnkxn
我们定义第k个混合元素对数据集的总贡献为:
N
k
:
=
∑
n
=
1
N
r
n
k
N_k:=\sum^N_{n=1}r_{nk}
Nk:=n=1∑Nrnk
得证。
这个均值更新的过程还可以使用重要性加权的蒙特卡罗估计(importance-weighted Monte Carlo estimate)理解。数据点
x
n
x_n
xn的重要性权值就是所有混合成份对数据点的责任(存疑where the importance weights of data point
x
n
x_n
xn are the responsibilities
r
n
k
r_{nk}
rnk of the kth cluster for
x
n
,
k
=
1
,
⋯
K
x_n, k = 1, \cdots K
xn,k=1,⋯K.)。
可以将均值的更新过程想象成均值点被各个数据点拉着移动,而每个数据点对均值点的力的大小就是责任,如下图:
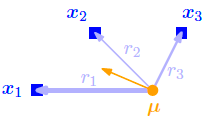
也可以将更新过程理解为在下式分布中的所有的数据点的期望值:
r
k
:
=
[
r
1
k
,
⋯
,
r
N
k
]
⊤
/
N
k
r_k:=[r_{1k},\cdots,r_{Nk}]^\top/N_k
rk:=[r1k,⋯,rNk]⊤/Nk
这也是一个规范化的概率向量:
μ
k
←
E
r
k
[
X
]
\mu_k\leftarrow \mathbb E_{rk}[\mathcal X]
μk←Erk[X]
更新协方差(Updating the Covariances)
定理(更新GMM的协方差)更新协方差参数:
Σ
k
n
e
w
=
1
N
k
∑
n
=
1
N
r
n
k
(
x
n
−
μ
k
)
(
x
n
−
μ
k
)
⊤
\Sigma^{new}_k=\frac1N_k\sum^N_{n=1}r_{nk}(x_n-\mu_k)(x_n-\mu_k)^\top
Σknew=N1kn=1∑Nrnk(xn−μk)(xn−μk)⊤
证明过程(原书p356)比较麻烦,这里略过.
与更新均值相似,更新协方差可以理解为是中心化数据
X
~
k
:
=
{
x
1
−
μ
k
,
⋯
.
x
N
−
μ
k
}
\tilde \mathcal X_k:=\{x_1-\mu_k,\cdots.x_N-\mu_k\}
X~k:={x1−μk,⋯.xN−μk}的平方的重要性加权期望值。
更新混合权重(Updating the Mixture Weights)
定理:
π
k
n
e
w
=
N
k
N
,
k
=
1
,
⋯
,
K
\pi^{new}_k=\frac{N_k}{N},\quad k=1,\cdots,K
πknew=NNk,k=1,⋯,K
其中,N是数据点的个数。
证明:
略(原书p358)
关于权重的更新即为第k个混合成分全部责任与数据点的个数的比。因为
N
=
∑
k
N
k
N=\sum_kN_k
N=∑kNk也可以理解为所有混合成分的的所有责任的总和,所以
π
k
\pi_k
πk可以理解为第k个混合成分对于整个数据集的相对重要性。
由于
N
k
=
∑
i
=
1
N
r
n
k
N_k=\sum^N_{i=1}r_{nk}
Nk=∑i=1Nrnk的更新等式依赖于责任,所以更新这个式子需要依赖于其他的所有参数:
π
j
,
μ
j
,
Σ
j
,
j
=
1
,
⋯
,
K
\pi_j,\mu_j,\Sigma_j,j=1,\cdots,K
πj,μj,Σj,j=1,⋯,K
实例(Example)
初始化
假设一个一维数据集
X
=
{
−
3
,
−
2.5
,
−
1
,
0
,
2
,
4
,
5
}
\mathcal X=\{-3,-2.5,-1,0,2,4,5\}
X={−3,−2.5,−1,0,2,4,5},现在有一个由三个成分混合而成的GMM,混合成份分别为:
p
1
(
x
)
=
N
(
x
∣
−
4
,
1
)
p
2
(
x
)
=
N
(
x
∣
0
,
0.2
)
p
3
(
x
)
=
N
(
x
∣
8
,
3
)
\begin{aligned} p_1(x) &= \mathcal N(x|-4,1) \\ p_2(x) &= \mathcal N(x|0,0.2)\\ p_3(x) &= \mathcal N(x|8,3) \end{aligned}
p1(x)p2(x)p3(x)=N(x∣−4,1)=N(x∣0,0.2)=N(x∣8,3)
初始化权重为:
π
1
=
π
2
=
π
3
=
1
3
\pi_1=\pi_2=\pi_3=\frac13
π1=π2=π3=31,在坐标中表示为:
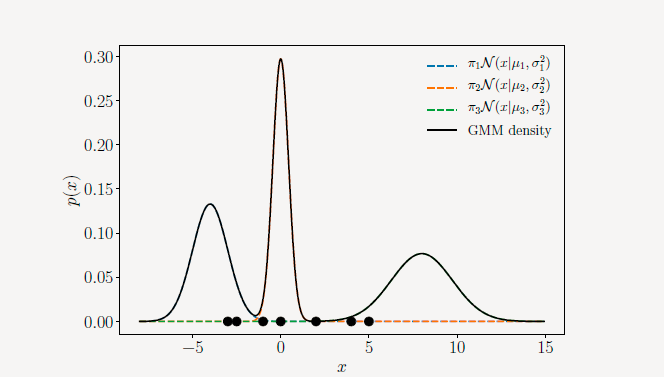
责任:
[
1.0
0.0
0.0
1.0
0.0
0.0
0.057
0.943
0.0
0.001
0.999
0.0
0.0
0.066
0.934
0.0
0.0
1.0
0.0
0.0
1.0
]
∈
R
N
×
K
.
\left[\begin{array}{ccc} 1.0 & 0.0 & 0.0 \\ 1.0 & 0.0 & 0.0 \\ 0.057 & 0.943 & 0.0 \\ 0.001 & 0.999 & 0.0 \\ 0.0 & 0.066 & 0.934 \\ 0.0 & 0.0 & 1.0 \\ 0.0 & 0.0 & 1.0 \end{array}\right] \in \mathbb{R}^{N \times K} .
⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡1.01.00.0570.0010.00.00.00.00.00.9430.9990.0660.00.00.00.00.00.00.9341.01.0⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤∈RN×K.
第n行告诉我们对
x
n
x_n
xn的所有混合成分的责任,责任之和为1,列告诉我们一个混合成分对所有的数据集的责任的情况。
更新均值
经计算,均值的变化为:
μ
1
:
−
4
→
−
2.7
μ
2
:
0
→
−
0.4
μ
3
:
8
→
3.7
\begin{aligned} & \mu_1:-4\rightarrow -2.7\\ & \mu_2:0\rightarrow -0.4\\ & \mu_3:8\rightarrow3.7 \end{aligned}
μ1:−4→−2.7μ2:0→−0.4μ3:8→3.7
变化形式表现在图中为:;
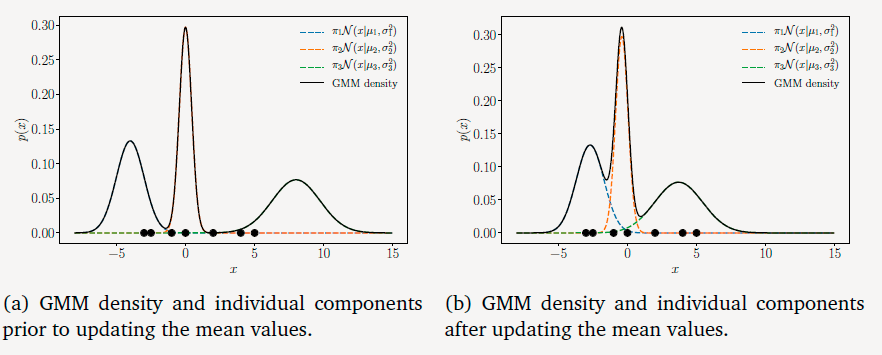
可以看到第一个混合成分和第三个混合成分朝着数据域的方向上移动。
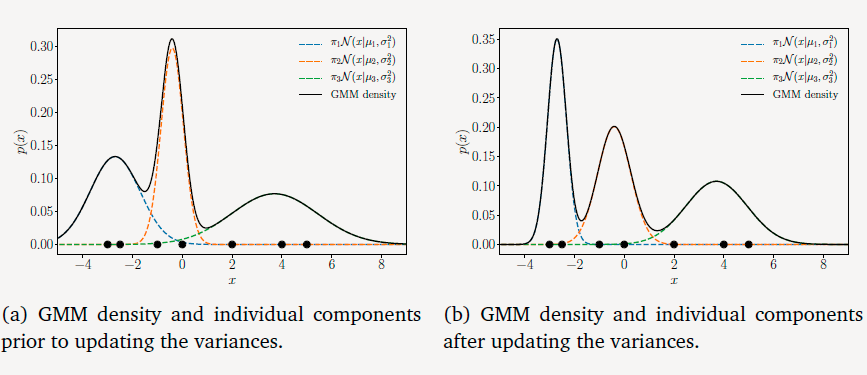
协方差更新
σ
1
2
:
1
→
0.14
σ
2
2
:
0.2
→
0.44
σ
3
2
:
3
→
1.53
\begin{aligned} &\sigma^2_1:1\rightarrow 0.14\\ & \sigma^2_2:0.2\rightarrow0.44\\ & \sigma_3^2:3\rightarrow1.53 \end{aligned}
σ12:1→0.14σ22:0.2→0.44σ32:3→1.53
这些变化表现在图像上为:
权重参数更新
π
1
:
1
3
→
0.29
π
2
:
1
3
→
0.29
π
3
:
1
3
→
0.42
\pi_1:\frac13\rightarrow0.29\\ \pi_2:\frac13\rightarrow0.29\\ \pi_3:\frac 13\rightarrow0.42
π1:31→0.29π2:31→0.29π3:31→0.42
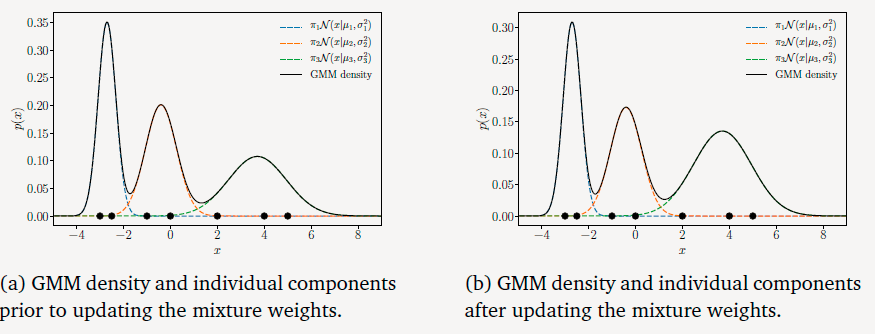
注意到图像中的各个峰值发生了变化。经过这一系列的更新,得到的模型能够更好地拟合给定的数据。
期望最大化算法(EM Algorithm)
由于之前提到的参数更新的过程依赖于责任 r n k r_{nk} rnk,而责任又与这些参数呈复杂的依赖关系,使得上述的更新过程没有一个闭型的解。接下来我们介绍一种解决参数的问题的迭代方案——期望最大化算法(The expectation maximization algorithm)。这其实是一种参数学习的泛化迭代方案。在高斯混合模中,我们选择参数的初始化值 μ k , Σ k , π k \mu_k,\Sigma_k,\pi_k μk,Σk,πk,不断改变这些参数,直到他们收敛于期望步(E-step)和极大步(M-step)之间的不断迭代。
期望步:评估责任 r n k r_{nk} rnk(属于k混合成分的的数据点n的后验概率)
极大步:用更新后的责任重新估计参数
由于EM算法每进行一次迭代都会导致似然函数值上升,所以可以利用这个特性直接检查自然对数似然或者参数。一个实例化的步骤如下:

迭代过程中的变化情况:
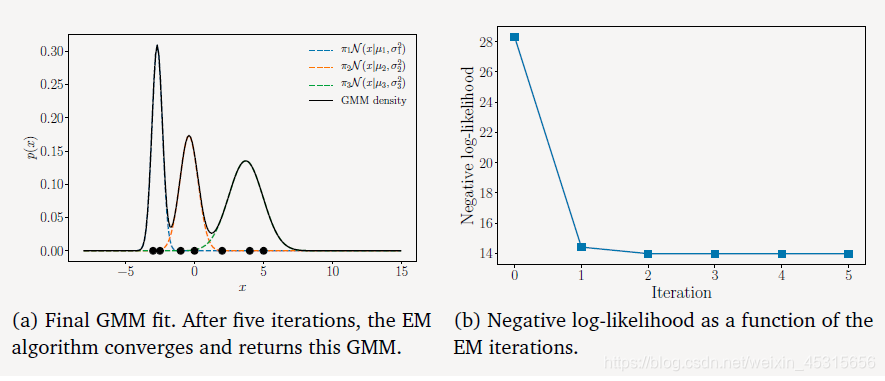
现在我们对开篇的时候的数据进行处理:
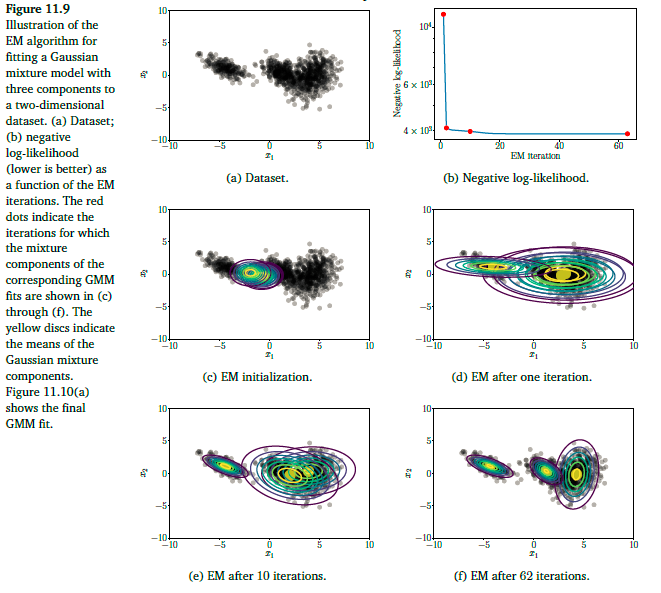
我们观察迭代的最终结果:
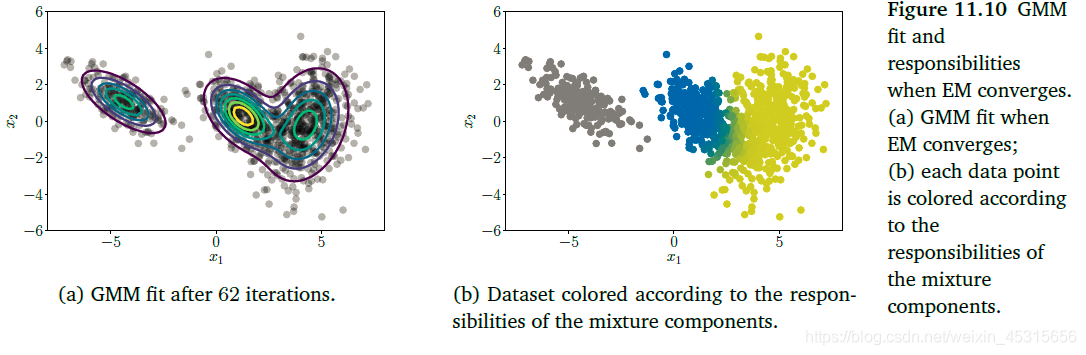
由上图可以直到,左边的一簇数据可以由一个单一的成分进行表示,但是右边的一簇数据是由两个成分混合儿而成的,所以这两个混合成分对这一簇的数据的责任在0.5左右。
潜变量角度(Latent-Variable Perspective)
我们使用一个离散型的潜变量模型来理解GMM。这样就可以将原先提到的责任的概念解释为后验概率分布了。其实,这个潜变量就是用来描述一个数据点在各个混合成分中的占有情况(表现为概率)。
生成过程和概率模型(Generative Process and Probabilistic Model)
想要得到对应的概率模型,我们需要弄清楚数据的生成过程。
假设一个混合模型由K个成分组成,而且每一个数据只能够由唯一的一个混合成分生成,这里我们引入一个定义域由0,1组成的随机变量
z
k
∈
{
0
,
1
}
z_k\in\{0,1\}
zk∈{0,1},这个随机变量表示第k个混合成份是否生成了该模型。所以:
p
(
x
∣
z
k
=
1
)
=
N
(
x
∣
μ
k
,
Σ
k
)
p(x|z_k=1)=\mathcal N(x|\mu_k,\Sigma_k)
p(x∣zk=1)=N(x∣μk,Σk)
其中,
z
:
=
[
z
1
,
⋯
,
z
K
]
⊤
z:=[z_1,\cdots,z_K]^\top
z:=[z1,⋯,zK]⊤,其中包含
K
−
1
K-1
K−1个0和
1
1
1个1.例如,
z
=
[
z
1
,
z
2
z
,
3
]
⊤
=
[
0
,
1
,
0
]
⊤
z=[z_1,z_2z,_3]^\top=[0,1,0]^\top
z=[z1,z2z,3]⊤=[0,1,0]⊤表示该数据是由第二个混合元素生成的。

在实际过程中,
z
k
z_k
zk可能是未知的,也就是可能是由不同的高斯模型混合按照不同的比例混合而成的。所以假设一个关于潜变量的先验分布:
p
(
z
)
=
π
=
[
π
1
,
⋯
,
π
K
]
⊤
,
∑
k
=
1
K
π
k
=
1
p(z)=\pi=[\pi_1,\cdots,\pi_K]^\top,\sum^K_{k=1}\pi_k=1
p(z)=π=[π1,⋯,πK]⊤,k=1∑Kπk=1
其中,
π
k
=
p
(
z
k
=
1
)
\pi_k=p(z_k=1)
πk=p(zk=1)表示该数据点由第k个成分生成的概率(类比为混合比例)。
潜变量的建模过程实际上对应着数据的生成过程,下面是单个数据的生成过程:
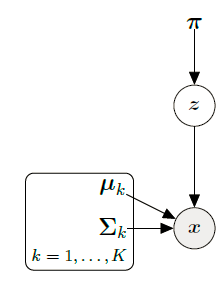
生成关系为:
z
(
i
)
∼
p
(
z
)
x
(
i
)
∼
p
(
x
∣
z
(
i
)
=
1
)
z_{(i)}\sim p(z)\\x^{(i)}\sim p(x|z^{(i)}=1)
z(i)∼p(z)x(i)∼p(x∣z(i)=1)
这种数据的采样依赖于图模型中的父节点的采样,这种采样称为原始采样(Ancestral Sampling)
通常一个概率模型是由数据和潜变量的联合分布定义的,结合前面的知识,我们可以得到所有K个成分的联合分布:
p
(
x
,
z
k
=
1
)
=
p
(
x
∣
z
k
=
1
)
p
(
z
k
=
1
)
=
π
k
N
(
x
∣
μ
k
,
Σ
k
)
p(x,z_k=1)=p(x|z_k=1)p(z_k=1)=\pi_k\mathcal N(x|\mu_k,\Sigma_k)
p(x,zk=1)=p(x∣zk=1)p(zk=1)=πkN(x∣μk,Σk)
对于所有的
k
=
1
,
⋯
,
K
k=1,\cdots ,K
k=1,⋯,K:
p
(
x
,
z
)
=
[
p
(
x
,
z
1
=
1
)
⋮
p
(
x
,
z
K
=
1
)
]
=
[
π
1
N
(
x
∣
μ
1
,
Σ
1
)
⋮
π
K
N
(
x
∣
μ
K
,
Σ
K
)
]
p(\boldsymbol{x}, \boldsymbol{z})=\left[\begin{array}{c} p\left(\boldsymbol{x}, z_{1}=1\right) \\ \vdots \\ p\left(\boldsymbol{x}, z_{K}=1\right) \end{array}\right]=\left[\begin{array}{c} \pi_{1} \mathcal{N}\left(\boldsymbol{x} \mid \boldsymbol{\mu}_{1}, \boldsymbol{\Sigma}_{1}\right) \\ \vdots \\ \pi_{K} \mathcal{N}\left(\boldsymbol{x} \mid \boldsymbol{\mu}_{K}, \boldsymbol{\Sigma}_{K}\right) \end{array}\right]
p(x,z)=⎣⎢⎡p(x,z1=1)⋮p(x,zK=1)⎦⎥⎤=⎣⎢⎡π1N(x∣μ1,Σ1)⋮πKN(x∣μK,ΣK)⎦⎥⎤
似然(Likelihood)
想要得到似然函数
p
(
x
∣
θ
)
p(x|\theta)
p(x∣θ),我们需要将潜变量消去,由于我们原先定义的潜变量是离散型的,所以只需要连加就可以将潜变量消掉:
p
(
z
∣
θ
)
=
∑
z
p
(
x
∣
θ
,
z
)
p
(
z
∣
θ
)
,
θ
:
=
{
μ
k
,
Σ
k
,
π
k
:
k
=
1
,
…
,
K
}
p(z|\theta)=\sum_zp(x|\theta,z)p(z|\theta), \quad \theta:=\{\mu_k,\Sigma_k,\pi_k:k=1,\dots,K\}
p(z∣θ)=z∑p(x∣θ,z)p(z∣θ),θ:={μk,Σk,πk:k=1,…,K}
采样的图模型为:(N个样本点)
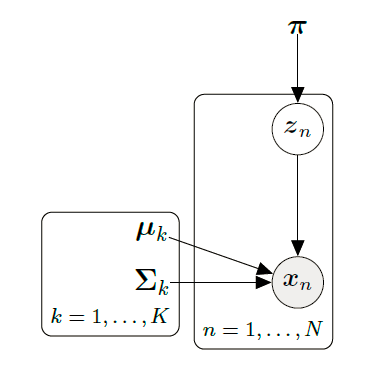
结合之前的知识,我们可以得到:
p
(
x
∣
θ
)
=
∑
k
=
1
K
π
k
N
(
x
∣
μ
k
,
Σ
k
)
p(x|\theta)=\sum^K_{k=1}\pi_k\mathcal N(x|\mu_k,\Sigma_k)
p(x∣θ)=k=1∑KπkN(x∣μk,Σk)
所以对于给定的数据集
X
\mathcal X
X的似然函数为:
p
(
X
∣
θ
)
=
∏
n
=
1
N
p
(
x
n
∣
θ
)
=
∏
n
=
1
N
∑
k
=
1
K
π
k
N
(
x
n
∣
μ
k
,
Σ
k
)
p(\mathcal X|\theta)=\prod^N_{n=1}p(x_n|\theta)=\prod^N_{n=1}\sum^K_{k=1}\pi_k\mathcal N(x_n|\mu_k,\Sigma_k)
p(X∣θ)=n=1∏Np(xn∣θ)=n=1∏Nk=1∑KπkN(xn∣μk,Σk)
这个与原先的概率模型一致
后验分布(Posterior Distribution)
根据贝叶斯公式,我们得到潜变量的后验分布:
p
(
z
k
=
1
∣
x
)
=
p
(
z
k
)
p
(
x
∣
z
k
=
1
)
p
(
x
)
p(z_k=1|x)=\frac{p(z_k)p(x|z_k=1)}{p(x)}
p(zk=1∣x)=p(x)p(zk)p(x∣zk=1)
将之前的结论带入:
p
(
z
k
∣
x
)
=
p
(
z
k
)
p
(
x
∣
z
k
)
∑
j
=
1
K
p
(
z
j
)
p
(
x
∣
z
j
)
=
π
k
N
(
x
∣
μ
k
,
Σ
k
)
∑
j
=
1
K
π
j
N
(
x
∣
μ
j
,
Σ
j
)
p(z_k|x)=\frac{p(z_k)p(x|z_k)}{\sum^K_{j=1}p(z_j)p(x|z_j)}=\frac{\pi_k\mathcal N(x|\mu_k,\Sigma_k)}{\sum^K_{j=1}\pi_j\mathcal N(x|\mu_j,\Sigma_j)}
p(zk∣x)=∑j=1Kp(zj)p(x∣zj)p(zk)p(x∣zk)=∑j=1KπjN(x∣μj,Σj)πkN(x∣μk,Σk)
可以发现,这就是我们之前提到的责任
拓展到整个数据集(Extension to a Full Dataset)
我们原先讨论的是单个数据,现在考虑一个数据集
X
:
=
{
x
1
,
⋯
,
x
N
}
\mathcal X:=\{x_1,\cdots,x_N\}
X:={x1,⋯,xN}每一个数据点都有自己的潜变量:
z
n
=
[
z
n
1
,
⋯
,
z
n
K
]
⊤
∈
R
K
z_n=[z_{n1},\cdots,z_{nK}]^\top\in\mathbb R^K
zn=[zn1,⋯,znK]⊤∈RK
由于所有的数据都是独立同分布的,所以可以将条件分布分解为连积的形式:
p
(
x
1
,
⋯
,
x
N
∣
z
1
,
⋯
,
z
N
)
=
∏
n
=
1
N
p
(
x
n
∣
z
n
)
p(x_1,\cdots,x_N|z_1,\cdots,z_N)=\prod^N_{n=1}p(x_n|z_n)
p(x1,⋯,xN∣z1,⋯,zN)=n=1∏Np(xn∣zn)
后验分布:
p
(
z
n
k
=
1
∣
x
n
)
=
p
(
x
n
∣
z
n
k
=
1
)
p
(
z
n
k
=
1
)
∑
j
=
1
K
p
(
x
n
∣
z
n
j
=
1
)
p
(
z
n
j
=
1
)
=
π
k
N
(
x
n
∣
μ
k
,
Σ
k
)
∑
j
=
1
K
π
j
N
(
x
n
∣
μ
j
,
Σ
j
)
=
r
n
k
\begin{aligned} p\left(z_{n k}=1 \mid \boldsymbol{x}_{n}\right) &=\frac{p\left(\boldsymbol{x}_{n} \mid z_{n k}=1\right) p\left(z_{n k}=1\right)}{\sum_{j=1}^{K} p\left(\boldsymbol{x}_{n} \mid z_{n j}=1\right) p\left(z_{n j}=1\right)} \\ &=\frac{\pi_{k} \mathcal{N}\left(\boldsymbol{x}_{n} \mid \boldsymbol{\mu}_{k}, \boldsymbol{\Sigma}_{k}\right)}{\sum_{j=1}^{K} \pi_{j} \mathcal{N}\left(\boldsymbol{x}_{n} \mid \boldsymbol{\mu}_{j}, \boldsymbol{\Sigma}_{j}\right)}=r_{n k} \end{aligned}
p(znk=1∣xn)=∑j=1Kp(xn∣znj=1)p(znj=1)p(xn∣znk=1)p(znk=1)=∑j=1KπjN(xn∣μj,Σj)πkN(xn∣μk,Σk)=rnk
这还是第k个混合元素的责任。
期望最大化算法重新回顾(EM Algorithm Revisited)
EM算法是一种用于求解极大似然估计的迭代算法,可以从潜变量的角度推导得来。对于一个给定的模型参数
θ
(
t
)
\theta^{(t)}
θ(t),在期望步时,计算自然对数似然的期望:
Q
(
θ
∣
θ
(
t
)
)
=
E
z
∣
x
,
θ
(
t
)
[
log
p
(
x
,
z
∣
θ
)
]
=
∫
log
p
(
x
,
z
∣
θ
)
p
(
z
∣
x
,
θ
(
t
)
)
d
z
Q(\theta|\theta^{(t)})=\mathbb E_{z|x,\theta^{(t)}}[\log p(x,z|\theta)]=\int \log p(x,z|\theta)p(z|x,\theta^{(t)})dz
Q(θ∣θ(t))=Ez∣x,θ(t)[logp(x,z∣θ)]=∫logp(x,z∣θ)p(z∣x,θ(t))dz
之后的极大步算则一个最大化上式的参数用于更新。但是EM算法并不一定会收敛于极大似然估计的解,有时候会收敛于局部最优解。可以采用不同的初始化值,这样可以减少得到局部最优解的风险。
拓展阅读
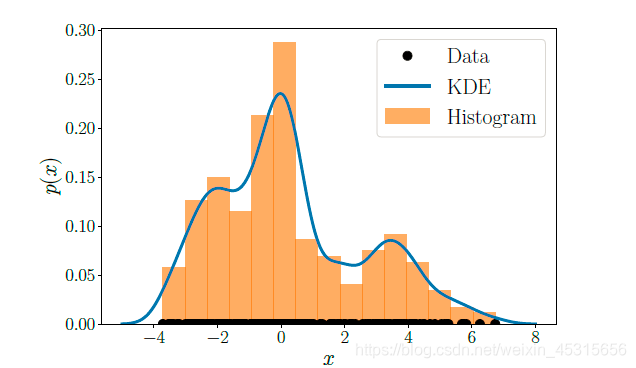
核密度估计(Kernel Density Estimation):
核密度估计是一种非参数密度估计,其实我们熟悉的直方图就是一种非参数估计,其中直方图的间距不合适可能会导致过拟合或者欠拟合。对于一个数据集,核密度估计的分布为:
p
(
x
)
=
1
N
h
∑
n
=
1
N
k
(
x
−
x
n
h
)
p(x)=\frac{1}{Nh}\sum^N_{n=1}k(\frac{x-x_n}{h})
p(x)=Nh1n=1∑Nk(hx−xn)
其中,k为核函数(Kernel Function),就是一个非负且积分值为1的函数。
h
>
0
h>0
h>0是一个光滑参数(smoothing/bandwidth parameter)这个与直方图的面元(直方图的柱子的宽度,bin size)大小类似。核函数通常的选择就是高斯函数或者时均匀分布函数。同时,核密度估计与直方图密切相关,但是核密度估计是光滑的,直方图不是。

















 888
888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









